Recognition: 2 theorem links
· Lean TheoremBoth Ends Count! Just How Good are LLM Agents at "Text-to-Big SQL"?
Pith reviewed 2026-05-15 19:50 UTC · model grok-4.3
The pith
Text-to-SQL accuracy metrics ignore the massive cost and latency penalties that emerge when queries run on large-scale data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing text-to-SQL metrics are insufficient for Big Data because they overlook execution efficiency, cost, and the impact of data scale; the proposed text-to-Big SQL metrics accurately capture these factors, as shown by frontier models where GPT-4o trades roughly 7 percent lower accuracy for up to 12.16 times speedup and GPT-5.2 proves more than twice as cost-effective as Gemini 3 Pro at large input scales.
What carries the argument
The new text-to-Big SQL metrics that incorporate execution efficiency, monetary cost, and data-scale effects into the evaluation of LLM-generated SQL queries.
If this is right
- Model selection for large-scale deployments should weigh efficiency and cost alongside accuracy.
- Minor translation errors that are acceptable on small tables produce substantial cost and latency overheads at scale.
- Production systems using LLM agents need metrics that reflect database-agnostic performance across varying data sizes.
- Later-generation models can achieve better cost-effectiveness than earlier ones when evaluated at large input scales.
- Text-to-Big SQL benchmarks should include scale-dependent cost and speed measurements to guide practical use.
Where Pith is reading between the lines
- Benchmark suites for LLM SQL generation will need to adopt large synthetic datasets as a standard requirement.
- Developers may shift focus from raw accuracy to cost-per-query when choosing models for analytics pipelines.
- The same efficiency-versus-accuracy trade-off likely appears in other data-intensive generation tasks such as data transformation scripts.
- Organizations could save significant cloud spend by preferring models that optimize for execution speed on big data even if accuracy is slightly lower.
Load-bearing premise
The novel metrics are representative of real production Text-to-Big SQL workloads and the frontier-model evaluation is sufficiently broad.
What would settle it
An experiment that measures actual production costs and latencies for the same queries and finds no correlation with the paper's proposed metrics would disprove the central claim.
Figures







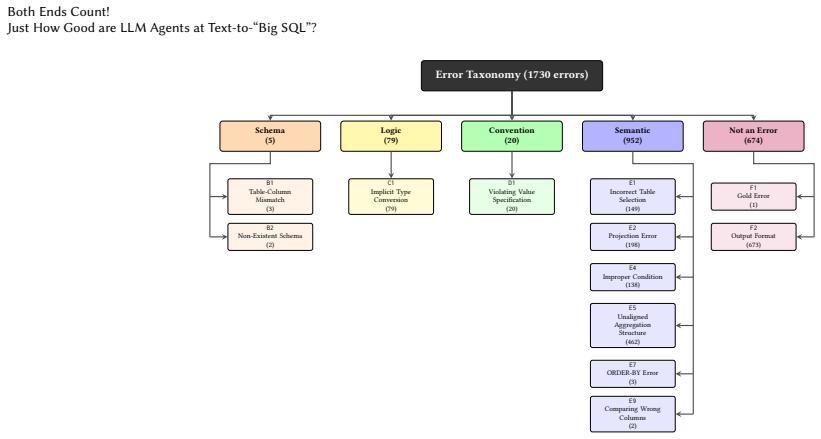
read the original abstract
Text-to-SQL and Big Data are both extensively benchmarked fields, yet there is limited research that evaluates them jointly. In the real world, Text-to-SQL systems are often embedded with Big Data workflows, such as large-scale data processing or interactive data analytics. We refer to this as ``Text-to-Big SQL''. However, existing text-to-SQL benchmarks remain narrowly scoped and overlook the cost and performance implications that arise at scale. For instance, translation errors that are minor on small datasets lead to substantial cost and latency overheads as data scales, a relevant issue completely ignored by text-to-SQL metrics. In this paper, we overcome this overlooked challenge by introducing novel and representative metrics for evaluating Text-to-Big SQL. Our study focuses on production-level LLM agents, a database-agnostic system adaptable to diverse user needs. Via an extensive evaluation of frontier models, we show that text-to-SQL metrics are insufficient for Big Data. In contrast, our proposed text-to-Big SQL metrics accurately reflect execution efficiency, cost, and the impact of data scale. For example, GPT-4o compensates for roughly 7% lower accuracy than the top-performing later-generation models with up to a 12.16x speedup, while GPT-5.2 is more than twice as cost-effective as Gemini 3 Pro at large input scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the concept of 'Text-to-Big SQL' to address the gap between standard Text-to-SQL benchmarks and real-world Big Data workflows. It argues that existing accuracy-focused metrics overlook execution cost, latency, and data-scale effects, proposes new scale-sensitive metrics, and evaluates frontier LLM agents (e.g., GPT-4o, GPT-5.2, Gemini 3 Pro) to show that standard metrics are insufficient while the new metrics better capture efficiency trade-offs, including a 12.16x speedup for GPT-4o despite ~7% lower accuracy and superior cost-effectiveness for GPT-5.2 at large scales.
Significance. If the proposed metrics and evaluation hold under scrutiny, the work is significant for bridging Text-to-SQL and Big Data research, providing actionable insights into production LLM agent performance where cost and latency dominate. The concrete empirical trade-off examples (speed vs. accuracy, cost-effectiveness at scale) could influence benchmark design and model selection in large-scale analytics.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The manuscript states concrete quantitative claims (12.16x speedup, 7% accuracy gap, 2x cost-effectiveness) but supplies no dataset scales, query workloads, execution environment details, or error bars/statistical tests. This makes it impossible to verify whether the reported differences are load-bearing or sensitive to benchmark construction.
- [Proposed Metrics] Proposed Metrics section: The central claim that the new Text-to-Big SQL metrics 'accurately reflect execution efficiency, cost, and the impact of data scale' requires explicit formulas or pseudocode for the metrics (e.g., how latency and cost are normalized across data sizes). Without these, it is unclear whether the metrics are independent of the evaluation setup or simply re-express standard execution time.
minor comments (2)
- [Abstract] The abstract uses 'GPT-5.2' and 'Gemini 3 Pro' without clarifying whether these refer to specific released versions or internal names; add precise model identifiers in the Evaluation section.
- [Evaluation] Clarify the database-agnostic claim for the LLM agents: specify which engines (e.g., Spark, BigQuery) were used for the Big Data execution measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity and verifiability, and we will address them fully in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The manuscript states concrete quantitative claims (12.16x speedup, 7% accuracy gap, 2x cost-effectiveness) but supplies no dataset scales, query workloads, execution environment details, or error bars/statistical tests. This makes it impossible to verify whether the reported differences are load-bearing or sensitive to benchmark construction.
Authors: We agree that the abstract and evaluation section would benefit from greater explicitness on the experimental parameters. The full manuscript describes evaluations on data scales ranging from 1 GB to 100 TB using extended TPC-DS workloads with 500 analytical queries on a distributed Spark-based execution environment. To make these details immediately verifiable and to address sensitivity concerns, we will add a dedicated 'Experimental Setup' subsection (including a summary table of scales, workloads, and hardware), report standard deviations across multiple runs, and include statistical significance tests (paired t-tests) for the reported differences such as the 12.16x speedup and cost-effectiveness claims. revision: yes
-
Referee: [Proposed Metrics] Proposed Metrics section: The central claim that the new Text-to-Big SQL metrics 'accurately reflect execution efficiency, cost, and the impact of data scale' requires explicit formulas or pseudocode for the metrics (e.g., how latency and cost are normalized across data sizes). Without these, it is unclear whether the metrics are independent of the evaluation setup or simply re-express standard execution time.
Authors: We accept that the current presentation of the metrics lacks sufficient formalization. The proposed Text-to-Big SQL metrics incorporate scale normalization (e.g., latency scaled by data volume and accuracy-weighted cost) to capture efficiency trade-offs beyond raw execution time. In the revision we will insert explicit mathematical definitions together with pseudocode in the 'Proposed Metrics' section, including the normalization procedure across data sizes. This will clarify independence from any particular execution environment and demonstrate that the metrics are not simple re-expressions of standard latency. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical evaluation study that introduces new metrics for Text-to-Big SQL performance (accuracy, execution efficiency, cost, and scale impact) and applies them to frontier LLM agents. Claims rest on direct experimental comparisons across models and data scales, with no mathematical derivation chain, no fitted parameters renamed as predictions, and no load-bearing self-citations or ansatzes. The abstract and described methodology define the novel metrics explicitly as extensions that capture overlooked scale effects, without reducing to self-definition or prior author results by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VES* = 1/N Σ [1(Vi, V̂i) · P(Si, Ŝi) · Tgold / Te2e]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose new metrics that jointly assess agent action, reasoning latency, and the cost-effectiveness of generated queries
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Feder Cooper, Sanmi Koyejo, and Percy Liang
Ahmed Ahmed, A. Feder Cooper, Sanmi Koyejo, and Percy Liang. 2026. Extracting books from production language models. arXiv:2601.02671 [cs.CL] https://arxiv. org/abs/2601.02671
-
[2]
Amazon Web Services. 2026. Amazon EMR - Cloud Big Data Platform. https: //aws.amazon.com/emr/. Accessed: February 22, 2026
work page 2026
-
[3]
Amazon Web Services, Inc. 2026. Amazon Athena - Serverless Interactive Query Service. https://aws.amazon.com/athena/ Accessed: 2026-02-12
work page 2026
-
[4]
Amazon Web Services, Inc. 2026. Amazon EC2. https://aws.amazon.com/ec2/ Accessed: 2026-02-22
work page 2026
-
[5]
Anthropic. 2024. Claude 3 Opus. https://www.anthropic.com/claude/opus Accessed: 2026-02-21
work page 2024
-
[6]
Apache Software Foundation. 2026. pyspark.sql.Catalog — PySpark 4.1.1 Docu- mentation. https://spark.apache.org/docs/latest/api/python/reference/pyspark. sql/api/pyspark.sql.Catalog.html. Accessed: 2026-02-19
work page 2026
-
[7]
Lorenzo Baldacci and Matteo Golfarelli. 2019. A Cost Model for SPARK SQL . IEEE Transactions on Knowledge & Data Engineering31, 05 (May 2019), 819–832. doi:10.1109/TKDE.2018.2850339
-
[8]
Pranav Bhagat, K N Ajay Shastry, Pranoy Panda, and Chaitanya Devaguptapu
-
[9]
Evaluating Compound AI Systems through Behaviors, Not Benchmarks. In Findings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 24193–24222. doi:10. 18653/v1/2025.findings-emnlp.1314
work page 2025
-
[10]
Surajit Chaudhuri, Bolin Ding, and Srikanth Kandula. 2017. Approximate Query Processing: No Silver Bullet. In2017 ACM International Conference on Manage- ment of Data (SIGMOD’17). Association for Computing Machinery, New York, NY, USA, 511–519. doi:10.1145/3035918.3056097
-
[11]
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. 2025. Barbarians at the Gate: How AI is Upending Systems Research. arXiv:2510.06189 [cs.AI] https://arxiv.org/abs/2510.06189
-
[12]
Kakkar, Yu Gan, Brenton Milne, and Fatma Özcan
Yeounoh Chung, Gaurav T. Kakkar, Yu Gan, Brenton Milne, and Fatma Özcan
-
[13]
VLDB Endow.18, 8 (April 2025), 2735–2747
Is Long Context All You Need? Leveraging LLM’s Extended Context for NL2SQL.Proc. VLDB Endow.18, 8 (April 2025), 2735–2747. doi:10.14778/3742728. 3742761
-
[14]
crewAI. 2026. crewAI: Multi AI Agents Systems. https://www.crewai.com/ Accessed: 2026-02-21
work page 2026
- [15]
- [16]
- [17]
-
[18]
Han Fu, Chang Liu, Bin Wu, Feifei Li, Jian Tan, and Jianling Sun. 2023. CatSQL: Towards Real World Natural Language to SQL Applications.Proc. VLDB Endow. 16, 6 (Feb. 2023), 1534–1547. doi:10.14778/3583140.3583165
-
[19]
Google. 2026. Gemini API Pricing. https://ai.google.dev/gemini-api/docs/pricing. Accessed: 2026-02-23
work page 2026
-
[20]
Google Cloud. 2026. BigQuery: Cloud Data Warehouse. https://cloud.google. com/bigquery?hl=en Accessed: 2026-02-12
work page 2026
-
[21]
Google Cloud. 2026. Generative AI overview. https://docs.cloud.google.com/ bigquery/docs/generative-ai-overview BigQuery - Google Cloud Documenta- tion
work page 2026
- [22]
-
[23]
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. 2025. Next-Generation Database Interfaces: A Survey of LLM-Based Text-to-SQL .IEEE Transactions on Knowledge & Data Engineering 37, 12 (Dec. 2025), 7328–7345. doi:10.1109/TKDE.2025.3609486
- [24]
-
[25]
Nan Huo, Xiaohan Xu, Jinyang Li, Per Jacobsson, Shipei Lin, Bowen Qin, Binyuan Hui, Xiaolong Li, Ge Qu, Shuzheng Si, Linheng Han, Edward Alexander, Xintong Zhu, Rui Qin, Ruihan Yu, Yiyao Jin, Feige Zhou, Weihao Zhong, Yun Chen, Hongyu Liu, Chenhao Ma, Fatma Ozcan, Yannis Papakonstantinou, and Reynold Cheng. 2025. BIRD-INTERACT: Re-imagining Text-to-SQL Ev...
-
[26]
IBM. [n. d.]. IBM Db2 Big SQL. https://www.ibm.com/es-es/products/db2-big-sql. Accessed: 2026-02-21
work page 2026
-
[27]
Dimitrios Koutsoukos, Renato Marroquín, Ingo Müller, and Ana Klimovic. 2025. Adaptive data transformations for QaaS. In15th Conference on Innovative Data Systems Research, CIDR 2025, Amsterdam, The Netherlands, January 19-22, 2025. www.cidrdb.org. https://vldb.org/cidrdb/2025/adaptive-data-transformations- for-qaas.html
work page 2025
-
[28]
LangChain. 2026. LangChain GitHub Repository. https://github.com/langchain- ai/langchain. Accessed: 2026-02-14
work page 2026
-
[29]
LangChain Inc. 2024. LangGraph: Agent Orchestration Framework for Reliable AI Agents. https://www.langchain.com/langgraph Accessed: 2025-05-14
work page 2024
-
[30]
LangChain Inc. 2026. Spark SQL | LangChain. https://python.langchain.com/ docs/integrations/tools/spark_sql/ Accessed: 2026-02-11
work page 2026
-
[31]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. arXiv:2411.07763 [cs.CL] https://arxiv.org/abs/2411.07763
-
[32]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready?Proc. VLDB Endow.17, 11 (July 2024), 3318–3331. doi:10.14778/3681954.3682003
- [33]
-
[34]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li. 2025. OmniSQL: Synthesizing High-Quality Text-to-SQL Data at Scale.Proc. VLDB Endow.18, 11 (July 2025), 4695–4709. doi:10.14778/3749646.3749723
-
[35]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM already serve as a database interface? a big bench for large-scale database grounded text-to-SQLs. InProceedings of the 37th Internat...
work page 2023
-
[36]
Chunwei Liu, Gerardo Vitagliano, Brandon Rose, Matthew Printz, David Andrew Samson, and Michael Cafarella. 2025. PalimpChat: Declarative and Interactive AI analytics. InCompanion of the 2025 International Conference on Management of Data(Berlin, Germany)(SIGMOD/PODS ’25). Association for Computing Ma- chinery, New York, NY, USA, 183–186. doi:10.1145/37222...
-
[37]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2025. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. arXiv:2509.00997 [cs.AI] https://arxiv.org/a...
-
[38]
Yuyu Luo, Guoliang Li, Ju Fan, Chengliang Chai, and Nan Tang. 2025. Natural Language to SQL: State of the Art and Open Problems.Proc. VLDB Endow.18, 12 (Aug. 2025), 5466–5471. doi:10.14778/3750601.3750696
-
[39]
Heng Ma, Alexander Brace, Carlo Siebenschuh, Ian Foster, and Arvind Ra- manathan. 2025. LangChain-Parsl: Connect Large Language Model Agents to High Performance Computing Resource. InProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC Workshops ’25). Association for Compu...
-
[40]
Microsoft. 2024. AutoGen: A Programming Framework for Agentic AI. https: //microsoft.github.io/autogen/stable//index.html Accessed: 2026-02-21
work page 2024
-
[41]
OpenAI. 2025. GPT-5.2 Model Documentation. https://developers.openai.com/ api/docs/models/gpt-5.2 Accessed: 2026-02-21
work page 2025
-
[42]
OpenAI. 2026. API Pricing. https://developers.openai.com/api/docs/pricing/. Accessed: 2026-02-23
work page 2026
-
[43]
Giovanni Pinna, Yuriy Perezhohin, Luca Manzoni, Mauro Castelli, and Andrea De Lorenzo. 2025. Redefining text-to-SQL metrics by incorporating semantic and structural similarity.Scientific Reports15, 1 (01 Jul 2025), 22357. doi:10.1038/ s41598-025-04890-9
work page 2025
- [44]
-
[45]
Ranjan Sapkota, Konstantinos I. Roumeliotis, and Manoj Karkee. 2026. AI Agents vs. Agentic AI: A Conceptual taxonomy, applications and challenges.Information Fusion126 (2026), 103599. doi:10.1016/j.inffus.2025.103599
- [46]
- [47]
-
[48]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv:2504.01848 [cs.AI] https://arxiv.org/ abs/2504.01848
work page internal anchor Pith review arXiv 2025
- [49]
-
[50]
The Apache Software Foundation. 2026. Spark SQL & DataFrame. https: //spark.apache.org/sql/ Accessed: 2026-02-15
work page 2026
-
[51]
Transaction Processing Performance Council. 2024. TPC Benchmark H (Deci- sion Support) Standard Specification Revision 3.0.1. [https://www.tpc.org/tpch/ ](https://www.tpc.org/tpch/). Accessed: 2026-02-21
work page 2024
-
[52]
Alexander van Renen and Viktor Leis. 2023. Cloud Analytics Benchmark.Proc. VLDB Endow.16, 6 (Feb. 2023), 1413–1425. doi:10.14778/3583140.3583156
-
[53]
Pengyi Wang, Sibei Chen, Ju Fan, Bin Wu, Nan Tang, and Jian Tan. 2025. An- dromeda: Debugging Database Performance Issues with Retrieval-Augmented Large Language Models. InCompanion of the 2025 International Conference on Management of Data(Berlin, Germany)(SIGMOD/PODS ’25). Association for Com- puting Machinery, New York, NY, USA, 243–246. doi:10.1145/37...
- [54]
-
[55]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2019. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. arXiv:1809.08887 [cs.CL] https://arxiv.org/abs/1809.08887
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[57]
Zheng Yuan, Hao Chen, Zijin Hong, Qinggang Zhang, Feiran Huang, Qing Li, and Xiao Huang. 2025. Knapsack Optimization-based Schema Linking for LLM-based Text-to-SQL Generation. arXiv:2502.12911 [cs.CL] https://arxiv.org/abs/2502. 12911
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Chao Zhang, Yuren Mao, Yijiang Fan, Yu Mi, Yunjun Gao, Lu Chen, Dongfang Lou, and Jinshu Lin. 2024. FinSQL: Model-Agnostic LLMs-based Text-to-SQL Frame- work for Financial Analysis. InCompanion of the 2024 International Conference on Management of Data(Santiago AA, Chile)(SIGMOD ’24). Association for Com- puting Machinery, New York, NY, USA, 93–105. doi:1...
- [59]
- [60]
-
[61]
Which year has the most number of races? The most number of races refers to max(round)
Xiaohu Zhu, Qian Li, Lizhen Cui, and Yongkang Liu. 2024. Large Language Model Enhanced Text-to-SQL Generation: A Survey. arXiv:2410.06011 [cs.DB] https://arxiv.org/abs/2410.06011 Eizaguirre et al. Appendix A Text-to-SQL formulas A text-to-SQL benchmark suite includes a set of triples containing anatural language(NL) query, agolden queryin SQL ( 𝑄𝑛), and a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.