Recognition: no theorem link
AlayaLaser: Efficient Index Layout and Search Strategy for Large-scale High-dimensional Vector Similarity Search
Pith reviewed 2026-05-15 18:41 UTC · model grok-4.3
The pith
AlayaLaser shows that on-disk graph indexes for high-dimensional vectors can match or beat in-memory speed by fixing compute bottlenecks instead of chasing I/O savings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
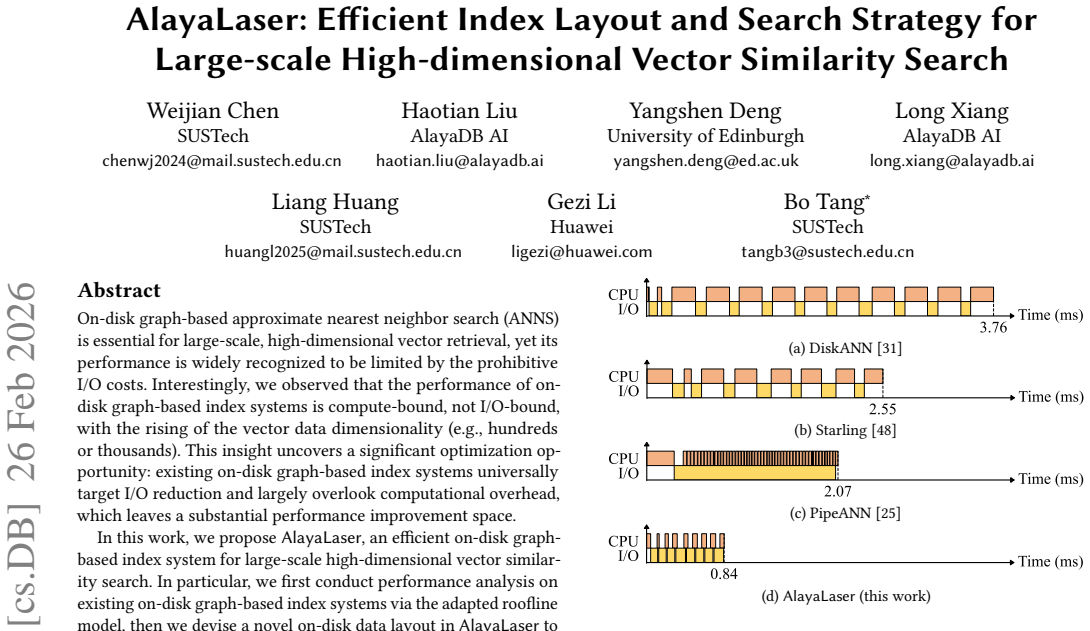
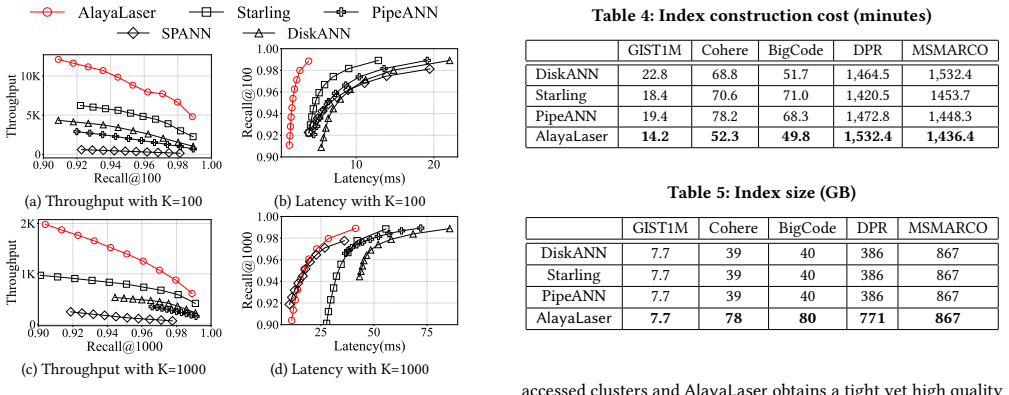
Performance analysis with an adapted roofline model reveals that on-disk graph-based ANNS becomes compute-bound rather than I/O-bound at high dimensions, so a SIMD-friendly on-disk data layout plus degree-based node caching, cluster-based entry point selection, and early dispatch strategy can reduce computational overhead enough for the system to surpass existing on-disk indexes and match or exceed in-memory performance.
What carries the argument
The SIMD-friendly on-disk data layout that packs vector data and graph edges for efficient parallel CPU processing, which directly targets the compute-bound bottleneck shown by the roofline analysis.
If this is right
- Large vector collections can stay on disk while still supporting query speeds previously possible only with full in-memory indexes.
- CPU SIMD instructions become a first-class tool for designing storage-resident graph indexes.
- The same roofline-guided analysis can be reused to spot compute versus I/O limits in other vector search methods.
- Memory requirements for production vector databases drop without sacrificing latency.
Where Pith is reading between the lines
- The layout approach could extend to non-graph indexes such as inverted files or product quantization structures.
- Lower compute time per query may reduce overall energy use when serving millions of searches.
- Similar redesigns might improve performance on storage devices other than SSDs, such as network-attached storage.
Load-bearing premise
That the main slowdown at high dimensions is CPU computation rather than disk reads, and that the new layout will cut that computation without raising I/O costs enough to cancel the gains.
What would settle it
A timing breakdown on any of the paper's high-dimensional datasets that shows disk I/O time still accounts for more than half of total search latency even after applying the SIMD layout and heuristics.
Figures













read the original abstract
On-disk graph-based approximate nearest neighbor search (ANNS) is essential for large-scale, high-dimensional vector retrieval, yet its performance is widely recognized to be limited by the prohibitive I/O costs. Interestingly, we observed that the performance of on-disk graph-based index systems is compute-bound, not I/O-bound, with the rising of the vector data dimensionality (e.g., hundreds or thousands). This insight uncovers a significant optimization opportunity: existing on-disk graph-based index systems universally target I/O reduction and largely overlook computational overhead, which leaves a substantial performance improvement space. In this work, we propose AlayaLaser, an efficient on-disk graph-based index system for large-scale high-dimensional vector similarity search. In particular, we first conduct performance analysis on existing on-disk graph-based index systems via the adapted roofline model, then we devise a novel on-disk data layout in AlayaLaser to effectively alleviate the compute-bound, which is revealed by the above roofline model analysis, by exploiting SIMD instructions on modern CPUs. We next design a suite of optimization techniques (e.g., degree-based node cache, cluster-based entry point selection, and early dispatch strategy) to further improve the performance of AlayaLaser. We last conduct extensive experimental studies on a wide range of large-scale high-dimensional vector datasets to verify the superiority of AlayaLaser. Specifically, AlayaLaser not only surpasses existing on-disk graph-based index systems but also matches or even exceeds the performance of in-memory index systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-disk graph-based ANNS becomes compute-bound (rather than I/O-bound) once vector dimensionality reaches hundreds or thousands, as shown by an adapted roofline model. It introduces AlayaLaser, which uses a SIMD-friendly on-disk layout plus heuristics (degree-based node cache, cluster-based entry point selection, early dispatch) to reduce compute overhead, claiming via experiments to outperform prior on-disk graph indexes while matching or exceeding in-memory indexes on large-scale high-dimensional datasets.
Significance. If the roofline premise and performance crossover hold, the work would be significant for memory-constrained large-scale vector retrieval, shifting optimization focus from pure I/O reduction to compute efficiency in on-disk ANNS and potentially enabling practical deployment of graph indexes on datasets exceeding RAM.
major comments (2)
- [Performance Modeling] Performance-modeling section: the adapted roofline analysis asserts compute-bound behavior at high dimensionality, yet the workload-specific parameters (arithmetic intensity, achieved FLOPS) are not cross-validated against direct I/O instrumentation or measured NVMe stalls; without this, the premise that prefetching fully overlaps I/O and that SIMD layout yields measurable gains remains unanchored.
- [Experimental Evaluation] Experimental evaluation section: the central claim that AlayaLaser surpasses on-disk systems and matches/exceeds in-memory ones rests on experimental studies, but the provided abstract supplies no quantitative results, baselines, dataset cardinalities, dimensionality values, or error bars, preventing verification of the reported superiority.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experimental studies on a wide range of large-scale high-dimensional vector datasets' is stated without naming the datasets or reporting even summary metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, proposing revisions where they strengthen the work without altering our core claims.
read point-by-point responses
-
Referee: [Performance Modeling] Performance-modeling section: the adapted roofline analysis asserts compute-bound behavior at high dimensionality, yet the workload-specific parameters (arithmetic intensity, achieved FLOPS) are not cross-validated against direct I/O instrumentation or measured NVMe stalls; without this, the premise that prefetching fully overlaps I/O and that SIMD layout yields measurable gains remains unanchored.
Authors: We appreciate the referee's point on empirical anchoring of the roofline parameters. The adapted model derives arithmetic intensity directly from vector dimensionality and distance-computation operations per loaded byte, and estimates achieved FLOPS from measured SIMD throughput (AVX-512) on the evaluated CPUs. Our experiments already show CPU utilization approaching saturation once prefetching is enabled, supporting the compute-bound regime. To address the validation gap, we will add a new subsection with direct I/O instrumentation (using perf and NVMe counters) and stall-cycle measurements to cross-validate the intensity and overlap assumptions. revision: yes
-
Referee: [Experimental Evaluation] Experimental evaluation section: the central claim that AlayaLaser surpasses on-disk systems and matches/exceeds in-memory ones rests on experimental studies, but the provided abstract supplies no quantitative results, baselines, dataset cardinalities, dimensionality values, or error bars, preventing verification of the reported superiority.
Authors: The referee is correct that the abstract is intentionally concise and omits specific numbers. The full manuscript (Section 5) details the experimental setup, including dataset cardinalities (millions to billions of vectors), dimensionalities (128–4096), baselines (on-disk and in-memory graph indexes), and results with error bars from repeated runs. We will revise the abstract to include representative quantitative highlights drawn from those experiments so that the superiority claims can be verified at a glance. revision: yes
Circularity Check
No circularity; claims rest on roofline analysis and independent empirical evaluation
full rationale
The paper derives its central insight (on-disk graph ANNS becoming compute-bound at high dimensionality) from an adapted roofline model applied to existing systems, then proposes SIMD-friendly layout and heuristics motivated by that analysis. These steps are followed by direct experimental comparison against baselines on multiple datasets, with no equations, fitted parameters, or self-citations that reduce the performance claims to self-referential definitions or constructions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- node cache size
axioms (1)
- domain assumption On-disk graph-based ANNS performance becomes compute-bound rather than I/O-bound at high dimensionality
Forward citations
Cited by 1 Pith paper
-
Low-Latency Out-of-Core ANN Search in High-Dimensional Space
SkipDisk is a disk-memory hybrid ANN search that achieves 63-85% of HNSW latency at 10-20% memory footprint via dedicated pivots for tighter lower bounds, three-level pruning, and decoupled async I/O.
Reference graph
Works this paper leans on
- [1]
-
[2]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2017. Acceler- ated nearest neighbor search with quick adc. InICMR. 159–166
work page 2017
-
[3]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2019. Quicker adc: Unlocking the hidden potential of product quantization with simd.TPAMI 43, 5 (2019), 1666–1677
work page 2019
-
[4]
Argilla. 2024. PersonaHub-FineWeb-Edu-4-Embeddings. Hugging Face dataset.https://huggingface.co/datasets/argilla-warehouse/personahub- fineweb-edu-4-embeddingsAccessed: 2025-10-06
work page 2024
-
[5]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374
work page 2020
-
[6]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2023. Elpis: Graph-based similarity search for scalable data science.PVLDB16, 6 (2023), 1548–1559
work page 2023
-
[7]
Artem Babenko and Victor Lempitsky. 2014. The inverted multi-index.TPAMI 37, 6 (2014), 1247–1260
work page 2014
-
[8]
Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Victor Lempitsky. 2014. Neural codes for image retrieval. InECCV. 584–599
work page 2014
-
[9]
2006.Pattern recognition and machine learning
Christopher M Bishop and Nasser M Nasrabadi. 2006.Pattern recognition and machine learning. Vol. 4. Springer
work page 2006
-
[10]
Davis W Blalock and John V Guttag. 2017. Bolt: Accelerated data mining with fast vector compression. InSIGKDD. 727–735
work page 2017
-
[11]
Meng Chen, Kai Zhang, Zhenying He, Yinan Jing, and X Sean Wang. 2024. Roar- Graph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Near- est Neighbor Search.Proc. VLDB Endow.17, 11 (2024), 2735–2749
work page 2024
-
[12]
Qi Chen, Haidong Wang, Mingqin Li, Gang Ren, Scarlett Li, Jeffery Zhu, Jason Li, Chuanjie Liu, Lintao Zhang, and Jingdong Wang. 2018.SPTAG: A library for fast approximate nearest neighbor search.https://github.com/Microsoft/SPTAG Accessed: 2025-5-12
work page 2018
-
[13]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. Spann: Highly-efficient billion-scale approximate nearest neighborhood search.NIPS34 (2021), 5199–5212
work page 2021
-
[14]
Cohere. 2025. msmarco-v2.1-embed-english-v3. Hugging Face dataset.https: //huggingface.co/datasets/Cohere/msmarco-v2.1-embed-english-v3Accessed: 2025-10-06
work page 2025
-
[15]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InRECSYS. 191–198
work page 2016
-
[16]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InSIGKDD. 6491–6501
work page 2024
-
[17]
C Fu. 2016. Efanna: An Extremely Fast Approximate Nearest Neighbor Search Algorithm Based on kNN Graph.arXiv preprint arXiv:1609.07228(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Cong Fu, Changxu Wang, and Deng Cai. 2021. High dimensional similarity search with satellite system graph: Efficiency, scalability, and unindexed query compatibility.TPAMI44, 8 (2021), 4139–4150
work page 2021
- [19]
-
[20]
Jianyang Gao and Cheng Long. 2023. High-dimensional approximate nearest neighbor search: with reliable and efficient distance comparison operations. SIGMOD1, 2 (2023), 1–27
work page 2023
-
[21]
Jianyang Gao and Cheng Long. 2024. RaBitQ: quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search. SIGMOD2, 3 (2024), 1–27
work page 2024
-
[22]
Albert Gordo, Jon Almazán, Jerome Revaud, and Diane Larlus. 2016. Deep image retrieval: Learning global representations for image search. InECCV. 241–257
work page 2016
-
[23]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.SIGMOD3, 1 (2025), 1–26
work page 2025
-
[24]
Part Guide. 2011. Intel®64 and ia-32 architectures software developer’s manual. Volume 3B: system programming guide, Part2, 11 (2011), 0–40
work page 2011
-
[25]
Hao Guo and Youyou Lu. 2025. Achieving Low-Latency Graph-Based Vector Search via Aligning Best-First Search Algorithm with SSD. InOSDI. 171–186
work page 2025
-
[26]
Gabriel Haas, Michael Haubenschild, and Viktor Leis. 2020. Exploiting Directly- Attached NVMe Arrays in DBMS.. InCIDR, Vol. 20. 2
work page 2020
-
[27]
Gabriel Haas and Viktor Leis. 2023. What Modern NVMe Storage Can Do, and How to Exploit it: High-Performance I/O for High-Performance Storage Engines. Proc. VLDB Endow.16, 9 (2023), 2090–2102
work page 2023
-
[28]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. InCIKM. 2333–2338
work page 2013
-
[29]
Hugging Face Inc. 2025. Hugging Face Datasets: A Community Library of Natural Language Data.https://huggingface.co/datasets. Accessed: 2025-10-08
work page 2025
-
[30]
IRISA. 2025. Corpus Tex-Mex: Datasets for approximate nearest neighbor search. http://corpus-texmex.irisa.fr/. Accessed: 2025-10-06
work page 2025
-
[31]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.NIPS32 (2019). 14
work page 2019
-
[32]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.TPAMI33, 1 (2010), 117–128
work page 2010
-
[33]
Hervé Jégou, Matthijs Douze, Cordelia Schmid, and Patrick Pérez. 2010. Aggregat- ing local descriptors into a compact image representation. InCVPR. 3304–3311
work page 2010
-
[34]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[35]
Retrieval-augmented generation for knowledge-intensive nlp tasks.NIPS 33 (2020), 9459–9474
work page 2020
-
[36]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2019. Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement.TKDE32, 8 (2019), 1475–1488
work page 2019
-
[37]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data — Experiments, Analyses, and Improvement.TKDE32, 8 (2020), 1475–1488
work page 2020
-
[38]
Wei Ling. 2025. kgraph: A Fast Approximate k-NN Graph Construction Library. https://github.com/aaalgo/kgraph. Accessed: 2025-03-09
work page 2025
-
[39]
Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wil- fred Ng. 2019. SDM: Sequential Deep Matching Model for Online Large-scale Recommender System. InCIKM. 2635–2643
work page 2019
-
[40]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.TPAMI 42, 4 (2018), 824–836
work page 2018
-
[41]
Javier Vargas Munoz, Marcos A Gonçalves, Zanoni Dias, and Ricardo da S Torres
-
[42]
Hierarchical clustering-based graphs for large scale approximate nearest neighbor search.Pattern Recognition96 (2019), 106970
work page 2019
-
[43]
Keiron O’shea and Ryan Nash. 2015. An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Zhen Peng, Minjia Zhang, Kai Li, Ruoming Jin, and Bin Ren. 2023. iQAN: Fast and Accurate Vector Search with Efficient Intra-Query Parallelism on Multi-Core Architectures. InPPoPP. 313–328
work page 2023
-
[45]
Giampaolo Rodolà. 2024. psutil—System and Process Utilities for Python. GitHub repository.https://github.com/giampaolo/psutilAccessed: 2025-10-06
work page 2024
-
[46]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy. InEMNLP. 9248–9274
work page 2023
- [47]
-
[48]
Harsha Vardhan Simhadri, George Williams, Martin Aumüller, Matthijs Douze, Artem Babenko, Dmitry Baranchuk, Qi Chen, Lucas Hosseini, Ravishankar Krish- naswamny, Gopal Srinivasa, et al. 2022. Results of the NeurIPS’21 challenge on billion-scale approximate nearest neighbor search. InNeurIPS 2021 Competitions and Demonstrations Track. 177–189
work page 2022
-
[49]
Bing Tian, Haikun Liu, Yuhang Tang, Shihai Xiao, Zhuohui Duan, Xiaofei Liao, Hai Jin, Xuecang Zhang, Junhua Zhu, and Yu Zhang. 2025. Towards High- throughput and Low-latency Billion-scale Vector Search via CPU/GPU Collabo- rative Filtering and Re-ranking. InFAST. 171–185
work page 2025
-
[50]
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xi- angyu Ke, Yunjun Gao, Xiaoliang Xu, Rentong Guo, and Charles Xie. 2024. Star- ling: An i/o-efficient disk-resident graph index framework for high-dimensional vector similarity search on data segment.SIGMOD2, 1 (2024), 1–27
work page 2024
-
[51]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A com- prehensive survey and experimental comparison of graph-based approximate nearest neighbor search.Proc. VLDB Endow.14, 11 (2021), 1964–1978
work page 2021
-
[52]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures.Commun. ACM 52, 4 (2009), 65–76
work page 2009
-
[53]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.WWW27, 5 (2024), 60
work page 2024
-
[54]
Yahoo Japan Corporation. 2024. NGT: Nearest Neighbor Search with Neighbor- hood Graph and Tree for High-dimensional Data.https://github.com/yahoojapan/ NGT. Accessed: 2025-5-12
work page 2024
-
[55]
Artem Babenko Yandex and Victor Lempitsky. 2016. Efficient Indexing of Billion- Scale Datasets of Deep Descriptors. InCVPR. 2055–2063
work page 2016
-
[56]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. Rankrag: Unifying context ranking with retrieval-augmented generation in llms.NIPS37 (2024), 121156–121184
work page 2024
-
[57]
Minjia Zhang and Yuxiong He. 2019. Grip: Multi-store capacity-optimized high- performance nearest neighbor search for vector search engine. InCIKM. 1673– 1682
work page 2019
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.