MPU: Towards Secure and Privacy-Preserving Knowledge Unlearning for Large Language Models
Pith reviewed 2026-05-15 18:45 UTC · model grok-4.3
Add this Pith Number to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{XAFXD6OC}
Prints a linked pith:XAFXD6OC badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
MPU lets clients unlearn LLM knowledge without exposing the forget set or the original model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
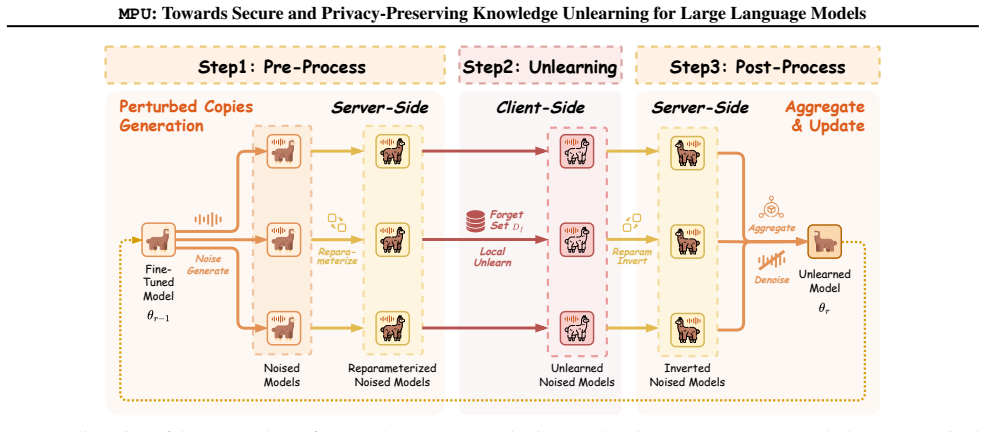
MPU introduces an algorithm-agnostic privacy-preserving framework using Pre-Process for randomized perturbed copy generation and Post-Process for reparameterization inversion and harmonic denoising aggregation, achieving unlearning performance comparable to noise-free baselines with most algorithms showing average degradation well below 1% up to 10% noise.
What carries the argument
Multiple Perturbed Copies Unlearning, which distributes reparameterized perturbed models for local unlearning and aggregates updates via harmonic denoising to counteract perturbation effects.
If this is right
- Unlearning becomes feasible in settings requiring dual non-disclosure of parameters and forget sets.
- The framework works with existing unlearning algorithms without changes.
- Performance remains close to standard methods across noise levels up to 10%.
- Both server and client maintain privacy during the unlearning process.
Where Pith is reading between the lines
- This method could enable regulatory-compliant data removal in deployed LLM services without full retraining.
- It may extend to other privacy-sensitive machine learning tasks involving distributed parties.
- Further analysis under stronger adversarial models could test the robustness of the perturbation scheme.
Load-bearing premise
The harmonic denoising in Post-Process removes perturbation effects without introducing new biases or vulnerabilities not captured in the reported experiments.
What would settle it
Demonstrating that an adversary can recover significant information about the original model or forget set from the distributed perturbed copies would disprove the privacy preservation.
Figures



read the original abstract
Machine unlearning for large language models often faces a privacy dilemma in which strict constraints prohibit sharing either the server's parameters or the client's forget set. To address this dual non-disclosure constraint, we propose MPU, an algorithm-agnostic privacy-preserving Multiple Perturbed Copies Unlearning framework that primarily introduces two server-side modules: Pre-Process for randomized copy generation and Post-Process for update aggregation. In Pre-Process, the server distributes multiple perturbed and reparameterized model instances, allowing the client to execute unlearning locally on its private forget set without accessing the server's exact original parameters. After local unlearning, the server performs Post-Process by inverting the reparameterization and aggregating updates with a harmonic denoising procedure to alleviate the impact of perturbation. Experiments with seven unlearning algorithms show that MPU achieves comparable unlearning performance to noise-free baselines, with most algorithms' average degradation well below 1% up to 10% noise, and can even outperform the noise-free baseline for some algorithms under 1% noise. Code is available at https://github.com/Tristan0318/MPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MPU, an algorithm-agnostic framework for privacy-preserving knowledge unlearning in LLMs under dual non-disclosure constraints. It introduces server-side Pre-Process to generate and distribute multiple perturbed and reparameterized model copies, allowing clients to perform local unlearning on private forget sets, followed by Post-Process inversion and harmonic denoising aggregation of updates. Experiments across seven unlearning algorithms report that MPU achieves comparable performance to noise-free baselines, with most algorithms showing average degradation well below 1% for noise levels up to 10% and occasional outperformance at 1% noise.
Significance. If the Post-Process harmonic denoising reliably recovers unlearning performance without residual bias or new vulnerabilities, MPU offers a practical solution to the privacy dilemma in LLM unlearning. The algorithm-agnostic design and public code release at https://github.com/Tristan0318/MPU are notable strengths that could facilitate adoption in secure distributed settings.
major comments (2)
- [Post-Process] Post-Process section: the central claim of degradation below 1% up to 10% noise (and occasional outperformance at 1% noise) rests on the harmonic denoising procedure inverting reparameterized perturbations. This implicitly assumes additive, linearly invertible noise, yet LLM unlearning gradients are highly non-linear and context-dependent; no ablation isolating the denoising operator, no comparison to alternatives such as median or trimmed-mean aggregation, and no formal residual-error bound are provided.
- [Experiments] Experiments section: the reported performance numbers lack error bars, details on statistical significance testing, exact noise distributions, or evaluation under stronger adversarial attacks that would expose potential forget-set leakage after denoising. These omissions directly affect confidence in the comparability claim versus noise-free baselines.
minor comments (1)
- [Abstract] The abstract and experiments description would benefit from explicit notation for the reparameterization function and the precise form of the harmonic denoising operator.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Post-Process] Post-Process section: the central claim of degradation below 1% up to 10% noise (and occasional outperformance at 1% noise) rests on the harmonic denoising procedure inverting reparameterized perturbations. This implicitly assumes additive, linearly invertible noise, yet LLM unlearning gradients are highly non-linear and context-dependent; no ablation isolating the denoising operator, no comparison to alternatives such as median or trimmed-mean aggregation, and no formal residual-error bound are provided.
Authors: We thank the referee for this observation. The reparameterization step is constructed to permit exact inversion of the added perturbations before aggregation, and the harmonic denoising is applied to the inverted updates to reduce variance. We acknowledge that unlearning gradients are non-linear and that no formal residual-error bound is derived. In the revised manuscript we will add an ablation isolating the denoising operator and direct comparisons against median and trimmed-mean aggregation. We will also expand the discussion to clarify the invertibility assumptions and note that a tight theoretical bound for arbitrary non-linear unlearning updates lies beyond the present scope; the empirical results across seven algorithms nevertheless demonstrate consistent recovery of unlearning performance. revision: partial
-
Referee: [Experiments] Experiments section: the reported performance numbers lack error bars, details on statistical significance testing, exact noise distributions, or evaluation under stronger adversarial attacks that would expose potential forget-set leakage after denoising. These omissions directly affect confidence in the comparability claim versus noise-free baselines.
Authors: We agree that these details strengthen reproducibility and confidence. The revised Experiments section will report means with standard deviations computed over multiple independent runs, include results of paired statistical significance tests against the noise-free baselines, and explicitly state the noise distribution (zero-mean Gaussian scaled to the reported percentage of model parameter magnitude). We will also add a paragraph discussing potential leakage risks under stronger adversarial attacks and, space permitting, include preliminary results; otherwise we will list this evaluation as an important direction for future work. revision: partial
- Deriving a formal residual-error bound for harmonic denoising under non-linear, context-dependent unlearning gradients
- Full evaluation under stronger adversarial attacks targeting post-denoising forget-set leakage
Circularity Check
No significant circularity: MPU is a procedural framework validated by direct experiments
full rationale
The paper defines MPU as an algorithm-agnostic framework with explicit Pre-Process (randomized perturbed copy generation) and Post-Process (reparameterization inversion plus harmonic denoising) modules. All performance claims, including degradation below 1% up to 10% noise and occasional outperformance at 1% noise, are obtained from empirical runs on seven unlearning algorithms rather than any equation or parameter fit that reduces to the input data by construction. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, or ansatzes smuggled via prior work appear in the derivation chain; the framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise level
axioms (1)
- domain assumption Perturbed model copies remain sufficiently close to the original for unlearning algorithms to transfer effectively after aggregation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
harmonic aggregation ... Pm α_k^{-1} bΔ(k,r) / Pm α_k^{-1} ... first-order error term introduced by noise ... zero-sum constraint
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the properties of neural machine translation: Encoder -- decoder approaches
Association for Computa- tional Linguistics. doi: 10.3115/v1/W14-4012. URL https://aclanthology.org/W14-4012/. Dong, Y . R., Lin, H., Belkin, M., Huerta, R., and Vuli´c, I. Undial: Self-distillation with adjusted logits for robust unlearning in large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associ...
-
[2]
Dorna, V ., Mekala, A., Zhao, W., McCallum, A., Lipton, Z. C., Kolter, J. Z., and Maini, P. OpenUnlearning: Ac- celerating LLM unlearning via unified benchmarking of methods and metrics.arXiv preprint arXiv:2506.12618,
-
[3]
Fan, C., Liu, J., Lin, L., Jia, J., Zhang, R., Mei, S., and Liu, S. Simplicity prevails: Rethinking negative pref- erence optimization for llm unlearning.arXiv preprint arXiv:2410.07163,
-
[4]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jin, X., Bu, Z., Vinzamuri, B., Ramakrishna, A., Chang, K.- W., Cevher, V ., and Hong, M. Unlearning as multi-task optimization: A normalized gradient difference approach with an adaptive learning rate. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies ...
work page 2025
-
[6]
arXiv preprint arXiv:2012.13891 , year=
Liu, B., Liu, Q., and Stone, P. Continual learning and private unlearning. InConference on Lifelong Learning Agents, pp. 243–254. PMLR, 2022a. Liu, G., Ma, X., Yang, Y ., Wang, C., and Liu, J. Federated unlearning.arXiv preprint arXiv:2012.13891,
-
[7]
TOFU: A Task of Fictitious Unlearning for LLMs
Liu, Y ., Xu, L., Yuan, X., Wang, C., and Li, B. The right to be forgotten in federated learning: An efficient realization with rapid retraining. InIEEE INFOCOM 2022-IEEE conference on computer communications, pp. 1749–1758. IEEE, 2022b. Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z. C., and Kolter, J. Z. Tofu: A task of fictitious unlearning for llms...
work page internal anchor Pith review arXiv 2022
-
[8]
Multi-objective large language model unlearning
Pan, Z., Zhang, S., Zheng, Y ., Li, C., Cheng, Y ., and Zhao, J. Multi-objective large language model unlearning. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
work page 2025
-
[9]
A survey on unlearning in large language models.arXiv preprint arXiv:2510.25117,
Qiu, R., Tan, J., Pu, J., Wang, H., Gao, X.-S., and Sun, F. A survey on unlearning in large language models.arXiv preprint arXiv:2510.25117,
-
[10]
F., Qiu, X., Kurmanji, M., Iacob, A., Sani, L., Chen, Y ., Cancedda, N., and Lane, N
Shen, W. F., Qiu, X., Kurmanji, M., Iacob, A., Sani, L., Chen, Y ., Cancedda, N., and Lane, N. D. Lunar: Llm un- learning via neural activation redirection.arXiv preprint arXiv:2502.07218,
-
[11]
Wang, B., Zi, Y ., Sun, Y ., Zhao, Y ., and Qin, B. Balancing forget quality and model utility: A reverse kl-divergence knowledge distillation approach for better unlearning in llms. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long ...
work page 2025
-
[12]
Y ., Pang, J., Liu, Q., Shah, A
Wang, Y ., Wei, J., Liu, C. Y ., Pang, J., Liu, Q., Shah, A. P., Bao, Y ., Liu, Y ., and Wei, W. LLM unlearning via loss adjustment with only forget data.arXiv preprint arXiv:2410.11143,
-
[13]
Exploring criteria of loss reweighting to enhance llm unlearning,
Yang, P., Wang, Q., Huang, Z., Liu, T., Zhang, C., and Han, B. Exploring criteria of loss reweighting to enhance llm unlearning.arXiv preprint arXiv:2505.11953,
- [14]
-
[15]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Zhang, R., Lin, L., Bai, Y ., and Mei, S. Negative preference optimization: From catastrophic collapse to effective un- learning.arXiv preprint arXiv:2404.05868,
work page internal anchor Pith review arXiv
-
[16]
Zhou, Y ., Song, L., Wang, B., and Chen, W. Metagpt: Merging large language models using model exclusive task arithmetic.arXiv preprint arXiv:2406.11385, 2024a. 10 MPU: Towards Secure and Privacy-Preserving Knowledge Unlearning for Large Language Models Zhou, Z., Chen, Z., Chen, Y ., Zhang, B., and Yan, J. On the emergence of cross-task linearity in the p...
-
[17]
Under the same local linearization used in Sec
Linear Response ModelFix an anchor point θ (e.g., θ=θ r−1) and write the perturbation as u. Under the same local linearization used in Sec. 3.4, ∆(θ+u) = ∆ ⋆(θ) +J u+ρ(u),∥ρ(u)∥ ≤ LJ 2 ∥u∥2.(71) A.5.1. ONE-ROUNDCOMPARISON: BIAS ANDVARIANCE FROMINJECTEDNOISE Noise-Only Baseline ErrorSubstituting the linear response into Eq. (70) yields θNO r =θ+η srv ∆⋆(θ)...
work page 2024
-
[18]
Prompt: Llama-3.2 Series Template System Prompt: You are a helpful assistant. System Prompt with Special Tokens:<|begin of text|><|start header id|> system<|end header id|>\n\nYou are a helpful assistant.<|eot id|> User Start Tag:<|start header id|>user<|end header id|>\n\n User End Tag:<|eot id|> Asst Start Tag:<|start header id|>assistant<|end header id...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.