Recognition: no theorem link
WebChain: A Large-Scale Human-Annotated Dataset of Real-World Web Interaction Traces
Pith reviewed 2026-05-15 16:29 UTC · model grok-4.3
The pith
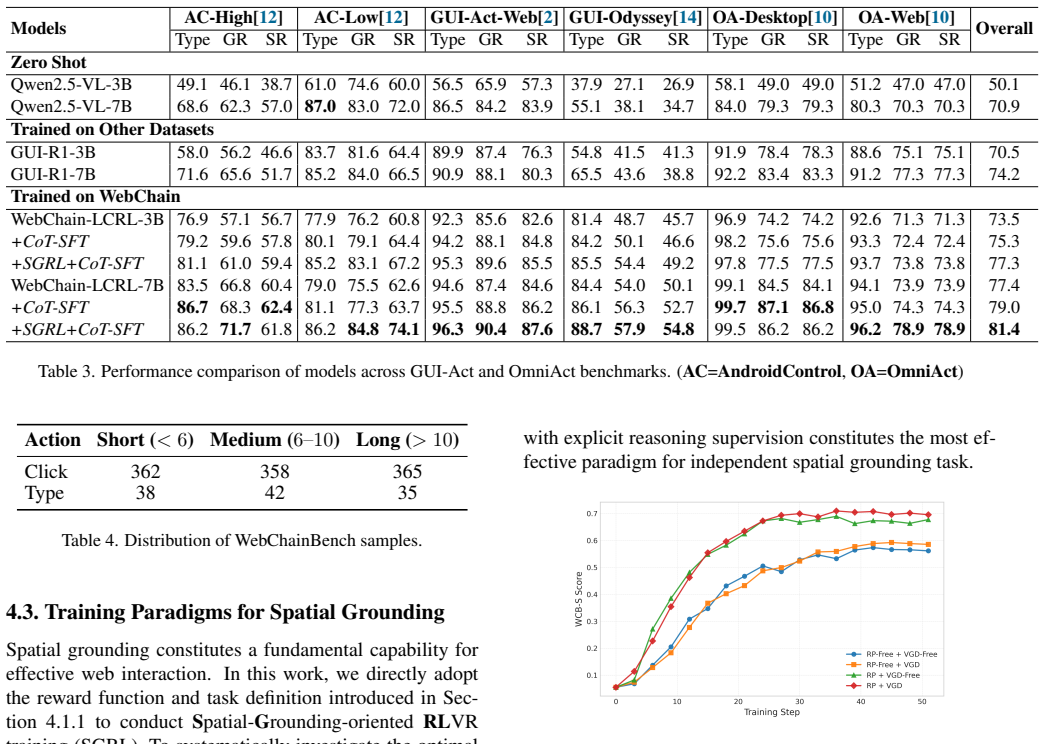
A dataset of 31,725 human-annotated web trajectories enables a dual mid-training method that decouples spatial grounding from planning and reaches state-of-the-art results on web agent benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WebChain supplies 31,725 human-annotated trajectories on real-world websites with triple alignment of visual, structural, and action data collected through a scalable pipeline. A Dual Mid-Training recipe that decouples spatial grounding from planning, when trained on this dataset, achieves state-of-the-art performance on WebChainBench and other public GUI benchmarks.
What carries the argument
The Dual Mid-Training recipe that separates spatial grounding from planning while using the triple-aligned trajectories from WebChain for supervision.
If this is right
- Web agents trained this way can handle more complex tasks on live sites than those trained on synthetic data alone.
- The dataset supports reproducible research and evaluation for web agents.
- Decoupling spatial grounding from planning improves results on both the new benchmark and standard GUI tests.
- Scalable human annotation pipelines can capture high-value tasks that synthetic generation misses.
Where Pith is reading between the lines
- The same separation of grounding and planning steps could be tested in related agent settings such as mobile interfaces.
- Triple-aligned multi-modal data might become a standard format for training interactive agents beyond the web.
- Extending the pipeline to additional sites could reveal whether performance gains hold without proportional increases in annotation effort.
Load-bearing premise
The human-annotated trajectories collected via the scalable pipeline are representative of complex real-world tasks and free of annotation biases that would limit generalization to new websites.
What would settle it
Evaluating the trained agent on a fresh collection of diverse, previously unseen websites and observing no performance gain over earlier methods would falsify the central performance claim.
Figures




read the original abstract
We introduce WebChain, the largest open-source dataset of human-annotated trajectories on real-world websites, designed to accelerate reproducible research in web agents. It contains 31,725 trajectories and 318k steps, featuring a core Triple Alignment of visual, structural, and action data to provide rich, multi-modal supervision. The data is collected via a scalable pipeline that ensures coverage of complex, high-value tasks often missed by synthetic methods. Leveraging this dataset, we propose a Dual Mid-Training recipe that decouples spatial grounding from planning, achieving state-of-the-art performance on our proposed WebChainBench and other public GUI benchmarks. Our work provides the data and insights necessary to build and rigorously evaluate the next generation of scalable web agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebChain, the largest open-source dataset of 31,725 human-annotated real-world web interaction trajectories comprising 318k steps with a core Triple Alignment of visual, structural, and action data collected via a scalable pipeline. It proposes a Dual Mid-Training recipe that decouples spatial grounding from planning and claims state-of-the-art performance on the self-proposed WebChainBench as well as other public GUI benchmarks.
Significance. If the dataset is shown to be representative of complex tasks and the training recipe generalizes, the work could accelerate reproducible research on web agents by supplying rich multi-modal supervision for tasks often missed by synthetic data.
major comments (3)
- [Abstract] Abstract: the SOTA performance claim on WebChainBench is presented without error bars, ablation studies, or baseline comparisons, preventing verification of the Dual Mid-Training recipe's contribution.
- [Evaluation] Evaluation: WebChainBench is derived from the same dataset and pipeline, creating a circular evaluation loop; no independent external benchmarks or explicitly described held-out test sets are provided to support the generalization claims.
- [Data Collection] Data Collection: the assertion that the scalable pipeline covers complex, high-value tasks missed by synthetic methods lacks quantitative support such as task-type histograms or domain coverage metrics compared against external real-world usage logs.
minor comments (1)
- [Abstract] Abstract: full data statistics, collection pipeline details, and methods are stated as unavailable, which limits immediate reproducibility assessment.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and recommendations for major revision. We address each of the major comments below, indicating the changes made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA performance claim on WebChainBench is presented without error bars, ablation studies, or baseline comparisons, preventing verification of the Dual Mid-Training recipe's contribution.
Authors: We agree that the abstract's claim requires supporting evidence for clarity. In the revised manuscript, we have updated the abstract to reference the detailed results in Section 4, where we now include error bars, ablation studies isolating the Dual Mid-Training components, and comparisons to baselines such as standard fine-tuning and other mid-training approaches. This allows readers to verify the contribution. revision: yes
-
Referee: [Evaluation] Evaluation: WebChainBench is derived from the same dataset and pipeline, creating a circular evaluation loop; no independent external benchmarks or explicitly described held-out test sets are provided to support the generalization claims.
Authors: We acknowledge the concern regarding potential circularity. We have revised Section 3.4 to explicitly describe the held-out test set construction, ensuring it is disjoint from the training trajectories. Furthermore, we report performance on independent external benchmarks including Mind2Web and WebArena, which are not derived from our pipeline, to support the generalization claims of the Dual Mid-Training recipe. revision: yes
-
Referee: [Data Collection] Data Collection: the assertion that the scalable pipeline covers complex, high-value tasks missed by synthetic methods lacks quantitative support such as task-type histograms or domain coverage metrics compared against external real-world usage logs.
Authors: We have added quantitative analyses to the revised manuscript. Specifically, we include task-type histograms in Figure 2 and domain coverage metrics in a new Table 2, comparing the distribution of tasks in WebChain against available public web interaction logs. While direct access to proprietary real-world usage logs is not feasible, these additions provide empirical support for the coverage of complex tasks. revision: partial
Circularity Check
WebChainBench performance claim reduces to in-distribution evaluation on the training dataset
specific steps
-
fitted input called prediction
[Abstract]
"Leveraging this dataset, we propose a Dual Mid-Training recipe that decouples spatial grounding from planning, achieving state-of-the-art performance on our proposed WebChainBench and other public GUI benchmarks."
WebChainBench is constructed from the identical human-annotated trajectories and scalable pipeline as the WebChain training dataset. Reporting SOTA performance on it after training on the source data makes the result a direct consequence of the input distribution rather than an independent prediction or generalization test.
full rationale
The paper introduces WebChain dataset and proposes WebChainBench from the same collection pipeline. The Dual Mid-Training recipe is trained on WebChain trajectories and then evaluated for SOTA on WebChainBench. This creates a fitted-input-called-prediction pattern because the benchmark is not an independent external test set; success on it is expected by construction when the model is optimized on the source data. The claim is partially mitigated by also reporting results on public GUI benchmarks, but the central SOTA assertion on the proposed benchmark lacks described held-out splits or external validation, producing moderate circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Guicourse: From general vision language model to versatile gui agent
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. Guicourse: From general vision language model to versatile gui agent. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21936–21959, 2025. 7
work page 2025
-
[3]
Seeclick: Har- nessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Har- nessing gui grounding for advanced visual gui agents. In Proceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024. 3
work page 2024
-
[4]
Rico: A mobile app dataset for building data- driven design applications
Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hib- schman, Daniel Afergan, Yang Li, Jeffrey Nichols, and Ran- jitha Kumar. Rico: A mobile app dataset for building data- driven design applications. InProceedings of the 30th annual ACM symposium on user interface software and technology, pages 845–854, 2017. 2
work page 2017
-
[5]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023. 1, 2, 3
work page 2023
-
[6]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Izzeddin Gur, Ulrich Rueckert, Aleksandra Faust, and Dilek Hakkani-Tur. Learning to navigate the web.arXiv preprint arXiv:1812.09195, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281– 14290, 2024. 1, 3
work page 2024
-
[9]
A data-driven approach for learning to control computers
Peter C Humphreys, David Raposo, Tobias Pohlen, Gregory Thornton, Rachita Chhaparia, Alistair Muldal, Josh Abram- son, Petko Georgiev, Adam Santoro, and Timothy Lillicrap. A data-driven approach for learning to control computers. InInternational Conference on Machine Learning, pages 9466–9482. PMLR, 2022. 3
work page 2022
-
[10]
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem AlShikh, and Ruslan Salakhut- dinov. Omniact: A dataset and benchmark for enabling mul- timodal generalist autonomous agents for desktop and web. InEuropean Conference on Computer Vision, pages 161–
-
[11]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024. 2
work page 2024
-
[12]
On the effects of data scale on computer control agents.arXiv e-prints, pages arXiv–2406, 2024
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on computer control agents.arXiv e-prints, pages arXiv–2406, 2024. 7
work page 2024
-
[13]
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web in- terfaces using workflow-guided exploration.arXiv preprint arXiv:1802.08802, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices
Quanfeng Lu, Wenqi Shao, Zitao Liu, Lingxiao Du, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, and Ping Luo. Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 22404–22414, 2025. 7
work page 2025
-
[15]
Xing Han L `u, Zden ˇek Kasner, and Siva Reddy. We- blinx: Real-world website navigation with multi-turn dia- logue.arXiv preprint arXiv:2402.05930, 2024. 1, 2
-
[16]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision- language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 3
work page 2022
-
[18]
Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents
Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, and Ahmed Has- san. Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 6300–6323, 2025. 1, 2
work page 2025
-
[19]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shi- jue Huang, et al. Ui-tars: Pioneering automated gui inter- action with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OS-genesis: Automating GUI agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Li- heng Chen, Zhoumianze Liu, Ben Kao, Guohao Li, Junxian He, Yu Qiao, and Zhiyong Wu. OS-genesis: Automating GUI agent trajectory construction via reverse task synthesis. InProceedings of the 63rd Annual Meeting of the Associ- ation for Computational Li...
work page 2025
-
[21]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shi- hao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[24]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web en- vironment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.