Recognition: 3 theorem links
· Lean TheoremNePPO: Near-Potential Policy Optimization for General-Sum Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-15 15:23 UTC · model grok-4.3
The pith
NePPO learns a player-independent potential function whose induced cooperative Nash equilibrium approximates the original general-sum game's equilibrium.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that minimizing a novel MARL objective produces the best player-independent potential function candidate, and that the Nash equilibrium of the induced cooperative game with this potential approximates a Nash equilibrium of the original general-sum game. An algorithmic pipeline using zeroth-order gradient descent then returns the corresponding approximate Nash equilibrium policy.
What carries the argument
The player-independent potential function that becomes the common utility in the induced cooperative game.
Load-bearing premise
A player-independent potential function exists whose Nash equilibrium in the induced cooperative game is close enough to a Nash equilibrium of the original general-sum game.
What would settle it
Apply NePPO to a small known general-sum game with an analytically computable Nash equilibrium and measure whether the returned policies satisfy the Nash condition to within a small tolerance.
Figures
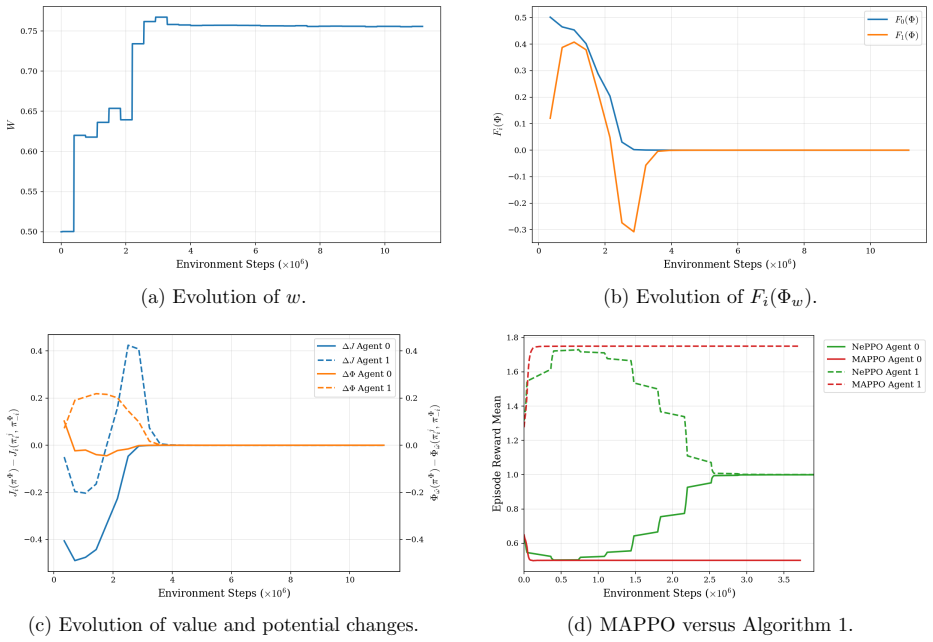

read the original abstract
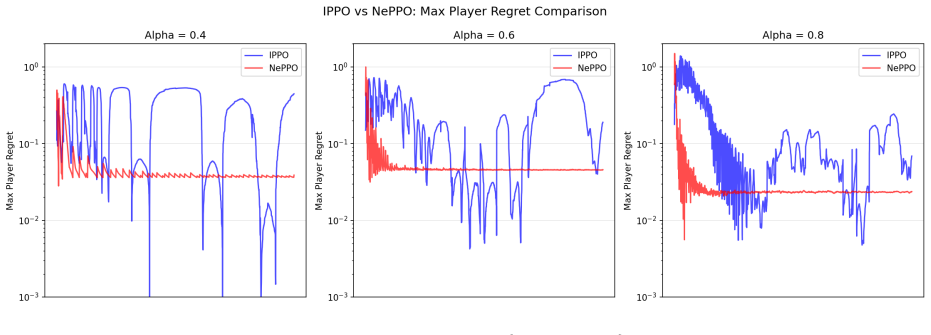
Multi-agent reinforcement learning (MARL) is increasingly used to design learning-enabled agents that interact in shared environments. However, training MARL algorithms in general-sum games remains challenging: learning dynamics can become unstable, and convergence guarantees typically hold only in restricted settings such as two-player zero-sum or fully cooperative games. Moreover, when agents have heterogeneous and potentially conflicting preferences, it is unclear what system-level objective should guide learning. In this paper, we propose a new MARL pipeline called Near-Potential Policy Optimization (NePPO) for computing approximate Nash equilibria in mixed cooperative--competitive environments. The core idea is to learn a player-independent potential function such that the Nash equilibrium of a cooperative game with this potential as the common utility approximates a Nash equilibrium of the original game. To this end, we introduce a novel MARL objective such that minimizing this objective yields the best possible potential function candidate and consequently an approximate Nash equilibrium of the original game. We develop an algorithmic pipeline that minimizes this objective using zeroth-order gradient descent and returns an approximate Nash equilibrium policy. We empirically show the superior performance of this approach compared to popular baselines such as IPPO and MAPPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NePPO, a MARL pipeline for approximate Nash equilibria in general-sum settings. It learns a player-independent potential function φ by minimizing a novel objective via zeroth-order gradient descent; the Nash equilibrium of the induced cooperative game (with common reward φ) is then returned as an approximate equilibrium of the original game. Empirical results claim superiority over IPPO and MAPPO baselines.
Significance. If the central reduction holds, the approach would provide a practical route to stabilize learning in mixed cooperative-competitive environments by leveraging potential-game structure, extending beyond the restricted settings where current MARL convergence guarantees apply. The use of zeroth-order optimization for the potential-learning objective is a distinctive technical element.
major comments (2)
- [Abstract / Core construction] The abstract states that minimizing the novel objective 'yields the best possible potential function candidate and consequently an approximate Nash equilibrium,' but supplies neither a derivation of the objective nor any explicit bound relating its value to NE approximation error (e.g., exploitability or payoff distance) in the original general-sum game. This relation is load-bearing for the central claim.
- [Algorithmic pipeline] No convergence argument is provided for the zeroth-order gradient descent procedure on the novel objective, nor for the resulting policy being close to equilibrium in the original game. Without such analysis the pipeline's correctness cannot be verified.
minor comments (1)
- [Experiments] The abstract asserts empirical superiority over IPPO and MAPPO but omits any description of environments, evaluation metrics, number of runs, or statistical tests; these details must be supplied with tables or figures in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of our approach to stabilize learning in mixed cooperative-competitive MARL environments. We address each major comment below and will make targeted revisions to improve clarity and rigor where possible.
read point-by-point responses
-
Referee: [Abstract / Core construction] The abstract states that minimizing the novel objective 'yields the best possible potential function candidate and consequently an approximate Nash equilibrium,' but supplies neither a derivation of the objective nor any explicit bound relating its value to NE approximation error (e.g., exploitability or payoff distance) in the original general-sum game. This relation is load-bearing for the central claim.
Authors: We acknowledge that the abstract is concise and omits the derivation details. Section 3 derives the objective by minimizing the L2 discrepancy between each agent's individual reward and a shared player-independent potential function, which is motivated by the exact potential-game condition that the change in potential equals the change in individual utility. This construction ensures that any NE of the induced cooperative game is an approximate NE of the original game, with the quality depending on how well the potential approximates the incentives. We agree that no explicit bound (e.g., on exploitability) is derived. The claim rests on the potential-game reduction plus empirical validation. We will revise the abstract to briefly reference the derivation and add a discussion paragraph on approximation quality and its limitations. revision: partial
-
Referee: [Algorithmic pipeline] No convergence argument is provided for the zeroth-order gradient descent procedure on the novel objective, nor for the resulting policy being close to equilibrium in the original game. Without such analysis the pipeline's correctness cannot be verified.
Authors: The objective is non-differentiable due to the inner maximization over policies, so we apply zeroth-order gradient descent. We will add a remark citing standard ZO convergence results (e.g., Nesterov & Spokoiny 2017) that guarantee convergence to stationary points under Lipschitz and smoothness assumptions on the objective. Once the potential is obtained, the cooperative game is solved with MAPPO, whose convergence properties in cooperative settings are established in the literature. The link back to the original game's NE follows from the potential-game approximation rather than a direct proof. We will clarify this structure and the heuristic nature of the overall guarantee in a new subsection. revision: partial
Circularity Check
No significant circularity; novel objective defined independently of its minimizer
full rationale
The paper introduces a new MARL objective whose explicit form is not shown to be defined in terms of the resulting potential or its induced NE (no self-definitional reduction or fitted-input-called-prediction). The pipeline uses zeroth-order gradient descent on this objective to obtain the potential, then computes the cooperative NE; this separation is maintained without load-bearing self-citation chains or ansatz smuggling. The central claim that the minimizer yields an approximate NE rests on the design of the objective rather than tautological equivalence to inputs. No equations reduce the output to a renaming or prior self-result by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
We introduce a novel MARL objective such that minimizing this objective yields the best possible potential function candidate and consequently an approximate Nash equilibrium of the original game. ... Fi(Φ) = Φ(π*,Φ) − Φ(π*,Ji , π*,Φ−i) − (Ji(π*,Φ) − Ji(π*,Ji , π*,Φ−i)) ... Theorem 3.1: if max_i Fi(Φ) ≤ α then π*,Φ is an α-Nash equilibrium.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
A function Φ : Π → R is a Markov near-potential function (MNPF) ... |Ji(π′i, π−i) − Ji(πi, π−i) − (Φ(π′i, π−i) − Φ(πi, π−i))| ≤ α
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery / J-uniqueness echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Proposition 3.2: If a game G is a Markov potential game with potential function Φ, then Fi(Φ) = 0 for all i ... there exist games that are not potential games, but there exists Φ such that Fi(Φ) = 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Emergent tool use from multi-agent interaction.arXiv preprint arXiv:1909.07528,
Bowen Baker, Ingmar Kanitscheider, Todd Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. Emergent tool use from multi-agent interaction.arXiv preprint arXiv:1909.07528,
-
[2]
Dota 2 with Large Scale Deep Reinforcement Learning
13 Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemys law Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[3]
Online convex optimization in the bandit setting: gradient descent without a gradient
doi: 10.1137/070699652. Abraham D Flaxman, Adam Tauman Kalai, and H Brendan McMahan. Online convex optimization in the bandit setting: gradient descent without a gradient.arXiv preprint cs/0408007,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1137/070699652
-
[4]
Anα-potential game framework forn-player dynamic games
Xin Guo, Xinyu Li, and Yufei Zhang. Anα-potential game framework forn-player dynamic games. arXiv preprint arXiv:2403.16962,
-
[5]
Distributed games with jumps: An $\alpha$-potential game approach
Xin Guo, Xinyu Li, Chinmay Maheshwari, Shankar Sastry, and Manxi Wu. Markovα-potential games.IEEE Transactions on Automatic Control, 2025a. Xin Guo, Xinyu Li, and Yufei Zhang. Distributed games with jumps: Anα-potential game ap- proach.arXiv preprint arXiv:2508.01929, 2025b. Xin Guo, Xun Li, and Liangquan Zhang. Bsde approach forα-potential stochastic dif...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Addison Kalanther, Daniel Bostwick, Chinmay Maheshwari, and Shankar Sastry. Evader- agnostic team-based pursuit strategies in partially-observable environments.arXiv preprint arXiv:2511.05812,
-
[7]
Stefanos Leonardos, Will Overman, Ioannis Panageas, and Georgios Piliouras. Global convergence of multi-agent policy gradient in markov potential games.arXiv preprint arXiv:2106.01969,
-
[8]
Multi-agent guided policy search for non-cooperative dynamic games.arXiv preprint arXiv:2509.24226,
Jingqi Li, Gechen Qu, Jason J Choi, Somayeh Sojoudi, and Claire Tomlin. Multi-agent guided policy search for non-cooperative dynamic games.arXiv preprint arXiv:2509.24226,
-
[9]
Fanqi Lin, Shiyu Huang, Tim Pearce, Wenze Chen, and Wei-Wei Tu. Tizero: Mastering multi-agent football with curriculum learning and self-play.arXiv preprint arXiv:2302.07515,
-
[10]
Chinmay Maheshwari, Chinmay Pimpalkhare, and Debasish Chatterjee. Exotic: An exact, opti- mistic, tree-based algorithm for min-max optimization.arXiv preprint arXiv:2508.12479,
-
[11]
Anytime psro for two-player zero-sum games.arXiv preprint arXiv:2201.07700,
Stephen McAleer, Kevin Wang, John Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox. Anytime psro for two-player zero-sum games.arXiv preprint arXiv:2201.07700,
-
[12]
Jonathan Schaeffer, Joseph Culberson, Norman Treloar, Brent Knight, Paul Lu, and Duane Szafron
doi: 10.1006/game.1996.0044. Jonathan Schaeffer, Joseph Culberson, Norman Treloar, Brent Knight, Paul Lu, and Duane Szafron. A world championship caliber checkers program.Artificial Intelligence, 53(2-3):273–289,
-
[13]
Proximal Policy Optimization Algorithms
15 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving
Shai Shalev-Shwartz, Shaked Shammah, and Amnon Shashua. Safe, multi-agent, reinforcement learning for autonomous driving.arXiv preprint arXiv:1610.03295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Solving Large Imperfect Information Games Using CFR+
Oskari Tammelin. Solving large imperfect information games using cfr+.arXiv preprint arXiv:1407.5042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Terry, Benjamin Black, Ananth Jayakumar, Aniket Hari, Lucas Santos, Clemens Dief- fendahl, Niall L
Jordan K. Terry, Benjamin Black, Ananth Jayakumar, Aniket Hari, Lucas Santos, Clemens Dief- fendahl, Niall L. Williams, Yashasvi Lokesh, Ryan Sullivan, et al. Pettingzoo: Gym for multi- agent reinforcement learning.arXiv preprint arXiv:2009.14471, 2020a. Justin K Terry, Nathaniel Grammel, Sanghyun Son, Benjamin Black, and Aakriti Agrawal. Revisiting param...
-
[17]
Zelai Xu, Yancheng Liang, Chao Yu, Yu Wang, and Yi Wu. Fictitious cross-play: Learning global nash equilibrium in mixed cooperative-competitive games.arXiv preprint arXiv:2310.03354,
-
[18]
A survey on self-play methods in reinforcement learning
Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Wenhao Tang, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, et al. A survey on self-play methods in reinforcement learning. arXiv preprint arXiv:2408.01072,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.