Recognition: no theorem link
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Pith reviewed 2026-05-15 09:45 UTC · model grok-4.3
The pith
Simulation Distillation pretrains world models in simulation so that only the latent dynamics need updating for fast real-world robot adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
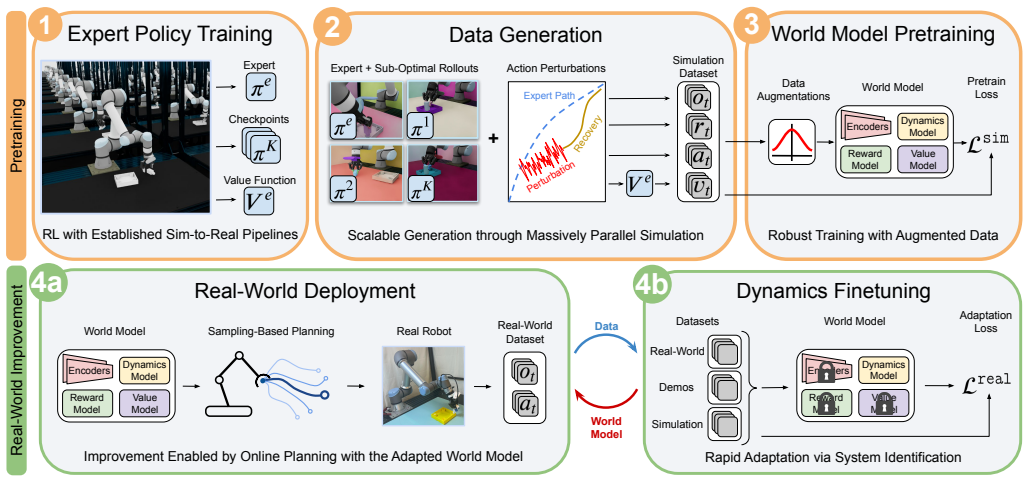
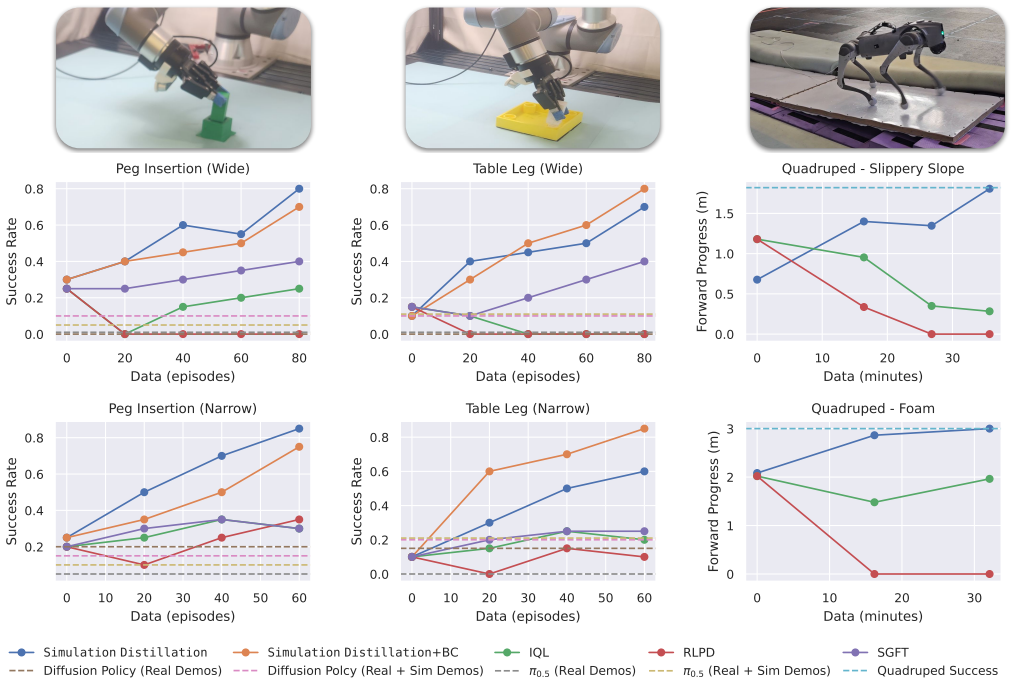
By distilling priors from simulators into a world model, SimDist allows the encoder, reward model, and value function to transfer directly from simulation to real observations. Only the latent dynamics are updated online with prediction losses on real data. This preserves planning signals for counterfactual reasoning and leads to rapid performance gains across tasks, unlike prior adaptation approaches that struggle or degrade.
What carries the argument
The transferred encoder, reward model, and value function combined with an adaptable latent dynamics model updated solely via real-world prediction losses.
If this is right
- World models can be adapted to real robots by supervised updates to dynamics only.
- Online planning becomes feasible with limited real-world experience in long-horizon tasks.
- Contact-rich manipulation and locomotion improve rapidly during real-world finetuning.
- Prior methods that update more components tend to degrade rather than improve.
Where Pith is reading between the lines
- Extending the approach to tasks with larger visual domain gaps might require partial encoder updates.
- Similar distillation could apply to other model-based methods beyond world models.
- Testing on more diverse real-world scenarios would show if prediction losses alone suffice broadly.
Load-bearing premise
The components pretrained in simulation, specifically the encoder, reward model, and value function, stay effective on real-world observations without any retraining.
What would settle it
Observing that real-world performance stops improving or worsens after several adaptation episodes when only the latent dynamics are updated, while methods that update the full model succeed.
Figures






read the original abstract
Robot learning requires adaptation methods that improve reliably from limited, mixed-quality interaction data. This is especially challenging in long-horizon, contact-rich tasks, where end-to-end policy finetuning remains inefficient and brittle. World models offer a compelling alternative: by predicting the outcomes of candidate action sequences, they enable online planning through counterfactual reasoning. However, training action-conditioned robotic world models directly in the real world requires diverse data at impractical scale. We introduce Simulation Distillation (SimDist), a framework that uses physics simulators as a scalable source of action-conditioned robot experience. During pretraining, SimDist distills structural priors from the simulator into a world model that enables planning from raw real-world observations. During real-world adaptation, SimDist transfers the encoder, reward model, and value function learned in simulation, and updates only the latent dynamics model using real-world prediction losses. This reduces adaptation to supervised system identification while preserving dense, long-horizon planning signals for online improvement. Across contact-rich manipulation and quadruped locomotion tasks, SimDist rapidly improves with experience, while prior adaptation methods struggle to make progress or degrade during online finetuning. Project website and code: https://sim-dist.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Simulation Distillation (SimDist), a framework that pretrains an action-conditioned world model in physics simulation to distill structural priors, then transfers the encoder, reward model, and value function to the real world while updating only the latent dynamics model via supervised prediction losses on real interaction data. This is claimed to enable rapid online improvement via planning in long-horizon contact-rich tasks such as manipulation and quadruped locomotion, outperforming prior adaptation methods that struggle or degrade.
Significance. If the empirical claims hold with rigorous validation, the approach could meaningfully advance sim-to-real transfer for model-based planning by reducing adaptation to system identification while retaining dense planning signals. This addresses data-efficiency bottlenecks in contact-rich robotics where end-to-end finetuning is brittle.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The central claim of rapid improvement across tasks while prior methods struggle or degrade is stated without any quantitative metrics, error bars, ablation studies, baseline comparisons, or experimental protocols. This prevents assessment of whether the data support the superiority assertion.
- [Method] Method description (adaptation phase): The load-bearing assumption that the fixed sim-pretrained encoder, reward model, and value function produce usable signals on real observations without retraining is not supported by described ablations or transfer-success metrics. In contact-rich regimes, sim-to-real gaps in perception or contact dynamics typically invalidate such fixed components, yet only latent dynamics are updated.
- [Adaptation and Planning] Adaptation and planning description: The assertion that real-world prediction losses alone suffice to adapt the latent dynamics for successful long-horizon planning assumes the transferred reward/value remain aligned with real outcomes. No concrete test (e.g., planning success with frozen vs. adapted components) is reported to address the risk of optimizing against misaligned objectives.
minor comments (1)
- [Abstract] The provision of a project website and code link is a positive step toward reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas to strengthen the clarity and rigor of our empirical claims. We address each major comment below and will incorporate revisions to provide additional quantitative support, ablations, and validation experiments.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim of rapid improvement across tasks while prior methods struggle or degrade is stated without any quantitative metrics, error bars, ablation studies, baseline comparisons, or experimental protocols. This prevents assessment of whether the data support the superiority assertion.
Authors: The Experiments section reports results via performance curves with error bars across tasks, including direct comparisons to prior adaptation baselines and ablations on adaptation components. To make these claims more explicit, we will revise the abstract to include key quantitative metrics (e.g., success rates and adaptation speed) and add a summary table of baseline comparisons with error bars. We will also expand the experimental protocols subsection to detail data collection, evaluation metrics, and hyperparameters. revision: yes
-
Referee: [Method] Method description (adaptation phase): The load-bearing assumption that the fixed sim-pretrained encoder, reward model, and value function produce usable signals on real observations without retraining is not supported by described ablations or transfer-success metrics. In contact-rich regimes, sim-to-real gaps in perception or contact dynamics typically invalidate such fixed components, yet only latent dynamics are updated.
Authors: We agree this assumption requires stronger validation. The manuscript already includes ablations showing that full finetuning degrades performance while partial dynamics update succeeds. We will add explicit transfer-success metrics (e.g., encoder and reward prediction accuracy on held-out real data) and an ablation comparing planning performance when freezing versus updating the reward and value functions. These additions will be placed in the revised Experiments section. revision: yes
-
Referee: [Adaptation and Planning] Adaptation and planning description: The assertion that real-world prediction losses alone suffice to adapt the latent dynamics for successful long-horizon planning assumes the transferred reward/value remain aligned with real outcomes. No concrete test (e.g., planning success with frozen vs. adapted components) is reported to address the risk of optimizing against misaligned objectives.
Authors: We recognize the value of directly testing alignment. While overall task success with SimDist provides indirect evidence, we will add a concrete experiment reporting planning success rates using frozen versus adapted dynamics (with reward/value held fixed). This will quantify any misalignment risk and be included in the revised manuscript. revision: yes
Circularity Check
No circularity in derivation chain; method is standard transfer with independent adaptation
full rationale
The paper presents Simulation Distillation as pretraining a world model (encoder, reward, value, dynamics) in simulation, then transferring the encoder/reward/value while adapting only the latent dynamics via standard supervised prediction losses on real data. This reduces adaptation to system identification without any self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations in the abstract or described chain. No equations or steps reduce outputs to inputs by construction; the approach relies on external simulation data and real-world losses as independent signals, making the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physics simulators supply structural priors that remain useful after transfer to real robot observations
Reference graph
Works this paper leans on
-
[1]
Karl Johan ˚Astr¨om. Adaptive control. InMathematical System Theory: The Influence of RE Kalman, pages 437–
-
[2]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
work page 2023
-
[3]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[4]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video- language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. Transdreamer: Reinforcement learning with transformer world models.arXiv preprint arXiv:2202.09481, 2022
-
[6]
Xinyue Chen, Che Wang, Zijian Zhou, and Keith W. Ross. Randomized ensembled double q-learning: Learn- ing fast without a model. InInternational Confer- ence on Learning Representations, 2021. URL https: //openreview.net/forum?id=AY8zfZm0tDd
work page 2021
-
[7]
Randomized ensembled double q-learning: Learn- ing fast without a model
Xinyue Chen, Che Wang, Zijian Zhou, and Keith W Ross. Randomized ensembled double q-learning: Learn- ing fast without a model. InInternational Conference on Learning Representations, 2021
work page 2021
-
[8]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
work page 2024
-
[9]
Deep reinforcement learning in a handful of trials using probabilistic dynamics models
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. Advances in neural information processing systems, 31, 2018
work page 2018
-
[10]
Wensing, Benjamin Katz, Gerardo Bledt, and Sangbae Kim
Jared Di Carlo, Patrick M. Wensing, Benjamin Katz, Gerardo Bledt, and Sangbae Kim. Dynamic locomotion in the mit cheetah 3 through convex model-predictive control. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–9, 2018. doi: 10.1109/IROS.2018.8594448
-
[11]
Finetuning offline world models in the real world, 2023
Yunhai Feng, Nicklas Hansen, Ziyan Xiong, Chan- dramouli Rajagopalan, and Xiaolong Wang. Finetuning offline world models in the real world, 2023. URL https://arxiv.org/abs/2310.16029
-
[12]
Learning to Walk via Deep Reinforcement Learning
Tuomas Haarnoja, Sehoon Ha, Aurick Zhou, Jie Tan, George Tucker, and Sergey Levine. Learning to walk via deep reinforcement learning.arXiv preprint arXiv:1812.11103, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mo- hammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
work page 2020
-
[15]
Tem- poral difference learning for model predictive control
Nicklas A Hansen, Hao Su, and Xiaolong Wang. Tem- poral difference learning for model predictive control. InInternational Conference on Machine Learning, pages 8387–8406. PMLR, 2022
work page 2022
-
[16]
Minho Heo, Youngwoon Lee, Doohyun Lee, and Joseph J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation. In Robotics: Science and Systems, 2023
work page 2023
-
[17]
Dropout q- functions for doubly efficient reinforcement learning
Takuya Hiraoka, Takahisa Imagawa, Taisei Hashimoto, Takashi Onishi, and Yoshimasa Tsuruoka. Dropout q- functions for doubly efficient reinforcement learning. In International Conference on Learning Representations, 2022
work page 2022
-
[18]
Dropout q-functions for doubly efficient reinforcement learn- ing
Takuya Hiraoka, Takahisa Imagawa, Taisei Hashimoto, Takashi Onishi, and Yoshimasa Tsuruoka. Dropout q-functions for doubly efficient reinforcement learn- ing. InInternational Conference on Learning Repre- sentations, 2022. URL https://openreview.net/forum?id= xCVJMsPv3RT
work page 2022
-
[19]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. Pi*0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
PTR Prentice-Hall Upper Saddle River, NJ, 1996
Petros A Ioannou and Jing Sun.Robust adaptive control, volume 1. PTR Prentice-Hall Upper Saddle River, NJ, 1996
work page 1996
-
[22]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
-
[23]
When to trust your model: Model-based pol- icy optimization, 2021
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based pol- icy optimization, 2021. URL https://arxiv.org/abs/1906. 08253
work page 2021
-
[24]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. Scalable deep reinforcement learning for vision-based robotic manipulation. In Aude Billard, Anca Dragan, Jan Peters, and Jun Morimoto, editors, Proceedings of The 2nd Conference ...
work page 2018
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. InInter- national Conference on Learning Representations, 2022
work page 2022
-
[27]
Rma: Rapid motor adaptation for legged robots
Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. arXiv preprint arXiv:2107.04034, 2021
-
[28]
Conservative q-learning for offline reinforcement learning, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning, 2020. URL https://arxiv.org/abs/2006.04779
-
[29]
Adapting world models with latent-state dynamics residuals, 2025
JB Lanier, Kyungmin Kim, Armin Karamzade, Yifei Liu, Ankita Sinha, Kat He, Davide Corsi, and Roy Fox. Adapting world models with latent-state dynamics residuals, 2025. URL https://arxiv.org/abs/2504.02252
-
[30]
Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
work page 2020
-
[31]
Kun Lei, Huanyu Li, Dongjie Yu, Zhenyu Wei, Lingxiao Guo, Zhennan Jiang, Ziyu Wang, Shiyu Liang, and Huazhe Xu. Rl-100: Performant robotic manipulation with real-world reinforcement learning.arXiv preprint arXiv:2510.14830, 2025
-
[32]
End-to-end training of deep visuomotor policies
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40,
-
[33]
URL http://jmlr.org/papers/v17/15-522.html
-
[34]
Learning to walk from three minutes of real-world data with semi-structured dynamics models
Jacob Levy, Tyler Westenbroek, and David Fridovich- Keil. Learning to walk from three minutes of real-world data with semi-structured dynamics models. InConfer- ence on Robot Learning, pages 2061–2079. PMLR, 2025
work page 2061
-
[35]
Chenhao Li, Andreas Krause, and Marco Hutter. Offline robotic world model: Learning robotic policies without a physics simulator.arXiv preprint arXiv:2504.16680, 2025
-
[36]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Serl: A software suite for sample-efficient robotic reinforcement learning
Jianlan Luo, Zheyuan Hu, Charles Xu, You Liang Tan, Jacob Berg, Archit Sharma, Stefan Schaal, Chelsea Finn, Abhishek Gupta, and Sergey Levine. Serl: A software suite for sample-efficient robotic reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024
work page 2024
-
[38]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Manfred Morari and Jay H Lee. Model predictive control: past, present and future.Computers & chemical engineering, 23(4-5):667–682, 1999
work page 1999
-
[40]
Factory: Fast contact for robotic assembly.arXiv preprint arXiv:2205.03532, 2022
Yashraj Narang, Kier Storey, Iretiayo Akinola, Miles Macklin, Philipp Reist, Lukasz Wawrzyniak, Yunrong Guo, Adam Moravanszky, Gavriel State, Michelle Lu, et al. Factory: Fast contact for robotic assembly.arXiv preprint arXiv:2205.03532, 2022
-
[41]
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexan- dre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sul- tan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Frederic Besse, Tim Harley, A...
work page 2024
-
[42]
Contactnets: Learning discontinuous contact dynamics with smooth, implicit representations
Samuel Pfrommer, Mathew Halm, and Michael Posa. Contactnets: Learning discontinuous contact dynamics with smooth, implicit representations. InConference on Robot Learning, pages 2279–2291. PMLR, 2021
work page 2021
-
[43]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
work page 2022
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Ritvik Singh, Arthur Allshire, Ankur Handa, Nathan Ratliff, and Karl Van Wyk. Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands.arXiv preprint arXiv:2412.01791, 2024
-
[46]
Jean-Jacques E Slotine and Weiping Li. On the adaptive control of robot manipulators.The international journal of robotics research, 6(3):49–59, 1987
work page 1987
-
[47]
Legged robots that keep on learning: Fine-tuning locomotion policies in the real world
Laura Smith, J Chase Kew, Xue Bin Peng, Sehoon Ha, Jie Tan, and Sergey Levine. Legged robots that keep on learning: Fine-tuning locomotion policies in the real world. In2022 international conference on robotics and automation (ICRA), pages 1593–1599. IEEE, 2022
work page 2022
-
[48]
Laura Smith, Ilya Kostrikov, and Sergey Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning.arXiv preprint arXiv:2208.07860, 2022
-
[49]
Grow your limits: Continuous improvement with real-world rl for robotic locomotion
Laura Smith, Yunhao Cao, and Sergey Levine. Grow your limits: Continuous improvement with real-world rl for robotic locomotion. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 10829–10836. IEEE, 2024
work page 2024
-
[50]
Andrew Wagenmaker, Kevin Huang, Liyiming Ke, Kevin Jamieson, and Abhishek Gupta. Overcoming the sim-to- real gap: Leveraging simulation to learn to explore for real-world rl.Advances in Neural Information Processing Systems, 37:78715–78765, 2024
work page 2024
-
[51]
Lyapunov design for robust and efficient robotic reinforcement learning,
Tyler Westenbroek, Fernando Castaneda, Ayush Agrawal, Shankar Sastry, and Koushil Sreenath. Lyapunov design for robust and efficient robotic reinforcement learning,
- [52]
-
[53]
Tyler Westenbroek, Jacob Levy, and David Fridovich- Keil. Enabling efficient, reliable real-world reinforce- ment learning with approximate physics-based models. InConference on Robot Learning, pages 2478–2497. PMLR, 2023
work page 2023
-
[54]
Aggressive driving with model predictive path integral control
Grady Williams, Paul Drews, Brian Goldfain, James M Rehg, and Evangelos A Theodorou. Aggressive driving with model predictive path integral control. In2016 IEEE International Conference on Robotics and Automation (ICRA), pages 1433–1440. IEEE, 2016
work page 2016
-
[55]
Anycar to anywhere: Learning universal dynamics model for agile and adaptive mobil- ity
Wenli Xiao, Haoru Xue, Tony Tao, Dvij Kalaria, John M Dolan, and Guanya Shi. Anycar to anywhere: Learning universal dynamics model for agile and adaptive mobil- ity. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8819–8825. IEEE, 2025
work page 2025
-
[56]
Latent diffusion planning for imitation learning
Amber Xie, Oleh Rybkin, Dorsa Sadigh, and Chelsea Finn. Latent diffusion planning for imitation learning. arXiv preprint arXiv:2504.16925, 2025
-
[57]
Jie Xu, Eric Heiden, Iretiayo Akinola, Dieter Fox, Miles Macklin, and Yashraj Narang. Neural robot dynamics. arXiv preprint arXiv:2508.15755, 2025
-
[58]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023
-
[59]
Patrick Yin, Tyler Westenbroek, Simran Bagaria, Kevin Huang, Ching-an Cheng, Andrey Kobolov, and Ab- hishek Gupta. Rapidly adapting policies to the real world via simulation-guided fine-tuning.arXiv preprint arXiv:2502.02705, 2025
-
[60]
Emergent dexterity via diverse resets and large-scale reinforcement learning
Patrick Yin, Tyler Westenbroek, Zhengyu Zhang, Ignacio Dagnino, Eeshani Shilamkar, Numfor Mbiziwo-Tiapo, Simran Bagaria, Xinlei Liu, Galen Mullins, Andrey Kolobov, and Abhishek Gupta. Emergent dexterity via diverse resets and large-scale reinforcement learning. InThe Fourteenth International Conference on Learn- ing Representations, 2026. URL https://open...
work page 2026
-
[61]
Mopo: Model-based offline policy optimization
Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Y Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization. Advances in Neural Information Processing Systems, 33: 14129–14142, 2020
work page 2020
-
[62]
Combo: Conservative offline model-based policy optimization
Tianhe Yu, Aviral Kumar, Rafael Rafailov, Aravind Ra- jeswaran, Sergey Levine, and Chelsea Finn. Combo: Conservative offline model-based policy optimization. Advances in neural information processing systems, 34: 28954–28967, 2021
work page 2021
-
[63]
Rewind: Language-guided rewards teach robot policies without new demonstrations, 2025
Jiahui Zhang, Yusen Luo, Abrar Anwar, Sumedh Anand Sontakke, Joseph J Lim, Jesse Thomason, Erdem Biyik, and Jesse Zhang. Rewind: Language-guided rewards teach robot policies without new demonstrations, 2025. URL https://arxiv.org/abs/2505.10911
-
[64]
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforcement learn- ing fine-tuning need not retain offline data.arXiv preprint arXiv:2412.07762, 2024
-
[65]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025. APPENDIX A. Diverse Data Generation Details Algorithm 2 details the data generation process. Data gen- eration proceeds with ru...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.