Recognition: 2 theorem links
· Lean TheoremDynFlowDrive: Flow-Based Dynamic World Modeling for Autonomous Driving
Pith reviewed 2026-05-15 09:03 UTC · model grok-4.3
The pith
DynFlowDrive learns a velocity field via rectified flow to predict how driving actions evolve latent scene states, supporting stability-based trajectory selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
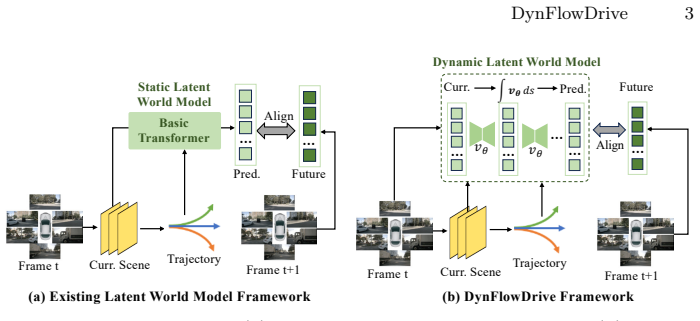
By adopting the rectified flow formulation, the model learns a velocity field that describes how the scene state changes under different driving actions, enabling progressive prediction of future latent states. Building on this, the method adds a stability-aware multi-mode trajectory selection strategy that evaluates candidates according to the stability of the induced scene transitions, yielding consistent gains across driving frameworks on the nuScenes and NavSim benchmarks.
What carries the argument
The rectified flow velocity field in latent space that models continuous, action-conditioned transitions between world states.
If this is right
- Future states can be predicted progressively by integrating along the learned velocity field instead of generating appearances or regressing deterministically.
- Trajectory selection becomes possible by measuring the stability of the scene transitions each candidate action would induce.
- The same model can be plugged into existing driving frameworks to improve reliability without increasing inference time.
- Action-conditioned evolution is captured directly in the latent dynamics rather than through separate generation steps.
Where Pith is reading between the lines
- The same velocity-field approach could be tested on other sequential control tasks where state transitions depend on chosen actions.
- If the latent space preserves enough scene structure, the stability metric might be extended to incorporate uncertainty estimates from the flow itself.
- Online fine-tuning of the velocity field using new sensor data could allow the model to adapt to changing environments without retraining from scratch.
Load-bearing premise
The velocity field learned in latent space accurately captures how real scenes evolve under driving actions and that the stability of those transitions reliably indicates safe planning choices.
What would settle it
If integrating the learned velocity field from an observed initial state under a known action produces latent predictions that deviate substantially from the actual future states recorded in held-out driving sequences, the central modeling claim would be falsified.
Figures





read the original abstract
Recently, world models have been incorporated into the autonomous driving systems to improve the planning reliability. Existing approaches typically predict future states through appearance generation or deterministic regression, which limits their ability to capture trajectory-conditioned scene evolution and leads to unreliable action planning. To address this, we propose DynFlowDrive, a latent world model that leverages flow-based dynamics to model the transition of world states under different driving actions. By adopting the rectifiedflow formulation, the model learns a velocity field that describes how the scene state changes under different driving actions, enabling progressive prediction of future latent states. Building upon this, we further introduce a stability-aware multi-mode trajectory selection strategy that evaluates candidate trajectories according to the stability of the induced scene transitions. Extensive experiments on the nuScenes and NavSim benchmarks demonstrate consistent improvements across diverse driving frameworks without introducing additional inference overhead. Source code will be abaliable at https://github.com/xiaolul2/DynFlowDrive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DynFlowDrive, a latent world model for autonomous driving that adopts the rectified flow formulation to learn a velocity field describing action-conditioned scene state transitions. This enables progressive prediction of future latent states via ODE integration. A stability-aware multi-mode trajectory selection strategy is proposed that scores candidate trajectories by the integrated norm of the induced velocity field. Experiments on nuScenes and NavSim benchmarks report consistent improvements over prior world-model and planning baselines without added inference cost.
Significance. If the empirical gains and ablations hold under rigorous scrutiny, the work offers a principled continuous-dynamics alternative to deterministic regression or generative world models, potentially improving trajectory-conditioned prediction reliability for planning. The stability metric provides a concrete, if empirical, link between flow-field properties and planning safety.
major comments (2)
- [Experiments] Experiments section: the central claim of consistent improvements rests on quantitative results, yet the manuscript provides insufficient detail on data splits, number of runs, error bars, and exact metric values for the nuScenes and NavSim evaluations, preventing verification that gains are robust rather than post-hoc.
- [§3.2] §3.2 (Stability-aware Trajectory Selection): the stability metric is defined as the integrated norm of the velocity field along the predicted path, but no analysis is given of its sensitivity to integration step count, norm choice, or latent-space scaling; this directly affects whether the metric reliably proxies safe planning.
minor comments (2)
- [Abstract] Abstract: typo 'abaliable' should be 'available'.
- [Abstract] Abstract and §2: 'rectifiedflow' should be hyphenated or spaced as 'rectified flow' to match standard terminology in the flow-matching literature.
Simulated Author's Rebuttal
We thank the referee for the positive summary and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of results and analysis.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of consistent improvements rests on quantitative results, yet the manuscript provides insufficient detail on data splits, number of runs, error bars, and exact metric values for the nuScenes and NavSim evaluations, preventing verification that gains are robust rather than post-hoc.
Authors: We agree that additional details are required for reproducibility and verification. In the revised manuscript we will expand the Experiments section to explicitly describe the train/validation/test splits for both nuScenes and NavSim, state that all quantitative results are averaged over five independent runs with different random seeds, include error bars (standard deviation) in all tables and figures, and report the precise numerical values (rather than only relative gains) for every metric. revision: yes
-
Referee: [§3.2] §3.2 (Stability-aware Trajectory Selection): the stability metric is defined as the integrated norm of the velocity field along the predicted path, but no analysis is given of its sensitivity to integration step count, norm choice, or latent-space scaling; this directly affects whether the metric reliably proxies safe planning.
Authors: We acknowledge that the current manuscript does not contain sensitivity analysis for the stability metric. In the revision we will add a dedicated paragraph (and, if space permits, a small table or plot in the appendix) that examines the effect of varying the number of ODE integration steps, the choice of norm (L1 versus L2), and different latent-space scaling factors on the ranking of candidate trajectories. This will provide evidence that the metric remains stable under reasonable hyper-parameter choices. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper adopts the standard rectified-flow formulation to learn a velocity field in latent space conditioned on driving actions and trajectories; this is trained directly from data rather than defined by construction to equal its own outputs. The stability metric is introduced as the integrated norm of the predicted velocity field along candidate paths, which is a downstream computation and does not reduce the core prediction to a fitted input. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are used to justify the central modeling choice. The claimed gains are presented as empirical results on nuScenes and NavSim benchmarks, leaving the derivation self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE TPAMI (2024) 2
work page 2024
-
[4]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Chen,S.,Jiang,B.,Gao,H.,Liao,B.,Xu,Q.,Zhang,Q.,Huang,C.,Liu,W.,Wang, X.: Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv preprint arXiv:2402.13243 (2024) 2, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 4
Chi,C.,Xu,Z.,Feng,S.,Cousineau,E.,Du,Y.,Burchfiel,B.,Tedrake,R.,Song,S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025) 4
work page 2025
-
[6]
Chi, H., Gao, H.a., Liu, Z., Liu, J., Liu, C., Li, J., Yang, K., Yu, Y., Wang, Z., Li, W., et al.: Impromptu vla: Open weights and open data for driving vision- language-action models. arXiv preprint arXiv:2505.23757 (2025) 4
-
[7]
Chib,P.S.,Singh,P.:Recentadvancementsinend-to-endautonomousdrivingusing deep learning: A survey. TIV9(1), 103–118 (2023) 2
work page 2023
-
[8]
IEEE TPAMI 45(11), 12878–12895 (2022) 13
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imi- tation with transformer-based sensor fusion for autonomous driving. IEEE TPAMI 45(11), 12878–12895 (2022) 13
work page 2022
-
[9]
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschenski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. In: NeurIPS (2024) 3, 9, 11
work page 2024
-
[10]
IEEE Internet of Things Journal13(3), 3870–3898 (2025) 2
Dong, W., Lu, S., Chen, X., Zhang, S., Liu, Q., Liu, Z., Chen, L., Wang, H., Cai, Y.: End-to-end autonomous driving: From classic paradigm to large model empowerment—a comprehensive survey. IEEE Internet of Things Journal13(3), 3870–3898 (2025) 2
work page 2025
-
[11]
Gao, H., Chen, S., Jiang, B., Liao, B., Shi, Y., Guo, X., Pu, Y., Yin, H., Li, X., Zhang, X., Zhang, Y., Liu, W., Zhang, Q., Wang, X.: Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning. arXiv preprint arXiv:2502.13144 (2025) 4
-
[12]
Gao, R., Chen, K., Xie, E., Hong, L., Li, Z., Yeung, D.Y., Xu, Q.: Magicdrive: Street view generation with diverse 3d geometry control. In: ICLR (2024) 2
work page 2024
-
[13]
González, D., Pérez, J., Milanés, V., Nashashibi, F.: A review of motion planning techniques for automated vehicles. TITS17(4), 1135–1145 (2015) 4
work page 2015
-
[14]
Guan, Y., Liao, H., Li, Z., Hu, J., Yuan, R., Zhang, G., Xu, C.: World models for autonomous driving: An initial survey. TIV (2024) 2, 4
work page 2024
- [15]
-
[16]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
-
[18]
arXiv preprint arXiv:2512.16760 (2025) 2 16 X
Hu, T., Liu, X., Wang, S., Zhu, Y., Liang, A., Kong, L., Zhao, G., Gong, Z., Cen, J., Huang, Z., et al.: Vision-language-action models for autonomous driving: Past, present, and future. arXiv preprint arXiv:2512.16760 (2025) 2 16 X. Liu et al
- [19]
- [20]
-
[21]
arXiv preprint arXiv:2508.09158 (2025) 4
Jiao, S., Qian, K., Ye, H., Zhong, Y., Luo, Z., Jiang, S., Huang, Z., Fang, Y., Miao, J., Fu, Z., et al.: Evadrive: Evolutionary adversarial policy optimization for end-to-end autonomous driving. arXiv preprint arXiv:2508.09158 (2025) 4
-
[22]
arXiv preprint arXiv:2509.07996 (2025) 2, 4
Kong, L., Yang, W., Mei, J., Liu, Y., Liang, A., Zhu, D., Lu, D., Yin, W., Hu, X., Jia, M., et al.: 3d and 4d world modeling: A survey. arXiv preprint arXiv:2509.07996 (2025) 2, 4
-
[23]
arXiv preprint arXiv:2409.18341 (2024) 3, 4, 6, 10, 11
Li, P., Cui, D.: Navigation-guided sparse scene representation for end-to-end au- tonomous driving. arXiv preprint arXiv:2409.18341 (2024) 3, 4, 6, 10, 11
-
[24]
Li, Y., Fan, L., He, J., Wang, Y., Chen, Y., Zhang, Z., Tan, T.: Enhancing end-to- end autonomous driving with latent world model. arXiv preprint arXiv:2406.08481 (2024) 2, 4, 6, 10, 11, 13
-
[25]
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with online trajectory evaluation via bev world model. arXiv preprint arXiv:2504.01941 (2025) 4, 10, 11, 13
-
[26]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Li, Y., Tian, M., Zhu, D., Zhu, J., Lin, Z., Xiong, Z., Zhao, X.: Drive-r1: Bridg- ing reasoning and planning in vlms for autonomous driving with reinforcement learning. arXiv preprint arXiv:2506.18234 (2025) 4
-
[28]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra- distillation. arXiv preprint arXiv:2406.06978 (2024) 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bevformer: learningbird’s-eye-viewrepresentationfromlidar-cameraviaspatiotemporaltrans- formers. IEEE TPAMI (2024) 3
work page 2024
-
[30]
Li, Z., Yu, Z., Lan, S., Li, J., Kautz, J., Lu, T., Alvarez, J.M.: Is ego status all you need for open-loop end-to-end autonomous driving? In: CVPR (2024) 4, 10, 11
work page 2024
- [31]
-
[32]
Lim, W., Lee, S., Sunwoo, M., Jo, K.: Hybrid trajectory planning for autonomous driving in on-road dynamic scenarios. TITS22(1), 341–355 (2019) 4
work page 2019
-
[33]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [34]
- [35]
- [36]
-
[37]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [38]
-
[39]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017) 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: ICLR (2024) 2
work page 2024
- [41]
- [42]
- [43]
- [44]
- [45]
- [46]
- [47]
-
[48]
arXiv preprint arXiv:2503.24381 (2025) 4
Wang, Y., Huang, X., Sun, X., Yan, M., Xing, S., Tu, Z., Li, J.: Uniocc: A unified benchmark for occupancy forecasting and prediction in autonomous driving. arXiv preprint arXiv:2503.24381 (2025) 4
- [49]
- [50]
- [51]
- [52]
-
[53]
arXiv preprint arXiv:2511.20325 (2025) 4 18 X
Yan, T., Tang, T., Gui, X., Li, Y., Zhesng, J., Huang, W., Kong, L., Han, W., Zhou, X., Zhang, X., et al.: Ad-r1: Closed-loop reinforcement learning for end-to-end autonomous driving with impartial world models. arXiv preprint arXiv:2511.20325 (2025) 4 18 X. Liu et al
- [54]
-
[55]
arXiv preprint arXiv:2512.19133 (2025) 2, 4
Yang, P., Lu, B., Xia, Z., Han, C., Gao, Y., Zhang, T., Zhan, K., Lang, X., Zheng, Y., Zhang, Q.: Worldrft: Latent world model planning with reinforcement fine- tuning for autonomous driving. arXiv preprint arXiv:2512.19133 (2025) 2, 4
- [56]
-
[57]
arXiv preprint arXiv:2408.03601 (2024) 13
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024) 13
-
[58]
arXiv preprint arXiv:2506.24113 (2025) 2, 4
Zhang, K., Tang, Z., Hu, X., Pan, X., Guo, X., Liu, Y., Huang, J., Yuan, L., Zhang, Q., Long, X.X., et al.: Epona: Autoregressive diffusion world model for autonomous driving. arXiv preprint arXiv:2506.24113 (2025) 2, 4
- [59]
- [60]
- [61]
- [62]
-
[63]
arXiv preprint arXiv:2503.23463 (2025) 4
Zhou, X., Han, X., Yang, F., Ma, Y., Tresp, V., Knoll, A.: Opendrivevla: Towards end-to-end autonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463 (2025) 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.