Recognition: no theorem link
What If Consensus Lies? Selective-Complementary Reinforcement Learning at Test Time
Pith reviewed 2026-05-15 08:45 UTC · model grok-4.3
The pith
Test-time learning for LLMs avoids reinforcing wrong answers by using strict consensus and entropy-based negatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCRL shows that test-time reinforcement learning succeeds when selective positive pseudo-labeling applies strict consensus filters and entropy-gated negative pseudo-labeling prunes high-uncertainty incorrect paths, countering the noise from lying consensus on dispersed distributions.
What carries the argument
The complementary pair of strict-consensus positive pseudo-labeling and entropy-gated negative pseudo-labeling within the SCRL framework.
Load-bearing premise
Entropy serves as a reliable indicator for identifying incorrect trajectories suitable for negative pseudo-labeling.
What would settle it
A counterexample would be a reasoning benchmark where high-entropy generations turn out to be correct more frequently than low-entropy ones, causing the negative labeling to hurt accuracy.
Figures



read the original abstract
Test-Time Reinforcement Learning (TTRL) enables Large Language Models (LLMs) to enhance reasoning capabilities on unlabeled test streams by deriving pseudo-rewards from majority voting consensus. However, existing TTRL methods rely exclusively on positive pseudo-labeling strategies. Such reliance becomes vulnerable under challenging scenarios where answer distributions are highly dispersed, resulting in weak consensus that inadvertently reinforces incorrect trajectories as supervision signals. In this paper, we propose SCRL (Selective-Complementary Reinforcement Learning), a robust test-time reinforcement learning framework that effectively mitigates label noise amplification. SCRL develops Selective Positive Pseudo-Labeling, which enforces strict consensus criteria to filter unreliable majorities. Complementarily, SCRL introduces Entropy-Gated Negative Pseudo-Labeling, the first negative supervision mechanism in TTRL, to reliably prune incorrect trajectories based on generation uncertainty. Extensive experiments on multiple reasoning benchmarks demonstrate that SCRL achieves substantial improvements over baselines, while maintaining robust generalization and training stability under constrained rollout budgets. Our code is available at https://github.com/Jasper-Yan/SCRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCRL, a test-time RL framework for LLMs on reasoning tasks. It critiques existing TTRL methods for relying only on positive pseudo-labels from majority voting, which fails under dispersed answer distributions. SCRL adds strict-consensus selective positive pseudo-labeling and introduces entropy-gated negative pseudo-labeling (claimed as the first such mechanism in TTRL) to prune incorrect trajectories. Experiments on reasoning benchmarks are said to show substantial gains over baselines while preserving generalization and stability under constrained rollouts.
Significance. If the entropy proxy for error is reliable, the addition of negative supervision would meaningfully extend TTRL and improve robustness on hard instances. The code release is a positive factor. However, the significance is limited by the absence of quantitative effect sizes, ablations on the gating mechanism, and verification that entropy remains anti-correlated with correctness after pseudo-label updates.
major comments (3)
- [§3.2] The central claim that entropy-gated negative pseudo-labeling reliably prunes incorrect trajectories (and thereby supplies the complementary benefit) rests on an unverified assumption that generation entropy is a faithful proxy for error. No section derives this correlation or provides post-fine-tuning empirical confirmation; in reasoning models, low-entropy systematic mistakes are common, so the negative labels may inject noise rather than remove it.
- [§4] The abstract and experimental sections report 'substantial improvements' and 'robust generalization' without effect sizes, error bars, ablation tables on the entropy threshold, or precise controls for rollout budget. This makes it impossible to evaluate whether the gains are load-bearing or whether stability holds when the negative-labeling component is ablated.
- [§3.3] Both the consensus strictness threshold and the entropy gate threshold are free parameters. No sensitivity analysis or robustness check is shown for these choices across benchmarks, undermining the claim of training stability under constrained rollouts.
minor comments (2)
- [Abstract] The abstract should include at least one quantitative result (e.g., average accuracy delta and standard deviation) to support the 'substantial improvements' claim.
- [§3.2] Notation for the entropy gate (e.g., how the threshold is applied to token-level vs. sequence-level entropy) is introduced without a clear equation or pseudocode reference.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate additional empirical analyses, quantitative reporting, and sensitivity checks as outlined.
read point-by-point responses
-
Referee: [§3.2] The central claim that entropy-gated negative pseudo-labeling reliably prunes incorrect trajectories (and thereby supplies the complementary benefit) rests on an unverified assumption that generation entropy is a faithful proxy for error. No section derives this correlation or provides post-fine-tuning empirical confirmation; in reasoning models, low-entropy systematic mistakes are common, so the negative labels may inject noise rather than remove it.
Authors: We acknowledge that the manuscript relies on entropy as an uncertainty proxy without a dedicated post-update verification section. While this choice draws from prior uncertainty estimation work in LLMs, we agree that explicit confirmation is needed. In the revision we will add an analysis (main text or appendix) with plots and statistics demonstrating the anti-correlation between generation entropy and correctness both before and after pseudo-label updates across benchmarks, along with discussion of potential low-entropy error cases. revision: yes
-
Referee: [§4] The abstract and experimental sections report 'substantial improvements' and 'robust generalization' without effect sizes, error bars, ablation tables on the entropy threshold, or precise controls for rollout budget. This makes it impossible to evaluate whether the gains are load-bearing or whether stability holds when the negative-labeling component is ablated.
Authors: We agree that the current reporting lacks the quantitative detail required for full evaluation. The revised manuscript will add effect sizes with standard deviations, error bars on all figures, a full ablation table isolating the entropy-gated negative labeling component, and additional experiments that control rollout budget while measuring performance with and without the negative supervision term. revision: yes
-
Referee: [§3.3] Both the consensus strictness threshold and the entropy gate threshold are free parameters. No sensitivity analysis or robustness check is shown for these choices across benchmarks, undermining the claim of training stability under constrained rollouts.
Authors: We recognize the value of demonstrating robustness to these hyperparameters. The revision will include a dedicated sensitivity analysis subsection (or appendix) with tables and plots varying both the consensus strictness threshold and the entropy gate threshold across all reported benchmarks, confirming performance stability within practical ranges and under constrained rollout budgets. revision: yes
Circularity Check
No significant circularity detected in SCRL derivation chain
full rationale
The paper defines SCRL via two new mechanisms—strict-consensus positive pseudo-labeling and entropy-gated negative pseudo-labeling—without any equations or steps that reduce a claimed prediction to a fitted input by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no known result is merely renamed. The central claims rest on empirical comparisons under constrained rollouts rather than tautological redefinitions, so the derivation remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- consensus strictness threshold
- entropy gate threshold
axioms (1)
- domain assumption Majority voting among rollouts provides useful pseudo-rewards when consensus is strong
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Process Reinforcement through Implicit Rewards
Pro- cess reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456. Junxian Duan, Siyu Liu, Yiming Hao, Huaibo Huang, and Ran He
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Don’t waste mis- takes: Leveraging negative rl-groups via confidence reweighting.arXiv preprint arXiv:2510.08696. Jiaxuan Gao, Shusheng Xu, Wenjie Ye, Weilin Liu, Chuyi He, Wei Fu, Zhiyu Mei, Guangju Wang, and Yi Wu
-
[4]
On designing effective rl reward at training time for llm reasoning.arXiv preprint arXiv:2410.15115. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others
-
[5]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Openai o1 system card.arXiv preprint arXiv:2412.16720. Dulhan Jayalath, Shashwat Goel, Thomas Foster, Parag Jain, Suchin Gururangan, Cheng Zhang, Anirudh Goyal, and Alan Schelten
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Compute as teacher: Turning inference compute into reference-free super- vision.arXiv preprint arXiv:2509.14234. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing fron- tiers in open language model post-training.arXiv preprint arXiv:2411.15124. Jia Li, Edward Beeching, Lewis Tunstall, Ben Lip- kin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, and 1 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Jia Liu, ChangYi He, YingQiao Lin, MingMin Yang, FeiYang Shen, and ShaoGuo Liu
A compre- hensive survey on test-time adaptation under distribu- tion shifts.International Journal of Computer Vision, 133(1):31–64. Jia Liu, ChangYi He, YingQiao Lin, MingMin Yang, FeiYang Shen, and ShaoGuo Liu. 2025a. Ettrl: Balancing exploration and exploitation in llm test- time reinforcement learning via entropy mechanism. arXiv preprint arXiv:2508.1...
-
[11]
arXiv preprint arXiv:2505.22660
Maximizing confidence alone improves reasoning. arXiv preprint arXiv:2505.22660. Archiki Prasad, Weizhe Yuan, Richard Yuanzhe Pang, Jing Xu, Maryam Fazel-Zarandi, Mohit Bansal, Sain- bayar Sukhbaatar, Jason Weston, and Jane Yu
-
[12]
Proximal Policy Optimization Algorithms
Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Amrith Setlur, Saurabh Garg, Xinyang Geng, Naman Garg, Virginia Smith, and Aviral Kumar
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Can large reasoning models self-train?arXiv preprint arXiv:2505.21444. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Felix Stahlberg, Ilia Kulikov, and Shankar Kumar
Heimdall: test-time scaling on the generative verification.arXiv preprint arXiv:2504.10337. Felix Stahlberg, Ilia Kulikov, and Shankar Kumar
-
[16]
arXiv preprint arXiv:2510.08977
Diagnos- ing and mitigating system bias in self-rewarding rl. arXiv preprint arXiv:2510.08977. Chenwei Tang, Jingyu Xing, Lin Long, Xinyu Liu, Deng Xiong, Wei Ju, Shudong Huang, Jiancheng Lv, and Ziyue Qiao
-
[17]
Rewarding the journey, not just the destination: A composite path and answer self- scoring reward mechanism for test-time reinforce- ment learning.arXiv preprint arXiv:2510.17923. Qwen Team and 1 others
-
[18]
Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2(3). Junqiao Wang, Zeng Zhang, Yangfan He, Zihao Zhang, Xinyuan Song, Yuyang Song, Tianyu Shi, Yuchen Li, Hengyuan Xu, Kunyu Wu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Ru Wang, Wei Huang, Qi Cao, Yusuke Iwasawa, Yu- taka Matsuo, and Jiaxian Guo
Enhancing code llms with reinforcement learning in code generation: A survey.arXiv preprint arXiv:2412.20367. Ru Wang, Wei Huang, Qi Cao, Yusuke Iwasawa, Yu- taka Matsuo, and Jiaxian Guo. 2025a. Self-harmony: Learning to harmonize self-supervision and self-play in test-time reinforcement learning.arXiv preprint arXiv:2511.01191. Yanbo Wang, Yongcan Yu, Ji...
-
[20]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-thought prompting elic- its reasoning in large language models.Preprint, arXiv:2201.11903. Lai Wei, Yuting Li, Chen Wang, Yue Wang, Linghe Kong, Weiran Huang, and Lichao Sun
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Jianghao Wu, Yasmeen George, Jin Ye, Yicheng Wu, Daniel F Schmidt, and Jianfei Cai
Self-evolving vision-language mod- els for image quality assessment via voting and rank- ing.arXiv preprint arXiv:2509.25787. Jianghao Wu, Yasmeen George, Jin Ye, Yicheng Wu, Daniel F Schmidt, and Jianfei Cai
-
[22]
Dong Yan, Gaochen Wu, and Bowen Zhou
Spine: Token-selective test-time reinforcement learning with entropy-band regularization.arXiv preprint arXiv:2511.17938. Dong Yan, Gaochen Wu, and Bowen Zhou
-
[23]
Mis- sion impossible: Feedback-guided dynamic interac- tive planning for improving reasoning on llms.arXiv preprint arXiv:2510.05577. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025a. Qwen3 technical report.arXiv preprint arXiv:2505.09388. Ziyi Yang, Weizhou Shen, Ru...
-
[24]
Zhaoning Yu, Will Su, Leitian Tao, Haozhu Wang, Aashu Singh, Hanchao Yu, Jianyu Wang, Hongyang Gao, Weizhe Yuan, Jason Weston, and 1 others. 2025b. Restrain: From spurious votes to signals– self-driven rl with self-penalization.arXiv preprint arXiv:2510.02172. Wenzhen Yuan, Shengji Tang, Weihao Lin, Jiacheng Ruan, Ganqu Cui, Bo Zhang, Tao Chen, Ting Liu, ...
-
[25]
Wis- dom of the crowd: Reinforcement learning from coevolutionary collective feedback.arXiv preprint arXiv:2508.12338. Kongcheng Zhang, Qi Yao, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, and Dacheng Tao. 2025a. Consistent paths lead to truth: Self- rewarding reinforcement learning for llm reasoning. arXiv preprint arXiv:2506.08745. Q...
-
[26]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng
Evolv- ing language models without labels: Majority drives selection, novelty promotes variation.arXiv preprint arXiv:2509.15194. Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng
-
[27]
Ttrl: Test- time reinforcement learning. InProc. NeurIPS. A Implementation Details A.1 Prompt Design Consistent with TTRL (Zuo et al., 2025), we adopt the standard chat templates corresponding to each model architecture. ForQwen2.5-3B, we employ the following prompt template: system You are a helpful assistant. user {question} Let’s think step by step and...
work page 2025
-
[28]
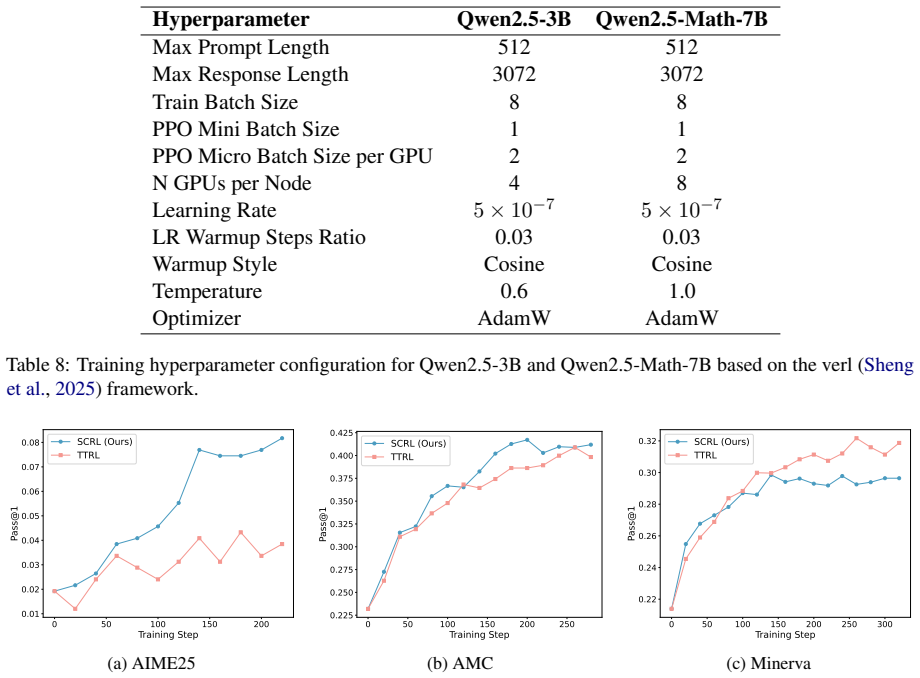
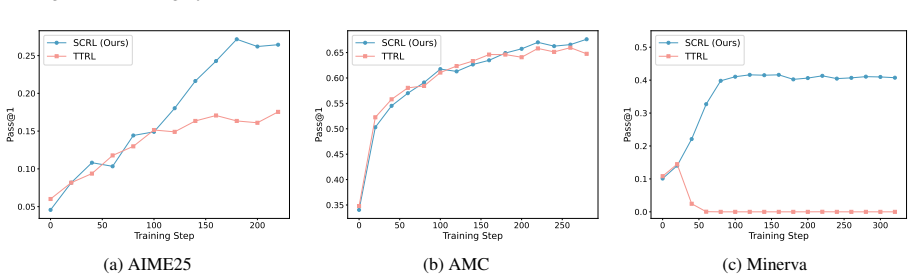
framework. 0 50 100 150 200 Training Step 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08Pass@1 SCRL (Ours) TTRL (a) AIME25 0 50 100 150 200 250 Training Step 0.225 0.250 0.275 0.300 0.325 0.350 0.375 0.400 0.425Pass@1 SCRL (Ours) TTRL (b) AMC 0 50 100 150 200 250 300 Training Step 0.22 0.24 0.26 0.28 0.30 0.32Pass@1 SCRL (Ours) TTRL (c) Minerva Figure 4: Trainin...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.