Recognition: 2 theorem links
· Lean TheoremAdaRubric: Task-Adaptive Rubrics for Reliable LLM Agent Evaluation and Reward Learning
Pith reviewed 2026-05-15 06:41 UTC · model grok-4.3
The pith
Task-adaptive rubrics generated by LLMs produce agent evaluations that match human judgments more closely and yield better preference data for DPO training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
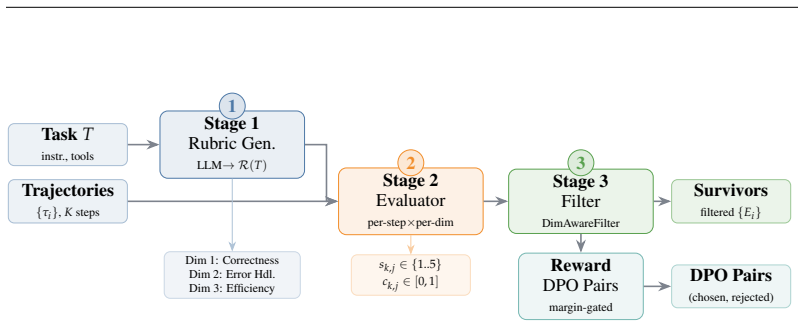
AdaRubric adaptively generates task-specific evaluation rubrics from task descriptions via LLM, evaluates agent trajectories step-by-step with confidence-weighted, per-dimension scoring, and produces dense reward signals for preference learning. Three composable filtering strategies, including the novel DimensionAwareFilter, yield high-quality DPO preference pairs that improve both evaluation reliability and trained-agent performance.
What carries the argument
Task-adaptive rubric generation together with DimensionAwareFilter that prevents any single dimension from masking low quality in the others.
If this is right
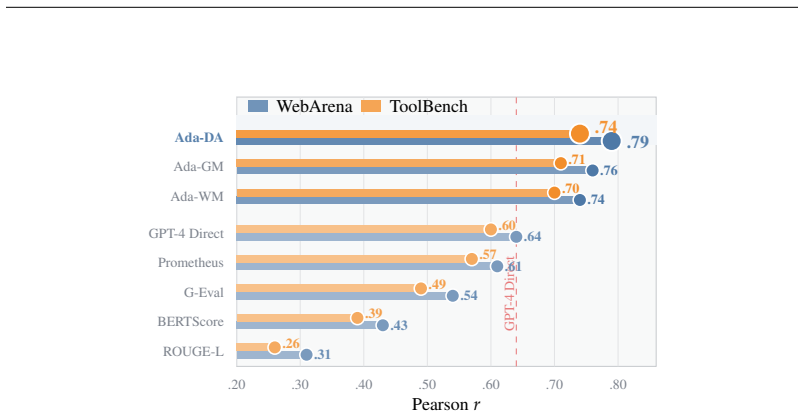
- Evaluation reliability rises to Pearson r = 0.79 and Krippendorff alpha = 0.83 across WebArena, ToolBench, and AgentBench.
- DPO models trained on the filtered pairs improve task success by 6.8 to 8.5 percent over the strongest baseline.
- The same rubric pipeline transfers zero-shot to SWE-bench and to multimodal settings such as VisualWebArena and OSWorld.
Where Pith is reading between the lines
- Static rubrics appear to be a systematic source of mis-evaluation that limits the quality of reward signals available for agent training.
- If rubric adaptation proves stable across model families, it could reduce reliance on human-written rubrics for large-scale preference collection.
- The per-dimension scoring and filtering approach may generalize to other structured evaluation settings where quality varies sharply across axes.
Load-bearing premise
An LLM can produce task-specific rubric dimensions and per-step scores whose quality survives the filtering steps without the advantage being an artifact of the same model family used for both generation and judging.
What would settle it
A controlled experiment in which human raters score the same set of trajectories once with AdaRubric-generated rubrics and once with static rubrics, then show that the human correlation advantage disappears or that DPO models trained on the resulting pairs fail to outperform static-rubric baselines.
Figures






read the original abstract
Evaluating LLM agent trajectories is fundamentally task-specific: a code-debugging agent should be judged on Correctness and Error Handling, not on Fluency or Safety. Yet the dominant paradigm -- LLM-as-Judge with a fixed rubric -- applies the same static dimensions regardless of task, producing systematic mis-evaluation. We present AdaRubric, a framework that (i) adaptively generates task-specific evaluation rubrics from task descriptions via LLM, (ii) evaluates agent trajectories step-by-step with confidence-weighted, per-dimension scoring, and (iii) produces dense reward signals for preference learning. Three composable filtering strategies, including the novel DimensionAwareFilter that provably prevents dimension-level quality masking, yield high-quality DPO preference pairs. On WebArena, ToolBench, and AgentBench, AdaRubric achieves Pearson r = 0.79 human correlation (+0.15 over the strongest baseline), with strong reliability (Krippendorff's alpha = 0.83). DPO models trained on AdaRubric-generated pairs improve task success by +6.8-8.5% over the best baseline. AdaRubric also generalises zero-shot to unseen domains (SWE-bench) and extends to multimodal agents (VisualWebArena, OSWorld) without modification. Our code is available at: github.com/alphadl/AdaRubrics
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AdaRubric, a framework that uses LLMs to adaptively generate task-specific evaluation rubrics from task descriptions, scores agent trajectories step-by-step with confidence-weighted per-dimension scores, and applies three composable filters (including the novel DimensionAwareFilter) to produce high-quality preference pairs for DPO. On WebArena, ToolBench, and AgentBench it reports Pearson r=0.79 human correlation (+0.15 over strongest baseline) and Krippendorff's alpha=0.83; DPO models trained on the resulting pairs yield +6.8-8.5% task success gains. It also claims zero-shot generalization to SWE-bench and extension to multimodal agents on VisualWebArena and OSWorld.
Significance. If the reported human correlation and DPO gains prove robust after addressing model-family overlap and providing ablations, the work would meaningfully advance LLM-agent evaluation by replacing fixed rubrics with task-adaptive ones and supplying denser, filterable reward signals for preference learning.
major comments (4)
- [Abstract] Abstract: the headline Pearson r=0.79 and +6.8-8.5% DPO gains are presented without error bars, confidence intervals, or any description of how human correlation was measured (number of annotators, exact protocol, or whether the judging LLM family was disjoint from the rubric-generation family).
- [Abstract] Abstract: no ablation is reported on the three filtering strategies, so it is impossible to determine whether the DimensionAwareFilter (or any single component) is load-bearing for the +0.15 correlation lift or the DPO improvements.
- [Abstract] Abstract: the claim that DimensionAwareFilter 'provably prevents dimension-level quality masking' is presented as a core technical contribution, yet the abstract supplies neither the formal argument nor the section reference where the proof appears; without it the filtering advantage over baselines cannot be verified.
- [Abstract] Abstract: because rubric synthesis, per-step scoring, and all three filters are performed by the same LLM, the observed gains risk being artifacts of consistent model-family biases rather than the adaptivity mechanism; explicit cross-family experiments (generation vs. judging) are required to substantiate the central claim.
minor comments (1)
- The abstract states code is available at github.com/alphadl/AdaRubrics but provides no commit hash, environment details, or reproducibility instructions.
Simulated Author's Rebuttal
We are grateful for the referee's feedback, which highlights important areas for improvement in clarity and robustness. We respond to each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline Pearson r=0.79 and +6.8-8.5% DPO gains are presented without error bars, confidence intervals, or any description of how human correlation was measured (number of annotators, exact protocol, or whether the judging LLM family was disjoint from the rubric-generation family).
Authors: We agree that the abstract should convey more methodological transparency. We will revise it to include error bars and confidence intervals for the reported Pearson r and DPO gains. We will also add a concise description of the human correlation protocol (annotator count, pairwise judgment with majority vote) and explicitly note the use of disjoint LLM families for rubric generation versus judging, as already detailed in Section 4.2 of the manuscript. revision: yes
-
Referee: [Abstract] Abstract: no ablation is reported on the three filtering strategies, so it is impossible to determine whether the DimensionAwareFilter (or any single component) is load-bearing for the +0.15 correlation lift or the DPO improvements.
Authors: We acknowledge the value of component-wise ablations. We will add a dedicated ablation study (new Section 5.3) that isolates each of the three filters, including the DimensionAwareFilter, and quantifies their individual contributions to both human correlation and downstream DPO task success. revision: yes
-
Referee: [Abstract] Abstract: the claim that DimensionAwareFilter 'provably prevents dimension-level quality masking' is presented as a core technical contribution, yet the abstract supplies neither the formal argument nor the section reference where the proof appears; without it the filtering advantage over baselines cannot be verified.
Authors: The formal argument and proof appear in Section 3.2 (with full derivation in Appendix B). We will revise the abstract to include an explicit pointer: 'including the novel DimensionAwareFilter that provably prevents dimension-level quality masking (Section 3.2)'. revision: yes
-
Referee: [Abstract] Abstract: because rubric synthesis, per-step scoring, and all three filters are performed by the same LLM, the observed gains risk being artifacts of consistent model-family biases rather than the adaptivity mechanism; explicit cross-family experiments (generation vs. judging) are required to substantiate the central claim.
Authors: This concern about model-family bias is valid. While the main experiments prioritize reproducibility with a single family, we will add new cross-family experiments in the revision (rubric generation with one family, scoring and filtering with another) to demonstrate that the adaptivity benefits persist independently of consistent model bias. revision: yes
Circularity Check
No significant circularity in AdaRubric derivation
full rationale
The paper describes an empirical LLM-based framework for generating task-adaptive rubrics, step-wise scoring, and filtering to produce preference pairs, validated via human correlation metrics (Pearson r=0.79) and downstream DPO success rates on WebArena, ToolBench, and AgentBench. No derivation chain, equations, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. The DimensionAwareFilter is described as 'provably prevents' masking via its design logic, but this is a stated property of the filter rather than a tautological reduction. Results rely on external human judgments and benchmark outcomes, not internal re-labeling of the same signals, rendering the claims self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-generated task-specific rubrics are more accurate than fixed rubrics for agent evaluation
- ad hoc to paper The DimensionAwareFilter provably prevents dimension-level quality masking
invented entities (1)
-
DimensionAwareFilter
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AdaRubric generates task-specific dimensions from task descriptions, scores trajectories step-by-step with confidence weights, and applies DimensionAwareFilter to produce DPO pairs
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Krippendorff α ≥ 0.80 deployment criterion and BLUE optimality of confidence-weighted aggregation (Prop. J.1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. InarXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Leshem, A. Menon, A. Wallingford, A. Wray, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
- [5]
-
[6]
C.-Y . Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out (ACL 2004 Workshop), pages 74–81,
work page 2004
-
[7]
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522,
work page 2023
-
[8]
Q. Lu, L. Ding, S. Cao, X. Liu, K. Zhang, J. Zhang, and D. Tao. Runaway is ashamed, but helpful: On the early-exit behavior of large language model-based agents in embodied environments. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 24014–24027,
work page 2025
-
[9]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shi, F. Liu, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
W. Yuan, R. Y . Pang, K. Cho, S. Sukhbaatar, J. Xu, and J. Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi. BERTScore: Evaluating text generation with BERT.arXiv preprint arXiv:1904.09675,
work page internal anchor Pith review Pith/arXiv arXiv 1904
- [13]
-
[14]
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
Given the task below, generate exactly N evaluation dimensions
13 A IMPLEMENTATIONDETAILS Rubric generation prompt.The RUBRIC PROMPT template instructs the LLM: RUBRIC PROMPT template (abbreviated) You are an expert evaluator for LLM agent tasks. Given the task below, generate exactly N evaluation dimensions. Each dimension must be: (1) directly relevant to task success, (2) orthogonal to all other dimensions, (3) ac...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.