Recognition: 2 theorem links
· Lean TheoremForestPrune: High-ratio Visual Token Compression for Video Multimodal Large Language Models via Spatial-Temporal Forest Modeling
Pith reviewed 2026-05-15 00:53 UTC · model grok-4.3
The pith
ForestPrune prunes 90 percent of video tokens for multimodal models by building spatial-temporal forests without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ForestPrune constructs token forests across video frames based on the semantic, spatial and temporal constraints, making an overall comprehension of videos. Afterwards, ForestPrune evaluates the importance of token trees and nodes based on tree depth and node roles, thereby obtaining a globally optimal pruning decision.
What carries the argument
Spatial-temporal Forest Modeling that links tokens into forests via semantic, spatial, and temporal constraints and scores them by tree depth plus node roles to decide pruning.
If this is right
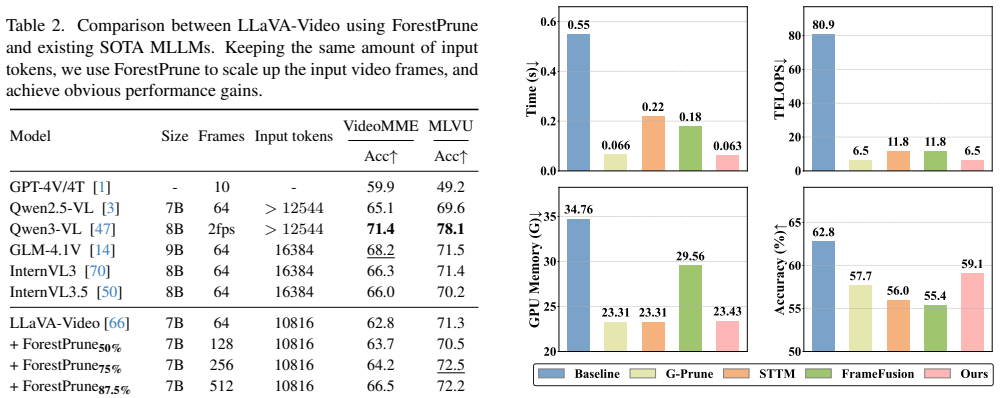
- Retains 95.8 percent average accuracy on standard video benchmarks after 90 percent token reduction on LLaVA-OneVision.
- Delivers +10.1 percent accuracy on the MLVU benchmark compared with earlier compression techniques.
- Cuts pruning time by 81.4 percent relative to FrameFusion when run on LLaVA-Video.
- Works directly on representative models including LLaVA-Video and LLaVA-OneVision.
Where Pith is reading between the lines
- The same forest-construction rules could be adapted to prune tokens in audio or text sequences that carry long-range dependencies.
- Lower token counts would reduce memory and energy demands enough to run video MLLMs on edge hardware.
- Combining the pruning step with light task-specific fine-tuning could recover any remaining accuracy loss on narrow domains.
Load-bearing premise
Scoring token importance solely by tree depth and node roles inside the constructed forests produces decisions that preserve all task-critical information across diverse videos.
What would settle it
A clear accuracy drop on a video benchmark containing complex motion or extended temporal dependencies after ForestPrune is applied, showing the depth-and-role scores missed necessary tokens.
Figures


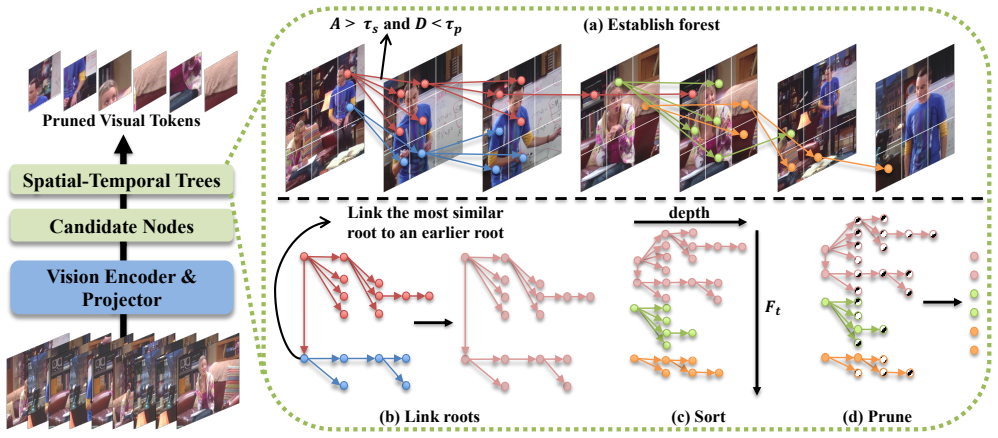

read the original abstract
Due to the great saving of computation and memory overhead, token compression has become a research hot-spot for MLLMs and achieved remarkable progress in image-language tasks. However, for the video, existing methods still fall short of high-ratio token compression. We attribute this shortcoming to the insufficient modeling of temporal and continual video content, and propose a novel and training-free token pruning method for video MLLMs, termed ForestPrune, which achieves effective and high-ratio pruning via Spatial-temporal Forest Modeling. In practice, ForestPrune construct token forests across video frames based on the semantic, spatial and temporal constraints, making an overall comprehension of videos. Afterwards, ForestPrune evaluates the importance of token trees and nodes based on tree depth and node roles, thereby obtaining a globally optimal pruning decision. To validate ForestPrune, we apply it to two representative video MLLMs, namely LLaVA-Video and LLaVA-OneVision, and conduct extensive experiments on a bunch of video benchmarks. The experimental results not only show the great effectiveness for video MLLMs, e.g., retaining 95.8% average accuracy while reducing 90% tokens for LLaVA-OneVision, but also show its superior performance and efficiency than the compared token compression methods, e.g., +10.1% accuracy on MLVU and -81.4% pruning time than FrameFusion on LLaVA-Video.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ForestPrune, a training-free token pruning method for video MLLMs. It constructs spatial-temporal token forests from semantic, spatial, and temporal constraints across frames, then scores token importance using tree depth and node roles to derive a pruning decision. Applied to LLaVA-Video and LLaVA-OneVision, it reports retaining 95.8% average accuracy at 90% token reduction, with gains such as +10.1% accuracy on MLVU and -81.4% pruning time versus FrameFusion.
Significance. If the results hold, ForestPrune could advance efficient long-video processing in MLLMs by enabling high-ratio compression without training or fine-tuning. The training-free design and reported efficiency improvements (speed and accuracy) are clear strengths that address a practical bottleneck in video multimodal models.
major comments (2)
- [Abstract / Method] Abstract and method description: the assertion that scoring solely by tree depth and node roles yields a 'globally optimal pruning decision' is not supported by any formal argument, optimality proof, or counter-example analysis comparing it to alternatives such as attention-weighted or motion-magnitude criteria. This assumption is load-bearing for the superiority claims over baselines.
- [Experiments] Experiments section: the concrete claims (95.8% accuracy retention at 90% pruning for LLaVA-OneVision; +10.1% on MLVU) lack reported standard deviations, multiple random seeds, exact forest-construction thresholds, or per-video-type error analysis, leaving the robustness of the central empirical result only moderately supported.
minor comments (2)
- [Abstract] Abstract: the phrase 'a bunch of video benchmarks' is imprecise; list the exact benchmarks (MLVU and others) explicitly.
- [Method] Notation: define the precise semantic, spatial, and temporal constraint functions used to build the forests, as these are central to reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the assertion that scoring solely by tree depth and node roles yields a 'globally optimal pruning decision' is not supported by any formal argument, optimality proof, or counter-example analysis comparing it to alternatives such as attention-weighted or motion-magnitude criteria. This assumption is load-bearing for the superiority claims over baselines.
Authors: We acknowledge that the phrasing 'globally optimal' is heuristic rather than formally proven. It refers to the fact that the forest construction integrates semantic, spatial, and temporal constraints across all frames before scoring, unlike per-frame local decisions in baselines. We will revise the abstract and method sections to replace 'globally optimal' with 'effective pruning decision under the spatial-temporal forest model' and add a dedicated paragraph explaining the rationale for tree depth and node roles, including a brief comparison to attention-based alternatives supported by our existing ablations. revision: yes
-
Referee: [Experiments] Experiments section: the concrete claims (95.8% accuracy retention at 90% pruning for LLaVA-OneVision; +10.1% on MLVU) lack reported standard deviations, multiple random seeds, exact forest-construction thresholds, or per-video-type error analysis, leaving the robustness of the central empirical result only moderately supported.
Authors: We agree these details would strengthen the results. The method is deterministic after threshold selection, but we will rerun experiments with 3 seeds for any stochastic components, report standard deviations, specify exact thresholds (e.g., semantic similarity 0.8, spatial distance 0.5), and add per-video-type breakdowns for MLVU and similar benchmarks in the revised Experiments section and appendix. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The ForestPrune method defines token forests explicitly from semantic/spatial/temporal constraints and derives pruning decisions from tree-depth and node-role scoring; this is a direct construction of the algorithm rather than a reduction of an output claim to fitted parameters or prior self-citations. Performance claims (e.g., 95.8% accuracy retention at 90% pruning) are supported by external benchmark experiments on LLaVA-Video and LLaVA-OneVision rather than by internal re-derivation. No equations or sections in the provided text exhibit self-definitional loops, fitted-input predictions, load-bearing self-citations, or ansatz smuggling. The derivation remains self-contained against the stated heuristics and empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic, spatial, and temporal constraints suffice to construct token forests that capture video content for pruning decisions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ForestPrune construct token forests across video frames based on the semantic, spatial and temporal constraints... evaluates the importance of token trees and nodes based on tree depth and node roles, thereby obtaining a globally optimal pruning decision.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
OTT-Vid: Optimal Transport Temporal Token Compression for Video Large Language Models
OTT-Vid uses optimal transport with non-uniform token mass and locality-aware costs to dynamically allocate compression budgets across video frames, retaining 95.8% VQA and 73.9% VTG performance at 10% token retention.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. To- ken merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Auroracap: Efficient, performant video detailed captioning and a new benchmark
Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Sain- ing Xie, and Christopher D Manning. Auroracap: Efficient, performant video detailed captioning and a new benchmark. arXiv preprint arXiv:2410.03051, 2024
-
[6]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[7]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video- llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Instructblip: Towards general- purpose vision-language models with instruction tuning, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning, 2023
work page 2023
-
[11]
Pact: Pruning and clustering-based token re- duction for faster visual language models
Mohamed Dhouib, Davide Buscaldi, Sonia Vanier, and Ay- men Shabou. Pact: Pruning and clustering-based token re- duction for faster visual language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14582–14592, 2025
work page 2025
-
[12]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025
work page 2025
-
[13]
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shen- gen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. Framefusion: Combining similarity and importance for video token reduction on large visual language models.arXiv preprint arXiv:2501.01986, 2024
-
[14]
GLM-V Team. GLM-4.5v and GLM-4.1v-thinking: To- wards versatile multimodal reasoning with scalable rein- forcement learning.arXiv preprint arXiv:2507.01006, 2025. v5, 15 Aug 2025. Zhipu AI & Tsinghua University
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
work page 2017
-
[16]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
work page 2025
-
[17]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6700–6709, 2019
work page 2019
-
[18]
Multi-granular spatio-temporal to- ken merging for training-free acceleration of video llms
Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon-Young Lee, Seon Joo Kim, and Minho Shim. Multi-granular spatio-temporal to- ken merging for training-free acceleration of video llms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23990–24000, 2025
work page 2025
-
[19]
In defense of grid features for visual question answering
Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned- Miller, and Xinlei Chen. In defense of grid features for visual question answering. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 10267–10276, 2020
work page 2020
-
[20]
Yutao Jiang, Qiong Wu, Wenhao Lin, Wei Yu, and Yiyi Zhou. What kind of visual tokens do we need? training- free visual token pruning for multi-modal large language models from the perspective of graph. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4075– 4083, 2025
work page 2025
-
[21]
Zhenglun Kong, Yize Li, Fanhu Zeng, Lei Xin, Shvat Mes- sica, Xue Lin, Pu Zhao, Manolis Kellis, Hao Tang, and Marinka Zitnik. Token reduction should go beyond effi- ciency in generative models – from vision, language to mul- timodality, 2026
work page 2026
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023
work page 2023
-
[24]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, pages 19730–19742, 2023
work page 2023
-
[25]
VideoChat: Chat-Centric Video Understanding
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv Preprint, 2023. https://arxiv.org/abs/2305.06355
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024
work page 2024
-
[27]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, pages 323–340. Springer, 2024
work page 2024
-
[28]
Jianxin Liang, Xiaojun Meng, Yueqian Wang, Chang Liu, Qun Liu, and Dongyan Zhao. End-to-end video question an- swering with frame scoring mechanisms and adaptive sam- pling.arXiv Preprint, 2024.https://arxiv.org/ abs/2407.15047
-
[29]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual represen- tation by alignment before projection.arXiv preprint arXiv:2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[31]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[32]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024
work page 2024
-
[33]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024
work page 2024
-
[34]
Nvila: Efficient frontier visual lan- guage models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual lan- guage models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4122–4134, 2025
work page 2025
-
[35]
Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Yan Wang, Liujuan Cao, Yongjian Wu, Feiyue Huang, and Rongrong Ji. To- wards lightweight transformer via group-wise transforma- tion for vision-and-language tasks.IEEE Transactions on Image Processing, 31:3386–3398, 2022
work page 2022
-
[36]
Gen Luo, Yiyi Zhou, Minglang Huang, Tianhe Ren, Xi- aoshuai Sun, and Rongrong Ji. Moil: Momentum imita- tion learning for efficient vision-language adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[37]
Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Yongjian Wu, Yue Gao, and Rongrong Ji. Towards language-guided visual recog- nition via dynamic convolutions.International Journal of Computer Vision, 132(1):1–19, 2024
work page 2024
-
[38]
Feast your eyes: Mixture-of- resolution adaptation for multimodal large language models
Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xi- aoshuai Sun, and Rongrong Ji. Feast your eyes: Mixture-of- resolution adaptation for multimodal large language models. arXiv preprint arXiv:2403.03003, 2024
-
[39]
Video-chatgpt: Towards detailed video un- derstanding via large vision and language models
Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video un- derstanding via large vision and language models. InACL, pages 12585–12602, 2024
work page 2024
-
[40]
Yuanbin Man, Ying Huang, Chengming Zhang, Bingzhe Li, Wei Niu, and Miao Yin. Adacmˆ 2: On understanding ex- tremely long-term video with adaptive cross-modality mem- ory reduction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8534–8544, 2025
work page 2025
-
[41]
GPT-4O.https://openai.com/index/ hello-gpt-4o/, 2024
OpenAI. GPT-4O.https://openai.com/index/ hello-gpt-4o/, 2024
work page 2024
-
[42]
Filtering, distil- lation, and hard negatives for vision-language pre-training
Filip Radenovic, Abhimanyu Dubey, Abhishek Kadian, Todor Mihaylov, Simon Vandenhende, Yash Patel, Yi Wen, Vignesh Ramanathan, and Dhruv Mahajan. Filtering, distil- lation, and hard negatives for vision-language pre-training. InCVPR, pages 6967–6977, 2023
work page 2023
-
[43]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
work page 2021
-
[44]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857– 22867, 2025
work page 2025
-
[45]
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models.arXiv preprint arXiv:2505.21334, 2025
-
[46]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
- [47]
-
[48]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv Preprint, 2024.https://arxiv.org...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Sheng- long Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Longvlm: Efficient long video understand- ing via large language models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understand- ing via large language models. InEuropean Conference on Computer Vision, pages 453–470. Springer, 2024
work page 2024
-
[52]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context inter- leaved video-language understanding.arXiv Preprint, 2024. https://arxiv.org/abs/2407.15754
-
[53]
Qiong Wu, Wenhao Lin, Yiyi Zhou, Weihao Ye, Zhanpeng Zen, Xiaoshuai Sun, and Rongrong Ji. Accelerating multi- modal large language models via dynamic visual-token exit and the empirical findings.arXiv preprint arXiv:2411.19628, 2024
-
[54]
Routing experts: Learning to route dynamic ex- perts in existing multi-modal large language models
Qiong Wu, Zhaoxi Ke, Yiyi Zhou, Xiaoshuai Sun, and Ron- grong Ji. Routing experts: Learning to route dynamic ex- perts in existing multi-modal large language models. InThe Thirteenth International Conference on Learning Represen- tations, 2025
work page 2025
-
[55]
Qiong Wu, Yiyi Zhou, Weihao Ye, Xiaoshuai Sun, and Ron- grong Ji. Not all attention is needed: Parameter and compu- tation efficient tuning for multi-modal large language mod- els via effective attention skipping.International Journal of Computer Vision, 134(3):128, 2026
work page 2026
-
[56]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InCVPR, pages 9777–9786, 2021
work page 2021
-
[57]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy re- duction.arXiv preprint arXiv:2410.17247, 2024
work page internal anchor Pith review arXiv 2024
-
[58]
Chenyu Yang, Xuan Dong, Xizhou Zhu, Weijie Su, Jiahao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. Pvc: Progressive visual token compression for unified image and video processing in large vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24939–24949, 2025
work page 2025
-
[59]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, et al. Topv: Compatible token pruning with infer- ence time optimization for fast and low-memory multimodal vision language model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19803– 19813, 2025
work page 2025
-
[60]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19792–19802, 2025
work page 2025
-
[61]
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models.arXiv preprint arXiv:2409.10197, 2024
-
[62]
Atp-llava: Adaptive token pruning for large vision language models
Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-Ping Zhang, and Yansong Tang. Atp-llava: Adaptive token pruning for large vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24972– 24982, 2025
work page 2025
-
[63]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. InEMNLP, pages 543–553, 2023
work page 2023
-
[64]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
work page internal anchor Pith review arXiv 2024
-
[65]
Llava- next: A strong zero-shot video understanding model, 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava- next: A strong zero-shot video understanding model, 2024
work page 2024
-
[66]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Accelerating multimodal large language models by searching optimal vision token re- duction
Shiyu Zhao, Zhenting Wang, Felix Juefei-Xu, Xide Xia, Miao Liu, Xiaofang Wang, Mingfu Liang, Ning Zhang, Dim- itris N Metaxas, and Licheng Yu. Accelerating multimodal large language models by searching optimal vision token re- duction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29869–29879, 2025
work page 2025
-
[68]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: A comprehensive benchmark for multi-task long video understanding.arXiv Preprint, 2024.https: //arxiv.org/abs/2406.04264
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Yiyi Zhou, Rongrong Ji, Xiaoshuai Sun, Jinsong Su, Deyu Meng, Yue Gao, and Chunhua Shen. Plenty is plague: Fine- grained learning for visual question answering.IEEE trans- actions on pattern analysis and machine intelligence, 44(2): 697–709, 2019
work page 2019
-
[70]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Xin Zou, Di Lu, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Xu Zheng, Linfeng Zhang, and Xuming Hu. Don’t just chase” highlighted tokens” in mllms: Revisiting visual holistic con- text retention.arXiv preprint arXiv:2510.02912, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.