Recognition: 2 theorem links
· Lean TheoremOTT-Vid: Optimal Transport Temporal Token Compression for Video Large Language Models
Pith reviewed 2026-05-13 05:46 UTC · model grok-4.3
The pith
Video large language models can reduce their visual tokens to one-tenth using optimal transport between frames while keeping most question-answering and grounding accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
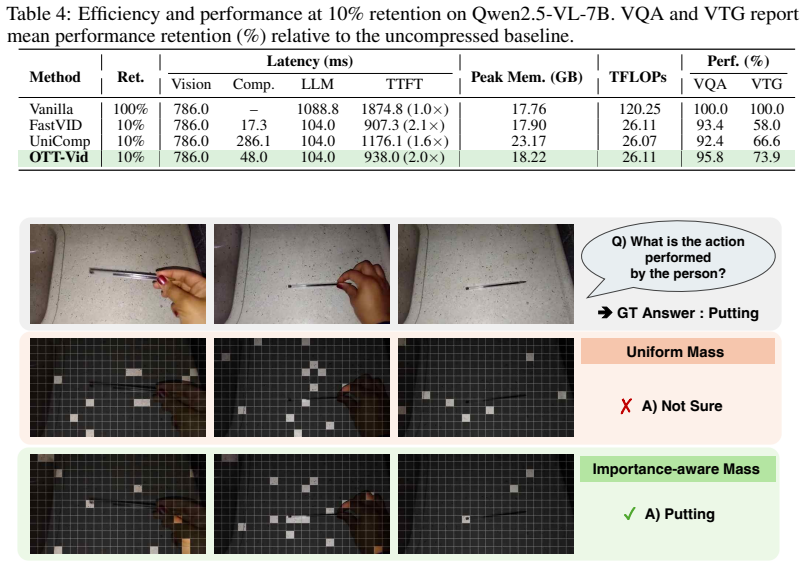
The central claim is that formulating optimal transport between adjacent frames with non-uniform token mass and a locality-aware cost produces a transport plan whose marginals identify tokens to retain and whose total cost measures frame-pair compressibility, enabling dynamic allocation of an overall compression budget that preserves high performance on video tasks at low token counts.
What carries the argument
The optimal transport plan solved between neighboring frames, which jointly encodes token importance via mass and compressibility via total cost.
If this is right
- Compression budgets can be allocated dynamically to each frame pair according to its measured transport difficulty rather than a fixed ratio.
- Tokens carrying higher mass in the transport formulation are protected from aggressive pruning.
- The two-stage process first reduces tokens inside each frame spatially and then decides temporal redundancy between frames.
- The same plan yields both the selection of retained tokens and the per-pair compression strength.
- No additional supervision or fine-tuning is required beyond the base Video-LLM.
Where Pith is reading between the lines
- Adjusting the locality cost term could let the method adapt to videos with fast camera motion without changing the overall framework.
- The transport-derived budgets might combine with existing spatial pruning techniques to reach even lower token counts on average.
- If the total transport cost correlates with downstream error, it could serve as a cheap proxy for deciding when to increase model context length instead of pruning.
- Extending the same mass-and-cost formulation to non-video sequences such as long audio or document streams would test whether the approach generalizes beyond visual tokens.
Load-bearing premise
That an optimal transport plan computed from non-uniform token mass and a locality-aware cost function can identify semantically important tokens and measure frame-pair compressibility without any model-specific training or extra supervision.
What would settle it
A controlled test on a new long-video benchmark in which forcing every frame pair to the same 10 percent token retention produces a measurable accuracy drop below the reported 95 percent VQA retention level.
Figures


read the original abstract
As Video Large Language Models (Video-LLMs) scale to longer and more complex videos, their inference cost grows rapidly due to the large volume of visual tokens accumulated across frames. Training-free token compression has emerged as a practical solution to this bottleneck. However, existing temporal compression methods rely primarily on cross-frame token similarity or segmentation heuristics, overlooking each token's semantic role within its frame and failing to adapt compression strength to the compressibility of each frame pair. In this work, we propose OTT-Vid, a transport-derived allocation framework for temporal token compression. Our approach consists of two stages: spatial pruning identifies representative content within each frame, and optimal transport (OT) is then solved between neighboring frames to estimate temporal compressibility. We formulate this OT with non-uniform token mass, which protects semantically important tokens from aggressive compression, and a locality-aware cost that captures both feature and spatial disparities. The resulting transport plan jointly balances token importance and matching cost, while its total cost defines the transport difficulty of each frame pair, which we use to allocate compression budgets dynamically. Experiments on six benchmarks spanning video question answering and temporal grounding show that OTT-Vid preserves 95.8% of VQA and 73.9% of VTG performance while retaining only 10% of tokens, consistently outperforming existing state-of-the-art training-free compression methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OTT-Vid, a training-free temporal token compression framework for Video-LLMs. It performs spatial pruning per frame followed by optimal transport between neighboring frames using non-uniform token mass (derived from spatial pruning) and a locality-aware cost function; the resulting transport plan determines per-pair compressibility, which is used to allocate dynamic token budgets. On six benchmarks for video question answering and temporal grounding, the method is reported to retain 95.8% of VQA and 73.9% of VTG performance while keeping only 10% of tokens and to outperform prior training-free baselines.
Significance. If the experimental claims hold under scrutiny, the work offers a practical, training-free approach to reducing inference cost in long-video Video-LLMs by leveraging optimal transport for joint importance-aware and temporally adaptive compression. The explicit use of non-uniform mass and dynamic budget allocation via transport cost distinguishes it from similarity- or heuristic-based alternatives and could influence subsequent compression research.
major comments (3)
- [§4 (Experiments)] §4 (Experiments) and associated tables: the headline retention figures (95.8% VQA, 73.9% VTG at 10% tokens) are presented without reported standard deviations, statistical significance tests, or ablation results isolating the contribution of non-uniform mass versus uniform mass and of the locality-aware cost versus a feature-only cost; these omissions leave the central claim that the OT plan reliably identifies semantically critical tokens unsupported by internal evidence.
- [§3.2 (Optimal Transport Formulation)] §3.2 (Optimal Transport Formulation): the transport plan is asserted to balance token importance and matching cost so that high-mass tokens are preferentially retained, yet no visualization, correlation analysis, or controlled comparison is supplied showing that retained tokens align with human-annotated important regions or model attention rather than low-level feature similarity; this assumption is load-bearing for the reported outperformance over prior methods.
- [§3.3 (Dynamic Budget Allocation)] §3.3 (Dynamic Budget Allocation): the total OT cost is used to set per-pair compression ratios, but the paper provides neither a sensitivity study on the cost-to-budget mapping function nor a comparison against fixed-ratio baselines under identical token budgets; without these controls it is unclear whether the dynamic allocation itself drives the gains or whether any reasonable adaptive scheme would suffice.
minor comments (3)
- [Abstract] The abstract and §1 list six benchmarks but do not name them explicitly; adding the exact dataset names and task types would improve reproducibility and context.
- [§3.2] Notation for the cost matrix C and marginals μ, ν in the OT problem could be made fully explicit (e.g., by writing the precise functional form of the locality term) to aid readers implementing the method.
- [§4] Figure captions and axis labels in the experimental plots would benefit from stating the exact token retention ratio and backbone model used in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor and validation that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated tables: the headline retention figures (95.8% VQA, 73.9% VTG at 10% tokens) are presented without reported standard deviations, statistical significance tests, or ablation results isolating the contribution of non-uniform mass versus uniform mass and of the locality-aware cost versus a feature-only cost; these omissions leave the central claim that the OT plan reliably identifies semantically critical tokens unsupported by internal evidence.
Authors: We agree that standard deviations, significance testing, and targeted ablations would provide stronger internal validation. In the revised manuscript we will report mean and standard deviation over three random seeds for the main results on all six benchmarks. We will also add two new ablation tables in §4: one comparing non-uniform token mass against uniform mass (with all other components fixed) and one comparing the locality-aware cost against a pure feature-based cost. These ablations will quantify the incremental contribution of each design choice to the reported retention rates. revision: yes
-
Referee: [§3.2 (Optimal Transport Formulation)] §3.2 (Optimal Transport Formulation): the transport plan is asserted to balance token importance and matching cost so that high-mass tokens are preferentially retained, yet no visualization, correlation analysis, or controlled comparison is supplied showing that retained tokens align with human-annotated important regions or model attention rather than low-level feature similarity; this assumption is load-bearing for the reported outperformance over prior methods.
Authors: The consistent outperformance on temporal-grounding benchmarks (which require precise localization of salient events) already supplies indirect evidence that the transport plan favors semantically relevant tokens. Nevertheless, we accept that direct inspection is valuable. In the revision we will add (i) qualitative visualizations of retained versus discarded tokens overlaid on sample frames, (ii) a quantitative correlation between per-token retention probability and the model’s cross-attention weights on the same frames, and (iii) a controlled comparison against a pure similarity-based baseline that uses identical token budgets but omits the mass term. revision: yes
-
Referee: [§3.3 (Dynamic Budget Allocation)] §3.3 (Dynamic Budget Allocation): the total OT cost is used to set per-pair compression ratios, but the paper provides neither a sensitivity study on the cost-to-budget mapping function nor a comparison against fixed-ratio baselines under identical token budgets; without these controls it is unclear whether the dynamic allocation itself drives the gains or whether any reasonable adaptive scheme would suffice.
Authors: We acknowledge that the current manuscript does not isolate the benefit of the cost-driven dynamic allocation. In the revised version we will include a sensitivity plot varying the scaling parameter of the cost-to-budget mapping across a range of values and report the resulting VQA and VTG scores. We will also add a direct comparison against two fixed-ratio baselines (uniform per-pair ratio and uniform per-frame ratio) that enforce exactly the same total token count as OTT-Vid on each video; this will clarify whether the adaptive allocation contributes beyond a reasonable non-adaptive scheme. revision: yes
Circularity Check
No circularity: OT application is a direct, non-reductive use of standard transport on external features
full rationale
The derivation applies optimal transport between neighboring-frame token sets using explicitly stated non-uniform mass (from spatial pruning) and locality-aware cost; the resulting plan and total cost are then used for dynamic budget allocation. No equation reduces the claimed performance retention (95.8 % VQA / 73.9 % VTG at 10 % tokens) to a fitted parameter or self-defined quantity inside the paper. The method is training-free and benchmark-evaluated on independent datasets; the central claim therefore rests on the external validity of the chosen mass/cost functions rather than on any internal tautology or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Optimal transport plans exist and can be solved for the chosen non-uniform mass and locality-aware cost functions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this OT with non-uniform token mass, which protects semantically important tokens from aggressive compression, and a locality-aware cost that captures both feature and spatial disparities. The resulting transport plan jointly balances token importance and matching cost, while its total cost defines the transport difficulty of each frame pair
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OTT-Vid preserves 95.8% of VQA and 73.9% of VTG performance while retaining only 10% of tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceedings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015
work page 2015
-
[4]
Pumer: Pruning and merging tokens for efficient vision language models
Qingqing Cao, Bhargavi Paranjape, and Hannaneh Hajishirzi. Pumer: Pruning and merging tokens for efficient vision language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pages 12736–12746, 2023
work page 2023
-
[5]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[6]
Janghoon Cho, Jungsoo Lee, Munawar Hayat, Kyuwoong Hwang, Fatih Porikli, and Sungha Choi. Floc: Facility location-based efficient visual token compression for long video under- standing.arXiv preprint arXiv:2511.00141, 2025
-
[7]
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
work page 2013
-
[8]
Jinhong Deng, Wen Li, Joey Tianyi Zhou, and Yang He. Scope: Saliency-coverage oriented token pruning for efficient multimodel llms.arXiv preprint arXiv:2510.24214, 2025
-
[9]
Pact: Pruning and clustering-based token reduction for faster visual language models
Mohamed Dhouib, Davide Buscaldi, Sonia Vanier, and Aymen Shabou. Pact: Pruning and clustering-based token reduction for faster visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14582– 14592, 2025
work page 2025
-
[10]
Junhao Du, Jialong Xue, Anqi Li, Jincheng Dai, and Guo Lu. Unified spatiotemporal token compression for video-llms at ultra-low retention.arXiv preprint arXiv:2603.21957, 2026
-
[11]
Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, and Zhuotao Tian. Flashvid: Efficient video large language models via training-free tree-based spatiotemporal token merging.arXiv preprint arXiv:2602.08024, 2026
-
[12]
Zhengyao Fang, Pengyuan Lyu, Chengquan Zhang, Guangming Lu, Jun Yu, and Wenjie Pei. Prune redundancy, preserve essence: Vision token compression in vlms via synergistic importance-diversity.arXiv preprint arXiv:2603.09480, 2026
-
[13]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[14]
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. Framefusion: Combining similarity and importance for video token reduction on large visual language models.arXiv preprint arXiv:2501.01986, 2025
-
[15]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275, 2017. 11
work page 2017
-
[16]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
work page 2025
-
[17]
Yihong Huang, Fei Ma, Yihua Shao, Jingcai Guo, Zitong Yu, Laizhong Cui, and Qi Tian. N\" uwa: Mending the spatial integrity torn by vlm token pruning.arXiv preprint arXiv:2602.02951, 2026
-
[18]
Multi-granular spatio-temporal token merging for training-free acceleration of video llms
Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon- Young Lee, Seon Joo Kim, and Minho Shim. Multi-granular spatio-temporal token merging for training-free acceleration of video llms. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[19]
Shaobo Ju, Baiyang Song, Tao Chen, Jiapeng Zhang, Qiong Wu, Chao Chang, HuaiXi Wang, Yiyi Zhou, and Rongrong Ji. Forestprune: High-ratio visual token compression for video multimodal large language models via spatial-temporal forest modeling.arXiv preprint arXiv:2603.22911, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. Token fusion: Bridging the gap between token pruning and token merging. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1383–1392, 2024
work page 2024
-
[21]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Token Reduction via Local and Global Contexts Optimization for Efficient Video Large Language Models
Jinlong Li, Liyuan Jiang, Haonan Zhang, and Nicu Sebe. Token reduction via local and global contexts optimization for efficient video large language models.arXiv preprint arXiv:2603.01400, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[24]
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models.arXiv preprint arXiv:2505.21334, 2025
-
[25]
arXiv preprint arXiv:2503.11187 (2025)
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, and Guiguang Ding. Fastvid: Dynamic density pruning for fast video large language models. arXiv preprint arXiv:2503.11187, 2025
-
[26]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
work page 2024
-
[29]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
work page 2025
-
[30]
Chao Yuan, Shimin Chen, Minliang Lin, Limeng Qiao, Guanglu Wan, and Lin Ma. Uni- comp: Rethinking video compression through informational uniqueness.arXiv preprint arXiv:2512.03575, 2025. 12
-
[31]
Jun Zhang, Teng Wang, Yuying Ge, Yixiao Ge, Xinhao Li, Ying Shan, and Limin Wang. Timelens: Rethinking video temporal grounding with multimodal llms.arXiv preprint arXiv:2512.14698, 2025
-
[32]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025
work page 2025
-
[33]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025. 13 A Additional Implementation Details Sinkhorn parameters.The OT ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.