Recognition: unknown
Positive-First Most Ambiguous: A Simple Active Learning Criterion for Interactive Retrieval of Rare Categories
Pith reviewed 2026-05-15 00:08 UTC · model grok-4.3
The pith
Positive-first ambiguous sampling retrieves rare visual categories more effectively by favoring likely positives near decision boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PF-MA selects near-boundary samples while favoring those likely to belong to the rare positive class, which enables rapid discovery of subtle visual categories in interactive fine-grained retrieval while keeping the selected samples informative for refining a lightweight classifier.
What carries the argument
The Positive-First Most Ambiguous (PF-MA) criterion, which ranks samples by their ambiguity score but adjusts to prefer probable positives over negatives in imbalanced settings.
If this is right
- Small annotation batches contain a higher fraction of positive samples, improving early retrieval performance.
- The proposed class coverage metric shows better spanning of visual variants for the target class.
- Classifier performance improves faster compared to symmetric active learning methods.
- The approach works across varying sizes of the rare class and different visual descriptors.
Where Pith is reading between the lines
- PF-MA could be integrated into existing interactive retrieval systems to reduce user annotation effort in domains with long-tailed distributions.
- The class coverage metric provides a way to evaluate not just precision but diversity in positive sample selection for other rare-event detection tasks.
- In practice, this might lead to higher user satisfaction due to seeing more relevant results sooner in the process.
Load-bearing premise
That prioritizing likely-positive boundary samples keeps them informative and avoids overlooking important visual variants of the rare class, with the coverage metric correctly quantifying that variability.
What would settle it
An experiment showing that PF-MA misses significant visual variants of the rare class or fails to outperform baselines in coverage despite its selection strategy.
Figures





read the original abstract
Real-world fine-grained visual retrieval often requires discovering a rare concept from large unlabeled collections with minimal supervision. This is especially critical in biodiversity monitoring, ecological studies, and long-tailed visual domains, where the target may represent only a tiny fraction of the data, creating highly imbalanced binary problems. Interactive retrieval with relevance feedback offers a practical solution: starting from a small query, the system selects candidates for binary user annotation and iteratively refines a lightweight classifier. While Active Learning (AL) is commonly used to guide selection, conventional AL assumes symmetric class priors and large annotation budgets, limiting effectiveness in imbalanced, low-budget, low-latency settings. We introduce Positive-First Most Ambiguous (PF-MA), a simple yet effective AL criterion that explicitly addresses the class imbalance asymmetry: it prioritizes near-boundary samples while favoring likely positives, enabling rapid discovery of subtle visual categories while maintaining informativeness. Unlike standard methods that oversample negatives, PF-MA consistently returns small batches with a high proportion of relevant samples, improving early retrieval and user satisfaction. To capture retrieval diversity, we also propose a class coverage metric that measures how well selected positives span the visual variability of the target class. Experiments on long-tailed datasets, including fine-grained botanical data, demonstrate that PF-MA consistently outperforms strong baselines in both coverage and classifier performance, across varying class sizes and descriptors. Our results highlight that aligning AL with the asymmetric and user-centric objectives of interactive fine-grained retrieval enables simple yet powerful solutions for retrieving rare and visually subtle categories in realistic human-in-the-loop settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Positive-First Most Ambiguous (PF-MA), a simple active learning criterion for interactive retrieval of rare visual categories from large unlabeled collections under extreme class imbalance. PF-MA selects near-boundary samples while favoring those with high estimated positive probability to enable rapid discovery with small annotation budgets. It also proposes a class coverage metric to quantify how well retrieved positives span the target's visual variability. Experiments on long-tailed datasets, including fine-grained botanical data, claim that PF-MA outperforms strong baselines in both coverage and downstream classifier performance across varying class sizes and descriptors.
Significance. If the empirical claims hold after addressing the initial-estimate reliability issue, the work would offer a practical, low-complexity solution for user-in-the-loop rare-category retrieval in domains such as biodiversity monitoring. The explicit handling of class-asymmetry and the introduction of the coverage metric address real gaps in standard active-learning practice for low-budget, high-imbalance settings. The method's simplicity is a genuine strength that could facilitate adoption.
major comments (2)
- [§3] §3 (PF-MA criterion definition): the selection rule relies on positive-probability estimates from a lightweight classifier trained on a tiny initial positive set. Under the extreme imbalance emphasized in the low-budget regime, these estimates are likely poorly calibrated or majority-biased, which could systematically discard informative boundary positives belonging to underrepresented visual variants. This assumption is load-bearing for the claim of improved early retrieval and requires explicit validation (e.g., calibration plots or per-iteration ablation).
- [§5] §5 (Experiments): the reported consistent outperformance lacks error bars, number of runs, statistical significance tests, and an ablation isolating the positive-first bias from standard uncertainty sampling. Without these, the magnitude and robustness of gains in coverage and classifier performance cannot be properly assessed.
minor comments (2)
- [Abstract] Abstract: name the 'strong baselines' explicitly (e.g., uncertainty sampling, core-set) rather than leaving them generic.
- [§4] §4 (class coverage metric): provide a formal equation or pseudocode for the metric to clarify how it quantifies visual variability beyond the current prose description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses to the major comments below, indicating the changes we have made or will make in the revised version.
read point-by-point responses
-
Referee: [§3] §3 (PF-MA criterion definition): the selection rule relies on positive-probability estimates from a lightweight classifier trained on a tiny initial positive set. Under the extreme imbalance emphasized in the low-budget regime, these estimates are likely poorly calibrated or majority-biased, which could systematically discard informative boundary positives belonging to underrepresented visual variants. This assumption is load-bearing for the claim of improved early retrieval and requires explicit validation (e.g., calibration plots or per-iteration ablation).
Authors: We agree that validating the calibration of the positive probability estimates is important for substantiating the method's effectiveness under extreme imbalance. In the revised manuscript, we have included calibration plots for the classifier at key iterations to show that the estimates, while not perfect, are sufficiently reliable to guide selection without systematically discarding boundary positives. We have also added a per-iteration analysis demonstrating the contribution of the positive-first component. revision: yes
-
Referee: [§5] §5 (Experiments): the reported consistent outperformance lacks error bars, number of runs, statistical significance tests, and an ablation isolating the positive-first bias from standard uncertainty sampling. Without these, the magnitude and robustness of gains in coverage and classifier performance cannot be properly assessed.
Authors: We acknowledge the need for greater statistical rigor in the experimental results. The revised manuscript now reports performance averaged over 5 independent runs with error bars showing the standard deviation. We have performed statistical significance tests (using paired t-tests) to confirm the improvements are significant. Additionally, we have included an ablation study that compares PF-MA against standard uncertainty sampling to isolate the effect of the positive-first bias. revision: yes
Circularity Check
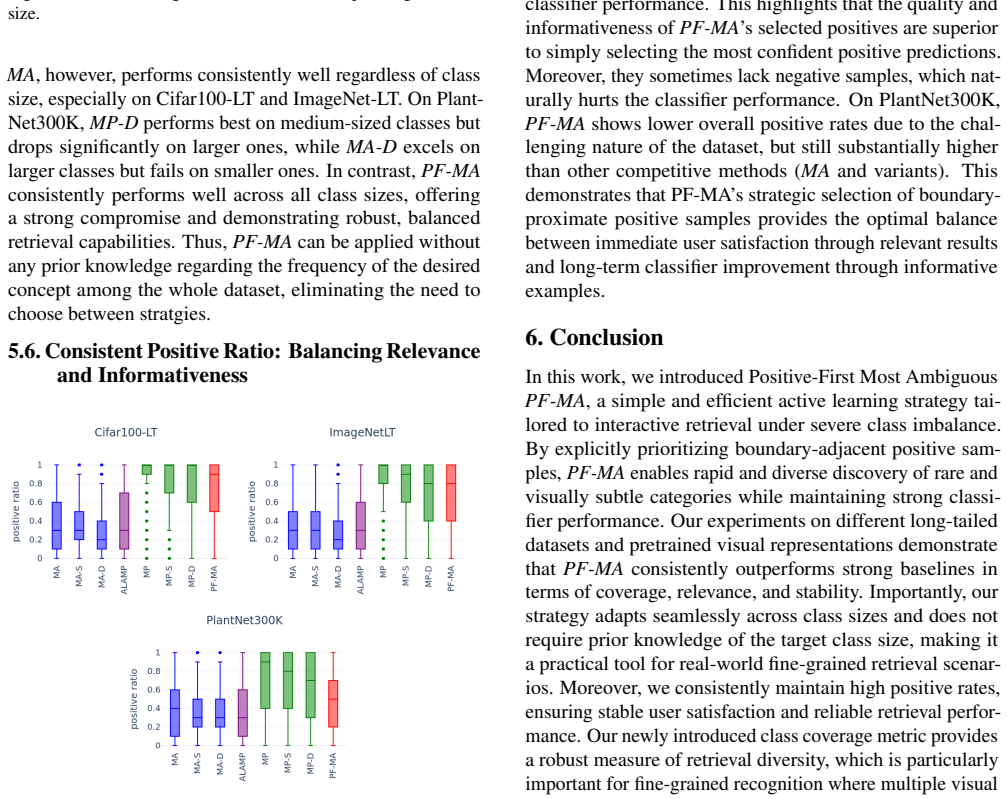
PF-MA criterion is a direct heuristic definition with no circular reductions
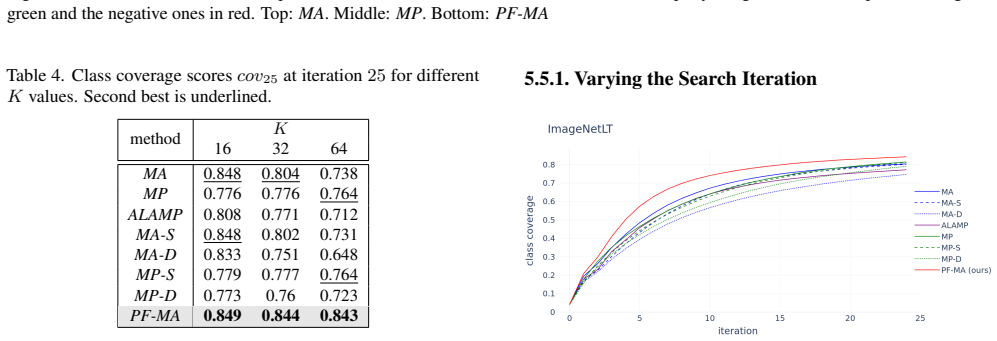
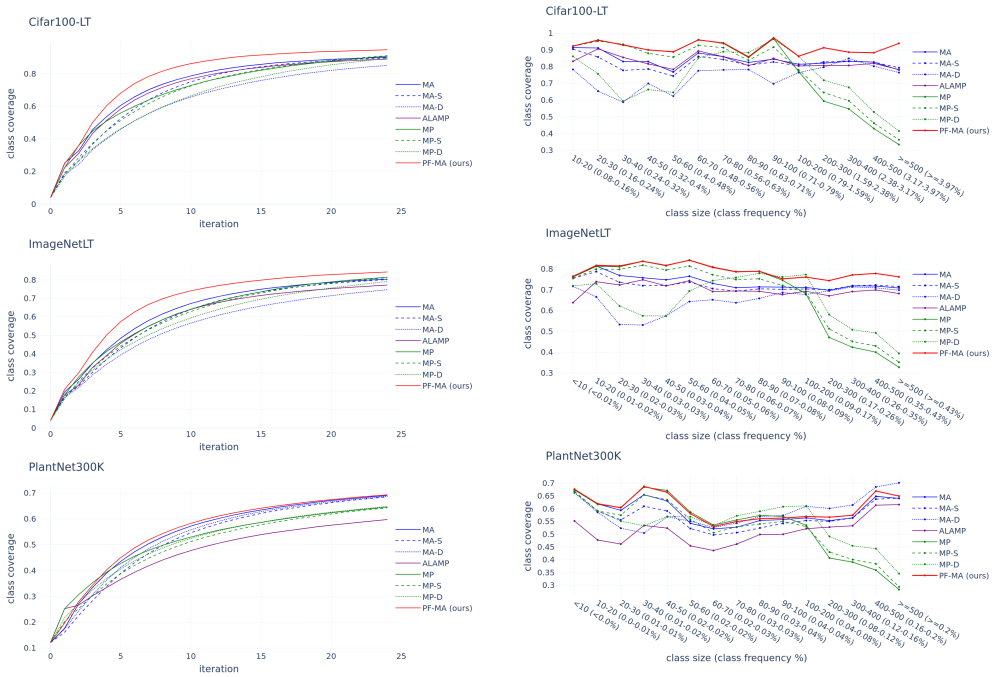
full rationale
The paper presents Positive-First Most Ambiguous (PF-MA) as an explicitly defined active learning selection rule that prioritizes near-boundary samples while favoring high positive probability estimates. No equations, derivations, or self-citations are shown that reduce this rule to fitted parameters, self-referential predictions, or imported uniqueness theorems from prior author work. The class coverage metric is introduced separately as an evaluation measure for visual variability rather than a load-bearing component of any derivation. All claims rest on empirical comparisons against baselines rather than tautological constructions, making the contribution self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ac- tive learning for imbalanced datasets
Umang Aggarwal, Adrian Popescu, and C´eline Hudelot. Ac- tive learning for imbalanced datasets. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1428–1437, 2020. 3
work page 2020
-
[2]
Mi- nority class oriented active learning for imbalanced datasets
Umang Aggarwal, Adrian Popescu, and C´eline Hudelot. Mi- nority class oriented active learning for imbalanced datasets. In2020 25th International Conference on Pattern Recognition (ICPR), pages 9920–9927. IEEE, 2021. 3
work page 2021
-
[3]
Op- timizing active learning for low annotation budgets.arXiv preprint arXiv:2201.07200, 2022
Umang Aggarwal, Adrian Popescu, and C´eline Hudelot. Op- timizing active learning for low annotation budgets.arXiv preprint arXiv:2201.07200, 2022. 3, 5
-
[4]
Josh Attenberg andS ¸eyda Ertekin. Class imbalance and active learning.Imbalanced Learning: Foundations, Algorithms, and Applications, pages 101–149, 2013. 3
work page 2013
-
[5]
Neural codes for image retrieval
Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Vic- tor Lempitsky. Neural codes for image retrieval. InEuropean conference on computer vision, pages 584–599. Springer,
-
[6]
Leah Bar, Boaz Lerner, Nir Darshan, and Rami Ben-Ari. Active learning via classifier impact and greedy selection for interactive image retrieval.arXiv preprint arXiv:2412.02310,
-
[7]
Information-theoretic active learning for content-based image retrieval
Bj¨orn Barz, Christoph K ¨ading, and Joachim Denzler. Information-theoretic active learning for content-based image retrieval. InGerman conference on pattern recognition, pages 650–666. Springer, 2018. 3
work page 2018
-
[8]
Towards open set deep networks
Abhijit Bendale and Terrance E Boult. Towards open set deep networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1563–1572,
-
[9]
Class-balanced active learn- ing for image classification
Javad Zolfaghari Bengar, Joost van de Weijer, Laura Lopez Fuentes, and Bogdan Raducanu. Class-balanced active learn- ing for image classification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1536–1545, 2022. 3
work page 2022
-
[10]
Incorporating diversity in active learning with support vector machines
Klaus Brinker. Incorporating diversity in active learning with support vector machines. InProceedings of the 20th international conference on machine learning (ICML-03), pages 59–66, 2003. 2
work page 2003
-
[11]
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label- distribution-aware margin loss.Advances in neural informa- tion processing systems, 32, 2019. 5
work page 2019
-
[12]
Ingemar J Cox, Matt L Miller, Thomas P Minka, Thomas V Papathomas, and Peter N Yianilos. The bayesian image re- trieval system, pichunter: theory, implementation, and psy- chophysical experiments.IEEE transactions on image pro- cessing, 9(1):20–37, 2000. 2
work page 2000
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Class balancing for efficient active learning in imbalanced datasets
Yaron Fairstein, Oren Kalinsky, Zohar Karnin, Guy Kushile- vitz, Alexander Libov, and Sofia Tolmach. Class balancing for efficient active learning in imbalanced datasets. InPro- ceedings of The 18th Linguistic Annotation Workshop (LAW- XVIII), pages 77–86, 2024. 3
work page 2024
-
[15]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.arXiv preprint arXiv:2210.02410, 2022. 4
-
[16]
Pl@ ntnet- 300k: a plant image dataset with high label ambiguity and a long-tailed distribution
Camille Garcin, Alexis Joly, Pierre Bonnet, Jean-Christophe Lombardo, Antoine Affouard, Mathias Chouet, Maximilien Servajean, Titouan Lorieul, and Joseph Salmon. Pl@ ntnet- 300k: a plant image dataset with high label ambiguity and a long-tailed distribution. InNeurIPS 2021-35th Conference on Neural Information Processing Systems, 2021. 5
work page 2021
-
[17]
Discriminative Active Learning
Daniel Gissin and Shai Shalev-Shwartz. Discriminative active learning.arXiv preprint arXiv:1907.06347, 2019. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[18]
Philippe Henri Gosselin and Matthieu Cord. Active learning methods for interactive image retrieval.IEEE Transactions on Image Processing, 17(7):1200–1211, 2008. 3
work page 2008
-
[19]
Content-based image retrieval: A review of recent trends.Cogent Engineering, 8(1):1927469, 2021
Ibtihaal M Hameed, Sadiq H Abdulhussain, and Basheera M Mahmmod. Content-based image retrieval: A review of recent trends.Cogent Engineering, 8(1):1927469, 2021. 2
work page 2021
-
[20]
Alexis Joly, Pierre Bonnet, Herv ´e Go ¨eau, Julien Barbe, Souheil Selmi, Julien Champ, Samuel Dufour-Kowalski, An- toine Affouard, Jennifer Carr´e, Jean-Franc ¸ois Molino, et al. A look inside the pl@ ntnet experience: The good, the bias and the hope.Multimedia Systems, 22(6):751–766, 2016. 3
work page 2016
-
[21]
Towards open world object detec- tion
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vi- neeth N Balasubramanian. Towards open world object detec- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 5830–5840, 2021. 3
work page 2021
-
[22]
Suraj Kothawade, Nathan Beck, Krishnateja Killamsetty, and Rishabh Iyer. Similar: Submodular information measures based active learning in realistic scenarios.Advances in Neu- ral Information Processing Systems, 34:18685–18697, 2021. 3
work page 2021
-
[23]
David D. Lewis and William A. Gale. A sequential algorithm for training text classifiers, 1994. 2
work page 1994
-
[24]
Dongyuan Li, Zhen Wang, Yankai Chen, Renhe Jiang, Weip- ing Ding, and Manabu Okumura. A survey on deep active learning: Recent advances and new frontiers.IEEE Trans- actions on Neural Networks and Learning Systems, 36(4): 5879–5899, 2024. 2
work page 2024
-
[25]
Large-scale long-tailed recog- nition in an open world
Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X Yu. Large-scale long-tailed recog- nition in an open world. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2537–2546, 2019. 5
work page 2019
-
[26]
Fun- damentals of content-based image retrieval
Fuhui Long, Hongjiang Zhang, and David Dagan Feng. Fun- damentals of content-based image retrieval. InMultimedia Information Retrieval and Management: Technological Fun- damentals and Applications, pages 1–26. Springer, 2003. 2
work page 2003
-
[27]
Robert Munro Monarch.Human-in-the-Loop Machine Learn- ing: Active learning and annotation for human-centered AI. Simon and Schuster, 2021. 2
work page 2021
-
[28]
Giang Truong Ngo, Tao Quoc Ngo, and Dung Duc Nguyen. Image retrieval with relevance feedback using svm active learning.International Journal of Electrical and Computer Engineering, 6(6):3238, 2016. 1, 2 9
work page 2016
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Yuxin Peng, Xiangteng He, and Junjie Zhao. Object-part attention model for fine-grained image classification.IEEE Transactions on Image Processing, 27(3):1487–1500, 2017. 3
work page 2017
-
[31]
Fine- grained visual categorization via multi-stage metric learning
Qi Qian, Rong Jin, Shenghuo Zhu, and Yuanqing Lin. Fine- grained visual categorization via multi-stage metric learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3716–3724, 2015. 3
work page 2015
-
[32]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 5
work page 2021
-
[33]
Joseph John Rocchio Jr. Relevance feedback in informa- tion retrieval.The SMART retrieval system: experiments in automatic document processing, 1971. 2
work page 1971
-
[34]
Active hidden markov models for information extraction
Tobias Scheffer, Christian Decomain, and Stefan Wrobel. Active hidden markov models for information extraction. In International symposium on intelligent data analysis, pages 309–318. Springer, 2001. 2
work page 2001
-
[35]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolu- tional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Active learning literature survey
Burr Settles. Active learning literature survey. 2009. 2
work page 2009
-
[37]
Yisheng Song, Ting Wang, Puyu Cai, Subrota K Mondal, and Jyoti Prakash Sahoo. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportuni- ties.ACM Computing Surveys, 55(13s):1–40, 2023. 2
work page 2023
-
[38]
Divya Srivastava, Shashank Sheshar Singh, B Rajitha, Mad- hushi Verma, Manjit Kaur, and Heung-No Lee. Content-based image retrieval: A survey on local and global features selec- tion, extraction, representation and evaluation parameters. IEEE Access, 2023. 2
work page 2023
-
[39]
Support vector machine active learning for image retrieval
Simon Tong and Edward Chang. Support vector machine active learning for image retrieval. InProceedings of the ninth ACM international conference on Multimedia, pages 107–118, 2001. 2
work page 2001
-
[40]
Novel class discovery: an introduction and key concepts.arXiv preprint arXiv:2302.12028, 2023
Colin Troisemaine, Vincent Lemaire, St ´ephane Gosselin, Alexandre Reiffers-Masson, Joachim Flocon-Cholet, and San- drine Vaton. Novel class discovery: an introduction and key concepts.arXiv preprint arXiv:2302.12028, 2023. 2
-
[41]
Relevance feedback in deep convolutional neural networks for content based image retrieval
Maria Tzelepi and Anastasios Tefas. Relevance feedback in deep convolutional neural networks for content based image retrieval. InProceedings of the 9th hellenic conference on artificial intelligence, pages 1–7, 2016. 2
work page 2016
-
[42]
Deep Learning for Fine-Grained Image Analysis: A Survey
Xiu-Shen Wei, Jianxin Wu, and Quan Cui. Deep learning for fine-grained image analysis: A survey.arXiv preprint arXiv:1907.03069, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[43]
Incorporating di- versity and density in active learning for relevance feedback
Zuobing Xu, Ram Akella, and Yi Zhang. Incorporating di- versity and density in active learning for relevance feedback. InAdvances in Information Retrieval: 29th European Con- ference on IR Research, ECIR 2007, Rome, Italy, April 2-5,
work page 2007
-
[44]
Proceedings 29, pages 246–257. Springer, 2007. 2 10 Positive-First Most Ambiguous: A Simple Active Learning Criterion for Interactive Retrieval of Rare Categories Supplementary Material
work page 2007
-
[45]
5 shows the performance of representative-based AL methods for different iterations
Performance of Representativeness-based AL Strategies Across Iterations Tab. 5 shows the performance of representative-based AL methods for different iterations. The strong performance of the uncertainty-based sampling strategy is consistent from the early retrieval stage. Table 5. Performance comparison of representativeness-based AL methods vs. uncertai...
-
[46]
Influence of Coverage Granularity over Iter- ations Tab. 6 extends the results of the effect of coverage granularity on each method’s performance to earlier iterations. The results are obtained on ImageNet-LT, using DINOv2 features. Our methods consistently shows strong and stable results since the early retrieval stages, rendering it robust to the choice...
-
[47]
Performance Across Multiple Datasets and Feature Descriptors 9.1. Class coverage scores We report the class coverage scores of the different methods, datasets and feature extractors in Tab. 7, across different iter- ations. The results highlight consistently strong performance ofPF-MAsince the early stages of retrieval. Other methods do not keep consisten...
-
[48]
Performance Across the Search Iterations and Per range of Class Size 10.1. Class coverage scores Fig. 7 and Fig. 8 show the strong performance ofPF-MA across iterations and per range of class size, for different datasets. The results are less pronounced on PlantNet300K because of its specific nature.MPand variants perform well on smaller classes, but they...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.