Recognition: 2 theorem links
· Lean TheoremWMF-AM: Probing LLM Working Memory via Depth-Parameterized Cumulative State Tracking
Pith reviewed 2026-05-14 21:57 UTC · model grok-4.3
The pith
LLMs exhibit performance degradation in cumulative state tracking as the depth of sequential operations increases within a single query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WMF-AM isolates within-pass cumulative load by parameterizing depth K in tasks that require maintaining running states across sequential operations. Performance on arithmetic accumulation and matched non-arithmetic variants declines as K grows, with construct-isolation ablations verifying that this reflects working memory limits on cumulative tracking rather than other factors.
What carries the argument
Depth-parameterized cumulative state tracking, which varies the number of sequential operations K to isolate the load of maintaining intermediate results in a single pass.
If this is right
- Models across sizes and families show similar patterns of degradation with increasing K.
- The probe generalizes beyond arithmetic to domains like permissions and inventories.
- Three ablations isolate cumulative load as the primary driver of difficulty.
- The method provides a recalibratable diagnostic as models advance.
Where Pith is reading between the lines
- Architectural changes may be needed to improve internal state maintenance beyond further scaling.
- The probe could compare training methods for better performance on sequential reasoning.
- Similar depth-dependent effects may appear in other untested sequential domains.
Load-bearing premise
The arithmetic and non-arithmetic variants together with the ablations isolate cumulative state tracking without leaving domain-specific confounds that affect the results.
What would settle it
Observing no performance degradation with increasing K in the main tasks or in the ablated versions would indicate that cumulative load is not the isolated driver.
Figures




read the original abstract
Existing large language models (LLMs) evaluations use fixed-difficulty benchmarks that cannot adapt as models improve, and rarely isolate specific cognitive processes. We introduce Working Memory Fidelity-Active Manipulation (WMF-AM), a probe of cumulative state tracking, the ability to maintain and update intermediate results across K sequential operations within a single query, without a scratchpad. Unlike multi-step agent benchmarks that stress task orchestration, WMF-AM isolates within-pass cumulative load by parameterizing depth K. The core probe uses arithmetic accumulation on 28 models from 12 families (0.5B to frontier); a matched non-arithmetic extension (permissions, schedules, inventories) confirms the design generalizes beyond arithmetic. Three construct-isolation ablations confirm that cumulative load, not arithmetic skill or entity tracking, drives difficulty. We release WMF-AM as a lightweight, recalibratable diagnostic for characterizing where models degrade under cumulative load. Code and data can be accessed at https://github.com/dengzhe-hou/WMF-AM
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WMF-AM, a benchmark that parameterizes depth K to probe LLMs' cumulative state tracking ability in sequential operations within a single query without scratchpad. It evaluates 28 models from 12 families (0.5B to frontier) on arithmetic accumulation tasks, includes a matched non-arithmetic extension (permissions, schedules, inventories), and reports three construct-isolation ablations intended to show that performance degradation is driven by cumulative load rather than arithmetic skill or entity tracking. The benchmark is positioned as a lightweight, recalibratable diagnostic and is released with code and data.
Significance. If the isolation of cumulative state tracking holds after addressing confounds, WMF-AM would supply a scalable, depth-parameterized diagnostic that complements fixed-difficulty benchmarks and multi-step agent evaluations. Its coverage across model scales and families, plus the non-arithmetic generalization, would make it a practical tool for tracking where models degrade under increasing within-pass load, with potential to inform architecture and training choices for better state maintenance.
major comments (2)
- [Abstract (ablations description)] The claim that the three construct-isolation ablations confirm cumulative load (rather than arithmetic skill or entity tracking) as the driver of difficulty is load-bearing for the central contribution, yet the design inherently increases prompt length and token count with K. No explicit controls for general long-context degradation or sequence-position effects (e.g., length-matched non-accumulation baselines or fixed-position variants) are described, leaving open the possibility that observed degradation reflects context-length sensitivity instead of state-tracking load specifically.
- [Abstract] The abstract states that tests were run on 28 models with three ablations and a non-arithmetic extension, but supplies no quantitative results, error bars, per-model metrics, or exclusion criteria. Without these data (presumably in the results section or tables), it is impossible to assess effect sizes, statistical reliability, or whether the ablations actually succeeded in isolating the target construct.
minor comments (1)
- [Abstract] The abstract could more precisely define 'within-pass cumulative load' and explicitly contrast WMF-AM with chain-of-thought or scratchpad methods to avoid reader confusion about the no-scratchpad constraint.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript introducing WMF-AM. We address each major comment point by point below. We have revised the manuscript to incorporate additional controls and quantitative details where the comments identify areas for strengthening the presentation of results and isolation of the target construct.
read point-by-point responses
-
Referee: [Abstract (ablations description)] The claim that the three construct-isolation ablations confirm cumulative load (rather than arithmetic skill or entity tracking) as the driver of difficulty is load-bearing for the central contribution, yet the design inherently increases prompt length and token count with K. No explicit controls for general long-context degradation or sequence-position effects (e.g., length-matched non-accumulation baselines or fixed-position variants) are described, leaving open the possibility that observed degradation reflects context-length sensitivity instead of state-tracking load specifically.
Authors: We acknowledge that increasing K necessarily lengthens the prompt, which could introduce a potential confound with general long-context sensitivity. The original ablations were designed to hold arithmetic operations and entity counts constant while varying only the cumulative update requirement, and the matched non-arithmetic extension (permissions, schedules, inventories) provides a control for arithmetic skill. However, to more directly address length and position effects, we will add length-matched non-accumulation baselines (e.g., repeated non-cumulative operations of equivalent token length) and fixed-position variants in the revised manuscript. These additions will allow explicit comparison of degradation under matched lengths but differing state-tracking demands. revision: yes
-
Referee: [Abstract] The abstract states that tests were run on 28 models with three ablations and a non-arithmetic extension, but supplies no quantitative results, error bars, per-model metrics, or exclusion criteria. Without these data (presumably in the results section or tables), it is impossible to assess effect sizes, statistical reliability, or whether the ablations actually succeeded in isolating the target construct.
Authors: The full manuscript reports all requested details in the Experiments, Results, and Ablations sections: per-model accuracy tables across the 28 models, degradation curves with standard error bars from multiple runs, specific ablation outcomes (e.g., performance when arithmetic skill is controlled), and exclusion criteria for model sizes and task variants. To make these findings immediately visible, we will revise the abstract to include key quantitative highlights such as average accuracy drop per increment in K and the proportion of variance explained by the cumulative-load ablations. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction
full rationale
The paper introduces WMF-AM as an empirical diagnostic probe that parameterizes task depth K and measures LLM performance degradation on cumulative state tracking via direct model evaluations on arithmetic and non-arithmetic variants across 28 models. No equations, derivations, fitted parameters, or predictions appear in the work; results derive from raw output comparisons and three ablations rather than any self-referential reduction or self-citation chain. The central claims rest on observable performance patterns under controlled prompt variations, with no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cumulative state tracking can be isolated from arithmetic skill and entity tracking through matched task variants and targeted ablations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WMF-AM isolates within-pass cumulative load by parameterizing depth K... three construct-isolation ablations confirm that cumulative load, not arithmetic skill or entity tracking, drives difficulty.
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
K-sweep... sigmoid-cliff collapse... Kcrit spans 1.3 to 55.3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[2]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Bran Labash, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
work page 2023
-
[3]
WebShop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[4]
Shengda Fan, Xuyan Ye, Yupeng Huo, Zhi-Yuan Chen, Yiju Guo, Shenzhi Yang, Wenkai Yang, Shuqi Ye, Jingwen Chen, Haotian Chen, et al. AgentProcessBench: Diagnosing step-level process quality in tool-using agents.arXiv preprint arXiv:2603.14465, 2026
-
[5]
Sixiong Xie, Zhuofan Shi, Haiyang Shen, Gang Huang, Yun Ma, and Xiang Jing. M3-bench: Process-aware evaluation of llm agents social behaviors in mixed-motive games.arXiv preprint arXiv:2601.08462, 2026
-
[6]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Measur- ing what matters: Construct validity in LLM benchmarks
Andrew M Bean, Marijn Jansen, Nicolas Baumard, Sarah Mathew, and Alberto Acerbi. Measur- ing what matters: Construct validity in LLM benchmarks. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2025
work page 2025
-
[9]
Lee J. Cronbach and Paul E. Meehl. Construct validity in psychological tests.Psychological Bulletin, 52(4):281–302, 1955
work page 1955
-
[10]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 2020
work page 2020
-
[11]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 2020
work page 2020
-
[12]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[14]
Alan D. Baddeley and Graham J. Hitch. Working memory.Psychology of Learning and Motivation, 8:47–89, 1974
work page 1974
-
[15]
Nelson Cowan. The magical number 4 in short-term memory: A reconsideration of mental storage capacity.Behavioral and Brain Sciences, 24(1):87–114, 2001
work page 2001
-
[16]
George A. Miller. The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological Review, 63(2):81–97, 1956
work page 1956
-
[17]
Working memory identifies reasoning limits in language models
Chunhui Zhang, Yiren Jian, Zhongyu Ouyang, and Soroush V osoughi. Working memory identifies reasoning limits in language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16896–16922, 2024
work page 2024
-
[18]
Exploring working memory capacity in LLMs: From stressors to human-inspired strategies
Eunjin Hong, Sumin Cho, and Juae Kim. Exploring working memory capacity in LLMs: From stressors to human-inspired strategies. InProceedings of the 14th International Joint Conference on Natural Language Processing (IJCNLP-AACL), 2025
work page 2025
-
[19]
Language models do not have human-like working memory.arXiv preprint arXiv:2505.10571, 2025
Jen-tse Huang, Kaiser Sun, Wenxuan Wang, and Mark Dredze. Language models do not have human-like working memory.arXiv preprint arXiv:2505.10571, 2025
-
[20]
Minerva: A programmable memory test benchmark for language models
Menglin Xia, Victor Ruehle, Saravan Rajmohan, and Reza Shokri. Minerva: A programmable memory test benchmark for language models. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[21]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941, 2025
-
[22]
Randall W. Engle, Stephen W. Tuholski, James E. Laughlin, and Andrew R. A. Conway. Working memory, short-term memory, and general fluid intelligence: A latent-variable approach. Journal of Experimental Psychology: General, 128(3):309–331, 1999
work page 1999
- [23]
-
[24]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamile Lukosiute, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rauber, Sam McCandlish, Catherine Olsson, Tom Henighan, Tristan Hume, Zac Hatfield-Dodds, Jared Kaplan, Jack Clark, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Fragile Thoughts: How Large Language Models Handle Chain-of-Thought Perturbations
Ashwath Vaithinathan Aravindan and Mayank Kejriwal. Fragile thoughts: How large language models handle chain-of-thought perturbations.arXiv preprint arXiv:2603.03332, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
work page 2022
-
[27]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[28]
Enyi Jiang, Changming Xu, Nischay Singh, Tian Qiu, and Gagandeep Singh. Robust an- swers, fragile logic: Probing the decoupling hypothesis in LLM reasoning.arXiv preprint arXiv:2505.17406, 2025. 11
-
[29]
Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narang, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
work page 2023
-
[30]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
work page 2023
- [31]
-
[32]
Abigail Z. Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (F AccT), pages 375–385, 2021
work page 2021
-
[33]
Entity tracking in language models
Najoung Kim and Sebastian Schuster. Entity tracking in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
work page 2023
-
[34]
Exploring state tracking capabilities of large language models.arXiv preprint arXiv:2511.10457, 2025
Kiamehr Rezaee, Jose Camacho-Collados, and Mohammad Taher Pilehvar. Exploring state tracking capabilities of large language models.arXiv preprint arXiv:2511.10457, 2025
-
[35]
Li, Zifan Carl Guo, and Jacob Andreas
Belinda Z. Li, Zifan Carl Guo, and Jacob Andreas. (how) do language models track state?arXiv preprint arXiv:2503.02854, 2025
-
[36]
Karin de Langis, Jong Inn Park, Bin Hu, Khanh Chi Le, Andreas Schramm, Michael C Mensink, Andrew Elfenbein, and Dongyeop Kang. Strong memory, weak control: An empirical study of executive functioning in llms.arXiv preprint arXiv:2504.02789, 2025
-
[37]
Faiz Ghifari Haznitrama, Faeyza Rishad Ardi, and Alice Oh. A neuropsychologically grounded evaluation of LLM cognitive abilities.arXiv preprint arXiv:2603.02540, 2026
-
[38]
Chupei Wang and Jiaqiu Vince Sun. Unable to forget: Proactive interference reveals working memory limits in LLMs beyond context length.arXiv preprint arXiv:2506.08184, 2025
-
[39]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022
work page 2022
-
[40]
Weiwei Wang, Jiyong Min, and Weijie Zou. Intelligence degradation in long-context llms: Critical threshold determination via natural length distribution analysis.arXiv preprint arXiv:2601.15300, 2026
-
[41]
Easy2hard- bench: Standardized difficulty labels for profiling llm performance and generalization
Zhiyuan Yuan, Jiawei Zhang, Changlong Li, Zhongyi Xu, Fei Liu, and Ning Chen. Easy2hard- bench: Standardized difficulty labels for profiling llm performance and generalization. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
work page 2024
-
[42]
Sai Teja Reddy Adapala. Cognitive load limits in large language models: Benchmarking multi-hop reasoning.arXiv preprint arXiv:2509.19517, 2025
-
[43]
Alan Baddeley. The episodic buffer: a new component of working memory?Trends in Cognitive Sciences, 4(11):417–423, 2000
work page 2000
-
[44]
Cognitive load during problem solving: Effects on learning.Cognitive Science, 12(2):257–285, 1988
John Sweller. Cognitive load during problem solving: Effects on learning.Cognitive Science, 12(2):257–285, 1988
work page 1988
-
[45]
Andrew R. A. Conway, Michael J. Kane, Michael F. Bunting, D. Zachary Hambrick, Oliver Wilhelm, and Randall W. Engle. Working memory span tasks: A methodological review and user’s guide.Psychonomic Bulletin & Review, 12(5):769–786, 2005
work page 2005
-
[46]
Klaus Oberauer, Stephan Lewandowsky, Edward Awh, Gordon D. A. Brown, Andrew Conway, Nelson Cowan, Christopher Donkin, Simon Farrell, Graham J. Hitch, Mark J. Hurlstone, Wei Ji Ma, Candice C. Morey, Derek Evan Nee, Judith Schweppe, Evie Vergauwe, and Geoff Ward. Benchmarks for models of short-term and working memory.Psychological Bulletin, 144(9): 885–958,...
work page 2018
-
[47]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Biber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[54]
Robert H. Somers. A new asymmetric measure of association for ordinal variables.American Sociological Review, 27(6):799–811, 1962
work page 1962
-
[55]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[56]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[57]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
work page 2022
-
[58]
Amirhosein Ghasemabadi and Di Niu. Can llms predict their own failures? self-awareness via internal circuits.arXiv preprint arXiv:2512.20578, 2025
-
[59]
Alexander D’Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, et al. Un- derspecification presents challenges for credibility in modern machine learning.Journal of Machine Learning Research, 23(226):1–61, 2022
work page 2022
- [60]
-
[61]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[62]
GAIA: a benchmark for General AI Assistants
Gr´egoire Mialon, Cl´ementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[64]
gains 3” immediately followed by “loses 3
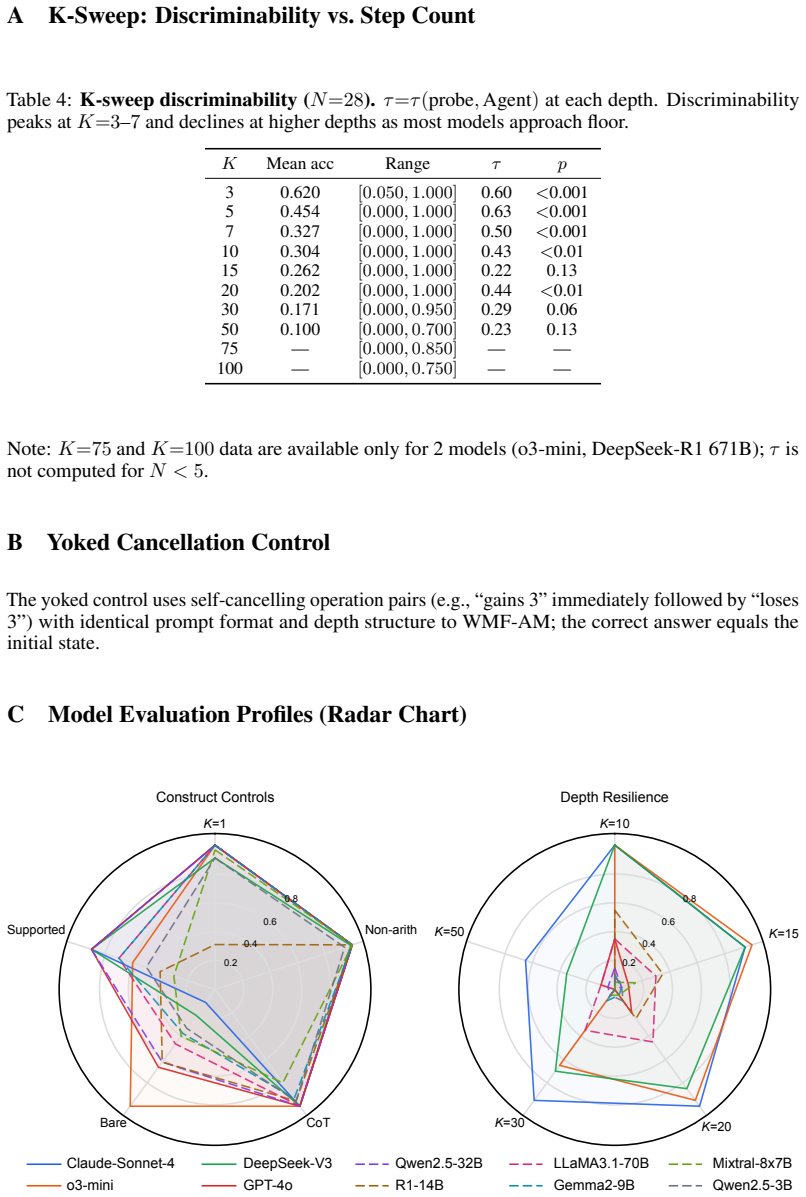
Donald T. Campbell and Donald W. Fiske. Convergent and discriminant validation by the multitrait-multimethod matrix.Psychological Bulletin, 56(2):81–105, 1959. 13 A K-Sweep: Discriminability vs. Step Count Table 4:K-sweep discriminability ( N=28). τ=τ(probe,Agent) at each depth. Discriminability peaks atK=3–7and declines at higher depths as most models ap...
work page 1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.