Recognition: unknown
Guess-Verify-Refine: Data-Aware Top-K for Sparse-Attention Decoding on Blackwell via Temporal Correlation
Pith reviewed 2026-05-08 09:54 UTC · model grok-4.3
The pith
Guess-Verify-Refine narrows exact Top-K thresholds from prior decode steps to reach 1.88x average speedup on Blackwell while staying bit-exact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GVR exploits temporal correlation across consecutive decode steps: it uses the previous step's Top-K as a prediction signal, computes pre-indexed statistics, narrows to a valid threshold by secant-style counting in 1-2 global passes, verifies candidates with a ballot-free collector, and finishes exact selection in shared memory. The design is connected to the Toeplitz and RoPE structure of DeepSeek Sparse Attention indexer scores and is validated on real DeepSeek-V3.2 workloads integrated into TensorRT-LLM, delivering an average 1.88x single-operator speedup over the production radix-select kernel, up to 2.42x per layer per step, while preserving bit-exact Top-K outputs.
What carries the argument
The Guess-Verify-Refine procedure that predicts a threshold from the prior Top-K set and narrows it via secant-style counting before ballot-free verification.
If this is right
- Achieves an average 1.88x single-operator speedup over the production radix-select kernel.
- Reaches up to 2.42x speedup per layer per decode step while keeping outputs bit-exact.
- Improves end-to-end time-per-output-token by up to 7.52 percent in min-latency deployment at 100K context length.
- Delivers larger gains at longer contexts and still positive gains under speculative decoding.
- The same principle may extend to other sparse-attention decoders that exhibit temporal stability in their decode-phase Top-K.
Where Pith is reading between the lines
- If the same degree of step-to-step stability appears in other sparse attention indexers, the guess-verify pattern could reduce Top-K overhead in models beyond DeepSeek.
- The method's reliance on only one or two global passes suggests it could be combined with hardware-specific reductions to further lower memory traffic in multi-GPU serving.
- Because the algorithm finishes in shared memory after the narrow pass, it may become attractive for on-device or edge inference where global synchronization costs are high.
Load-bearing premise
Temporal correlation across consecutive decode steps is strong enough in the target workloads to let secant-style counting narrow to a valid threshold in one or two passes without missing any exact top entries.
What would settle it
Measure the fraction of Top-K entries that differ between consecutive decode steps on a long-context workload; if that fraction is large enough that the guessed threshold range excludes true top entries, GVR would require extra passes or lose exactness.
Figures

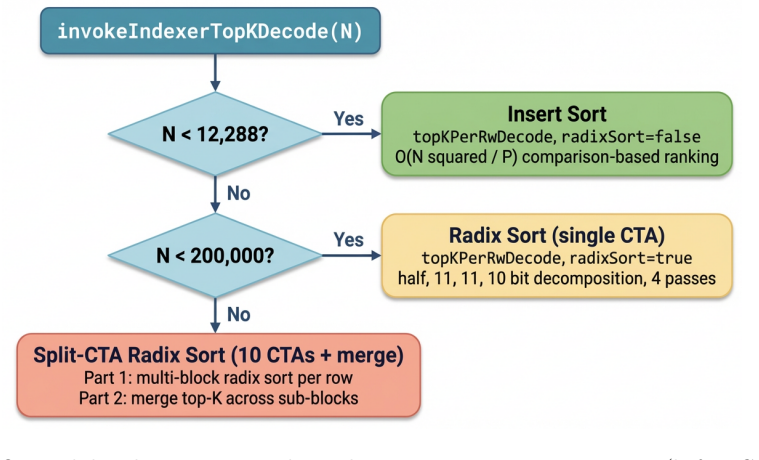
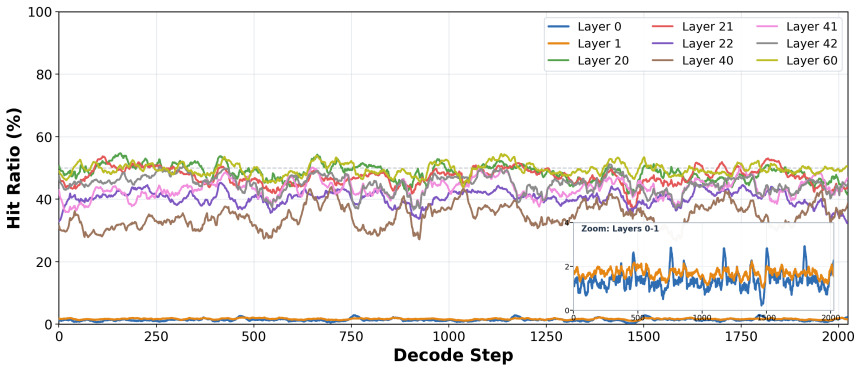








read the original abstract
Sparse-attention decoders rely on exact Top-K selection to choose the most important key-value entries for each query token. In long-context LLM serving, this Top-K stage runs once per decode query and becomes a meaningful latency bottleneck even when the indexer and attention kernels are already highly optimized. We present \textbf{Guess-Verify-Refine (GVR)}, a data-aware exact Top-K algorithm for sparse-attention decoding on NVIDIA Blackwell. GVR exploits temporal correlation across consecutive decode steps: it uses the previous step's Top-K as a prediction signal, computes pre-indexed statistics, narrows to a valid threshold by secant-style counting in 1-2 global passes, verifies candidates with a ballot-free collector, and finishes exact selection in shared memory. We connect this behavior to the Toeplitz / RoPE structure of DeepSeek Sparse Attention (DSA) indexer scores and validate the design on real DeepSeek-V3.2 workloads integrated into TensorRT-LLM. GVR achieves an average \textbf{1.88x} single-operator speedup over the production radix-select kernel, with up to \textbf{2.42x} per layer per step, while preserving bit-exact Top-K outputs. In controlled TEP8 min-latency deployment, it improves end-to-end TPOT by up to \textbf{7.52%} at 100K context, with larger gains at longer contexts and smaller but still positive gains under speculative decoding. While implemented and validated in the current TensorRT-LLM DSA stack on Blackwell, the same principle may extend to sparse-attention decoders whose decode-phase Top-K exhibits temporal stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Guess-Verify-Refine (GVR) algorithm, a data-aware exact Top-K method for sparse-attention decoding on NVIDIA Blackwell GPUs. It leverages temporal correlation across decode steps to predict a threshold from the previous Top-K, narrows it using secant-style counting in 1-2 global passes, verifies with a ballot-free collector, and refines in shared memory. Validated on DeepSeek-V3.2 workloads in TensorRT-LLM, it claims an average 1.88x speedup over the production radix-select kernel (up to 2.42x), bit-exact outputs, and up to 7.52% improvement in end-to-end TPOT at 100K context.
Significance. If the claims hold, this represents a meaningful optimization for long-context LLM serving by reducing the latency of the Top-K stage in sparse attention without sacrificing correctness. The approach is notable for maintaining bit-exactness independent of the strength of temporal correlation, with the correlation used only for performance. The integration into real production stacks and measurement on actual traces provide concrete evidence of practical impact. This could influence the design of future sparse-attention kernels on modern GPUs.
minor comments (3)
- The abstract and introduction use the term 'secant-style counting' without a brief definition or reference to the underlying technique; adding a short explanatory sentence or citation in §3 would improve readability for readers outside the immediate subfield.
- Figure 1 (or equivalent pipeline diagram) would benefit from explicit annotation of the 1-2 global pass narrowing and the shared-memory finish step to make the data flow clearer.
- The results section reports average and per-layer speedups but does not include a table or plot showing the distribution of pass counts (1 vs. 2) across layers or context lengths; this would help readers assess how often the temporal-correlation assumption yields the best-case narrowing.
Simulated Author's Rebuttal
We thank the referee for the positive review, recognition of GVR's practical impact on long-context LLM serving, and recommendation for minor revision. The emphasis on bit-exactness independent of correlation strength and the integration into TensorRT-LLM is appreciated. No major comments were listed in the report, so we provide no point-by-point responses below.
Circularity Check
No significant circularity; algorithm is self-contained with external validation
full rationale
The paper presents GVR as a concrete algorithm (guess from prior Top-K, secant-style narrowing, ballot-free verify, shared-memory refine) whose bit-exactness is enforced by the verify/refine stages independent of correlation strength. The claimed 1.88x speedup is an empirical measurement on real DeepSeek-V3.2 traces inside TensorRT-LLM, not a quantity derived from any fitted parameter or self-referential equation. The Toeplitz/RoPE reference is used only to explain why correlation is typically present in this indexer; it is not invoked as a correctness prerequisite or uniqueness theorem. No load-bearing step reduces the performance result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal correlation exists across consecutive decode steps in Top-K selections for the given workloads
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[2]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review arXiv
-
[3]
DeepSeek-AI. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089,
-
[4]
Oscar Key, Luka Ribar, Alberto Cattaneo, Luke Hudlass-Galley, and Douglas Orr
URLhttps://openreview.net/forum?id= VTF8yNQM66. Oscar Key, Luka Ribar, Alberto Cattaneo, Luke Hudlass-Galley, and Douglas Orr. Approximate top-kfor increased parallelism.arXiv preprint arXiv:2412.04358,
-
[5]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189, 2025
Enzhe Lu et al. MoBA: Multi-head mixture-of-block-attention for long-context llms.arXiv preprint arXiv:2502.13189,
-
[6]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Sharan. YaRN: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071,
work page internal anchor Pith review arXiv
-
[7]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review arXiv
-
[8]
HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Yufei Xu, Fanxu Meng, Fan Jiang, Yuxuan Wang, Ruijie Zhou, Zhaohui Wang, Jiexi Wu, Zhixin Pan, Xiao- juan Tang, Wenjie Pei, Tongxuan Liu, Di Yin, Xing Sun, and Muhan Zhang. Hisa: Efficient hierarchical indexing for fine-grained sparse attention.arXiv preprint arXiv:2603.28458,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Cited as an orthogonal DSA optimization direction. Donghyeon Yun et al. SAGE-KV: Self-attention guided KV cache eviction.arXiv preprint arXiv:2503.08879,
-
[10]
Reduction is computed from the mean TPOT values across the three alternating A/B repetitions. MTP ISL Baseline TPOT (ms) GVR TPOT (ms) Mean Base Mean GVR Reduction R1 R2 R3 R1 R2 R3 0 64K 10.8161 10.8509 10.8785 10.2708 10.2367 10.2593 10.8485 10.25565.47% 0 100K 11.4964 11.5023 11.5316 10.6522 10.6438 10.6359 11.5101 10.64407.52% 1 64K 6.5508 6.5188 6.50...
1900
-
[11]
" " DeepSeek - V3 .2 YaRN fr eq ue nc y c o m p u t a t i o n
as candidates. However, analysis showed that peak indices achieve only∼17–35% prediction success rate—the ratio of significant peaks to total tokens is low (∼13%), and many true Top-K indices fall between peaks. TheTopK-based prediction(using the Top-K ofg(∆) directly) achieves 45–100% success rate, a several-fold improvement. 26 C Shared Memory Layout an...
2048
-
[12]
" " Compute preIdx from the all - ones RoPE s t r u c t u r a l prior
13returnf r e q _ i n t e r * ramp + f r e q _ e x t r a * (1 - ramp ) 14 15defc o m p u t e _ s t a t i c _ p r e _ i d x (N , K =2048 , d_rope =64) : 16" " " Compute preIdx from the all - ones RoPE s t r u c t u r a l prior . " " " 17theta = y a r n _ i n v _ f r e q ( d_rope ) . numpy () 18f = 2 * np . cos ( np . outer ( np . arange ( N ) , theta ) ) ....
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.