Recognition: 2 theorem links
· Lean TheoremVideo Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Pith reviewed 2026-05-14 01:31 UTC · model grok-4.3
The pith
Efficiency techniques can turn video generation models into usable world simulators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Video generation models already hold the theoretical ability to simulate complex physical dynamics and long-horizon causalities, yet high costs of spatiotemporal modeling keep them from serving as usable world models. The paper supplies a three-part taxonomy of efficiency improvements and shows that these improvements would enable practical applications in autonomous driving, embodied AI, and game simulation.
What carries the argument
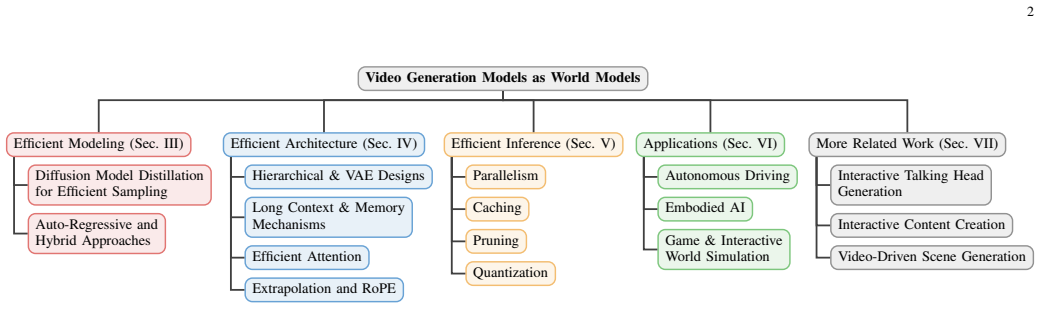
Three-dimensional taxonomy covering efficient modeling paradigms, efficient network architectures, and efficient inference algorithms.
Load-bearing premise
Video generation models already contain enough capacity to simulate physical dynamics and causalities, so the main barrier is simply computational cost.
What would settle it
A controlled test in which an efficiency-optimized video model runs in real time yet produces large errors when predicting object trajectories or collisions over many future frames in a driving scene.
Figures







read the original abstract
The rapid evolution of video generation has enabled models to simulate complex physical dynamics and long-horizon causalities, positioning them as potential world simulators. However, a critical gap still remains between the theoretical capacity for world simulation and the heavy computational costs of spatiotemporal modeling. To address this, we comprehensively and systematically review video generation frameworks and techniques that consider efficiency as a crucial requirement for practical world modeling. We introduce a novel taxonomy in three dimensions: efficient modeling paradigms, efficient network architectures, and efficient inference algorithms. We further show that bridging this efficiency gap directly empowers interactive applications such as autonomous driving, embodied AI, and game simulation. Finally, we identify emerging research frontiers in efficient video-based world modeling, arguing that efficiency is a fundamental prerequisite for evolving video generators into general-purpose, real-time, and robust world simulators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey on video generation models positioned as world simulators. It reviews frameworks and techniques with a focus on efficiency, introducing a three-dimensional taxonomy covering efficient modeling paradigms, network architectures, and inference algorithms. The work argues that closing the computational gap will enable practical applications in autonomous driving, embodied AI, and game simulation, while identifying future research directions.
Significance. As a conceptual survey organizing existing literature on efficiency in video-based world modeling, the taxonomy could serve as a useful reference point for the community if it proves comprehensive. Highlighting efficiency as a prerequisite for real-time interactive simulators aligns with practical needs in the cited applications, though its impact depends on the accuracy and completeness of the categorization rather than new empirical contributions.
major comments (1)
- [Abstract] Abstract: The central positioning that video generation models have already 'enabled' simulation of complex physical dynamics and long-horizon causalities lacks supporting citations to controlled benchmarks or quantitative evaluations of physical fidelity (e.g., momentum conservation, intervention-based state prediction, or deviation from Newtonian trajectories). This assumption is load-bearing for the claim that efficiency is the sole remaining barrier to reliable world simulation.
minor comments (1)
- The three-dimensional taxonomy would benefit from an explicit summary table or diagram early in the manuscript to clarify the relationships between paradigms, architectures, and algorithms.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive comment on our survey. We have addressed the concern regarding the abstract's positioning by planning targeted revisions to include supporting citations while preserving the paper's core argument on efficiency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central positioning that video generation models have already 'enabled' simulation of complex physical dynamics and long-horizon causalities lacks supporting citations to controlled benchmarks or quantitative evaluations of physical fidelity (e.g., momentum conservation, intervention-based state prediction, or deviation from Newtonian trajectories). This assumption is load-bearing for the claim that efficiency is the sole remaining barrier to reliable world simulation.
Authors: We acknowledge the validity of this observation. The abstract's phrasing draws from the reviewed literature demonstrating video models' capacity for physical simulation in specific settings, yet we agree that explicit citations to quantitative benchmarks on physical fidelity (e.g., conservation laws or intervention tests) would strengthen the claim and clarify the load-bearing assumption. In the revised manuscript, we will add references to relevant controlled evaluations from the surveyed works and adjust the abstract wording to note demonstrated capabilities alongside remaining limitations. This revision supports rather than undermines our central thesis that efficiency is the key remaining barrier to practical deployment, as even validated physical fidelity does not address computational scalability for real-time use. revision: yes
Circularity Check
Survey paper with no derivation chain; claims rest on external literature review
full rationale
This manuscript is a comprehensive review and taxonomy of existing video generation methods, introducing organizational categories (efficient paradigms, architectures, algorithms) without any new equations, fitted parameters, or first-principles derivations. No step claims a 'prediction' that reduces to a self-fit, self-citation chain, or renamed ansatz. The abstract and context explicitly frame the work as surveying published techniques, with efficiency positioned as an external engineering requirement rather than a quantity derived from the paper's own inputs. Central claims about world-simulation capacity are presented as motivation drawn from prior literature, not as internally validated results. This satisfies the self-contained benchmark: the paper's structure is independent of any circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe rapid evolution of video generation has enabled models to simulate complex physical dynamics and long-horizon causalities, positioning them as potential world simulators.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEfficient modeling paradigms, efficient network architectures, and efficient inference algorithms
Reference graph
Works this paper leans on
-
[1]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[2]
Temporal generative adver- sarial nets with singular value clipping,
M. Saito, E. Matsumoto, and S. Saito, “Temporal generative adver- sarial nets with singular value clipping,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2830–2839
work page 2017
-
[3]
N. Kalchbrenner, A. Oord, K. Simonyan, I. Danihelka, O. Vinyals, A. Graves, and K. Kavukcuoglu, “Video pixel networks,” inInterna- tional Conference on Machine Learning. PMLR, 2017, pp. 1771– 1779
work page 2017
-
[4]
VideoGPT: Video Generation using VQ-VAE and Transformers
W. Yan, Y . Zhang, P. Abbeel, and A. Srinivas, “Videogpt: Video gener- ation using vq-vae and transformers,”arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inInternational conference on machine learning. Pmlr, 2021, pp. 8821–8831. 16
work page 2021
-
[6]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
work page 2022
-
[7]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimanset al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in neural information processing systems, vol. 35, pp. 36 479–36 494, 2022
work page 2022
-
[8]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,”Advances in neural information processing systems, vol. 35, pp. 8633–8646, 2022
work page 2022
-
[9]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/ forum?id=PxTIG12RRHS
work page 2021
-
[10]
Align your latents: High-resolution video synthesis with latent diffusion models,
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis, “Align your latents: High-resolution video synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 563–22 575
work page 2023
-
[11]
Improving image generation with bet- ter captions,
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y . Guoet al., “Improving image generation with bet- ter captions,”Computer Science. https://cdn. openai. com/papers/dall- e-3. pdf, vol. 2, no. 3, p. 8, 2023
work page 2023
-
[12]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[13]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first International Conference on Machine Learning, 2024
work page 2024
-
[14]
Video generation models as world simulators,
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhmanet al., “Video generation models as world simulators,” 2024. [Online]. Available: https: //openai.com/research/video-generation-models-as-world-simulators
work page 2024
-
[15]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
work page 2023
-
[16]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Learning interactive real-world simulators,
S. Yang, Y . Du, S. K. S. Ghasemipour, J. Tompson, L. P. Kaelbling, D. Schuurmans, and P. Abbeel, “Learning interactive real-world simulators,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=sFyTZEqmUY
work page 2024
-
[18]
GAIA-1: A Generative World Model for Autonomous Driving
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado, “Gaia-1: A generative world model for autonomous driving,”arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Drivedreamer: Towards real-world-drive world models for autonomous driving,
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu, “Drivedreamer: Towards real-world-drive world models for autonomous driving,” in European conference on computer vision. Springer, 2024, pp. 55–72
work page 2024
-
[20]
Learning universal policies via text-guided video generation,
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schu- urmans, and P. Abbeel, “Learning universal policies via text-guided video generation,”Advances in neural information processing systems, vol. 36, pp. 9156–9172, 2023
work page 2023
-
[21]
Google DeepMind. Genie 3. Google DeepMind. [Online]. Available: https://deepmind.google/models/genie/
-
[22]
Stable video infinity: Infinite-length video generation with error recycling,
W. Li, W. Pan, P.-C. Luan, Y . Gao, and A. Alahi, “Stable video infinity: Infinite-length video generation with error recycling,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=X96Ei9n34a
work page 2026
-
[23]
World- pack: Compressed memory improves spatial consistency in video world modeling,
Y . Oshima, Y . Iwasawa, M. Suzuki, Y . Matsuo, and H. Furuta, “World- pack: Compressed memory improves spatial consistency in video world modeling,”arXiv preprint arXiv:2512.02473, 2025
-
[24]
Vidtome: Video token merging for zero-shot video editing,
X. Li, C. Ma, X. Yang, and M.-H. Yang, “Vidtome: Video token merging for zero-shot video editing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7486–7495
work page 2024
-
[25]
Dc-videogen: Efficient video gen- eration with deep compression video autoencoder,
J. Chen, W. He, Y . Gu, Y . Zhao, J. Yu, J. Chen, D. Zou, Y . Lin, Z. Zhang, M. Liet al., “Dc-videogen: Efficient video gen- eration with deep compression video autoencoder,”arXiv preprint arXiv:2509.25182, 2025
-
[26]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[27]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=PqvMRDCJT9t
work page 2023
-
[28]
Instaflow: One step is enough for high-quality diffusion-based text-to-image generation,
X. Liu, X. Zhang, J. Ma, J. Peng, and qiang liu, “Instaflow: One step is enough for high-quality diffusion-based text-to-image generation,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/ forum?id=1k4yZbbDqX
work page 2024
-
[29]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883
work page 2021
-
[30]
Latte: Latent diffusion transformer for video generation,
X. Ma, Y . Wang, X. Chen, G. Jia, Z. Liu, Y .-F. Li, C. Chen, and Y . Qiao, “Latte: Latent diffusion transformer for video generation,”Transactions on Machine Learning Research, 2025. [Online]. Available: https://openreview.net/forum?id=ntGPYNUF3t
work page 2025
-
[31]
Magvit: Masked gen- erative video transformer,
L. Yu, Y . Cheng, K. Sohn, J. Lezama, H. Zhang, H. Chang, A. G. Hauptmann, M.-H. Yang, Y . Hao, I. Essaet al., “Magvit: Masked gen- erative video transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 459–10 469
work page 2023
-
[32]
Cogvideox: Text-to- video diffusion models with an expert transformer,
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Fenget al., “Cogvideox: Text-to- video diffusion models with an expert transformer,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=LQzN6TRFg9
work page 2025
-
[33]
U-net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional net- works for biomedical image segmentation,” inInternational Confer- ence on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
work page 2015
-
[34]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[35]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
work page 2020
-
[36]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wuet al., “Hunyuanvideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y . Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Liet al., “Seedance 1.0: Exploring the boundaries of video generation models,”arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yanget al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a
B. Wu, C. Zou, C. Li, D. Huang, F. Yang, H. Tan, J. Peng, J. Wu, J. Xiong, J. Jianget al., “Hunyuanvideo 1.5 technical report,”arXiv preprint arXiv:2511.18870, 2025
-
[40]
Magicdrive- v2: High-resolution long video generation for autonomous driving with adaptive control,
R. Gao, K. Chen, B. Xiao, L. Hong, Z. Li, and Q. Xu, “Magicdrive- v2: High-resolution long video generation for autonomous driving with adaptive control,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 135–28 144
work page 2025
-
[41]
Genie: Generative interactive environments,
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Appset al., “Genie: Generative interactive environments,” inForty-first Interna- tional Conference on Machine Learning, 2024
work page 2024
-
[42]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
X. He, C. Peng, Z. Liu, B. Wang, Y . Zhang, Q. Cui, F. Kang, B. Jiang et al., “Matrix-game 2.0: An open-source real-time and streaming interactive world model,”arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
World Simulation with Video Foundation Models for Physical AI
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chaoet al., “World simulation with video foundation models for physical ai,”arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
L. Tian, Q. Wang, B. Zhang, and L. Bo, “Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 244–260
work page 2024
-
[45]
Ditto: Motion- space diffusion for controllable realtime talking head synthesis,
T. Li, R. Zheng, M. Yang, J. Chen, and M. Yang, “Ditto: Motion- space diffusion for controllable realtime talking head synthesis,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9704–9713
work page 2025
-
[46]
L. Shen, Q. Qiao, T. Yu, K. Zhou, T. Yu, Y . Zhan, Z. Wang, M. Tao, S. Yin, and S. Liu, “Soulx-flashtalk: Real-time infinite streaming of audio-driven avatars via self-correcting bidirectional distillation,”
-
[47]
Available: https://arxiv.org/abs/2512.23379 17
[Online]. Available: https://arxiv.org/abs/2512.23379 17
-
[48]
Infinitetalk: Audio-driven video generation for sparse-frame video dubbing,
S. Yang, Z. Kong, F. Gao, M. Cheng, X. Liu, Y . Zhang, Z. Kang, W. Luo, X. Cai, R. He, and X. Wei, “Infinitetalk: Audio-driven video generation for sparse-frame video dubbing,” 2025. [Online]. Available: https://arxiv.org/abs/2508.14033
-
[49]
MEMO: Memory-guided diffusion for expressive talking video generation,
L. Zheng, Y . Zhang, H. Guo, J. Pan, Z. Tan, J. Lu, C. Tang, B. An, and S. Y AN, “MEMO: Memory-guided diffusion for expressive talking video generation,”Transactions on Machine Learning Research, 2026, j2C Certification. [Online]. Available: https://openreview.net/forum?id=uBcHcM7Kzi
work page 2026
-
[50]
Magicinfinite: Generating infinite talking videos with your words and voice,
H. Yi, T. Ye, S. Shao, X. Yang, J. Zhao, H. Guo, T. Wang, Q. Yin, Z. Xie, L. Zhuet al., “Magicinfinite: Generating infinite talking videos with your words and voice,”arXiv preprint arXiv:2503.05978, 2025
-
[51]
ivideoGPT: Interactive videoGPTs are scalable world models,
J. Wu, S. Yin, N. Feng, X. He, D. Li, J. HAO, and M. Long, “ivideoGPT: Interactive videoGPTs are scalable world models,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id= 4TENzBftZR
work page 2024
-
[52]
Progressive distillation for fast sampling of diffusion models,
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/ forum?id=TIdIXIpzhoI
work page 2022
-
[53]
One step diffusion via shortcut models,
K. Frans, D. Hafner, S. Levine, and P. Abbeel, “One step diffusion via shortcut models,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=OlzB6LnXcS
work page 2025
-
[54]
Gpd: Guided progressive dis- tillation for fast and high-quality video generation,
X. Liang, Y . Zhang, and L. Zhu, “Gpd: Guided progressive dis- tillation for fast and high-quality video generation,”arXiv preprint arXiv:2602.01814, 2026
-
[55]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 32 211–32 252
work page 2023
-
[56]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
S. Luo, Y . Tan, L. Huang, J. Li, and H. Zhao, “Latent consistency models: Synthesizing high-resolution images with few-step inference,” arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Videolcm: Video latent consistency model,
X. Wang, S. Zhang, H. Zhang, Y . Liu, Y . Zhang, C. Gao, and N. Sang, “Videolcm: Video latent consistency model,”arXiv preprint arXiv:2312.09109, 2023
-
[58]
F.-Y . Wang, Z. Huang, W. Bian, X. Shi, K. Sun, G. Song, Y . Liu, and H. Li, “Animatelcm: Computation-efficient personalized style video generation without personalized video data,” inSIGGRAPH Asia 2024 Technical Communications, 2024, pp. 1–5
work page 2024
-
[59]
Turbodiffusion: Accelerating video diffusion models by 100-200 times,
J. Zhang, K. Zheng, K. Jiang, H. Wang, I. Stoica, J. E. Gonzalez, J. Chen, and J. Zhu, “Turbodiffusion: Accelerating video diffusion models by 100-200 times,”arXiv preprint arXiv:2512.16093, 2025
- [60]
-
[61]
One-step diffusion with distribution matching distillation,
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park, “One-step diffusion with distribution matching distillation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 6613–6623
work page 2024
-
[62]
Improved distribution matching distillation for fast image synthesis,
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and B. Freeman, “Improved distribution matching distillation for fast image synthesis,”Advances in neural information processing systems, vol. 37, pp. 47 455–47 487, 2024
work page 2024
-
[63]
Accelerating video diffusion models via distribution matching,
Y . Zhu, H. Yan, H. Yang, K. Zhang, and J. Li, “Accelerating video diffusion models via distribution matching,”arXiv preprint arXiv:2412.05899, 2024
-
[64]
Diffusion adversarial post-training for one-step video generation,
S. Lin, X. Xia, Y . Ren, C. Yang, X. Xiao, and L. Jiang, “Diffusion adversarial post-training for one-step video generation,” in Forty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=AAgzsnhc28
work page 2025
-
[65]
Videopoet: A large language model for zero-shot video generation,
D. Kondratyuk, L. Yu, X. Gu, J. Lezama, J. Huang, G. Schindler, R. Hornung, V . Birodkar, J. Yan, M.-C. Chiuet al., “Videopoet: A large language model for zero-shot video generation,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openreview.net/forum?id=LRkJwPIDuE
work page 2024
-
[66]
Loong: Generating minute-level long videos with autoregres- sive language models,
Y . Wang, T. Xiong, D. Zhou, Z. Lin, Y . Zhao, B. Kang, J. Feng, and X. Liu, “Loong: Generating minute-level long videos with autoregres- sive language models,”arXiv preprint arXiv:2410.02757, 2024
-
[67]
Progressive autoregressive video diffusion models,
D. Xie, Z. Xu, Y . Hong, H. Tan, D. Liu, F. Liu, A. Kaufman, and Y . Zhou, “Progressive autoregressive video diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2025, pp. 6376–6386
work page 2025
-
[68]
Frame context packing and drift prevention in next-frame-prediction video diffusion models,
L. Zhang, S. Cai, M. Li, G. Wetzstein, and M. Agrawala, “Frame context packing and drift prevention in next-frame-prediction video diffusion models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=J8JCF64aEn
work page 2025
-
[69]
From slow bidirectional to fast autoregressive video diffusion models,
T. Yin, Q. Zhang, R. Zhang, W. T. Freeman, F. Durand, E. Shechtman, and X. Huang, “From slow bidirectional to fast autoregressive video diffusion models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 963–22 974
work page 2025
-
[70]
Diffusion forcing: Next-token prediction meets full-sequence diffusion,
B. Chen, D. M. Mons ´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann, “Diffusion forcing: Next-token prediction meets full-sequence diffusion,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=yDo1ynArjj
work page 2024
-
[71]
Self forcing: Bridging the train-test gap in autoregressive video diffusion,
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman, “Self forcing: Bridging the train-test gap in autoregressive video diffusion,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id= mSiN7i0BYH
work page 2025
-
[72]
Rolling forcing: Autoregressive long video diffusion in real time,
K. Liu, W. Hu, J. Xu, Y . Shan, and S. Lu, “Rolling forcing: Autoregressive long video diffusion in real time,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=IAyzXjbfwo
work page 2026
-
[73]
Self-forcing++: Towards minute-scale high-quality video generation,
J. Cui, J. Wu, M. Li, T. Yang, X. Li, R. Wang, A. Bai, Y . Ban, and C.-J. Hsieh, “Self-forcing++: Towards minute-scale high-quality video generation,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=DzvPiqh23f
work page 2026
-
[74]
Y . Lu, Y . Zeng, H. Li, H. Ouyang, Q. Wang, K. L. Cheng, J. Zhu, H. Cao, Z. Zhang, X. Zhuet al., “Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation,” arXiv preprint arXiv:2512.04678, 2025
-
[75]
H. Zhu, M. Zhao, G. He, H. Su, C. Li, and J. Zhu, “Causal forcing: Autoregressive diffusion distillation done right for high-quality real- time interactive video generation,”arXiv preprint arXiv:2602.02214, 2026
-
[76]
H. Li, S. Liu, Z. Lin, and M. Chandraker, “Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion,”arXiv preprint arXiv:2602.07775, 2026. [Online]. Available: https://arxiv.org/abs/2602.07775
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Autoregressive adversarial post-training for real-time interactive video generation,
S. Lin, C. Yang, H. He, J. Jiang, Y . Ren, X. Xia, Y . Zhao, X. Xiao, and L. Jiang, “Autoregressive adversarial post-training for real-time interactive video generation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=lF6SHARvmG
work page 2025
-
[78]
Longlive: Real-time interactive long video generation,
S. Yang, W. Huang, R. Chu, Y . Xiao, Y . Zhao, X. Wang, M. Li, E. Xie, Y .-C. Chen, Y . Luet al., “Longlive: Real-time interactive long video generation,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=nCAODkpsPJ
work page 2026
-
[79]
J. Yi, W. Jang, P. H. Cho, J. Nam, H. Yoon, and S. Kim, “Deep forcing: Training-free long video generation with deep sink and participative compression,”arXiv preprint arXiv:2512.05081, 2025
-
[80]
Pyramidal flow matching for efficient video generative modeling,
Y . Jin, Z. Sun, N. Li, K. Xu, K. Xu, H. Jiang, N. Zhuang, Q. Huang, Y . Song, Y . MU, and Z. Lin, “Pyramidal flow matching for efficient video generative modeling,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=66NzcRQuOq
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.