Recognition: 2 theorem links
· Lean TheoremDIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
Pith reviewed 2026-05-13 23:17 UTC · model grok-4.3
The pith
DIAL separates high-level intent from low-level robot actions using a latent foresight bottleneck inside a vision-language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
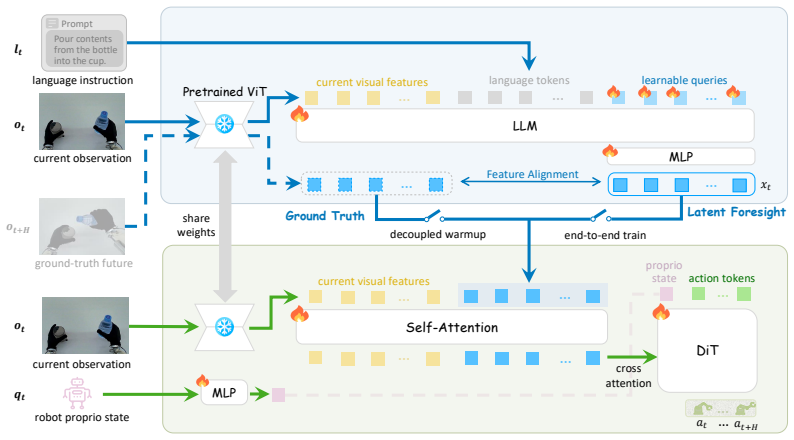
A VLM-based System-2 synthesizes latent visual foresight inside the model's native feature space; this foresight acts as an explicit, differentiable intent bottleneck. A System-1 policy then decodes the predicted intent together with the current observation through latent inverse dynamics to produce actions. Two-stage training first warms up the components separately under ground-truth future guidance, then performs controlled end-to-end fine-tuning that preserves pre-trained VLM knowledge.
What carries the argument
differentiable latent intent bottleneck formed by synthesizing latent visual foresight within the VLM's native feature space
If this is right
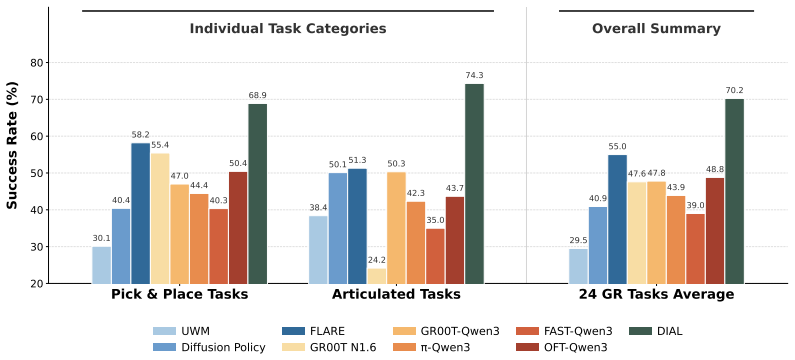
- Sets new state-of-the-art on the RoboCasa GR1 Tabletop benchmark
- Reaches superior performance using 10 times fewer demonstrations than prior methods
- Learns physically grounded manipulation priors from heterogeneous human demonstrations
- Exhibits robust zero-shot generalization to unseen objects and novel configurations on a physical humanoid robot
Where Pith is reading between the lines
- The same latent-bottleneck pattern could stabilize fine-tuning of other large multimodal models where direct action or generation heads tend to overwrite useful pre-trained features.
- Extending the foresight horizon inside the same feature space might enable longer-horizon planning without adding separate search or tree modules.
- The two-stage warmup could be reused in domains such as autonomous driving or video prediction where high-level scene understanding must remain intact while low-level controls are learned.
Load-bearing premise
Synthesizing latent visual foresight inside the VLM feature space will create a stable intent bottleneck that does not degrade the model's rich semantic representations during joint optimization.
What would settle it
Joint end-to-end training measurably reduces the VLM's performance on held-out semantic tasks or the full model shows no accuracy gain over baselines when both are trained with the same number of demonstrations.
Figures










read the original abstract
The development of Vision-Language-Action (VLA) models has been significantly accelerated by pre-trained Vision-Language Models (VLMs). However, most existing end-to-end VLAs treat the VLM primarily as a multimodal encoder, directly mapping vision-language features to low-level actions. This paradigm underutilizes the VLM's potential in high-level decision making and introduces training instability, frequently degrading its rich semantic representations. To address these limitations, we introduce DIAL, a framework bridging high-level decision making and low-level motor execution through a differentiable latent intent bottleneck. Specifically, a VLM-based System-2 performs latent world modeling by synthesizing latent visual foresight within the VLM's native feature space; this foresight explicitly encodes intent and serves as the structural bottleneck. A lightweight System-1 policy then decodes this predicted intent together with the current observation into precise robot actions via latent inverse dynamics. To ensure optimization stability, we employ a two-stage training paradigm: a decoupled warmup phase where System-2 learns to predict latent futures while System-1 learns motor control under ground-truth future guidance within a unified feature space, followed by seamless end-to-end joint optimization. This enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge. Extensive experiments on the RoboCasa GR1 Tabletop benchmark show that DIAL establishes a new state-of-the-art, achieving superior performance with 10x fewer demonstrations than prior methods. Furthermore, by leveraging heterogeneous human demonstrations, DIAL learns physically grounded manipulation priors and exhibits robust zero-shot generalization to unseen objects and novel configurations during real-world deployment on a humanoid robot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DIAL, a Vision-Language-Action (VLA) framework that decouples high-level intent from low-level actions via a differentiable latent intent bottleneck. A VLM-based System-2 performs latent world modeling by synthesizing latent visual foresight in the VLM's native feature space to encode intent explicitly; a lightweight System-1 policy then decodes this foresight plus current observations into actions via latent inverse dynamics. Training uses a two-stage paradigm (decoupled warmup followed by joint optimization) to stabilize gradients and preserve pre-trained VLM semantics. The manuscript claims new state-of-the-art results on the RoboCasa GR1 Tabletop benchmark with 10x fewer demonstrations than prior methods, plus robust zero-shot generalization in real-world humanoid deployment using heterogeneous human data.
Significance. If the central performance claims hold under rigorous verification, DIAL would offer a practical advance in data-efficient end-to-end VLA training by explicitly separating planning from control while retaining VLM semantic richness. The architectural separation and two-stage schedule address a known instability in direct VLM-to-action mapping; successful validation could influence subsequent work on latent world models for robotics. The real-world transfer results, if reproducible, would further strengthen the case for the latent foresight bottleneck as a general mechanism.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results: The headline claim of new SOTA performance with 10x fewer demonstrations is presented without any reported quantitative metrics, baseline tables, ablation results, or error bars. This absence directly undermines verification of the data-efficiency assertion and the contribution of the latent intent bottleneck.
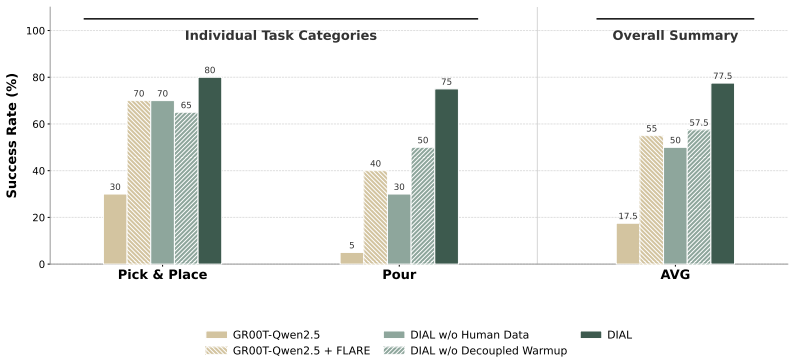
- [Training Paradigm] Training Paradigm description: The claim that the two-stage schedule 'enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge' is load-bearing for the stability argument, yet no supporting measurements (e.g., cosine similarity of VLM features before/after joint optimization, retention on held-out VLM tasks, or ablation removing the foresight bottleneck) are referenced.
minor comments (1)
- [Abstract] The terms 'latent visual foresight' and 'latent intent bottleneck' are used repeatedly but lack an explicit mathematical definition or diagram reference in the abstract-level description.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential of DIAL to advance data-efficient end-to-end VLAs through explicit intent-action decoupling. We address the two major comments below and will incorporate revisions to improve verifiability and empirical support.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: The headline claim of new SOTA performance with 10x fewer demonstrations is presented without any reported quantitative metrics, baseline tables, ablation results, or error bars. This absence directly undermines verification of the data-efficiency assertion and the contribution of the latent intent bottleneck.
Authors: We agree that the abstract would benefit from explicit numerical highlights to make the SOTA and data-efficiency claims immediately verifiable. The full experimental results section already contains detailed tables with success rates on RoboCasa GR1 Tabletop (comparing DIAL against prior VLAs at 1x, 5x, and 10x demonstration scales), ablation studies isolating the latent foresight bottleneck, and error bars computed over multiple random seeds. To address the concern directly, we will revise the abstract to include key quantitative results (e.g., absolute success rates and the precise data-reduction factor) and add a reference to the main results table. This change will be made in the revised manuscript. revision: yes
-
Referee: [Training Paradigm] Training Paradigm description: The claim that the two-stage schedule 'enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge' is load-bearing for the stability argument, yet no supporting measurements (e.g., cosine similarity of VLM features before/after joint optimization, retention on held-out VLM tasks, or ablation removing the foresight bottleneck) are referenced.
Authors: We acknowledge that direct measurements quantifying the preservation of VLM semantics under the two-stage schedule would strengthen the stability argument. The current manuscript provides indirect evidence through overall task performance and an ablation on the full framework, but does not report cosine similarity of VLM features or retention metrics on held-out VLM tasks. In the revision we will add these analyses: (1) cosine similarity of VLM embeddings before and after joint optimization, (2) performance retention on a held-out VLM benchmark, and (3) an explicit ablation that removes the latent foresight bottleneck during joint training to isolate its contribution to gradient stability. These additions will be included in the updated experimental section. revision: yes
Circularity Check
No circularity: architectural innovation with empirical claims only
full rationale
The paper describes DIAL as a two-stage training framework (decoupled warmup followed by joint optimization) that uses a VLM-based System-2 to synthesize latent visual foresight as an intent bottleneck and a lightweight System-1 decoder for actions. No equations, derivations, or fitted parameters are presented that reduce the SOTA performance or 10x data-efficiency claims to self-definitional constructs or predictions forced by construction. The central claims rest on benchmark experiments rather than any load-bearing self-citation chain or ansatz smuggled through prior work. This is a standard case of an architectural proposal evaluated empirically, with no reduction of outputs to inputs by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained VLMs retain useful semantic representations that can be preserved during controlled fine-tuning.
- ad hoc to paper Latent visual foresight can serve as an explicit, stable encoding of high-level intent.
invented entities (1)
-
latent intent bottleneck
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDIAL introduces latent visual foresight as a fully differentiable structural bottleneck... System-2 performs latent world modeling by synthesizing the latent visual foresight within the native feature space of the VLM’s vision encoder
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleartwo-stage training paradigm: a decoupled warmup phase... followed by seamless end-to-end joint optimization
Reference graph
Works this paper leans on
-
[1]
Paligemma: A versatile 3b vlm for transfer, 2024
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias Bau...
work page 2024
-
[2]
Eagle 2.5: Boosting long-context post-training for frontier vision-language models, 2025
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, Tyler Poon, Max Ehrlich, Tuomas Rintamaki, Tyler Poon, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, and Guilin Liu. Eagle 2.5: Boosting long-context post-training for frontier vision-language models,...
work page 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alex Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied ...
work page 2023
-
[7]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024
work page 2024
-
[8]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kua...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Hi robot: Open-ended instruction following with hierarchical vision-language-action models, 2025
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liyiming Ke, Karl Pertsch, Quan Vuong, James Tanner, Anna Walling, Haohuan Wang, Niccolo Fusai, Adrian Li-Bell, Danny Driess, Lachy Groom, Sergey Levine, and Chelsea Finn. Hi robot: Open-ended instruction following with hierarchical vision-language-action models, 2025
work page 2025
-
[10]
Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic manipulation, 2024
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic manipulation, 2024
work page 2024
-
[11]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Johan Bjorck, Nikita Cherniadev Fernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, 18 Yo...
work page 2025
-
[12]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page 2025
-
[13]
Flare: Robot learning with implicit world modeling, 2025
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, et al. Flare: Robot learning with implicit world modeling. arXiv preprint arXiv:2505.15659, 2025
-
[14]
Cot-vla: Visual chain-of-thought reasoning for vision-language- action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Tsung-Yi Lin, Gordon Wetzstein, Ming-Yu Liu, and Donglai Xiang. Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogn...
work page 2025
-
[15]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
-
[16]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page 2023
-
[17]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023
work page 2023
-
[18]
Egoplan-bench: Benchmarking multimodal large language models for human-level planning, 2024
Yi Chen, Yuying Ge, Yixiao Ge, Mingyu Ding, Bohao Li, Rui Wang, Ruifeng Xu, Ying Shan, and Xihui Liu. Egoplan-bench: Benchmarking multimodal large language models for human-level planning, 2024
work page 2024
-
[19]
Code as policies: Language model programs for embodied control, 2023
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control, 2023
work page 2023
-
[20]
Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean- Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, Michael Bloesch, Konstantinos Bousmalis, Philemon Brakel, An- thony Brohan, Thomas Buschmann, Arunkumar Byravan, Serkan Cabi, Ken Caluwaerts, Federico Casarini, Chr...
work page 2025
-
[21]
Tenenbaum, Dale Schuurmans, and Pieter Abbeel
Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation, 2023
work page 2023
-
[22]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better, 2025
work page 2025
-
[26]
Gr00t n1.6: An im- proved open foundation model for generalist humanoid robots
NVIDIA GEAR Team, Allison Azzolini, Johan Bjorck, Valts Blukis, et al. Gr00t n1.6: An im- proved open foundation model for generalist humanoid robots. https://research.nvidia. com/labs/gear/gr00t-n1_6/, December 2025
work page 2025
-
[27]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, and Yichu Yang. Gr-3 technical report, 2025
work page 2025
-
[29]
Igniting vlms toward the embodied space, 2025
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, Lucy Liang, Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shalfun Li, Starrick Liu, Sylas Chen, Vincent Chen, and Zach Xu. Igniting vlms toward the embodied space, 2025
work page 2025
-
[30]
Robotic control via embodied chain-of-thought reasoning
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. In8th Annual Conference on Robot Learning, 2024. 20
work page 2024
-
[31]
Molmoact: Action reasoning models that can reason in space, 2025
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. Molmoact: Action reasoning models that can reason in space, 2025
work page 2025
-
[32]
Unleashing large-scale video generative pre-training for visual robot manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[33]
Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, Hanbo Zhang, and Minzhao Zhu. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024
work page 2024
-
[34]
Unified vision-language-action model
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[35]
Worldvla: Towards autoregressive action world model, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model, 2025
work page 2025
-
[36]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Se June Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[37]
Moto: Latent motion token as the bridging language for learning robot manipulation from videos
Yi Chen, Yuying Ge, Weiliang Tang, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for learning robot manipulation from videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19752–19763, October 2025
work page 2025
-
[38]
villa- x: Enhancing latent action modeling in vision-language-action models
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, Jianyu Chen, and Jiang Bian. villa- x: Enhancing latent action modeling in vision-language-action models. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[39]
Unicod: Enhancing robot policy via unified continuous and discrete representation learning, 2025
Jianke Zhang, Yucheng Hu, Yanjiang Guo, Xiaoyu Chen, Yichen Liu, Wenna Chen, Chaochao Lu, and Jianyu Chen. Unicod: Enhancing robot policy via unified continuous and discrete representation learning, 2025
work page 2025
-
[40]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
-
[41]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[42]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Starvla: A lego-like codebase for vision-language-action model develop- ing
starVLA Contributors. Starvla: A lego-like codebase for vision-language-action model develop- ing. GitHub repository, 1 2025
work page 2025
-
[44]
Dinov2: Learning robust visual features without supervision, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.