Recognition: no theorem link
STRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Pith reviewed 2026-05-13 21:08 UTC · model grok-4.3
The pith
By generating multiple spatiotemporal variants of videos and jointly normalizing rewards across text and visuals, STRIVE stabilizes reinforcement learning for video question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
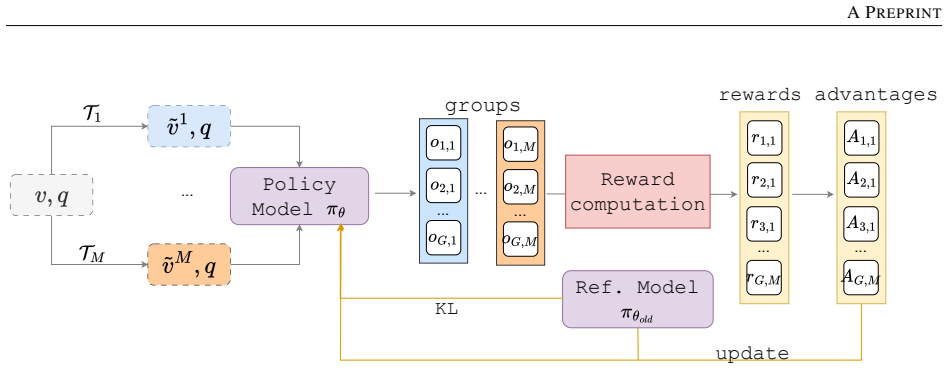
STRIVE constructs multiple spatiotemporal variants of each input video and performs joint normalization across both textual generations and visual variants to enrich reward signals and promote more stable and informative policy updates. It adds an importance-aware sampling mechanism that prioritizes frames most relevant to the question, encouraging robust reasoning across complementary visual perspectives rather than overfitting to one spatiotemporal configuration.
What carries the argument
Joint normalization across textual generations and structured spatiotemporal visual variants, paired with importance-aware frame sampling to keep exploration semantically grounded.
If this is right
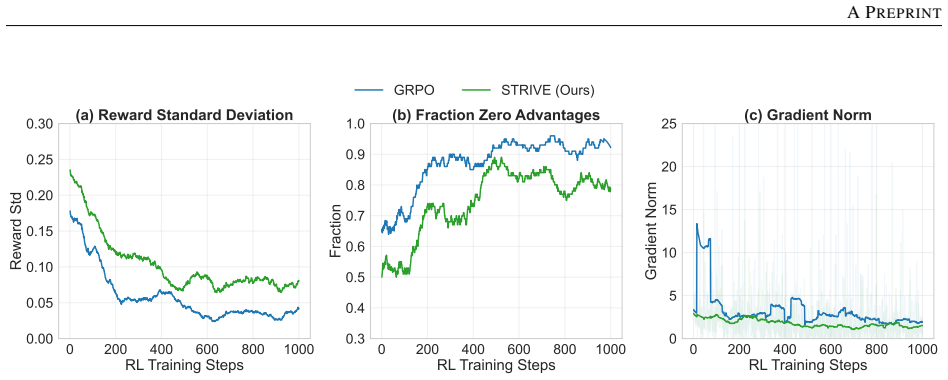
- More stable advantage estimates when textual responses share similar correctness levels.
- Improved robustness through reasoning across multiple complementary visual perspectives.
- Consistent performance gains on VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest.
- Lower risk of overfitting to any single spatiotemporal video configuration.
Where Pith is reading between the lines
- The same variant-generation and joint-normalization pattern could transfer to other multimodal RL settings such as video captioning or temporal action localization.
- Importance-aware sampling might be combined with uncertainty-driven exploration to further reduce the number of variants needed.
- Analogous structured perturbations could help address reward sparsity in static-image question-answering models that currently rely only on linguistic diversity.
Load-bearing premise
Joint normalization across textual generations and structured visual variants will enrich reward signals and produce stable policy updates without introducing new biases or causing the model to overfit to the chosen perturbations.
What would settle it
Running the same large multimodal models on the six listed benchmarks with STRIVE disabled would show no gain or a drop relative to the RL baselines.
Figures


read the original abstract
We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STRIVE, a reinforcement learning framework for video question answering that constructs multiple spatiotemporal variants of each input video via importance-aware frame sampling and performs joint normalization across both textual generations and visual variants. This is intended to increase reward variance and produce more stable advantage estimates than standard group-based policy optimization. The manuscript claims consistent improvements over strong RL baselines across six video reasoning benchmarks (VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, PerceptionTest) on multiple large multimodal models.
Significance. If the empirical results and the exchangeability assumption hold, STRIVE would provide a concrete mechanism for enriching reward signals in multimodal RL without external data, addressing a known limitation of low-variance advantages in group-based methods for video reasoning tasks.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 'consistent improvements' over baselines is unsupported by any quantitative results, tables, baseline specifications, ablation studies, or statistical tests in the provided manuscript text. This is load-bearing for the contribution and prevents verification of effect size or reliability.
- [Method] Method section on joint normalization: the procedure assumes that rewards from importance-aware spatiotemporal variants are exchangeable with the original video distribution so that normalization yields unbiased advantages. No analysis or ablation is shown to confirm that frame sampling does not systematically alter question difficulty or reward distributions, which would make normalized advantages reflect perturbation artifacts rather than response quality.
minor comments (1)
- [Method] Clarify the precise mathematical definition of the joint normalization operator and how advantages are aggregated across the combined textual-visual group.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment point by point below, outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 'consistent improvements' over baselines is unsupported by any quantitative results, tables, baseline specifications, ablation studies, or statistical tests in the provided manuscript text. This is load-bearing for the contribution and prevents verification of effect size or reliability.
Authors: We acknowledge that the excerpt provided for review did not include the full experimental results. The complete manuscript contains Section 4 with Table 1 reporting performance metrics across the six benchmarks (VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, PerceptionTest), baseline specifications (including standard group-based RL methods), ablation studies on the sampling and normalization components, and available statistical comparisons. We will revise the manuscript to ensure these quantitative results, tables, and analyses are explicitly referenced from the abstract and prominently featured in the experiments section to allow full verification of effect sizes and reliability. revision: yes
-
Referee: [Method] Method section on joint normalization: the procedure assumes that rewards from importance-aware spatiotemporal variants are exchangeable with the original video distribution so that normalization yields unbiased advantages. No analysis or ablation is shown to confirm that frame sampling does not systematically alter question difficulty or reward distributions, which would make normalized advantages reflect perturbation artifacts rather than response quality.
Authors: We agree this is an important point about the exchangeability assumption underlying the joint normalization. In the revised manuscript we will add a dedicated analysis subsection (likely in Experiments or an appendix) comparing reward distributions and question difficulty metrics between original videos and the generated spatiotemporal variants, including statistical tests for systematic shifts. We will also include an ablation study isolating the importance-aware sampling to quantify its effect. While our design prioritizes frames relevant to the question to maintain semantic equivalence and temporal coverage, we recognize that empirical validation is required and will provide it to rule out perturbation artifacts. revision: yes
Circularity Check
No significant circularity; method and claims are empirically grounded
full rationale
The paper introduces STRIVE as a structured RL framework that augments group-based policy optimization with spatiotemporal video variants and joint normalization across textual generations and visual perturbations. No equations, derivations, or self-referential definitions appear in the manuscript that would reduce the claimed advantages or policy updates to fitted parameters, self-citations, or inputs by construction. The core mechanism is described procedurally, with importance-aware sampling presented as a design choice rather than a derived necessity. All performance claims rest on experiments across six independent external benchmarks (VideoMME, TempCompass, etc.), which serve as falsifiable evidence outside the method's own definitions. No load-bearing uniqueness theorems or ansatzes are imported via self-citation chains. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Cheng, Z., Leng, S., Zhang, H., Xin, Y ., Li, X., Chen, G., Zhu, Y ., Zhang, W., Luo, Z., Zhao, D., et al.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y ., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video- r1: Reinforcing video reasoning in MLLMs. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Fu, C., Dai, Y ., Luo, Y ., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y ., Zhang, M., Chen, P., Li, Y ., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Ji, R., Sun, X.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conf...
work page 2025
-
[6]
Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
Ghazanfari, S., Croce, F., Flammarion, N., Krishnamurthy, P., Khorrami, F., Garg, S.: Chain-of-frames: Advancing video understanding in multimodal llms via frame-aware reasoning. arXiv preprint arxiv:2506.00318 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Hu, K., Wu, P., Pu, F., Xiao, W., Zhang, Y ., Yue, X., Li, B., Liu, Z.: Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826 (2025)
work page internal anchor Pith review arXiv 2025
-
[8]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., Li, C.: Llava- onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning,
Li, X., Yan, Z., Meng, D., Dong, L., Zeng, X., He, Y ., Wang, Y ., Qiao, Y ., Wang, Y ., Wang, L.: Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958 (2025)
-
[11]
Proceedings of the 2024 conference on empirical methods in natural language processing pp
Lin, B., Ye, Y ., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. Proceedings of the 2024 conference on empirical methods in natural language processing pp. 5971–5984 (2024)
work page 2024
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Lin, J., Yin, H., Ping, W., Molchanov, P., Shoeybi, M., Han, S.: Vila: On pre-training for visual language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
work page 2024
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y ., Lee, Y .J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
work page 2024
-
[14]
Advances in neural information processing systems 36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y .J.: Visual instruction tuning. Advances in neural information processing systems 36, 34892–34916 (2023)
work page 2023
-
[15]
arXiv preprint arXiv:2601.05175 (2026)
Liu, S., Zhuge, M., Zhao, C., Chen, J., Wu, L., Liu, Z., Zhu, C., Cai, Z., Zhou, C., Liu, H., Chang, E., Suri, S., Xu, H., Qian, Q., Wen, W., Varadarajan, B., Liu, Z., Xu, H., Bordes, F., Krishnamoorthi, R., Ghanem, B., Chandra, V ., Xiong, Y .: Videoauto-r1: Video auto reasoning via thinking once, answering twice. arXiv preprint arXiv:2601.05175 (2026)
- [16]
-
[17]
In: Conference on Language Modeling (COLM) (2025)
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W.S., Lin, M.: Understanding r1-zero-like training: A critical perspective. In: Conference on Language Modeling (COLM) (2025)
work page 2025
-
[18]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (2024)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (2024)
work page 2024
-
[19]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback (2022)
work page 2022
-
[20]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 11 A PREPRINT
Park, J., Na, J., Kim, J., Kim, H.J.: Deepvideo-r1: Video reinforcement fine-tuning via difficulty-aware regressive GRPO. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 11 A PREPRINT
work page 2025
-
[21]
Advances in Neural Information Processing Systems (2023)
Patraucean, V ., Smaira, L., Gupta, A., Recasens, A., Markeeva, L., Banarse, D., Koppula, S., Malinowski, M., Yang, Y ., Doersch, C., et al.: Perception test: A diagnostic benchmark for multimodal video models. Advances in Neural Information Processing Systems (2023)
work page 2023
-
[22]
Advances in neural information processing systems (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems (2023)
work page 2023
-
[23]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024)
work page 2024
-
[25]
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D.M., Lowe, R., V oss, C., Radford, A., Amodei, D., Christiano, P.: Learning to summarize with human feedback. In: NeurIPS 2020 (2020)
work page 2020
-
[26]
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. The MIT Press, second edn. (2018)
work page 2018
-
[27]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V .I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al.: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Advances in Neural Information Processing Systems37, 87310–87356 (2024)
Tong, P., Brown, E., Wu, P., Woo, S., IYER, A.J.V ., Akula, S.C., Yang, S., Yang, J., Middepogu, M., Wang, Z., et al.: Cambrian-1: A fully open, vision-centric exploration of multimodal llms. Advances in Neural Information Processing Systems37, 87310–87356 (2024)
work page 2024
-
[29]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y ., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Time-r1: Post-training large vision language model for temporal video grounding,
Wang, Y ., Wang, Z., Xu, B., Du, Y ., Lin, K., Xiao, Z., Yue, Z., Ju, J., Zhang, L., Yang, D., Fang, X., He, Z., Luo, Z., Wang, W., Lin, J., Luan, J., Jin, Q.: Time-r1: Post-training large vision language model for temporal video grounding. arXiv preprint arXiv:2503.13377 (2025)
-
[31]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Xue, Z., Luo, M., Grauman, K.: Seeing the arrow of time in large multimodal models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
work page 2025
-
[33]
arXiv preprint arXiv:2505.16673 (2025)
Yao, H., Yin, Q., Zhang, J., Yang, M., Wang, Y ., Wu, W., Su, F., Shen, L., Qiu, M., Tao, D., et al.: R1- sharevl: Incentivizing reasoning capability of multimodal large language models via share-grpo. arXiv preprint arXiv:2505.16673 (2025)
-
[34]
In: EMNLP 2023 (Demo Track) (2023)
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual language model for video understand- ing. In: EMNLP 2023 (Demo Track) (2023)
work page 2023
-
[35]
Long Context Transfer from Language to Vision
Zhang, P., Zhang, K., Li, B., Zeng, G., Yang, J., Zhang, Y ., Wang, Z., Tan, H., Li, C., Liu, Z.: Long context transfer from language to vision. arXiv preprint arXiv:2406.16852 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 12
Zhao, Y ., Zhang, H., Xie, L., Hu, T., Gan, G., Long, Y ., Hu, Z., Chen, W., Li, C., Xu, Z., et al.: Mmvu: Measuring expert-level multi-discipline video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 12
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.