Recognition: 2 theorem links
· Lean TheoremLanguage-Pretraining-Induced Bias: A Strong Foundation for General Vision Tasks
Pith reviewed 2026-05-13 21:03 UTC · model grok-4.3
The pith
A random-label bridge training stage aligns large language model parameters with vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
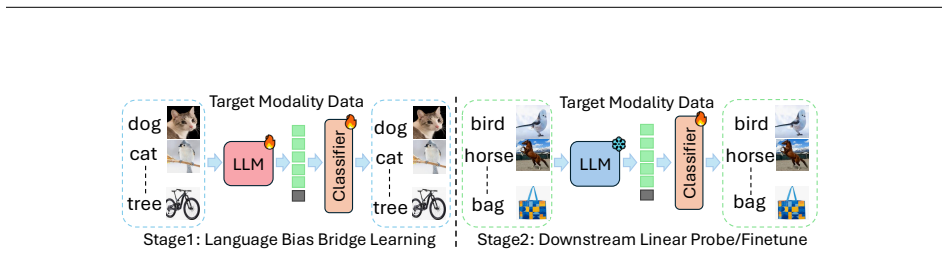
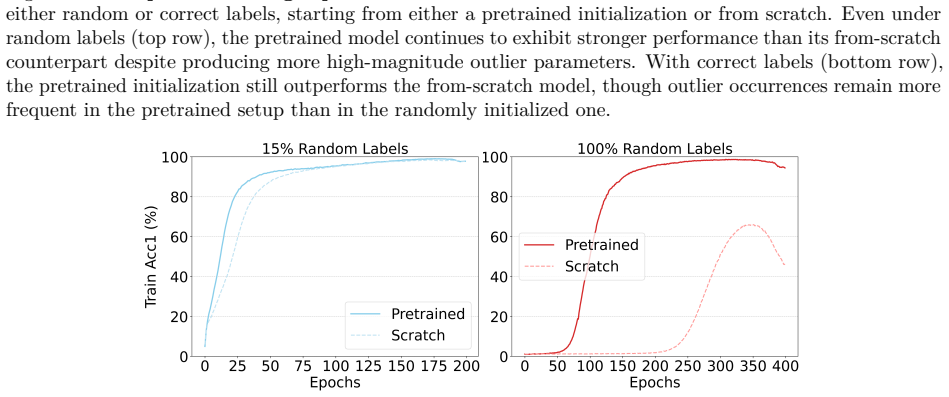
Adding a bridge training stage as a modality adaptation learner can effectively align Large Language Model (LLM) parameters with vision tasks. Specifically, random label bridge training requires no manual labeling and helps LLM parameters adapt to vision foundation tasks. Partial bridge training is often advantageous because certain layers in LLMs exhibit strong foundational properties that remain beneficial even without fine-tuning for visual tasks.
What carries the argument
The bridge training stage using random labels as a modality adaptation learner to align parameter spaces between language and vision models.
Load-bearing premise
The assumption that random-label bridge training can successfully align the disparate language and vision parameter spaces.
What would settle it
Observing no performance improvement on vision tasks when using random label bridge training compared to no adaptation or full fine-tuning would falsify the effectiveness of the alignment.
Figures










read the original abstract
The ratio of outlier parameters in language pre-training models and vision pre-training models differs significantly, making cross-modality (language and vision) inherently more challenging than cross-domain adaptation. As a result, many prior studies have focused on cross-domain transfer rather than attempting to bridge language and vision modalities, assuming that language pre-trained models are unsuitable for downstream visual tasks due to disparate parameter spaces. Contrary to this assumption, we show that adding a bridge training stage as a modality adaptation learner can effectively align Large Language Model (LLM) parameters with vision tasks. Specifically, we propose a simple yet powerful solution random label bridge training that requires no manual labeling and helps LLM parameters adapt to vision foundation tasks. Moreover, our findings reveal that partial bridge training is often advantageous, as certain layers in LLMs exhibit strong foundational properties that remain beneficial even without fine-tuning for visual tasks. This surprising discovery opens up new avenues for leveraging language pre-trained parameters directly within vision models and highlights the potential of partial bridge training as a practical pathway to cross-modality adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that differences in outlier parameters between language and vision pre-training models make cross-modality adaptation difficult, but a simple 'random label bridge training' stage can align LLM parameters to vision tasks without manual labels. It further asserts that partial bridge training is often advantageous because certain LLM layers retain strong foundational properties beneficial for vision even without full fine-tuning.
Significance. If the empirical results and mechanism hold, the work would demonstrate a low-cost pathway to repurpose language-pretrained models for vision foundation tasks, reducing dependence on vision-specific pretraining and labeled data. The partial-training observation, if substantiated, could also inform more efficient adaptation strategies across modalities.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the claim that random-label bridge training aligns language and vision parameter spaces lacks any derivation, loss-landscape analysis, or bound showing how zero-semantic supervision produces task-relevant gradients; the optimization dynamics that would make this possible are not characterized.
- [§4.2] §4.2 (experiments on partial training): the assertion that certain layers exhibit 'strong foundational properties' for vision is supported only by performance after freezing; without layer-wise feature comparisons to vision-pretrained counterparts or controlled ablations that isolate the contribution of those layers, the claim that partial training is 'often advantageous' remains under-justified.
minor comments (2)
- [Abstract] The term 'outlier parameters' is used without a formal definition or citation to the specific statistic (e.g., kurtosis, tail index) employed to measure it.
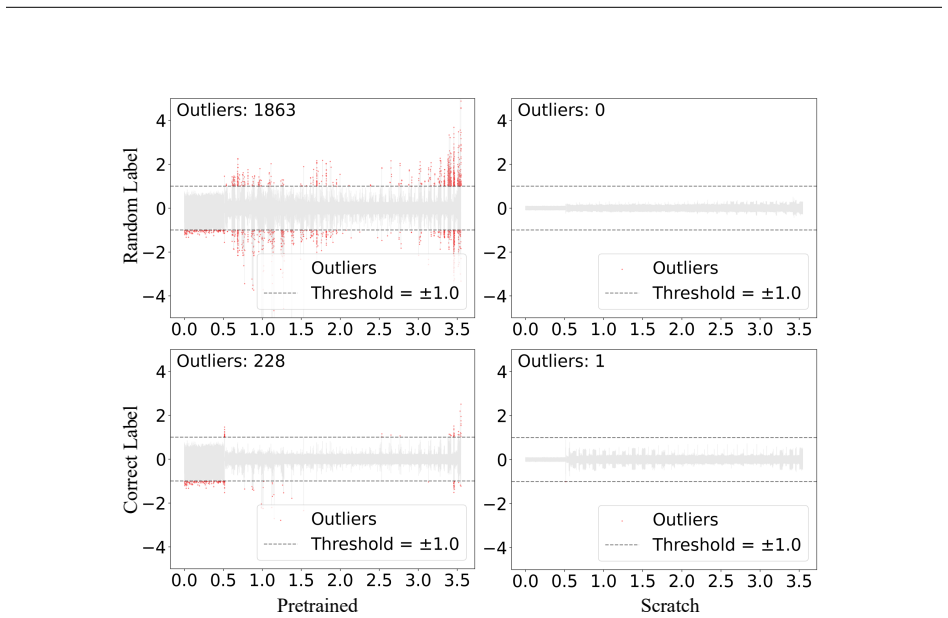
- [Figures] Figure captions and axis labels should explicitly state the random-label generation procedure and the exact layers frozen in the partial-training regime.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. Below, we provide point-by-point responses to the major comments and indicate the revisions made to address them.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the claim that random-label bridge training aligns language and vision parameter spaces lacks any derivation, loss-landscape analysis, or bound showing how zero-semantic supervision produces task-relevant gradients; the optimization dynamics that would make this possible are not characterized.
Authors: We acknowledge that our work is primarily empirical and does not include a formal derivation or loss-landscape analysis of the alignment process. In the revised manuscript, we have added an intuitive explanation in §3 regarding how random labels can still generate task-relevant gradients by encouraging the learning of general visual representations. We have also included this as a limitation in the discussion, noting that a theoretical characterization remains an open question for future research. The empirical results across various benchmarks provide strong support for the practical utility of the method. revision: partial
-
Referee: [§4.2] §4.2 (experiments on partial training): the assertion that certain layers exhibit 'strong foundational properties' for vision is supported only by performance after freezing; without layer-wise feature comparisons to vision-pretrained counterparts or controlled ablations that isolate the contribution of those layers, the claim that partial training is 'often advantageous' remains under-justified.
Authors: We agree with the referee that the original evidence was limited. In the revised §4.2, we have added layer-wise feature comparisons using cosine similarity and CKA between activations from our partially trained models and vision-pretrained counterparts. Additionally, we performed controlled ablations by varying which layers are trained during the bridge stage and reported the corresponding performance gains. These results substantiate that certain layers retain strong foundational properties, making partial training often advantageous. revision: yes
Circularity Check
No circularity: empirical proposal with no self-referential derivations or fitted predictions
full rationale
The paper proposes random-label bridge training as a modality adaptation stage and reports empirical findings that partial training of certain LLM layers preserves useful properties for vision tasks. These are presented as experimental outcomes rather than derived from equations or prior self-citations that reduce the result to its own inputs by construction. No load-bearing self-citations, uniqueness theorems, ansatzes, or renamings of known results appear in the abstract or description. The central claim rests on the observable effects of the training procedure, which remains externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ratio of outlier parameters differs significantly between language pre-training and vision pre-training models, making cross-modality transfer inherently harder than cross-domain adaptation.
invented entities (1)
-
random label bridge training
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[4]
Alessio Ansuini, Alessandro Laio, Jakob H Macke, and Davide Zoccolan. Intrinsic dimension of data representations in deep neural networks.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[5]
Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation.Advances in neural information processing systems, 19, 2006
work page 2006
-
[6]
A theory of learning from different domains
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains. InMachine Learning, volume 79, pages 151–175,
-
[7]
doi: 10.1007/s10994-009-5152-4
-
[8]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
work page 2020
-
[9]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR, 2020
work page 2020
-
[10]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[11]
Zhuyun Chen, Guolin He, Jipu Li, Yixiao Liao, Konstantinos Gryllias, and Weihua Li. Domain adversarial transfer network for cross-domain fault diagnosis of rotary machinery.IEEE Transactions on Instrumentation and Measurement, 69(11):8702–8712, 2020
work page 2020
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. IEEE, 2009
work page 2009
-
[13]
Pmr: Prototypical modal rebalance for multimodal learning
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Junxiao Wang, and Song Guo. Pmr: Prototypical modal rebalance for multimodal learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20029–20038, 2023
work page 2023
-
[14]
Abolfazl Farahani, Sahar Voghoei, Khaled Rasheed, and Hamid R Arabnia. A brief review of domain adaptation.Advances in data science and information engineering: proceedings from ICDATA 2020 and IKE 2020, pages 877–894, 2021
work page 2020
-
[15]
An investigation into neural net optimization via hessian eigenvalue density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density. InInternational Conference on Machine Learning, pages 2232–2241. PMLR, 2019
work page 2019
-
[16]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. 14
work page 2020
-
[17]
Larry C. Grove. Classical groups and geometric algebra, graduate studies in mathematics.American Mathematical Society, (ISBN 978-0-8218-2019-3, MR1859189), 2002
work page 2019
-
[18]
Rethinking imagenet pre-training
Kaiming He, Ross Girshick, and Piotr Dollár. Rethinking imagenet pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 4918–4927, 2019
work page 2019
-
[19]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[20]
Deep networks with stochastic depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. InEuropean Conference on Computer Vision, pages 646–661. Springer, 2016
work page 2016
-
[21]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis. arXiv preprint arXiv:2405.07987, 2024
work page Pith review arXiv 2024
-
[22]
Cross-domain weakly- supervised object detection through progressive domain adaptation
Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, and Kiyoharu Aizawa. Cross-domain weakly- supervised object detection through progressive domain adaptation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5001–5009, 2018
work page 2018
-
[23]
Alan T James. Normal multivariate analysis and the orthogonal group.The Annals of Mathematical Statistics, 25(1):40–75, 1954
work page 1954
-
[24]
John Kontras, Emma Lee, and Amandeep Singh. Improving multimodal learning with multi-loss gradient modulation.arXiv preprint arXiv:2405.07930, 2024
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, Canada, 2009
work page 2009
-
[26]
Tiny imagenet visual recognition challenge
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge. InCS 231N, 2015
work page 2015
-
[27]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Boosting multi-modal model performance with adaptive gradient modulation
Hong Li, Xingyu Li, Pengbo Hu, Yinuo Lei, Chunxiao Li, and Yi Zhou. Boosting multi-modal model performance with adaptive gradient modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22214–22224, 2023
work page 2023
-
[29]
Jiaang Li, Yova Kementchedjhieva, Constanza Fierro, and Anders Søgaard. Do vision and language models share concepts? a vector space alignment study.Transactions of the Association for Computational Linguistics, 2024
work page 2024
-
[30]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26689–26699, 2024
work page 2024
-
[31]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context.arXiv preprint arXiv:1405.0312, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024
work page 2024
-
[34]
Visual perception by large language model’s weights
Feipeng Ma, Hongwei Xue, Guangting Wang, Yizhou Zhou, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, and Xiaoyan Sun. Visual perception by large language model’s weights. arXiv preprint arXiv:2405.20339, 2024. 15
-
[35]
Hartmut Maennel, Ibrahim M Alabdulmohsin, Ilya O Tolstikhin, Robert Baldock, Olivier Bousquet, Sylvain Gelly, and Daniel Keysers. What do neural networks learn when trained with random labels? Advances in Neural Information Processing Systems, 33:19693–19704, 2020
work page 2020
-
[36]
Mayug Maniparambil, Raiymbek Akshulakov, Yasser Abdelaziz Dahou Djilali, Mohamed El Amine Seddik, Sanath Narayan, Karttikeya Mangalam, and Noel E O’Connor. Do vision and language encoders represent the world similarly? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[37]
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22 (165):1–73, 2021
work page 2021
-
[38]
The role of context for object detection and semantic segmentation in the wild
Roozbeh Mottaghi, Xianjie Chen, Xiaobai Liu, Nam-Gyu Cho, Seong-Whan Lee, Sanja Fidler, Raquel Urtasun, and Alan Yuille. The role of context for object detection and semantic segmentation in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014
work page 2014
-
[39]
Muhammad Muzammal Naseer, Salman H Khan, Muhammad Haris Khan, Fahad Shahbaz Khan, and Fatih Porikli. Cross-domain transferability of adversarial perturbations.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[40]
Behnam Neyshabur, Hanie Sedghi, and Chiyuan Zhang. What is being transferred in transfer learning? Advances in neural information processing systems, 33:512–523, 2020
work page 2020
-
[41]
Cross-domain sentiment classification via spectral feature alignment
Sinno Jialin Pan, Xiaochuan Ni, Jian-Tao Sun, Qiang Yang, and Zheng Chen. Cross-domain sentiment classification via spectral feature alignment. InProceedings of the 19th international conference on World wide web, pages 751–760, 2010
work page 2010
-
[42]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8238–8247, 2022
work page 2022
-
[43]
Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
work page 2019
-
[44]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[46]
Dsod: Learning deeply supervised object detectors from scratch
Zhiqiang Shen, Zhuang Liu, Jianguo Li, Yu-Gang Jiang, Yurong Chen, and Xiangyang Xue. Dsod: Learning deeply supervised object detectors from scratch. InProceedings of the IEEE international conference on computer vision, pages 1919–1927, 2017
work page 1919
-
[47]
Oscar Skean, Md Rifat Arefin, Yann LeCun, and Ravid Shwartz-Ziv. Does representation matter? exploring intermediate layers in large language models.arXiv preprint arXiv:2412.09563, 2024
-
[48]
Segmenter: Transformer for semantic segmentation
Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmentation. InProceedings of the IEEE/CVF international conference on computer vision, pages 7262–7272, 2021
work page 2021
-
[49]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. InInternational conference on machine learning, pages 9229–9248. PMLR, 2020. 16
work page 2020
-
[50]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021
work page 2021
-
[53]
tent: fully test-time adaptation by entropy minimization.ICLR, 2021
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. tent: fully test-time adaptation by entropy minimization.ICLR, 2021
work page 2021
-
[54]
Rui Wang, Zuxuan Wu, Zejia Weng, Jingjing Chen, Guo-Jun Qi, and Yu-Gang Jiang. Cross-domain contrastive learning for unsupervised domain adaptation.IEEE Transactions on Multimedia, 25:1665– 1673, 2022
work page 2022
-
[55]
Xiaofeng Wei and Zhiyuan Hu. Mmpareto: Boosting multimodal learning with innocent unimodal assistance.arXiv preprint arXiv:2405.17730, 2024
-
[56]
Tongkun Xu, Weihua Chen, Pichao Wang, Fan Wang, Hao Li, and Rong Jin. Cdtrans: Cross-domain transformer for unsupervised domain adaptation.arXiv preprint arXiv:2109.06165, 2021
-
[57]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Linjie Yu, Kun He, and Wenjie Zhang. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis.arXiv preprint arXiv:2102.04830, 2021
-
[59]
Multimodal representation learning by alternating unimodal adaptation
Xiaohui Zhang, Jaehong Yoon, Mohit Bansal, and Huaxiu Yao. Multimodal representation learning by alternating unimodal adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27456–27466, 2024
work page 2024
-
[60]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017
work page 2017
-
[61]
Adapting object detectors via selective cross-domain alignment
Xinge Zhu, Jiangmiao Pang, Ceyuan Yang, Jianping Shi, and Dahua Lin. Adapting object detectors via selective cross-domain alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 687–696, 2019
work page 2019
-
[62]
Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin Dogus Cubuk, and Quoc Le. Rethinking pre-training and self-training.Advances in neural information processing systems, 33: 3833–3845, 2020
work page 2020
-
[63]
Heqing Zou, Meng Shen, Chen Chen, Yuchen Hu, Deepu Rajan, and Eng Siong Chng. Unis-mmc: Multimodal classification via unimodality-supervised multimodal contrastive learning.arXiv preprint arXiv:2305.09299, 2023. 17 Appendix In this appendix, we provide additional material that complements the main paper: • Section A: Detailed Proofs.Formal derivations sup...
-
[64]
from a distribution with zero mean and covarianceΣ x∈Rd×d
Input Assumptions.Each input x∈Rd is drawn i.i.d. from a distribution with zero mean and covarianceΣ x∈Rd×d. For concreteness and simplicity,x can be taken to be Gaussian (i.e.,x∼N(0,Σx), or more generally, drawn from a distributionD whose symmetry group is large enough to include all orthogonal transformations that preserveΣx
-
[65]
Network Assumptions.The first layer of the neural network is either fully connected embedding or (a patch-based) convolution for image input. In either case, each first-layer weight vectorw∈Rd interacts with x primarily through inner products⟨w,x⟩. The initial weightsw∈Rd in the first layer are drawn i.i.d. from an isotropic distribution with mean zero an...
-
[66]
This implies there is no genuine correlation between inputxand labely
Label Assumptions (Random Labels).Each training instance(x,y )has label y drawnindependently and uniformlyfrom a finite label set{1, 2,...,c},regardlessof x. This implies there is no genuine correlation between inputxand labely. 18
-
[67]
The crucial point being random, theonlystructure the model sees is in x
Training Assumption.We train the first-layer parameters (and possibly deeper layers) by stochastic gradient descent (SGD) forT steps. The crucial point being random, theonlystructure the model sees is in x. Proof. We adopt an invariance argument using the orthogonal group [22, 16, 34]: G= { G∈O(d) ⏐⏐GT ΣxG= Σ x } ,(7) where the set of all orthogonal matri...
-
[68]
We show that, at each iterationt, the distribution ofw remains invariant under the action ofG
Step 1 (Invariance in Distribution). We show that, at each iterationt, the distribution ofw remains invariant under the action ofG. That is, ifw∼µt is the distribution of weights at iterationt, thenGw∼µt for allG∈G
-
[69]
Step 2 (Alignment of Covariances). Because the data distribution and the random labels provide no directional bias other thanΣx itself, the limiting covarianceΣw of w must share the same eigenspaces asΣx. Concretely, any distributionµthat is invariant under allG∈Gmust be aligned withΣx. One then shows that each eigenvalueσ2 i ofΣ x maps to a corresponding...
-
[70]
Definition of Group Action onwandx. Letw∈Rd andx∈Rd. For eachG∈G⊆O(d), define (G·w,G·x) = (Gw,Gx),(8) SinceG∈O(d)preserves inner products,⟨Gw,Gx⟩=⟨w,x⟩
-
[71]
Because G∈GsatisfiesGT ΣxG = Σx, it leaves the distribution ofx invariant
Invariance of Data Distribution. Because G∈GsatisfiesGT ΣxG = Σx, it leaves the distribution ofx invariant. Concretely,x∼N(0,Σx) implies Gx∼N(0,Σ x) as well. Thus sampling x and then applyingG yields a sample from thesame distribution
-
[72]
By assumption, the initial weight distributionw0 is isotropic: E [ w0wT 0 ] = σ2I
Initial Weights Are Isotropic. By assumption, the initial weight distributionw0 is isotropic: E [ w0wT 0 ] = σ2I. Hence Gw0∼w0. This implies that att= 0, the distributionµ0 ofw 0 is invariant underG
-
[73]
Loss Function Under Random Labels. The training loss at iterationtis L(wt;x, y) =ℓ ( ⟨wt, x⟩, y ) .(9) Sinceyis random and uncorrelated withx, each gradient update wt+1 =w t−η∇wL(wt;x,y) depends only on the scalar product⟨wt,x⟩. Crucially, ifwt and x follow distributions that are invariant under group action byG, the next update remains invariant as well
-
[74]
SGD Update Commutes with Group Action. Formally, one must show that for eachG∈G, Gwt+1 =G ( wt−η∇wL(wt;x, y) ) = (G wt)−η∇GwtL(Gwt;G x, y),(10) where the last equality holds because⟨Gwt,Gx⟩=⟨wt,x⟩and the labely is unchanged byG. By induction, this invariance holds at every iterationt. Thus the distributionµt ofw t satisfiesG wt∼wt for allG∈G. 19 Step 2: C...
-
[75]
HenceΣ w Shares Eigenspaces withΣx. Since eachVi is forced to be an invariant subspace ofΣw, we conclude thatΣw andΣ x must diagonalize in the same basis. In other words, there exist scalarsτ2 i such that Σw(v) =τ2 iv,∀v∈Vi This shows thatΣw andΣ z shareeigenvectors but differ in their eigenvaluesτ2 i vs.σ2 i
-
[76]
Eigenvalue Mappingσ2 i↦→τ2 i . Empirically, one observes a smooth functionf(·)such that τi≈f(σi). Intuitively, directions inx-space with larger varianceσ2 i yield (via random-label SGD) more significant updates tow, driving the correspondingτ2 i higher until other competing directions partially balance out. This effect is captured by a stable “transfer fu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.