Recognition: no theorem link
FastTurn: Unifying Acoustic and Streaming Semantic Cues for Low-Latency and Robust Turn Detection
Pith reviewed 2026-05-13 20:52 UTC · model grok-4.3
The pith
FastTurn detects conversation turns faster by fusing partial semantic cues from streaming speech recognition with acoustic features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FastTurn unifies acoustic features with streaming CTC outputs to enable low-latency turn detection by making decisions from partial semantic cues, achieving higher decision accuracy and lower interruption latency than baselines while remaining robust under noisy and overlapping speech conditions on a new real-dialogue test set.
What carries the argument
The fusion of partial CTC decoding outputs with acoustic features to extract early semantic cues for turn detection decisions.
If this is right
- Enables real-time full-duplex dialogue agents to respond without waiting for complete transcriptions.
- Maintains robustness when speech overlaps or background noise is present.
- Supports practical deployment by providing a dedicated real-dialogue evaluation set.
- Reduces the latency penalty typically introduced by separate ASR modules in turn-taking systems.
Where Pith is reading between the lines
- The same fusion pattern could extend to other streaming audio tasks that need early semantic context, such as real-time intent detection.
- The released real-dialogue dataset may become a useful benchmark for comparing full-duplex methods beyond the original experiments.
- Integration with larger end-to-end models might further improve cue reliability when partial observations are very short.
Load-bearing premise
That partial CTC outputs supply reliable early semantic cues without errors caused by incomplete speech observations.
What would settle it
A direct comparison on the real-dialogue test set in which FastTurn shows no reduction in interruption latency or no gain in decision accuracy relative to acoustic-only or full-ASR baselines under heavy noise or short utterances.
Figures
read the original abstract
Recent advances in AudioLLMs have enabled spoken dialogue systems to move beyond turn-based interaction toward real-time full-duplex communication, where the agent must decide when to speak, yield, or interrupt while the user is still talking. Existing full-duplex approaches either rely on voice activity cues, which lack semantic understanding, or on ASR-based modules, which introduce latency and degrade under overlapping speech and noise. Moreover, available datasets rarely capture realistic interaction dynamics, limiting evaluation and deployment. To mitigate the problem, we propose \textbf{FastTurn}, a unified framework for low-latency and robust turn detection. To advance latency while maintaining performance, FastTurn combines streaming CTC decoding with acoustic features, enabling early decisions from partial observations while preserving semantic cues. We also release a test set based on real human dialogue, capturing authentic turn transitions, overlapping speech, backchannels, pauses, pitch variation, and environmental noise. Experiments show FastTurn achieves higher decision accuracy with lower interruption latency than representative baselines and remains robust under challenging acoustic conditions, demonstrating its effectiveness for practical full-duplex dialogue systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FastTurn, a unified framework for low-latency turn detection in full-duplex spoken dialogue systems. It combines streaming CTC decoding (with prefix scoring) and acoustic features to enable early decisions from partial observations while preserving semantic information. The authors also release a new test set derived from real human dialogues that captures overlapping speech, backchannels, pauses, pitch variation, and environmental noise. Experiments, including ablations, latency measurements, and robustness tests under noise and overlap, claim that FastTurn achieves higher decision accuracy and lower interruption latency than representative baselines.
Significance. If the reported results hold, this work would advance practical full-duplex dialogue systems by addressing the latency-semantics tradeoff that limits current voice-activity or full-ASR approaches. The new real-dialogue test set fills an important evaluation gap, and the explicit inclusion of ablations, latency metrics, and robustness experiments under realistic conditions (overlap, noise) strengthens the contribution. The approach builds on established CTC techniques without introducing new free parameters or circular derivations.
major comments (2)
- [§3.2] §3.2, CTC prefix scoring and fusion: The description of how partial CTC outputs are combined with acoustic encoder features to produce early semantic cues does not quantify the prefix error rate or provide an error analysis for incomplete observations; this is load-bearing for the claim that the fusion yields reliable cues without introducing errors from partial data.
- [§4.3] §4.3, test-set construction: While aggregate statistics on overlap, backchannels, and noise are given, the paper does not detail the annotation protocol or inter-annotator agreement for turn-transition labels; without this, it is difficult to assess whether the set sufficiently represents deployment conditions for the robustness claims.
minor comments (2)
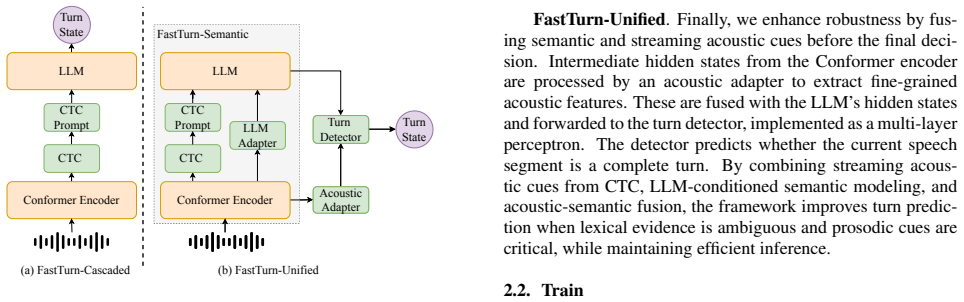
- [Figure 2] Figure 2: The diagram of the fusion module would benefit from explicit labels on the acoustic and CTC streams and a legend for the attention weights.
- [§4.1] §4.1: The baseline implementations (especially the ASR-based one) are summarized too briefly; adding a short paragraph on the exact ASR model and decision threshold would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2, CTC prefix scoring and fusion: The description of how partial CTC outputs are combined with acoustic encoder features to produce early semantic cues does not quantify the prefix error rate or provide an error analysis for incomplete observations; this is load-bearing for the claim that the fusion yields reliable cues without introducing errors from partial data.
Authors: We agree that quantifying prefix error rates strengthens the claim. In the revised version we will add to §3.2 a table reporting CTC character error rate (CER) and word error rate (WER) on prefixes at 20 %, 40 %, 60 %, and 80 % completion, both before and after fusion with the acoustic encoder. The analysis will show that fusion reduces the error introduced by incomplete observations, thereby supporting the reliability of the early semantic cues. revision: yes
-
Referee: [§4.3] §4.3, test-set construction: While aggregate statistics on overlap, backchannels, and noise are given, the paper does not detail the annotation protocol or inter-annotator agreement for turn-transition labels; without this, it is difficult to assess whether the set sufficiently represents deployment conditions for the robustness claims.
Authors: We acknowledge the omission. We will expand §4.3 with a description of the annotation protocol: two expert annotators independently labeled turn-transition points using both audio and transcripts; disagreements were resolved by a third annotator. We will also report inter-annotator agreement (Cohen’s κ = 0.82). These additions will substantiate the reliability of the test set for the robustness experiments. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents FastTurn as a fusion of established streaming CTC decoding and acoustic feature processing for turn detection. No equations, derivations, or self-referential fitting steps are described in the provided text. The approach combines known techniques without reducing predictions to fitted inputs by construction, and the central claims rest on experimental evaluations rather than self-citation chains or ansatzes imported from prior author work. The new test set is described with explicit statistics, providing external grounding. This is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction In recent years, rapid advances in AudioLLMs [1, 2, 3, 4, 5, 6] have enabled spoken dialogue systems to move beyond tra- ditional turn-based interaction toward more natural real-time communication. In highly interactive scenarios, this evolution leads to full-duplex interaction, where the system must pro- cess speech perception, partial seman...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
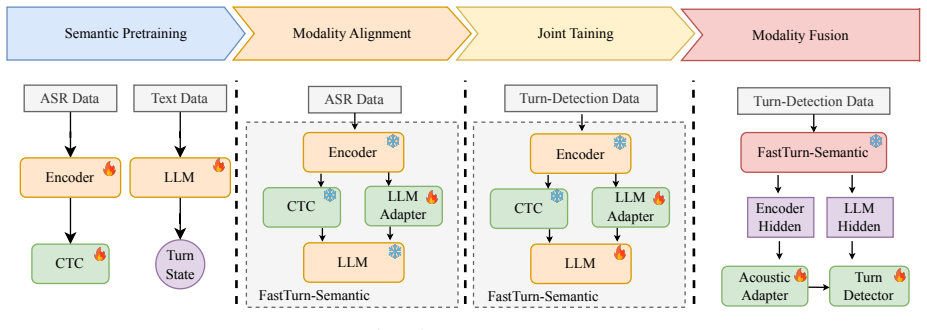
FastTurn 2.1. Architecture As shown in Figure 1, the framework consists of three compo- nents: FastTurn-Semantic, an acoustic adapter, and a turn detec- tor. The architecture is developed in three steps. First, we use FastTurn-Cascaded to route a fast CTC transcript to an LLM for low-latency decisions, then progressively introduce speech- derived cues to ...
-
[3]
Experiments 3.1. Datasets ASR Task. We use large-scale open-source corpora and in- ternal datasets, including AISHELL-1 [23], AISHELL-2 [24], WenetSpeech [25], LibriSpeech [26], GigaSpeech [27], and MLS [28], totaling over 30,000 hours of Chinese and English speech to support robust feature learning. Turn Detection Task.We use the Easy Turn training set, ...
-
[4]
Conclusion This paper presents FastTurn, a framework for efficient turn de- tection in full-duplex systems. By utilizing fast CTC decod- ing and integrating acoustic features, FastTurn reduces latency and enhances robustness. We release a comprehensive test set to promote research on conversational turn-taking and speech overlap phenomena, specifically de...
-
[5]
Audiogpt: Understanding and generating speech, music, sound, and talking head,
R. Huang, M. Li, D. Yang, J. Shi, X. Chang, Z. Ye, Y . Wu, Z. Hong, J. Huang, J. Liuet al., “Audiogpt: Understanding and generating speech, music, sound, and talking head,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024, pp. 23 802–23 804
work page 2024
-
[6]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation,
W. Yu, S. Wang, X. Yang, X. Chen, X. Tian, J. Zhang, G. Sun, L. Lu, Y . Wang, and C. Zhang, “Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation,”arXiv preprint arXiv:2411.18138, 2024
-
[8]
Glm-4-voice: Towards intelligent and human-like end- to-end spoken chatbot,
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “Glm-4-voice: Towards intelligent and human-like end- to-end spoken chatbot,”arXiv preprint arXiv:2412.02612, 2024
-
[9]
Mini-omni: Language models can hear, talk while thinking in streaming,
Z. Xie and C. Wu, “Mini-omni: Language models can hear, talk while thinking in streaming,”arXiv preprint arXiv:2408.16725, 2024
-
[10]
X. Geng, Q. Shao, H. Xue, S. Wang, H. Xie, Z. Guo, Y . Zhao, G. Li, W. Tian, C. Wanget al., “Osum-echat: Enhancing end-to- end empathetic spoken chatbot via understanding-driven spoken dialogue,”arXiv preprint arXiv:2508.09600, 2025
-
[11]
Duplexmamba: Enhancing real-time speech conver- sations with duplex and streaming capabilities,
X. Lu, W. Xu, H. Wang, H. Zhou, H. Zhao, C. Zhu, T. Zhao, and M. Yang, “Duplexmamba: Enhancing real-time speech conver- sations with duplex and streaming capabilities,” inCCF Interna- tional Conference on Natural Language Processing and Chinese Computing. Springer, 2025, pp. 62–74
work page 2025
-
[12]
C. Liu, J. Jiang, C. Xiong, Y . Yang, and J. Ye, “Towards building an intelligent chatbot for customer service: Learning to respond at the appropriate time,” inProceedings of the 26th ACM SIGKDD international conference on Knowledge Discovery & Data Min- ing, 2020, pp. 3377–3385
work page 2020
-
[13]
Google duplex: An ai system for accomplishing real-world tasks over the phone,
Y . Leviathan and Y . Matias, “Google duplex: An ai system for accomplishing real-world tasks over the phone,”Google AI blog, vol. 8, 2018
work page 2018
-
[14]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,
X. Wang, Y . Li, C. Fu, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,”arXiv preprint arXiv:2411.00774, 2024
-
[16]
J. Chen, Y . Hu, J. Li, K. Li, K. Liu, W. Li, X. Li, Z. Li, F. Shen, X. Tanget al., “Fireredchat: A pluggable, full-duplex voice in- teraction system with cascaded and semi-cascaded implementa- tions,”arXiv preprint arXiv:2509.06502, 2025
-
[17]
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction,
C. Fu, H. Lin, X. Wang, Y .-F. Zhang, Y . Shen, X. Liu, H. Cao, Z. Long, H. Gao, K. Liet al., “Vita-1.5: Towards gpt-4o level real-time vision and speech interaction,”arXiv preprint arXiv:2501.01957, 2025
-
[18]
G. Li, C. Wang, H. Xue, S. Wang, D. Gao, Z. Zhang, Y . Lin, W. Li, L. Xiao, Z. Fu, and L. Xie, “Easy turn: Integrating acous- tic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
work page 2026
-
[19]
W. Kraaij, T. Hain, M. Lincoln, and W. Post, “The ami meeting corpus,” inProc. International Conference on Methods and Tech- niques in Behavioral Research, 2005, pp. 1–4
work page 2005
-
[20]
Open source magicdata-ramc: A rich annotated mandarin conversational (ramc) speech dataset,
Z. Yang, Y . Chen, L. Luo, R. Yang, L. Ye, G. Cheng, J. Xu, Y . Jin, Q. Zhang, P. Zhanget al., “Open source magicdata-ramc: A rich annotated mandarin conversational (ramc) speech dataset,”arXiv preprint arXiv:2203.16844, 2022
-
[21]
G.-T. Lin, J. Lian, T. Li, Q. Wang, G. Anumanchipalli, A. H. Liu, and H.-y. Lee, “Full-duplex-bench: A benchmark to evaluate full- duplex spoken dialogue models on turn-taking capabilities,”arXiv preprint arXiv:2503.04721, 2025
-
[22]
Fd-bench: A full-duplex benchmarking pipeline de- signed for full duplex spoken dialogue systems,
Y . Peng, Y .-W. Chao, D. Ng, Y . Ma, C. Ni, B. Ma, and E. S. Chng, “Fd-bench: A full-duplex benchmarking pipeline de- signed for full duplex spoken dialogue systems,”arXiv preprint arXiv:2507.19040, 2025
-
[23]
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inProceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376
work page 2006
-
[24]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical re- port,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech,” arXiv preprint arXiv:2506.21619, 2025
-
[27]
Aishell-1: An open- source mandarin speech corpus and a speech recognition base- line,
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open- source mandarin speech corpus and a speech recognition base- line,” in2017 20th conference of the oriental chapter of the inter- national coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA). IEEE, 2017, pp. 1–5
work page 2017
-
[28]
Aishell-2: Transform- ing mandarin asr research into industrial scale,
J. Du, X. Na, X. Liu, and H. Bu, “Aishell-2: Transform- ing mandarin asr research into industrial scale,”arXiv preprint arXiv:1808.10583, 2018
-
[29]
Wenetspeech: A 10000+ hours multi- domain mandarin corpus for speech recognition,
B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zenget al., “Wenetspeech: A 10000+ hours multi- domain mandarin corpus for speech recognition,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6182–6186
work page 2022
-
[30]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
work page 2015
-
[31]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,
G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhanget al., “Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,” arXiv preprint arXiv:2106.06909, 2021
-
[32]
Mls: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “Mls: A large-scale multilingual dataset for speech research,” arXiv preprint arXiv:2012.03411, 2020
-
[33]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wuet al., “Conformer: Convolution- augmented transformer for speech recognition,”arXiv preprint arXiv:2005.08100, 2020
-
[34]
Z. Gao, S. Zhang, I. McLoughlin, and Z. Yan, “Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to- end speech recognition,”arXiv preprint arXiv:2206.08317, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.