Recognition: no theorem link
Woosh: A Sound Effects Foundation Model
Pith reviewed 2026-05-13 20:48 UTC · model grok-4.3
The pith
Woosh releases an open sound effects foundation model whose components match or exceed existing open alternatives on public and private evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
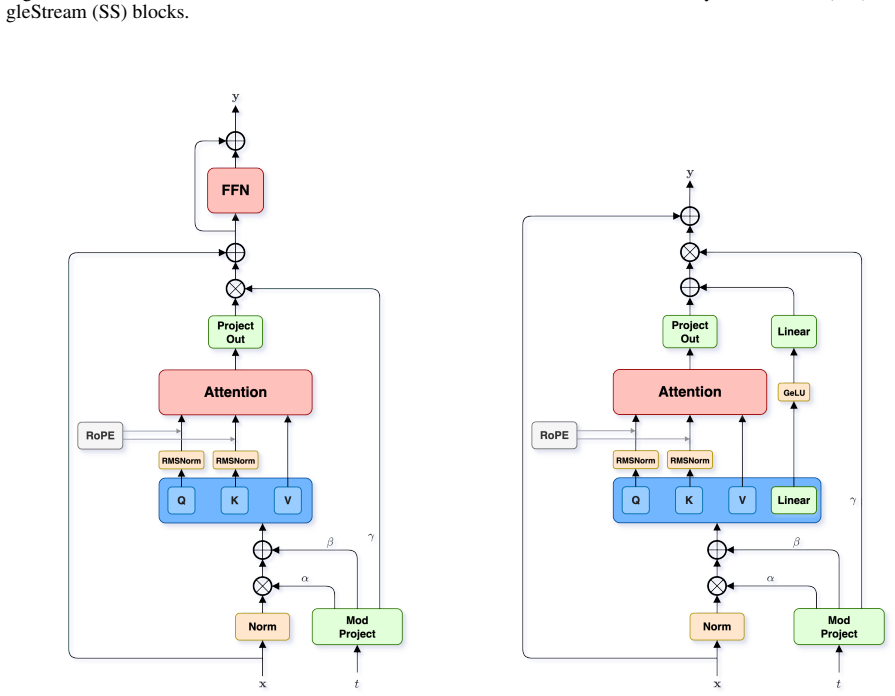
Woosh is a sound effects foundation model consisting of an audio encoder/decoder, a text-audio alignment model, text-to-audio and video-to-audio generative models, and their distilled low-resource counterparts; the complete set is released publicly with weights and inference code, and each component is shown to deliver competitive or superior performance to existing open models on both public and private test sets.
What carries the argument
The Woosh suite of models, which pairs a high-quality audio codec with a text-audio alignment module to condition specialized generative networks for sound effects from text or video prompts.
Load-bearing premise
The private-data comparisons assume that evaluation conditions, training data, and compute resources were equivalent to those used for the open baseline models without undisclosed advantages.
What would settle it
A fully public benchmark where all compared models are retrained or evaluated under identical standardized conditions would falsify the performance claim if Woosh falls below the open baselines on quantitative metrics or listening tests.
Figures




read the original abstract
The audio research community depends on open generative models as foundational tools for building novel approaches and establishing baselines. In this report, we present Woosh, Sony AI's publicly released sound effect foundation model, detailing its architecture, training process, and an evaluation against other popular open models. Being optimized for sound effects, we provide (1) a high-quality audio encoder/decoder model and (2) a text-audio alignment model for conditioning, together with (3) text-to-audio and (4) video-to-audio generative models. Distilled text-to-audio and video-to-audio models are also included in the release, allowing for low-resource operation and fast inference. Our evaluation on both public and private data shows competitive or better performance for each module when compared to existing open alternatives like StableAudio-Open and TangoFlux. Inference code and model weights are available at https://github.com/SonyResearch/Woosh. Demo samples can be found at https://sonyresearch.github.io/Woosh/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Woosh, Sony AI's publicly released sound effects foundation model. It comprises (1) a high-quality audio encoder/decoder, (2) a text-audio alignment model, (3) text-to-audio and (4) video-to-audio generative models, plus distilled low-resource variants. The authors detail the architecture and training process and report that evaluations on both public and private data show competitive or better performance for each module relative to open baselines such as StableAudio-Open and TangoFlux. Model weights and inference code are released at the provided GitHub link.
Significance. If the performance claims hold, the work supplies the audio community with a specialized open foundation model for sound-effect generation that includes video conditioning, a capability not uniformly present in the cited baselines. The public release of weights, inference code, and demo samples directly supports reproducibility and downstream use as a baseline or building block.
major comments (1)
- [Evaluation] Evaluation section: the headline claim of 'competitive or better performance for each module' on private internal data is load-bearing for the overall contribution, yet the manuscript provides no details on test-set composition, prompt distributions, sampling hyperparameters, or confirmation that the baseline models (StableAudio-Open, TangoFlux) were evaluated under identical conditioning, compute budgets, and post-processing. This prevents independent verification of equivalence and directly affects the strength of the empirical comparison.
minor comments (1)
- [Abstract] The abstract states that architecture and training details are provided, but explicit forward references to the relevant sections or tables (e.g., model hyperparameters, training curves) would improve readability for readers who wish to reproduce or extend the work.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work, recognition of its significance for the audio community, and recommendation for minor revision. We appreciate the constructive feedback on the evaluation section and address it point-by-point below. We will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: Evaluation section: the headline claim of 'competitive or better performance for each module' on private internal data is load-bearing for the overall contribution, yet the manuscript provides no details on test-set composition, prompt distributions, sampling hyperparameters, or confirmation that the baseline models (StableAudio-Open, TangoFlux) were evaluated under identical conditioning, compute budgets, and post-processing. This prevents independent verification of equivalence and directly affects the strength of the empirical comparison.
Authors: We agree that additional protocol details would strengthen the manuscript and improve reproducibility. In the revised version we will expand the Evaluation section with: (i) explicit descriptions of the public test sets, including sample counts, category distributions, and prompt characteristics; (ii) the exact sampling hyperparameters (guidance scale, diffusion steps, etc.) used for all models; and (iii) a clear statement that baselines were evaluated on identical conditioning inputs, under matched compute budgets, and with the same post-processing pipeline. For the private internal data we will add high-level statistics (number of clips, broad sound-effect categories, and rationale for internal evaluation) while noting that exact prompts cannot be released for confidentiality reasons. These changes will allow readers to assess the fairness of the comparisons without compromising proprietary data. revision: yes
- Exact prompts and full composition of the private internal test set cannot be disclosed due to Sony AI data confidentiality policies.
Circularity Check
No circularity: empirical claims rest on external baseline comparisons
full rationale
The paper presents an empirical release of the Woosh sound-effects models (encoder/decoder, text-audio aligner, text-to-audio and video-to-audio generators) together with training details and benchmark numbers. All load-bearing claims are performance comparisons against independent external models (StableAudio-Open, TangoFlux) on public data plus internal private data. No equations, first-principles derivations, or fitted parameters are presented whose outputs are then re-labeled as predictions; the reported metrics are direct empirical measurements, not quantities defined by the authors' own fitting procedure. Self-citations, if any, are not load-bearing for the central performance statements. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- model architecture hyperparameters
axioms (1)
- standard math Standard assumptions of deep generative modeling (e.g., latent variable models can capture audio distributions)
Reference graph
Works this paper leans on
-
[1]
Andrea Agostinelli et al.MusicLM: Generating Music From Text. 2023. arXiv: 2301.11325[cs.SD].URL: https://arxiv.org/abs/2301.11325
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
- [3]
- [4]
- [5]
- [6]
- [7]
- [8]
- [9]
-
[10]
Black Forest Labs et al.FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. 2025. arXiv: 2506.15742[cs.GR].URL: https://arxiv.org/abs/2506.15742
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Alexandre D ´efossez et al.High Fidelity Neural Audio Compression. 2022. arXiv: 2210 . 13438[eess.AS]. URL: https://arxiv.org/abs/2210.13438
work page internal anchor Pith review arXiv 2022
- [13]
-
[14]
Upsampling Artifacts in Neural Audio Synthesis
Jordi Pons et al. “Upsampling Artifacts in Neural Audio Synthesis”. In:Proc. of the IEEE Int. Conf. on Acous- tics, Speech and Signal Processing (ICASSP). 2021, pp. 3005–3009.URL: https://arxiv.org/abs/2010.14356
-
[15]
Frederic Font, Gerard Roma, and Xavier Serra. “Freesound Technical Demo”. In:MM ’13: Proceedings of the 21st ACM international conference on Multimedia. 2013, pp. 411–412
work page 2013
-
[16]
Audio Set: An ontology and human-labeled dataset for audio events
Jort F. Gemmeke et al. “Audio Set: An ontology and human-labeled dataset for audio events”. In:Proc. IEEE ICASSP 2017. New Orleans, LA, 2017
work page 2017
-
[17]
AudioCaps: Generating Captions for Audios in The Wild
Chris Dongjoo Kim et al. “AudioCaps: Generating Captions for Audios in The Wild”. In:NAACL-HLT. 2019
work page 2019
-
[18]
Xinhao Mei et al. “WavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio- Language Multimodal Research”. In:IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), pp. 3339–3354.ISSN: 2329-9304.DOI: 10.1109/taslp.2024.3419446.URL: http://dx.doi.org/10.1109/ TASLP.2024.3419446
-
[19]
2019.URL: https://datashare.ed.ac.uk/handle/10283/ 2950
Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald.CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92). 2019.URL: https://datashare.ed.ac.uk/handle/10283/ 2950
work page 2019
- [20]
- [21]
- [22]
- [23]
-
[24]
Yinhan Liu et al.RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019. arXiv: 1907 . 11692 [cs.CL].URL: https://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Efficient Training of Audio Transformers with Patchout
Khaled Koutini et al. “Efficient Training of Audio Transformers with Patchout”. In:23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22,
work page 2022
-
[26]
V oxCeleb: A Large-Scale Speaker Identification Dataset
Ed. by Hanseok Ko and John H. L. Hansen. ISCA, 2022, pp. 2753–2757.DOI: 10.21437/INTERSPEECH. 2022-227.URL: https://doi.org/10.21437/Interspeech.2022-227
-
[27]
Alexey Dosovitskiy et al.An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2021. arXiv: 2010.11929[cs.CV].URL: https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Alec Radford et al.Learning Transferable Visual Models From Natural Language Supervision. 2021. arXiv: 2103.00020[cs.CV].URL: https://arxiv.org/abs/2103.00020. 18 Woosh: A Sound Effects Foundation Model
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [29]
- [30]
-
[31]
Yaron Lipman et al.Flow Matching for Generative Modeling. 2023. arXiv: 2210.02747[cs.LG].URL: https: //arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Jianlin Su et al.RoFormer: Enhanced Transformer with Rotary Position Embedding. 2023. arXiv: 2104.09864 [cs.CL].URL: https://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Yaron Lipman et al. “Flow Matching Guide and Code”. In:arXiv preprint(2024). arXiv: 2412.06264[cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Mean flows for one-step generative modeling
Zhengyang Geng et al. “Mean flows for one-step generative modeling”. In:arXiv preprint(2025). arXiv: 2505. 13447[cs.LG]
work page 2025
-
[35]
Jonathan Ho and Tim Salimans.Classifier-Free Diffusion Guidance. 2022. arXiv: 2207.12598[cs.LG].URL: https://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
Axel Sauer et al. “Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation”. In: SIGGRAPH Asia 2024 Conference Papers. 2024, pp. 1–11.DOI: 10.1145/3680528.3687625
- [37]
-
[38]
Sana-sprint: One-step diffusion with continuous-time consistency distillation
Junsong Chen et al. “Sana-sprint: One-step diffusion with continuous-time consistency distillation”. In:arXiv preprint(2025). arXiv: arXiv:2503.09641[cs.GR]
-
[39]
Full-Band General Audio Synthesis with Score-Based Diffusion
Santiago Pascual et al. “Full-Band General Audio Synthesis with Score-Based Diffusion”. In:IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP). 2023.DOI: 10.1109/ICASSP49357.2023.10096760
-
[40]
Yusong Wu et al. “Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword- to-Caption Augmentation”. In:IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4-10, 2023. IEEE, 2023, pp. 1–5.DOI: 10.1109/ICASSP49357. 2023.10095969.URL: https://doi.org/10.1109/ICASSP49357...
- [41]
-
[42]
Jin Xu et al. “Qwen3-Omni Technical Report”. In:CoRRabs/2509.17765 (2025).DOI: 10.48550/ARXIV .2509. 17765. arXiv: 2509.17765.URL: https://doi.org/10.48550/arXiv.2509.17765
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[43]
Vggsound: A Large-Scale Audio-Visual Dataset
Honglie Chen et al. “Vggsound: A Large-Scale Audio-Visual Dataset”. In:2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020. IEEE, 2020, pp. 721–725.DOI: 10.1109/ICASSP40776.2020.9053174.URL: https://doi.org/10.1109/ICASSP40776.2020. 9053174
-
[44]
GameGen-X: Interactive Open-world Game Video Generation
Haoxuan Che et al. “GameGen-X: Interactive Open-world Game Video Generation”. In:The Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025.URL: https://openreview.net/forum?id=8VG8tpPZhe
work page 2025
-
[45]
SoundReactor: Frame-level Online Video-to-Audio Generation
Koichi Saito et al. “SoundReactor: Frame-level Online Video-to-Audio Generation”. In:ArXivabs/2510.02110 (2025).URL: https://api.semanticscholar.org/CorpusID:281725129
-
[46]
FoleyBench: A Benchmark For Video-to-Audio Models
Satvik Dixit et al. “FoleyBench: A Benchmark For Video-to-Audio Models”. In:ArXivabs/2511.13219 (2025). URL: https://api.semanticscholar.org/CorpusID:283072409
-
[47]
Rohit Girdhar et al. “ImageBind One Embedding Space to Bind Them All”. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 2023, pp. 15180–15190.DOI: 10.1109/CVPR52729.2023.01457.URL: https://doi.org/10.1109/CVPR52729. 2023.01457. 19 Woosh: A Sound Effects Foundation Model
-
[48]
Lifting the veil on visual information flow in mllms: Unlocking pathways to faster inference
Ho Kei Cheng et al. “MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthe- sis”. In:IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. Computer Vision Foundation / IEEE, 2025, pp. 28901–28911.DOI: 10.1109/CVPR52734. 2025.02691
-
[49]
Nataniel Ruiz et al.DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- [50]
-
[51]
Daniel Garibi et al.TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space. 2025. arXiv: 2501.12224[cs.CV].URL: https://arxiv.org/abs/2501.12224. Appendix A Distillation Pseudocode Algorithm 1 provides detailed pseudocode for the Woosh-DFLow and Woosh-DVFlow training processes, using the MeanFlow criterion together with latent adver...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.