Recognition: no theorem link
Attention at Rest Stays at Rest: Breaking Visual Inertia for Cognitive Hallucination Mitigation
Pith reviewed 2026-05-13 22:03 UTC · model grok-4.3
The pith
Visual attention in multimodal models remains static after initial steps, leading to failures in relational reasoning that a new excitation method can address.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through token-wise attention analysis, visual attention in MLLMs exhibits pronounced inertia, remaining largely static once settled during early decoding steps and failing to dynamically support relational inference required for cognitive understanding. The proposed Inertia-aware Visual Excitation (IVE) method breaks this pattern by selecting visual tokens that emerge dynamically relative to historical trends and applying an inertia-aware penalty to discourage over-concentration and persistence in localized regions, thereby modeling cognitive inference as dynamic responsiveness of visual attention.
What carries the argument
The Inertia-aware Visual Excitation (IVE) method, which identifies inertial attention behavior and excites dynamic token responsiveness through trend-based selection and penalties.
Load-bearing premise
That promoting dynamic visual token selection and penalizing attention persistence will enhance relational inference capabilities without causing new errors or reducing performance on non-cognitive tasks.
What would settle it
Running IVE on a cognitive hallucination benchmark and finding no reduction in error rates for questions requiring inter-object relational deduction compared to the base model.
Figures
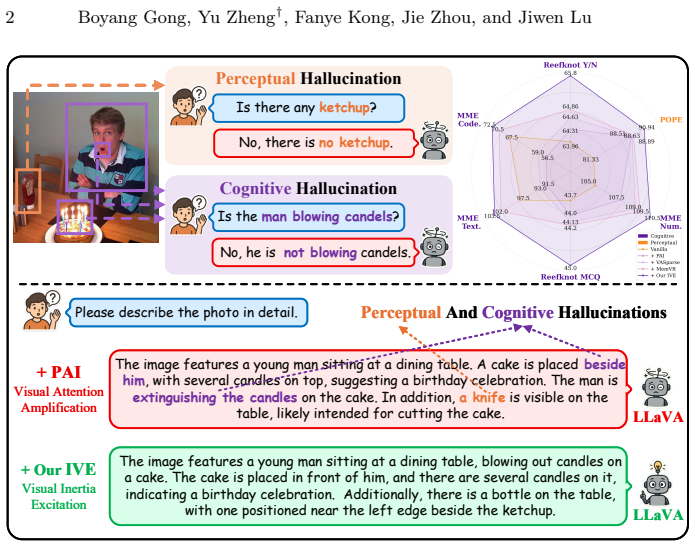






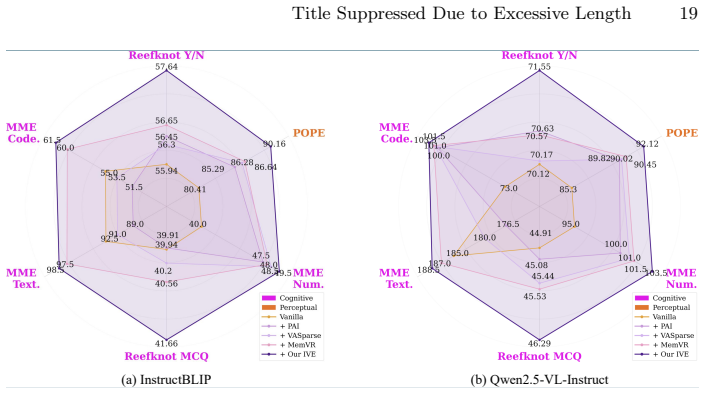

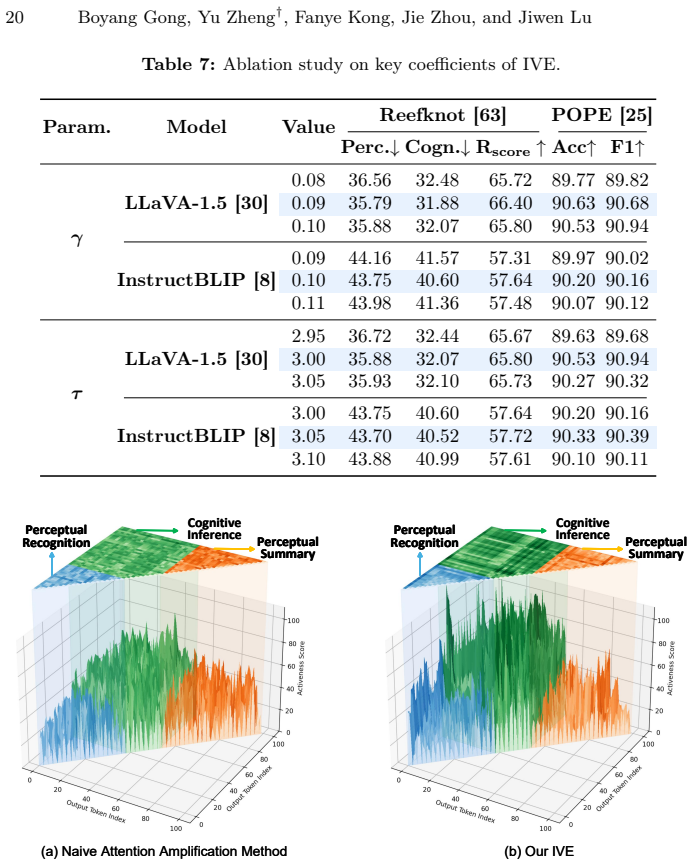







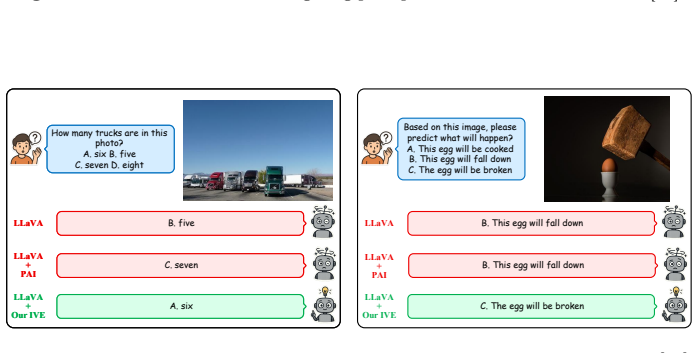
read the original abstract
Like a body at rest that stays at rest, we find that visual attention in multimodal large language models (MLLMs) exhibits pronounced inertia, remaining largely static once settled during early decoding steps and failing to support the compositional understanding required for cognitive inference. While existing hallucination mitigation methods mainly target perceptual hallucinations concerning object existence or attributes, they remain inadequate for such cognitive hallucinations that require inter-object relational deduction. Through token-wise attention analysis, we identify this visual inertia as a key factor: attention to semantically critical regions remains persistently focused and fails to dynamically support relational inference. We thereby propose a training-free Inertia-aware Visual Excitation (IVE) method that breaks this inertial pattern by modeling cognitive inference as the dynamic responsiveness of visual attention. Specifically, IVE selects visual tokens that are dynamically emerging relative to historical attention trends while distinguishing tokens exhibiting inertial behavior. To further facilitate compositional inference, IVE introduces an inertia-aware penalty that discourages over-concentration and limits the persistence of attention within localized regions. Extensive experiments show that IVE is effective across various base MLLMs and multiple hallucination benchmarks, particularly for cognitive hallucinations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual attention in MLLMs exhibits pronounced inertia—remaining largely static after early decoding steps and failing to support compositional relational inference—leading to cognitive hallucinations distinct from perceptual ones. Through token-wise attention analysis, the authors identify persistent focus on semantically critical regions as the key factor and propose a training-free Inertia-aware Visual Excitation (IVE) method. IVE selects dynamically emerging visual tokens relative to historical attention trends, distinguishes inertial tokens, and applies an inertia-aware penalty to discourage over-concentration, thereby modeling cognitive inference as dynamic attention responsiveness. Experiments reportedly show effectiveness across base MLLMs and hallucination benchmarks, especially for cognitive cases.
Significance. If the central claim holds, the work provides a novel, training-free perspective on hallucination mitigation by directly targeting attention dynamics rather than perceptual object attributes. The parameter-free grounding in token-wise analysis and the explicit modeling of inertia as a barrier to relational deduction are strengths that could inform future MLLM interpretability research. However, the absence of ablations isolating the historical-trend mechanism limits the ability to credit the specific inertia-breaking logic over generic attention spreading.
major comments (2)
- [§3] §3 (IVE method description): the central claim that selecting tokens relative to historical trends plus an inertia-aware penalty specifically enables compositional inference is not supported by any ablation that isolates this component from generic attention redistribution or diversity injection; improvements on benchmarks could arise from any increase in attention spread.
- [Experiments] Experiments section: no ablation studies, quantitative metrics, or error analysis are referenced that would verify the causal role of visual inertia in cognitive hallucinations versus other attention patterns, leaving the data support for the mapping from IVE operations to reduced hallucinations unverified.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experiments' is used without any specific benchmark names, metrics, or baseline comparisons, reducing clarity on the scope of validation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that additional ablations are needed to strengthen the causal claims regarding visual inertia and the specific contributions of the historical-trend mechanism in IVE. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (IVE method description): the central claim that selecting tokens relative to historical trends plus an inertia-aware penalty specifically enables compositional inference is not supported by any ablation that isolates this component from generic attention redistribution or diversity injection; improvements on benchmarks could arise from any increase in attention spread.
Authors: We acknowledge that the current version does not include an ablation isolating the historical attention trend component from generic spreading. In the revision we will add a controlled comparison of IVE against a variant that applies uniform diversity injection without historical trend selection, together with attention visualization showing the difference in dynamic responsiveness on relational queries. revision: yes
-
Referee: [Experiments] Experiments section: no ablation studies, quantitative metrics, or error analysis are referenced that would verify the causal role of visual inertia in cognitive hallucinations versus other attention patterns, leaving the data support for the mapping from IVE operations to reduced hallucinations unverified.
Authors: We agree that stronger quantitative linkage is required. The revised experiments section will include (i) attention entropy and shift-rate metrics computed across decoding steps to quantify inertia, (ii) error analysis breaking down hallucination types before/after IVE, and (iii) an ablation that disables the inertia-aware penalty while keeping token selection, to isolate its contribution to cognitive hallucination reduction. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper grounds its identification of visual inertia directly in token-wise attention analysis of MLLM decoding steps and proposes an explicitly training-free IVE method that selects dynamically emerging tokens relative to historical trends while applying an inertia-aware penalty. No equations or steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations; the mapping from observed attention patterns to the proposed operations remains an independent modeling choice supported by external hallucination benchmarks rather than internal equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-wise attention analysis during decoding can identify persistent focus patterns that limit relational inference
invented entities (1)
-
Inertia-aware Visual Excitation (IVE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
- [4]
- [5]
-
[6]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023)2(3), 6 (2023)
work page 2023
- [7]
-
[8]
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. In: NeurIPS. vol. 36, pp. 49250–49267 (2023)
work page 2023
- [9]
- [10]
-
[11]
arXiv preprint arXiv:2509.11569 (2025)
Ding, Y., Zhu, X., Xia, T., Wu, J., Chen, X., Liu, Q., Wang, L.: D 2 hscore: Reasoning-aware hallucination detection via semantic breadth and depth analysis in llms. arXiv preprint arXiv:2509.11569 (2025)
-
[12]
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. In: NeurIPS (2025)
work page 2025
-
[13]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
GLM, T., Zeng, A., Xu, B., Wang, B., Zhang, C., Yin, D., Zhang, D., Rojas, D., Feng, G., Zhao, H., et al.: Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Hu, M., Pan, S., Li, Y., Yang, X.: Advancing medical imaging with language mod- els: A journey from n-grams to chatgpt. arXiv preprint arXiv:2304.04920 (2023) 26 Boyang Gong, Yu Zheng †, Fanye Kong, Jie Zhou, and Jiwen Lu
- [17]
- [18]
-
[19]
Jung, M., Lee, S., Kim, E., Yoon, S.: Visual attention never fades: Selective pro- gressive attention recalibration for detailed image captioning in multimodal large language models. In: ICML (2025)
work page 2025
- [20]
- [21]
- [22]
-
[23]
Li, K., Patel, O., Viégas, F., Pfister, H., Wattenberg, M.: Inference-time interven- tion: Eliciting truthful answers from a language model. In: NeurIPS. vol. 36, pp. 41451–41530 (2023)
work page 2023
-
[24]
Li, X.L., Holtzman, A., Fried, D., Liang, P., Eisner, J., Hashimoto, T., Zettlemoyer, L., Lewis, M.: Contrastive decoding: Open-ended text generation as optimization. In: ACL. p. 12286–12312 (2023)
work page 2023
-
[25]
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hallucination in large vision-language models. In: EMNLP (2023)
work page 2023
- [26]
-
[27]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
arXiv preprint arXiv:2308.14972 (2023)
Liu, H., Zhu, Y., Kato, K., Kondo, I., Aoyama, T., Hasegawa, Y.: Llm-based human-robot collaboration framework for manipulation tasks. arXiv preprint arXiv:2308.14972 (2023)
- [30]
-
[31]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS. vol. 36, pp. 34892–34916 (2024)
work page 2024
- [32]
-
[33]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: ECCV. pp. 216–233 (2024)
work page 2024
-
[34]
arXiv preprint arXiv:2304.09349 (2023) Title Suppressed Due to Excessive Length 27
Mai, J., Chen, J., Li, B., Qian, G., Elhoseiny, M., Ghanem, B.: Llm as a robotic brain: Unifying egocentric memory and control. arXiv preprint arXiv:2304.09349 (2023) Title Suppressed Due to Excessive Length 27
- [35]
-
[36]
Ren, J., Zhao, Y., Vu, T., Liu, P.J., Lakshminarayanan, B.: Self-evaluation im- proves selective generation in large language models. In: NeurIPS Workshop (2023)
work page 2023
-
[37]
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: EMNLP (2018)
work page 2018
-
[38]
Su, W., Wang, C., Ai, Q., Hu, Y., Wu, Z., Zhou, Y., Liu, Y.: Unsupervised real- time hallucination detection based on the internal states of large language models. In: ACL. pp. 14379–14391 (2025)
work page 2025
-
[39]
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.X., Yang, Y., et al.: Aligning large multimodal models with factually augmented rlhf. In: ACL. pp. 13088–13110 (2024)
work page 2024
-
[40]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., Hashimoto, T.B.: Stanford alpaca: An instruction-following llama model (2023)
work page 2023
-
[41]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., Manning, C.D.: Just ask for calibration: Strategies for eliciting calibrated confi- dence scores from language models fine-tuned with human feedback. In: ACL. p. 5433–5442 (2023)
work page 2023
-
[42]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS30(2017)
work page 2017
- [45]
-
[46]
Communications Engineering3(1), 133 (2024)
Wang, S., Zhao, Z., Ouyang, X., Liu, T., Wang, Q., Shen, D.: Interactive computer- aided diagnosis on medical image using large language models. Communications Engineering3(1), 133 (2024)
work page 2024
-
[47]
Wang, X., Pan, J., Ding, L., Biemann, C.: Mitigating hallucinations in large vision- language models with instruction contrastive decoding. In: ACL. p. 15840–15853 (2024)
work page 2024
-
[48]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al.: Huggingface’s transformers: State-of- the-art natural language processing. arXiv preprint arXiv:1910.03771 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[49]
arXiv preprint arXiv:2307.01848 (2023)
Wu, Z., Wang, Z., Xu, X., Lu, J., Yan, H.: Embodied task planning with large language models. arXiv preprint arXiv:2307.01848 (2023)
- [50]
- [51]
-
[52]
Yin, Y., Xie, Y., Yang, W., Yang, D., Ru, J., Zhuang, X., Liang, L., Zou, Y.: Atri: Mitigating multilingual audio text retrieval inconsistencies by reducing data distribution errors. In: ACL. pp. 5491–5504 (2025) 28 Boyang Gong, Yu Zheng †, Fanye Kong, Jie Zhou, and Jiwen Lu
work page 2025
- [53]
- [54]
-
[55]
arXiv preprint arXiv:2509.21789 (2025)
Yu, X., Xu, C., Zhang, G., He, Y., Chen, Z., Xue, Z., Zhang, J., Liao, Y., Hu, X., Jiang, Y.G., et al.: Visual multi-agent system: Mitigating hallucination snowballing via visual flow. arXiv preprint arXiv:2509.21789 (2025)
- [56]
-
[57]
Yue, Z., Zhang, L., Jin, Q.: Less is more: Mitigating multimodal hallucination from an eos decision perspective. In: ACL. pp. 11766–11781 (2024)
work page 2024
- [58]
- [59]
-
[60]
Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., Huang, X., Zhao, E., Zhang, Y., Chen, Y., et al.: Siren’s song in the ai ocean: A survey on hallucination in large language models. Computational Linguistics pp. 1–46 (2025)
work page 2025
- [61]
- [62]
-
[63]
Zheng, K., Chen, J., Yan, Y., Zou, X., Hu, X.: Reefknot: A comprehensive bench- mark for relation hallucination evaluation, analysis and mitigation in multimodal large language models. In: ACL. pp. 6193–6212 (2024)
work page 2024
-
[64]
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: NeurIPS. vol. 36, pp. 46595–46623 (2023)
work page 2023
- [65]
-
[66]
Zhuang, X., Cheng, X., Zhu, Z., Chen, Z., Li, H., Zou, Y.: Towards multimodal-augmented pre-trained language models via self-balanced expectation- maximization iteration. In: ACM MM (2024)
work page 2024
- [67]
-
[68]
Zou, X., Wang, Y., Yan, Y., Lyu, Y., Zheng, K., Huang, S., Chen, J., Jiang, P., Liu, J., Tang, C., et al.: Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models. In: ICML (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.