Recognition: 2 theorem links
· Lean TheoremUI-Oceanus: Scaling GUI Agents with Synthetic Environmental Dynamics
Pith reviewed 2026-05-16 02:50 UTC · model grok-4.3
The pith
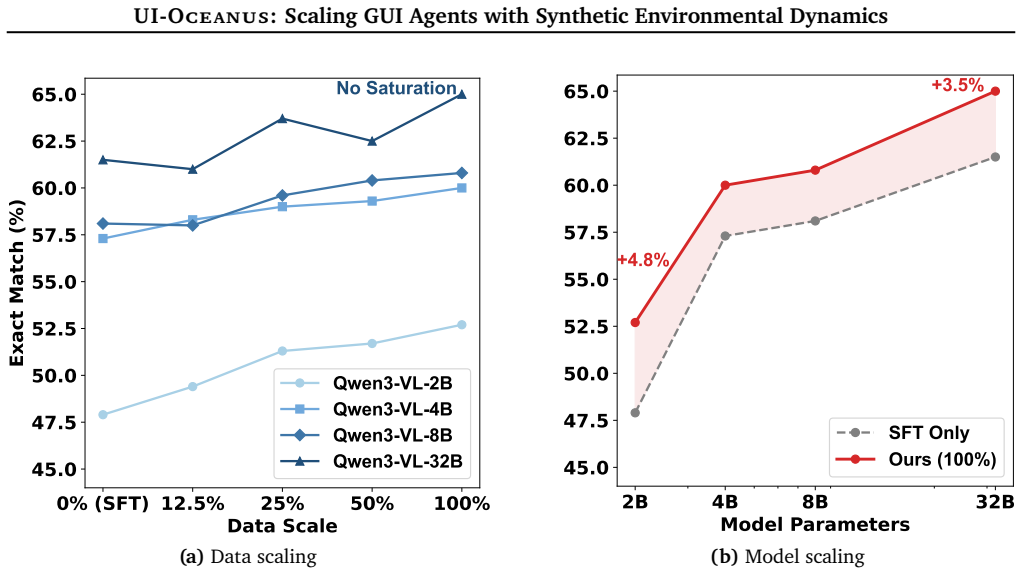
UI-Oceanus shows that continual pre-training on forward dynamics predictions from synthetic GUI exploration improves agent success rates by 7% offline and 16.8% online, with gains scaling by data volume.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
models utilizing Continual Pre-Training (CPT) on synthetic dynamics outperform non-CPT baselines with an average success rate improvement of 7% on offline benchmarks, which amplifies to a 16.8% gain in real-world online navigation. Furthermore, we observe that navigation performance scales with synthetic data volume.
Load-bearing premise
That forward dynamics prediction identified via systematic investigation of self-supervised objectives is the primary scalable driver and that autonomous exploration verified by system execution yields unbiased high-density generative supervision for a robust internal world model.
Figures



read the original abstract
Scaling generalist GUI agents is hindered by the data scalability bottleneck of expensive human demonstrations and the "distillation ceiling" of synthetic teacher supervision. To transcend these limitations, we propose UI-Oceanus, a framework that shifts the learning focus from mimicking high-level trajectories to mastering interaction physics via ground-truth environmental feedback. Through a systematic investigation of self-supervised objectives, we identify that forward dynamics, defined as the generative prediction of future interface states, acts as the primary driver for scalability and significantly outweighs inverse inference. UI-Oceanus leverages this insight by converting low-cost autonomous exploration, which is verified directly by system execution, into high-density generative supervision to construct a robust internal world model. Experimental evaluations across a series of models demonstrate the decisive superiority of our approach: models utilizing Continual Pre-Training (CPT) on synthetic dynamics outperform non-CPT baselines with an average success rate improvement of 7% on offline benchmarks, which amplifies to a 16.8% gain in real-world online navigation. Furthermore, we observe that navigation performance scales with synthetic data volume. These results confirm that grounding agents in forward predictive modeling offers a superior pathway to scalable GUI automation with robust cross-domain adaptability and compositional generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UI-Oceanus, a framework for scaling GUI agents that shifts focus from trajectory imitation to mastering interaction physics via ground-truth feedback. It claims that a systematic investigation of self-supervised objectives identifies forward dynamics (generative future-state prediction) as the dominant scalable driver over inverse inference; autonomous exploration verified by system execution is converted into high-density synthetic supervision for continual pre-training (CPT) of an internal world model. Models using CPT on this synthetic dynamics reportedly achieve 7% average success-rate gains on offline benchmarks and 16.8% gains in real-world online navigation, with performance scaling with synthetic data volume.
Significance. If the central claims hold after proper controls, the work would offer a concrete, data-scalable route to robust GUI agents that reduces dependence on human demonstrations and teacher distillation, with potential benefits for cross-domain generalization. The emphasis on verifiable system execution as an external ground truth and the reported scaling behavior are positive features that could influence future agent training pipelines.
major comments (3)
- Abstract: the assertion that forward dynamics 'significantly outweighs inverse inference' rests on an unspecified 'systematic investigation of self-supervised objectives,' yet no description of the candidate objectives, matched data volumes, CPT schedules, or quantitative metrics used in that comparison is supplied, leaving the identification of forward dynamics as the primary driver unsupported.
- Abstract: the 7% offline and 16.8% online success-rate improvements are reported only for CPT on synthetic dynamics; no ablation results compare forward dynamics against other self-supervised objectives (e.g., inverse inference or reconstruction) at identical data volume and CPT schedule, so the gains cannot be isolated from the effects of additional pre-training data or the CPT procedure itself.
- Abstract: the experimental claims cite specific percentage gains and a scaling observation but provide no information on baselines, number of runs, statistical tests, data exclusion criteria, or evaluation protocols, rendering the numbers unverifiable and the soundness of the central empirical claim low.
minor comments (1)
- Abstract: the phrase 'high-density generative supervision' is used without a quantitative definition or comparison to the density of human-demonstration data.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each of the major comments point by point below, and we will make revisions to the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: Abstract: the assertion that forward dynamics 'significantly outweighs inverse inference' rests on an unspecified 'systematic investigation of self-supervised objectives,' yet no description of the candidate objectives, matched data volumes, CPT schedules, or quantitative metrics used in that comparison is supplied, leaving the identification of forward dynamics as the primary driver unsupported.
Authors: We agree that the abstract, due to length constraints, does not detail the systematic investigation. The main body of the manuscript describes the self-supervised objectives considered and the comparison metrics in Section 3. To strengthen the presentation, we will revise the abstract to briefly outline the key objectives compared (forward dynamics, inverse inference, and reconstruction) and the primary metric (downstream success rate) used to identify forward dynamics as the dominant objective. revision: yes
-
Referee: Abstract: the 7% offline and 16.8% online success-rate improvements are reported only for CPT on synthetic dynamics; no ablation results compare forward dynamics against other self-supervised objectives (e.g., inverse inference or reconstruction) at identical data volume and CPT schedule, so the gains cannot be isolated from the effects of additional pre-training data or the CPT procedure itself.
Authors: We acknowledge this limitation in the current presentation. While the paper focuses on the forward dynamics approach, we will add ablation studies in the revised manuscript that compare forward dynamics prediction against inverse inference and reconstruction objectives using identical data volumes and CPT schedules to isolate the contribution of each objective. revision: yes
-
Referee: Abstract: the experimental claims cite specific percentage gains and a scaling observation but provide no information on baselines, number of runs, statistical tests, data exclusion criteria, or evaluation protocols, rendering the numbers unverifiable and the soundness of the central empirical claim low.
Authors: We agree that additional details on the experimental setup are needed for verifiability. In the revised version, we will expand the experimental section to include the baseline models used, the number of independent runs (e.g., 5 runs per condition), statistical significance tests (e.g., paired t-tests), data exclusion criteria, and detailed evaluation protocols for both offline and online settings. revision: yes
Circularity Check
No significant circularity; derivation relies on claimed external investigation and system-verified data
full rationale
The paper states that a systematic investigation of self-supervised objectives identified forward dynamics as the primary scalable driver, then applies CPT on synthetic data generated via autonomous exploration that is verified directly by system execution. No equations, fitted parameters, or self-citations are shown that reduce the performance claims (7% offline, 16.8% online gains) to the inputs by construction. The gains are presented as experimental outcomes on benchmarks, and the verification step supplies an external ground truth independent of the modeling choice. The derivation chain therefore remains self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forward dynamics prediction acts as the primary driver for scalability and significantly outweighs inverse inference
invented entities (1)
-
internal world model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
forward dynamics ... generative prediction of future interface states ... Lfwd = −E log Pθ(st+1 | st, at)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance scales log-linearly with synthetic data volume ... no saturation up to 32B parameters and 3.2B tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
Corpus complexity matters in pretraining language models
Ameeta Agrawal and Suresh Singh. Corpus complexity matters in pretraining language models. In Proceedings of The Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), pages 257--263, 2023
work page 2023
-
[2]
Anthropic . Claude opus 4.5, 2025 a . URL https://www.anthropic.com/claude/opus. Accessed: 2026-01-29
work page 2025
-
[3]
Anthropic . Claude sonnet 4.5, 2025 b . URL https://www.anthropic.com/news/claude-sonnet-4-5. Accessed: 2026-01-29
work page 2025
-
[4]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619--15629, 2023
work page 2023
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Seed1.8 model card: Towards generalized real-world agency, 2025
ByteDance-Seed. Seed1.8 model card: Towards generalized real-world agency, 2025. Accessed: 2026-01-29
work page 2025
-
[8]
Guicourse: From general vision language models to versatile GUI agents
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. Guicourse: From general vision language models to versatile GUI agents. arXiv preprint arXiv:2406.11317, 2024
-
[9]
Seeclick: Harnessing GUI grounding for advanced visual GUI agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing GUI grounding for advanced visual GUI agents. arXiv preprint arXiv:2401.10935, 2024
-
[10]
Uishift: Enhancing vlm-based gui agents through self-supervised reinforcement learning
Longxi Gao, Li Zhang, and Mengwei Xu. Uishift: Enhancing vlm-based gui agents through self-supervised reinforcement learning. arXiv preprint arXiv:2505.12493, 2025
-
[11]
Shortcut learning in deep neural networks
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2 0 (11): 0 665--673, 2020
work page 2020
-
[12]
Google . Android monkey. https://developer.android.com/studio/test/monkey, 2021. Accessed: 2026-01-03
work page 2021
-
[13]
Google . Gemini 3 flash, 2025. URL https://deepmind.google/models/gemini/flash/. Accessed: 2026-01-29
work page 2025
-
[14]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International journal of computer vision, 129 0 (6): 0 1789--1819, 2021
work page 2021
-
[15]
Practical GUI testing of Android applications via model abstraction and refinement
Tianxiao Gu, Chengnian Sun, Xiaoxing Ma, Chun Cao, Chang Xu, Yuan Yao, Qirun Zhang, Jian Lu, and Zhendong Su. Practical GUI testing of Android applications via model abstraction and refinement. In ICSE, pages 269--280, 2019
work page 2019
-
[16]
David Ha and J \"u rgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2 0 (3), 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[18]
Mastering diverse control tasks through world models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models. Nature, pages 1--7, 2025
work page 2025
-
[19]
Cogagent: A visual language model for GUI agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for GUI agents. In CVPR, pages 14281--14290, 2024
work page 2024
-
[20]
A path towards autonomous machine intelligence version 0.9
Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62 0 (1): 0 1--62, 2022
work page 2022
-
[21]
Mobileworldbench: Towards semantic world modeling for mobile agents
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Mobileworldbench: Towards semantic world modeling for mobile agents. arXiv preprint arXiv:2512.14014, 2025
-
[22]
On the effects of data scale on UI control agents
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on UI control agents. NeurIPS, 37: 0 92130--92154, 2024
work page 2024
-
[23]
Widget captioning: Generating natural language description for mobile user interface elements
Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. Widget captioning: Generating natural language description for mobile user interface elements. arXiv preprint arXiv:2010.04295, 2020
-
[24]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19498--19508, 2025 a
work page 2025
-
[25]
Musen Lin, Minghao Liu, Taoran Lu, Lichen Yuan, Yiwei Liu, Haonan Xu, Yu Miao, Yuhao Chao, and Zhaojian Li. Gui-rewalk: Massive data generation for gui agent via stochastic exploration and intent-aware reasoning. arXiv preprint arXiv:2509.15738, 2025 b
-
[26]
GUI odyssey: A comprehensive dataset for cross-app GUI navigation on mobile devices
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. GUI odyssey: A comprehensive dataset for cross-app GUI navigation on mobile devices. arXiv preprint arXiv:2406.08451, 2024
-
[27]
Vimo: A generative visual gui world model for app agents
Dezhao Luo, Bohan Tang, Kang Li, Georgios Papoudakis, Jifei Song, Shaogang Gong, Jianye Hao, Jun Wang, and Kun Shao. Vimo: A generative visual gui world model for app agents. arXiv preprint arXiv:2504.13936, 2025
-
[28]
When less is more: Investigating data pruning for pretraining llms at scale
Max Marion, Ahmet \"U st \"u n, Luiza Pozzobon, Alex Wang, Marzieh Fadaee, and Sara Hooker. When less is more: Investigating data pruning for pretraining llms at scale. arXiv preprint arXiv:2309.04564, 2023
-
[29]
Update to gpt-5 system card: Gpt-5.2
OpenAI. Update to gpt-5 system card: Gpt-5.2. Technical report, OpenAI, 12 2025. URL https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf. Accessed: 2026-01-29
work page 2025
-
[30]
Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents
Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, and Ahmed Hassan. Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents. In Findings of the Association for Computational Linguistics: ACL 2025, pages 6300--6323, 2025
work page 2025
-
[31]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Scaling synthetic task generation for agents via exploration
Ram Ramrakhya, Andrew Szot, Omar Attia, Yuhao Yang, Anh Nguyen, Bogdan Mazoure, Zhe Gan, Harsh Agrawal, and Alexander Toshev. Scaling synthetic task generation for agents via exploration. arXiv preprint arXiv:2509.25047, 2025
-
[33]
Badge: prioritizing UI events with hierarchical multi-armed bandits for automated UI testing
Dezhi Ran, Hao Wang, Wenyu Wang, and Tao Xie. Badge: prioritizing UI events with hierarchical multi-armed bandits for automated UI testing. In ICSE, pages 894--905, 2023
work page 2023
-
[34]
Androidinthewild: A large-scale dataset for Android device control
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Androidinthewild: A large-scale dataset for Android device control. NeurIPS, 36: 0 59708--59728, 2023
work page 2023
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Guided, stochastic model-based gui testing of android apps
Ting Su, Guozhu Meng, Yuting Chen, Ke Wu, Weiming Yang, Yao Yao, Geguang Pu, Yang Liu, and Zhendong Su. Guided, stochastic model-based gui testing of android apps. In Proceedings of the 2017 11th joint meeting on foundations of software engineering, pages 245--256, 2017
work page 2017
-
[37]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, et al. Os-genesis: Automating gui agent trajectory construction via reverse task synthesis. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5555--5579, 2025
work page 2025
-
[38]
Magicgui: A foundational mobile gui agent with scalable data pipeline and reinforcement fine-tuning
Liujian Tang, Shaokang Dong, Yijia Huang, Minqi Xiang, Hongtao Ruan, Bin Wang, Shuo Li, Zhiheng Xi, Zhihui Cao, Hailiang Pang, et al. Magicgui: A foundational mobile gui agent with scalable data pipeline and reinforcement fine-tuning. arXiv preprint arXiv:2508.03700, 2025
-
[39]
Weixin mini program platform capabilities, 2024
Tencent . Weixin mini program platform capabilities, 2024. URL https://developers.weixin.qq.com/miniprogram/dev/platform-capabilities/miniapp/intro/. Accessed: 2026-01-29
work page 2024
-
[40]
Behavioral Cloning from Observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation. arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Rethinking the role of text complexity in language model pretraining
Dan John Velasco and Matthew Theodore Roque. Rethinking the role of text complexity in language model pretraining. In Proceedings of the First BabyLM Workshop, pages 1--28, 2025
work page 2025
-
[42]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Vagen:reinforcing world model reasoning for multi-turn vlm agents, 2025
Kangrui Wang*, Pingyue Zhang*, Zihan Wang*, Yaning Gao*, Linjie Li*, Qineng Wang, Hanyang Chen, Chi Wan, Yiping Lu, Zhengyuan Yang, Lijuan Wang, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, Yejin Choi, and Manling Li. Vagen:reinforcing world model reasoning for multi-turn vlm agents, 2025. URL https://vagen-ai.github.io/
work page 2025
-
[44]
Gui agents with foundation models: A comprehensive survey
Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, et al. Gui agents with foundation models: A comprehensive survey. arXiv preprint arXiv:2411.04890, 2024
-
[45]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
work page 2022
-
[46]
Skill-adpative imitation learning for UI test reuse
Mengzhou Wu, Hao Wang, Jun Ren, Yuan Cao, Yuetong Li, Alex Jiang, Dezhi Ran, Yitao Hu, Wei Yang, and Tao Xie. Skill-adpative imitation learning for UI test reuse. arXiv preprint arXiv:2409.13311, 2024 a
-
[47]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents. arXiv preprint arXiv:2410.23218, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Mobilerl: Online agentic reinforcement learning for mobile gui agents, 2025 a
Yifan Xu, Xiao Liu, Xinghan Liu, Jiaqi Fu, Hanchen Zhang, Bohao Jing, Shudan Zhang, Yuting Wang, Wenyi Zhao, and Yuxiao Dong. Mobilerl: Online agentic reinforcement learning for mobile gui agents, 2025 a . URL https://arxiv.org/abs/2509.18119
-
[49]
Aguvis: Unified pure vision agents for autonomous GUI interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous GUI interaction. In ICML, 2025 b
work page 2025
-
[50]
Mobile-agent-v3: Foundamental agents for gui automation
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-agent-v3: Foundamental agents for gui automation. arXiv preprint arXiv:2508.15144, 2025
-
[51]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
On the interplay of pre-training, mid-training, and rl on reasoning language models, 2025 a
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models, 2025 a . URL https://arxiv.org/abs/2512.07783
-
[53]
Progrm: Build better gui agents with progress rewards
Danyang Zhang, Situo Zhang, Ziyue Yang, Zichen Zhu, Zihan Zhao, Ruisheng Cao, Lu Chen, and Kai Yu. Progrm: Build better gui agents with progress rewards. arXiv preprint arXiv:2505.18121, 2025 b
-
[54]
Android in the zoo: Chain-of-action-thought for GUI agents
Jiwen Zhang, Jihao Wu, Yihua Teng, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. Android in the zoo: Chain-of-action-thought for GUI agents. arXiv preprint arXiv:2403.02713, 2024
-
[55]
Agent learning via early experience
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience. arXiv preprint arXiv:2510.08558, 2025 c
-
[56]
Bee: A high-quality corpus and full-stack suite to unlock advanced fully open mllms
Yi Zhang, Bolin Ni, Xin-Sheng Chen, Heng-Rui Zhang, Yongming Rao, Houwen Peng, Qinglin Lu, Han Hu, Meng-Hao Guo, and Shi-Min Hu. Bee: A high-quality corpus and full-stack suite to unlock advanced fully open mllms. arXiv preprint arXiv:2510.13795, 2025 d
-
[57]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[58]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[59]
GUI as a state transition graph
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.