Recognition: 2 theorem links
· Lean TheoremSpatial-Aware Conditioned Fusion for Audio-Visual Navigation
Pith reviewed 2026-05-13 21:08 UTC · model grok-4.3
The pith
Spatial-Aware Conditioned Fusion improves audio-visual navigation by discretizing target position to condition visual feature modulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
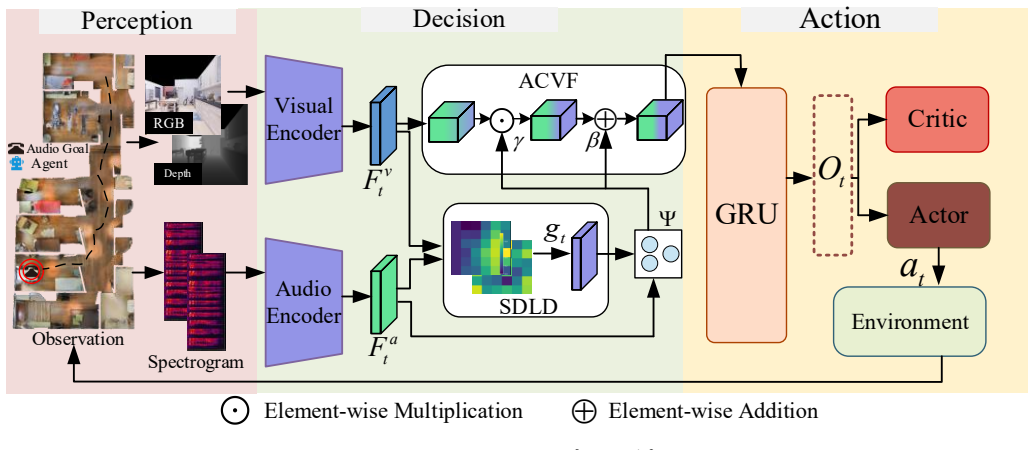
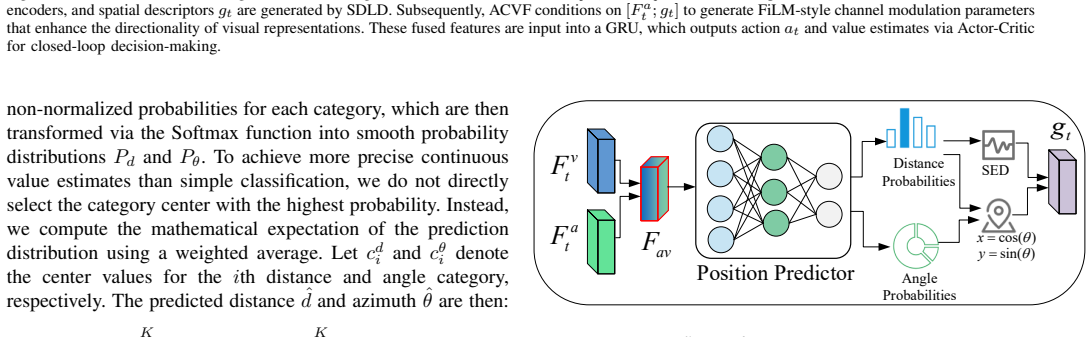
SACF first discretizes the target's relative direction and distance from audio-visual cues, predicts their distributions, and encodes them as a compact descriptor for policy conditioning and state modeling. SACF then uses audio embeddings and spatial descriptors to generate channel-wise scaling and bias to modulate visual features via conditional linear transformation, producing target-oriented fused representations.
What carries the argument
Spatial-Aware Conditioned Fusion (SACF), which turns audio-visual cues into a discrete spatial descriptor and applies it through conditional linear transformation to scale and bias visual features.
If this is right
- Navigation policies reach targets in fewer steps than methods using simple concatenation.
- Computational cost drops because the spatial descriptor replaces heavier fusion operations.
- The same model maintains performance on target sounds absent from training data.
- Explicit spatial conditioning produces state representations that support more stable reinforcement learning.
Where Pith is reading between the lines
- The same discretization-plus-modulation pattern could be tested on other continuous control tasks that combine vision with another modality.
- In real-robot settings the compact descriptor might reduce sensitivity to audio noise by focusing the policy on relative geometry rather than raw waveforms.
- Extending the discretization bins to include elevation or velocity could be checked without changing the core conditioning step.
Load-bearing premise
That discretizing the target's relative direction and distance from audio-visual cues and encoding them as a compact descriptor will produce target-oriented fused representations that meaningfully improve policy learning.
What would settle it
A side-by-side evaluation on the same navigation episodes where SACF is replaced by plain feature concatenation and the number of steps to target or success rate shows no improvement.
Figures




read the original abstract
Audio-visual navigation tasks require agents to locate and navigate toward continuously vocalizing targets using only visual observations and acoustic cues. However, existing methods mainly rely on simple feature concatenation or late fusion, and lack an explicit discrete representation of the target's relative position, which limits learning efficiency and generalization. We propose Spatial-Aware Conditioned Fusion (SACF). SACF first discretizes the target's relative direction and distance from audio-visual cues, predicts their distributions, and encodes them as a compact descriptor for policy conditioning and state modeling. Then, SACF uses audio embeddings and spatial descriptors to generate channel-wise scaling and bias to modulate visual features via conditional linear transformation, producing target-oriented fused representations. SACF improves navigation efficiency with lower computational overhead and generalizes well to unheard target sounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spatial-Aware Conditioned Fusion (SACF) for audio-visual navigation. SACF discretizes the target's relative direction and distance from audio-visual cues, predicts distributions over these values, encodes them as a compact descriptor, and uses audio embeddings plus the descriptor to generate channel-wise scaling and bias parameters that modulate visual features via conditional linear transformation, producing target-oriented fused representations for policy learning. The authors claim this yields improved navigation efficiency, lower computational overhead, and better generalization to unheard target sounds compared to simple concatenation or late-fusion baselines.
Significance. If the empirical claims hold, the explicit spatial discretization and conditional modulation could provide a lightweight way to inject target-oriented spatial awareness into audio-visual policies, potentially improving sample efficiency and cross-sound generalization in embodied navigation tasks. The approach is conceptually clean and could be adopted in resource-constrained settings such as mobile robots or AR devices.
major comments (2)
- [§4] §4 (Experiments): No quantitative metrics, baseline tables, or ablation results are referenced in the provided description or abstract, so the central claims of efficiency gains and generalization cannot be assessed; the load-bearing assertion that the discretized spatial descriptor drives the improvements therefore lacks direct support.
- [§3.2] §3.2 (SACF module): The causal contribution of the discretization-plus-distribution-prediction step is not isolated; without an ablation that replaces the conditional linear transform with direct audio-visual concatenation while keeping all other training details fixed, it is impossible to rule out that gains arise from the backbone or training schedule rather than the spatial conditioning.
minor comments (2)
- [§3.2] Notation for the conditional linear transformation (scale and bias generation) should be formalized with an explicit equation to avoid ambiguity in the channel-wise modulation step.
- [Figures] Figure captions should explicitly label all visual elements (arrows, color codes, input/output tensors) so that the fusion pipeline can be followed without reference to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We have revised the manuscript to improve clarity on experimental results and to include the requested ablation, as detailed below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): No quantitative metrics, baseline tables, or ablation results are referenced in the provided description or abstract, so the central claims of efficiency gains and generalization cannot be assessed; the load-bearing assertion that the discretized spatial descriptor drives the improvements therefore lacks direct support.
Authors: We agree that the abstract and introductory description did not sufficiently reference the quantitative results. The full manuscript contains Section 4 with baseline comparison tables (success rate, SPL, navigation efficiency) and ablation tables demonstrating gains from the spatial descriptor. In the revision we have added explicit metric references to the abstract (e.g., improved efficiency and generalization numbers) and cross-references to the tables throughout the text, making the empirical support for the discretized descriptor explicit. revision: yes
-
Referee: [§3.2] §3.2 (SACF module): The causal contribution of the discretization-plus-distribution-prediction step is not isolated; without an ablation that replaces the conditional linear transform with direct audio-visual concatenation while keeping all other training details fixed, it is impossible to rule out that gains arise from the backbone or training schedule rather than the spatial conditioning.
Authors: We acknowledge the value of this specific control experiment. The original manuscript contained ablations on the spatial descriptor and fusion components, but not the exact replacement of conditional linear transformation by direct concatenation. We have now run the requested ablation (direct concatenation while retaining discretization and all other training details) and the results show a clear performance drop, confirming the contribution of the conditioned modulation. These new results have been added to the ablation study in Section 4. revision: yes
Circularity Check
No circularity in SACF architectural proposal
full rationale
The paper introduces Spatial-Aware Conditioned Fusion as a new module that discretizes relative direction/distance, predicts distributions, encodes a descriptor, and applies conditional linear transformation to modulate visual features. No equations, derivations, or self-citations appear in the provided text. The central steps are architectural choices presented as design decisions rather than reductions of outputs to inputs by construction. Claims rest on empirical navigation results rather than any load-bearing self-referential premise or fitted parameter renamed as prediction. This is a standard non-circular proposal of a fusion technique.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spatially Discretized Localization Descriptor (SDLD) ... discretizes the target’s relative spatial position into direction and distance, predicts its distribution, and encodes it into a compact descriptor
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ACVF ... generates FiLM-style channel modulation parameters ... ˜F_v_t = (1 + γ) ⊙ F_v_t + β
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Soundspaces: Audio-visual navigation in 3d environments,
C. Chen, U. Jain, C. Schissler, S. V . A. Gari, Z. Al-Halah, V . K. Ithapu, P. Robinson, and K. Grauman, “Soundspaces: Audio-visual navigation in 3d environments,” inEuropean conference on computer vision, 2020, pp. 17–36
work page 2020
-
[2]
Visuale- choes: Spatial image representation learning through echolocation,
R. Gao, C. Chen, Z. Al-Halah, C. Schissler, and K. Grauman, “Visuale- choes: Spatial image representation learning through echolocation,” in European Conference on Computer Vision, 2020, pp. 658–676
work page 2020
-
[3]
Semantic audio-visual naviga- tion,
C. Chen, Z. Al-Halah, and K. Grauman, “Semantic audio-visual naviga- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 516–15 525
work page 2021
-
[4]
Dynamic multi-target fusion for efficient audio-visual navigation,
Y . Yu, H. Zhang, and M. Zhu, “Dynamic multi-target fusion for efficient audio-visual navigation,”arXiv preprint arXiv:2509.21377, 2025
-
[5]
Advancing audio- visual navigation through multi-agent collaboration in 3d environments,
H. Zhang, Y . Yu, L. Wang, F. Sun, and W. Zheng, “Advancing audio- visual navigation through multi-agent collaboration in 3d environments,” inInternational Conference on Neural Information Processing, 2025, pp. 502–516
work page 2025
-
[6]
Audio-guided dynamic modality fusion with stereo-aware attention for audio-visual navigation,
J. Li, Y . Yu, L. Wang, F. Sun, and W. Zheng, “Audio-guided dynamic modality fusion with stereo-aware attention for audio-visual navigation,” inInternational Conference on Neural Information Processing, 2025, pp. 346–359
work page 2025
-
[7]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[8]
Dope: Dual object perception-enhancement network for vision-and-language navigation,
Y . Yu and D. Yang, “Dope: Dual object perception-enhancement network for vision-and-language navigation,” inProceedings of the 2025 Inter- national Conference on Multimedia Retrieval, 2025, pp. 1739–1748
work page 2025
-
[9]
Pay self-attention to audio- visual navigation,
Y . Yu, L. Cao, F. Sun, X. Liu, and L. Wang, “Pay self-attention to audio- visual navigation,” in33rd British Machine Vision Conference 2022, BMVC 2022, London, UK, November 21-24, 2022, 2022, p. 46
work page 2022
-
[10]
Dgfnet: End-to-end audio-visual source separation based on dynamic gating fusion,
Y . Yu and S. Sun, “Dgfnet: End-to-end audio-visual source separation based on dynamic gating fusion,” inProceedings of the 2025 Interna- tional Conference on Multimedia Retrieval, 2025, pp. 1730–1738
work page 2025
-
[11]
Learning to set waypoints for audio-visual navigation,
C. Chen, S. Majumder, Z. Al-Halah, R. Gao, S. K. Ramakrishnan, and K. Grauman, “Learning to set waypoints for audio-visual navigation,” inEmbodied Multimodal Learning Workshop at ICLR 2021, 2021
work page 2021
-
[12]
Echo-enhanced embodied visual navigation,
Y . Yu, L. Cao, F. Sun, C. Yang, H. Lai, and W. Huang, “Echo-enhanced embodied visual navigation,”Neural Computation, vol. 35, no. 5, pp. 958–976, 2023
work page 2023
-
[13]
Sound adversarial audio-visual navigation,
Y . Yu, W. Huang, F. Sun, C. Chen, Y . Wang, and X. Liu, “Sound adversarial audio-visual navigation,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[14]
Measuring acoustics with collaborative multiple agents,
Y . Yu, C. Chen, L. Cao, F. Yang, and F. Sun, “Measuring acoustics with collaborative multiple agents,” inProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, 2023, pp. 335– 343
work page 2023
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[16]
Weavenet: End- to-end audiovisual sentiment analysis,
Y . Yu, Z. Jia, F. Shi, M. Zhu, W. Wang, and X. Li, “Weavenet: End- to-end audiovisual sentiment analysis,” inInternational Conference on Cognitive Systems and Signal Processing, 2021, pp. 3–16
work page 2021
-
[17]
H. Zhang, Y . Yu, L. Wang, F. Sun, and W. Zheng, “Iterative residual cross-attention mechanism: An integrated approach for audio-visual navigation tasks,”arXiv preprint arXiv:2509.25652, 2025
-
[18]
Modulating early visual processing by language,
H. De Vries, F. Strub, J. Mary, H. Larochelle, O. Pietquin, and A. C. Courville, “Modulating early visual processing by language,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[19]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[20]
Embodied navigation with auxiliary task of action description prediction,
H. Kondoh and A. Kanezaki, “Embodied navigation with auxiliary task of action description prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7025–7036
work page 2025
-
[21]
Avlen: Audio-visual- language embodied navigation in 3d environments,
S. Paul, A. Roy-Chowdhury, and A. Cherian, “Avlen: Audio-visual- language embodied navigation in 3d environments,”Advances in Neural Information Processing Systems, vol. 35, pp. 6236–6249, 2022
work page 2022
-
[22]
H. Du, L. Li, Z. Huang, and X. Yu, “Object-goal visual navigation via effective exploration of relations among historical navigation states,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2563–2573
work page 2023
-
[23]
Omnidirectional infor- mation gathering for knowledge transfer-based audio-visual navigation,
J. Chen, W. Wang, S. Liu, H. Li, and Y . Yang, “Omnidirectional infor- mation gathering for knowledge transfer-based audio-visual navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 993–11 003
work page 2023
-
[24]
Matterport3d: Learning from rgb-d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niebner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” in2017 International Conference on 3D Vision (3DV), 2017, pp. 667–676
work page 2017
-
[25]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.