Recognition: no theorem link
Analyzing Reverse Address Translation Overheads in Multi-GPU Scale-Up Pods
Pith reviewed 2026-05-13 20:34 UTC · model grok-4.3
The pith
Cold TLB misses in reverse address translation slow small collectives by up to 1.4 times in multi-GPU scale-up systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
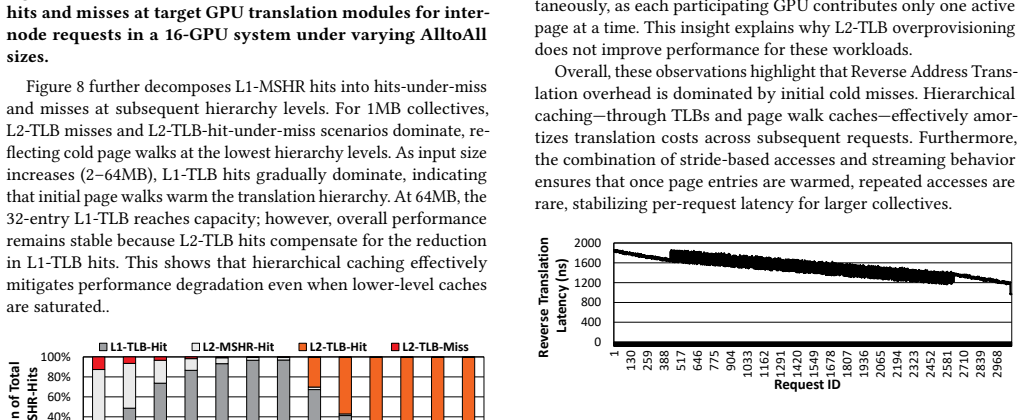
Reverse address translation at the destination side of scale-up links is performed by Link MMUs and Link TLBs; cold misses in these TLBs account for the bulk of added latency on small all-to-all collectives and produce up to 1.4x slowdown, while larger transfers see diminishing returns from bigger TLBs once the working set is cached.
What carries the argument
Link TLB, the destination-side cache that holds translations from Network Physical Addresses to System Physical Addresses and whose miss penalty dominates small-collective latency.
If this is right
- Small, latency-critical collectives experience the largest slowdown from reverse translation.
- Once the TLB working set fits in the cache, further increases in TLB size yield only marginal returns.
- Fused pre-translation kernels that overlap address translation with computation can hide most of the overhead.
- Software-guided TLB prefetching can proactively load likely entries before the network request arrives.
Where Pith is reading between the lines
- Inference workloads that rely on many small collectives would see the largest benefit from the proposed prefetch and pre-translation techniques.
- Designers of future scale-up fabrics may need to expose explicit translation control or larger shared TLBs to software.
- The same reverse-translation bottleneck is likely to appear in any direct-access interconnect that uses separate network and system address spaces.
Load-bearing premise
The extended ASTRA-sim plus Omnet++ model correctly reproduces the timing and behavior of real Link MMUs and Link TLBs.
What would settle it
Hardware counter measurements of Link TLB miss rates and end-to-end latency for small all-to-all transfers on an actual multi-GPU system connected by NVLink or UALink.
Figures








read the original abstract
Distributed ML workloads rely heavily on collective communication across multi-GPU, multi-node systems. Emerging scale-up fabrics, such as NVLink and UALink, enable direct memory access across nodes but introduce a critical destination-side translation step: translating Network Physical Addresses (NPAs) to System Physical Addresses (SPAs), which we term Reverse Translation (Reverse Address Translation). Despite its importance, the performance impact of Reverse Address Translation remains poorly understood. In this work, we present the first systematic study of Reverse Address Translation in large-scale GPU clusters. Using an extended ASTRA-sim framework with Omnet++ as the network backend, we model Link MMUs and Link TLBs and evaluate their effect on All-to-All collective communication across varying input sizes and GPU counts. Our analysis shows that cold TLB misses dominate latency for small, latency-sensitive collectives, causing up to 1.4x performance degradation, while larger collectives benefit from warmed caches and experience diminishing returns from over sized TLBs. Based on these observations, we propose two avenues for optimization: fused pre-translation kernels that overlap Reverse Address Translation with computation and software-guided TLB prefetching to proactively populate likely-needed entries. These techniques aim to hide translation latency, particularly for small collectives, improving throughput and scalability for inference workloads. Our study establishes a foundation for designing efficient destination-side translation mechanisms in large-scale multi-GPU systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic simulation study of reverse address translation (NPA-to-SPA) overheads in multi-GPU scale-up pods. Using an extended ASTRA-sim framework with Omnet++ as the network backend, it models Link MMUs and Link TLBs and evaluates their impact on All-to-All collectives across input sizes and GPU counts. The central findings are that cold TLB misses dominate latency for small, latency-sensitive collectives (up to 1.4x degradation) while larger collectives benefit from warmed caches with diminishing returns from oversized TLBs; the authors propose fused pre-translation kernels and software-guided TLB prefetching to hide translation latency.
Significance. If the simulation model is shown to be accurate, the work would be significant as the first quantitative characterization of destination-side translation costs in emerging scale-up fabrics such as NVLink and UALink. It identifies a concrete performance bottleneck for latency-sensitive collectives and outlines actionable optimization directions, providing a useful foundation for hardware and runtime designers. The simulation-based approach allows exploration of parameter spaces not yet available in silicon, but the lack of hardware grounding currently limits the strength of the quantitative claims.
major comments (2)
- [Methodology and Evaluation sections] The Link TLB/MMU latency model (described in the methodology section) is not calibrated or validated against silicon measurements from real NVLink or UALink systems. Because the reported 1.4x degradation for small collectives and the diminishing-returns conclusion for larger collectives rest directly on the modeled miss penalties and cache-warming behavior, the absence of such validation makes the performance numbers sensitive to unverified parameter choices rather than observed system properties.
- [Abstract and Conclusion] The proposed optimizations (fused pre-translation kernels and software-guided TLB prefetching) are introduced in the abstract and conclusion but receive no quantitative evaluation within the simulation framework. Without results showing their impact on the reported TLB-miss overheads, it is unclear whether these techniques would meaningfully mitigate the identified bottlenecks.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and describe the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Methodology and Evaluation sections] The Link TLB/MMU latency model (described in the methodology section) is not calibrated or validated against silicon measurements from real NVLink or UALink systems. Because the reported 1.4x degradation for small collectives and the diminishing-returns conclusion for larger collectives rest directly on the modeled miss penalties and cache-warming behavior, the absence of such validation makes the performance numbers sensitive to unverified parameter choices rather than observed system properties.
Authors: We agree that the model is not calibrated against silicon measurements from deployed NVLink or UALink systems, as these fabrics are still emerging and detailed public measurements of Link MMU/TLB behavior are not yet available. Our latency and size parameters are based on architectural specifications and analogous structures reported in the literature. To address the concern, we will add a sensitivity analysis subsection that varies the TLB miss penalty and TLB capacity over plausible ranges and shows that the central conclusions (cold-miss dominance for small collectives and diminishing returns for large collectives) remain qualitatively stable. We will also expand the methodology with explicit justification and citations for each parameter choice. revision: yes
-
Referee: [Abstract and Conclusion] The proposed optimizations (fused pre-translation kernels and software-guided TLB prefetching) are introduced in the abstract and conclusion but receive no quantitative evaluation within the simulation framework. Without results showing their impact on the reported TLB-miss overheads, it is unclear whether these techniques would meaningfully mitigate the identified bottlenecks.
Authors: We acknowledge that the two optimizations are introduced without quantitative evaluation in the current study. In the revised version we will modify the abstract and conclusion to state clearly that these are proposed directions motivated by the observed bottlenecks, not evaluated techniques. We will add a short Future Work subsection that outlines how the optimizations could be modeled in extensions of the framework, while removing any implication of measured benefit in this manuscript. revision: yes
Circularity Check
No circularity: results are direct simulation outputs from an extended framework, with no equations, fitted predictions, or self-referential derivations
full rationale
The paper presents a simulation study using an extended ASTRA-sim + Omnet++ model to measure TLB miss effects on collectives. No mathematical derivation chain exists; performance numbers (e.g., 1.4x degradation) are reported as direct outputs of the simulator runs across input sizes and GPU counts. The modeling assumptions are stated explicitly but do not reduce to self-definition or self-citation; the central claims rest on the simulation results themselves rather than any fitted parameter renamed as prediction or ansatz smuggled via prior work. This is a standard empirical modeling paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The extended ASTRA-sim with Omnet++ accurately captures Link MMU and TLB behavior in NVLink/UALink fabrics.
Reference graph
Works this paper leans on
-
[1]
2023.Concise: The New Way to Read News. https://www.concise.app
work page 2023
-
[2]
Introducing Microsoft 365 Copilot: Your Copilot for Work
2023. Introducing Microsoft 365 Copilot: Your Copilot for Work. https: //blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot- your-copilot-for-work/. Accessed: 2023-08-03
work page 2023
-
[3]
https://github.com/microsoft/msccl-tools Accessed: Jul
2025.GitHub - microsoft/msccl-tools: Synthesizer for optimal collective communi- cation algorithms. https://github.com/microsoft/msccl-tools Accessed: Jul. 09, 2025
work page 2025
-
[4]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Man- junath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: A system f...
-
[5]
Inc. Advanced Micro Devices. 2023. RCCL. https : / / github . com / ROCmSoftwarePlatform/rccl
work page 2023
-
[6]
Advanced Micro Devices, Inc. 2025. AMD Instinct MI350X GPU Product Brief. https://www.amd.com/content/dam/amd/en/documents/instinct-tech-docs/ product-briefs/amd-instinct-mi350x-gpu-brochure.pdf. Accessed: 2025-08-16
work page 2025
-
[7]
Palwisha Akhtar, Erhan Tezcan, Fareed Mohammad Qararyah, and Didem Unat
-
[8]
InInternational Symposium on Benchmarking, Measuring and Optimization
ComScribe: identifying intra-node GPU communication. InInternational Symposium on Benchmarking, Measuring and Optimization. Springer, 157–174
- [9]
-
[10]
Rajesh Arsid. 2025. Ultra Ethernet and UALink: Next-Generation Interconnects for AI Infrastructure.IJSAT-International Journal on Science and Technology16, 2 (2025)
work page 2025
-
[11]
Rogers, Evan Schneider, Jean-Luc Vay, and P
Scott Atchley, Christopher Zimmer, John Lange, David Bernholdt, Veronica Melesse Vergara, Thomas Beck, Michael Brim, Reuben Budiardja, Sunita Chan- drasekaran, Markus Eisenbach, Thomas Evans, Matthew Ezell, Nicholas Fron- tiere, Antigoni Georgiadou, Joe Glenski, Philipp Grete, Steven Hamilton, John Holmen, Axel Huebl, Daniel Jacobson, Wayne Joubert, Kim M...
-
[12]
Thomas W. Barr, Alan L. Cox, and Scott Rixner. 2011. SpecTLB: A Mechanism for Speculative Address Translation.SIGARCH Comput. Archit. News(2011)
work page 2011
- [13]
-
[14]
Abishek Bhattacharjee. 2017. Advanced concepts on address translation.Com- puter architecture—A quantitative approach (6th ed.), John L. Hennessy and David A. Patterson (Eds.). Morgan Kaufmann, Cambridge, MA, USA, Appendix L(2017), 1–69
work page 2017
-
[15]
Abhishek Bhattacharjee. 2017. Translation-Triggered Prefetching.SIGPLAN Not.(2017)
work page 2017
-
[16]
Abhishek Bhattacharjee, Daniel Lustig, and Margaret Martonosi. 2011. Shared last-level TLBs for chip multiprocessors. In2011 IEEE 17th International Sympo- sium on High Performance Computer Architecture
work page 2011
-
[17]
Abhishek Bhattacharjee and Margaret Martonosi. 2010. Inter-Core Cooperative TLB for Chip Multiprocessors. InProceedings of the Fifteenth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
work page 2010
- [18]
- [19]
-
[20]
Dave Brown and Kent Lusted. 2025. UALink 200G 1.0 Specification Overview: Data Link Layer (DL) and Physical Layer (PL). https://www.ieee802.org/3/ad_ hoc/E4AI/public/25_0624/lusted_e4ai_01_250624.pdf. Accessed: 2025-08-05
work page 2025
-
[21]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page 2020
-
[22]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Ka- plan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litw...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[23]
Jehoshua Bruck, Ching-Tien Ho, Shlomo Kipnis, and Derrick Weathersby. 1994. Efficient algorithms for all-to-all communications in multi-port message-passing systems. InProceedings of the sixth annual ACM symposium on Parallel algo- rithms and architectures. 298–309
work page 1994
-
[24]
Chang Chen, Xiuhong Li, Qianchao Zhu, Jiangfei Duan, Peng Sun, Xingcheng Zhang, and Chao Yang. 2024. Centauri: Enabling Efficient Scheduling for Communication-Computation Overlap in Large Model Training via Communi- cation Partitioning. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating ...
-
[25]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Se- bastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prab- hakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James...
work page 2023
-
[26]
Massed Compute. 2025.How does the latency of NVIDIA NVLink compare to other high-speed interconnects like Ethernet?Massed Compute. https: //massedcompute.com/faq- answers/?question=How+does+the+latency+ of+NVIDIA+NVLink+compare+to+other+high-speed+interconnects+like+ Ethernet%3F&utm_source=chatgpt.com
work page 2025
-
[27]
NVIDIA Corporation. 2022. The NVLink-Network Switch: NVIDIA’s Switch Chip for High Communication-Bandwidth Superpods. InProceedings of the 34th IEEE Hot Chips Symposium (HotChips 34). Stanford, CA, USA. https://hc34. hotchips.org/assets/program/conference/day2/Network%20and%20Switches/ NVSwitch%20HotChips%202022%20r5.pdf
work page 2022
-
[28]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft Collective Communication Language. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2023). Association for Computing Machinery, Ne...
-
[29]
Guilherme Cox and Abhishek Bhattacharjee. 2017. Efficient Address Translation for Architectures with Multiple Page Sizes. InProceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
work page 2017
-
[30]
Daniele De Sensi, Lorenzo Pichetti, Flavio Vella, Tiziano De Matteis, Zebin Ren, Luigi Fusco, Matteo Turisini, Daniele Cesarini, Kurt Lust, Animesh Trivedi, Duncan Roweth, Filippo Spiga, Salvatore Di Girolamo, and Torsten Hoefler
-
[31]
Exploring GPU-to-GPU Communication: Insights into Supercomputer In- terconnects. InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis(Atlanta, GA, USA)(SC ’24). IEEE Press, Article 33, 15 pages. doi:10.1109/SC41406.2024.00039
-
[32]
Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V
Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, Fatima, Ta, and Beckmann and Andrew Y. Ng. 2012. Large scale distributed deep networks. InProceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1(Lake Tahoe, ...
work page 2012
-
[33]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Under- standing.CoRRabs/1810.04805 (2018). arXiv:1810.04805 http://arxiv.org/abs/ 1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [34]
-
[35]
Oak Ridge Leadership Computing Facility. 2022. Frontier User Guide - System Overview. https://docs.olcf.ornl.gov/systems/frontier_user_guide.html#id2
work page 2022
-
[36]
Amel Fatima, Sihang Liu, Korakit Seemakhupt, Rachata Ausavarungnirun, and Samira Khan. 2023. vPIM: Efficient virtual address translation for scalable processing-in-memory architectures. In2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 1–6
work page 2023
-
[37]
Amel Fatima, Yang Yang, Yifan Sun, Rachata Ausavarungnirun, and Adwait Jog. 2025. NetCrafter: Tailoring Network Traffic for Non-Uniform Bandwidth Multi-GPU Systems. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 1064–1078. doi:10.1145/3695053.3731040
-
[38]
Denis Foley and John Danskin. 2017. Ultra-Performance Pascal GPU and NVLink Interconnect.IEEE Micro37, 2 (2017), 7–17. doi:10.1109/MM.2017.37
-
[39]
Nitin A Gawande, Jeff A Daily, Charles Siegel, Nathan R Tallent, and Abhinav Vishnu. 2020. Scaling deep learning workloads: Nvidia dgx-1/pascal and intel knights landing.Future Generation Computer Systems108 (2020), 1162–1172
work page 2020
-
[40]
Amir Gholami, Ariful Azad, Peter Jin, Kurt Keutzer, and Aydin Buluc. 2018. Integrated Model, Batch, and Domain Parallelism in Training Neural Networks. InProceedings of the 30th on Symposium on Parallelism in Algorithms and Archi- tectures(Vienna, Austria)(SPAA ’18). Association for Computing Machinery, New York, NY, USA, 77–86. doi:10.1145/3210377.3210394
- [41]
-
[42]
Raja Gond, Nipun Kwatra, and Ramachandran Ramjee. 2025. TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference. arXiv preprint arXiv:2505.11329(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He
-
[44]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.ArXiv abs/1706.02677 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Cliff Grossner. 2025. Open Compute Project Foundation and UALink Consor- tium Announce a New Collaboration. https://www.opencompute.org/blog/ open-compute-project-foundation-and-ualinktm-consortium-announce-a- new-collaboration. Accessed: 2025-08-05
work page 2025
-
[46]
Mert Hidayetoglu, Simon Garcia De Gonzalo, Elliott Slaughter, Yu Li, Christo- pher Zimmer, Tekin Bicer, Bin Ren, William Gropp, Wen-Mei Hwu, and Alex Aiken. 2024. CommBench: Micro-Benchmarking Hierarchical Networks with Multi-GPU, Multi-NIC Nodes. InProceedings of the 38th ACM International Conference on Supercomputing (ICS ’24). Association for Computing...
-
[47]
Jinbin Hu, Houqiang Shen, Xuchong Liu, and Jin Wang. 2024. RDMA transports in datacenter networks: survey.IEEE Network38, 6 (2024), 380–387
work page 2024
-
[48]
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Yanping Huang, Yonglong Cheng, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, and Zhifeng Chen. 2018. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism.CoRRabs/1811.06965 (2018). arXiv:1811.06965 http://arxiv.org/abs/1811.06965
work page Pith review arXiv 2018
-
[49]
Christian Hundt and Miguel Martinez. 2021.Machine Learning Frameworks Interoperability, Part 2: Data Loading and Data Transfer Bottlenecks. https: //developer.nvidia.com/blog/machine-learning-frameworks-interoperability- part-2-data-loading-and-data-transfer-bottlenecks/ NVIDIA Developer Blog
work page 2021
-
[50]
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al . 2023. Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems5 (2023), 269–287
work page 2023
-
[51]
Intel. 2023. oneCCL. https://github.com/oneapi-src/oneCCL. Accessed: 2025-08-06
work page 2023
-
[52]
Zhihao Jia, Sina Lin, Charles R. Qi, and Alex Aiken. 2018. Explor- ing Hidden Dimensions in Parallelizing Convolutional Neural Networks. arXiv:1802.04924 [cs.LG] https://arxiv.org/abs/1802.04924
- [53]
-
[54]
G.B. Kandiraju and A. Sivasubramaniam. 2002. Going the distance for TLB prefetching: An application-driven study. InProceedings 29th Annual Interna- tional Symposium on Computer Architecture. 195–206. doi:10.1109/ISCA.2002. 1003578
-
[55]
Vasileios Karakostas, Jayneel Gandhi, Furkan Ayar, Adrián Cristal, Mark D. Hill, Kathryn S. McKinley, Mario Nemirovsky, Michael M. Swift, and Osman Ünsal
-
[56]
InPro- ceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA)
Redundant Memory Mappings for Fast Access to Large Memories. InPro- ceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA)
-
[57]
2022.NVIDIA NVLink4 NVSwitch at Hot Chips 34
Patrick Kennedy. 2022.NVIDIA NVLink4 NVSwitch at Hot Chips 34. https:// www.servethehome.com/nvidia-nvlink4-nvswitch-at-hot-chips-34/ Accessed: 2025-08-05
work page 2022
-
[58]
2024.This Is the NVIDIA DGX GB200 NVL72
Patrick Kennedy. 2024.This Is the NVIDIA DGX GB200 NVL72. https://www. servethehome.com/this-is-the-nvidia-dgx-gb200-nvl72/ Accessed: 2025-08-05
work page 2024
-
[59]
Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. A Survey of Rec- ommendation Systems: Recommendation Models, Techniques, and Application Fields.Electronics11, 1 (2022). doi:10.3390/electronics11010141
-
[60]
Xinhao Kong, Jingrong Chen, Wei Bai, Yechen Xu, Mahmoud Elhaddad, Shachar Raindel, Jitendra Padhye, Alvin R Lebeck, and Danyang Zhuo. 2023. Understand- ing {RDMA} microarchitecture resources for performance isolation. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 31–48
work page 2023
- [61]
-
[62]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. 2017. ImageNet classification with deep convolutional neural networks.Commun. ACM60, 6 (may 2017), 84–90. doi:10.1145/3065386
-
[63]
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R. Tallent, and Kevin J. Barker. 2020. Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect.IEEE Transactions on Parallel and Distributed Systems31, 1 (2020), 94–110. doi:10.1109/TPDS.2019.2928289
-
[64]
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Xu Liu, Nathan Tallent, and Kevin Barker. 2018. Tartan: Evaluating Modern GPU Interconnect via a Multi-GPU Benchmark Suite. In2018 IEEE International Symposium on Workload Charac- terization (IISWC). 191–202. doi:10.1109/IISWC.2018.8573483
-
[65]
Bingyao Li, Jieming Yin, Anup Holey, Youtao Zhang, Jun Yang, and Xulong Tang
-
[66]
In2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA)
Trans-FW: Short Circuiting Page Table Walk in Multi-GPU Systems via Remote Forwarding. In2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 456–470. doi:10.1109/HPCA56546.2023.10071054
-
[67]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala
-
[68]
PyTorch distributed: experiences on accelerating data parallel training. Proc. VLDB Endow.13, 12 (Aug. 2020), 3005–3018. doi:10.14778/3415478.3415530
-
[69]
Heng Liao, Jiajin Tu, Jing Xia, Hu Liu, Xiping Zhou, Honghui Yuan, and Yuxing Hu. 2021. Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing : Industry Track Paper. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 789–801. doi:10. 1109/HPCA51647.2021.00071
-
[70]
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, and John D. Owens. 2025. Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms.IEEE Transactions on Parallel and Distributed Systems36, 2 (2025), 226–238. doi:10.1109/TPDS.2024.3507814
-
[71]
Tobias Mann. 2025. With Tomahawk Ultra, Broadcom asks who needs UALink when there’s Ethernet?The Register(15 July 2025). https://www.theregister. com/2025/07/15/broadcom_ethernet_scale_up/ Accessed: 2025-08-14
work page 2025
-
[72]
Anish Mathew, Arif Khan, Joe Chen, and Gautam Singampalli. 2025. UALink™ 200G 1.0 Specification Overview. https://ualinkconsortium.org/blog/ualink- 200g-1-0-specification-overview-802/
work page 2025
-
[73]
2024.Building Meta’s GenAI Infrastructure
Meta. 2024.Building Meta’s GenAI Infrastructure. https://engineering.fb.com/ 2024/03/12/data- center-engineering/building- metas- genai- infrastructure/ Accessed: 2024-03-19
work page 2024
-
[74]
Christopher Mitchell, Yifeng Geng, and Jinyang Li. 2013. Using one-sided RDMA reads to build a fast, CPU-efficient key-value store. InProceedings of the 2013 USENIX Conference on Annual Technical Conference(San Jose, CA)(USENIX ATC’13). USENIX Association, USA, 103–114
work page 2013
-
[75]
Harini Muthukrishnan, Daniel Lustig, Oreste Villa, Thomas Wenisch, and David Nellans. 2023. FinePack: Transparently Improving the Efficiency of Fine-Grained Transfers in Multi-GPU Systems. In2023 IEEE International Symposium on High- Performance Computer Architecture (HPCA). 516–529. doi:10.1109/HPCA56546. 2023.10070949
-
[76]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient large-scale language model training on GPU clusters using megatron- LM. InProceedings of the International Conference for High ...
-
[77]
NVIDIA. 2017. NVIDIA Collective Communications Library (NCCL). https: //developer.nvidia.com/nccl. Accessed: 2025-08-06
work page 2017
-
[78]
NVIDIA. 2017. NVIDIA NVLINK. http://www.nvidia.com/object/nvlink.html. Accessed: Aug. 1, 2025. Analyzing Reverse Address Translation Overheads in Multi-GPU Scale-Up Pods
work page 2017
-
[79]
Subhankar Pal, Jonathan Beaumont, Dong-Hyeon Park, Aporva Amarnath, Siying Feng, Chaitali Chakrabarti, Hun-Seok Kim, David Blaauw, Trevor Mudge, and Ronald Dreslinski. 2018. OuterSPACE: An Outer Product Based Sparse Matrix Multiplication Accelerator. In2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). 724–736. doi:10.1109...
-
[80]
M. Papadopoulou, X. Tong, A. Seznec, and A. Moshovos. 2015. Prediction-based superpage-friendly TLB designs. InIEEE 21st International Symposium on High Performance Computer Architecture (HPCA)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.