Recognition: 2 theorem links
· Lean TheoremMatClaw: An Autonomous Code-First LLM Agent for End-to-End Materials Exploration
Pith reviewed 2026-05-13 18:58 UTC · model grok-4.3
The pith
An LLM agent autonomously handles end-to-end materials simulations by writing and executing its own code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MatClaw writes and executes Python directly to orchestrate any installed domain library for multi-code workflows without predefined tool functions. A four-layer memory architecture sustains coherent execution across multi-day workflows, while retrieval-augmented generation over domain source code raises per-step accuracy to about 99 percent. End-to-end demonstrations reveal reliable code generation but struggles with tacit domain knowledge such as simulation timescales and equilibration protocols, which literature self-learning and expert constraints can bridge to enable guided autonomy.
What carries the argument
The code-first agent that dynamically writes and executes Python code, augmented by a four-layer memory architecture for long-term coherence and retrieval-augmented generation from domain source code for accurate API usage.
If this is right
- LLMs can reliably generate and interpret scientific code for materials tasks, reducing manual coding effort.
- Multi-day autonomous workflows become practical with proper memory management.
- Guided autonomy, combining agent execution with human domain knowledge, accelerates materials discovery.
- Rapid LLM improvements will outpace manual workflows in exploration speed.
Where Pith is reading between the lines
- Similar code-first agents could be applied to other fields like chemistry or biology that rely on scripted simulations.
- Open-sourcing the code allows testing on new problems to refine the approach.
- Future versions might minimize the need for expert constraints as models learn more from data.
- Integration with real-time experimental data could create closed-loop discovery systems.
Load-bearing premise
Tacit domain knowledge about simulation parameters and protocols can be reliably supplied by self-learning from literature and expert constraints without causing systematic errors.
What would settle it
Running the agent on a new materials problem with only minimal constraints and checking if it selects incorrect simulation timescales or sampling strategies that lead to wrong physical conclusions.
Figures


read the original abstract
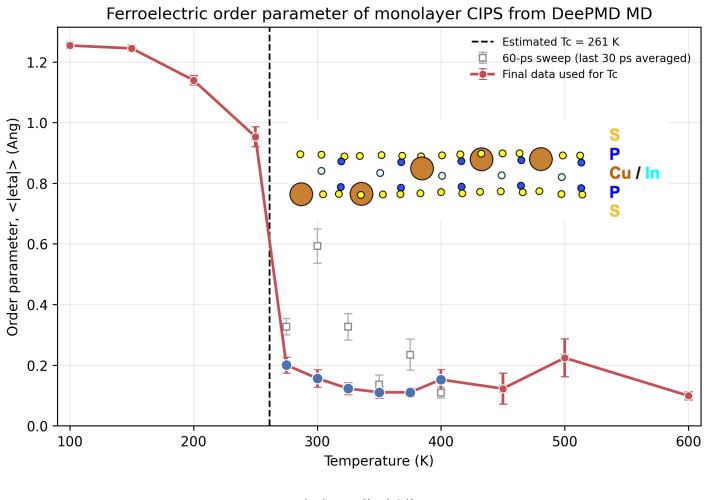
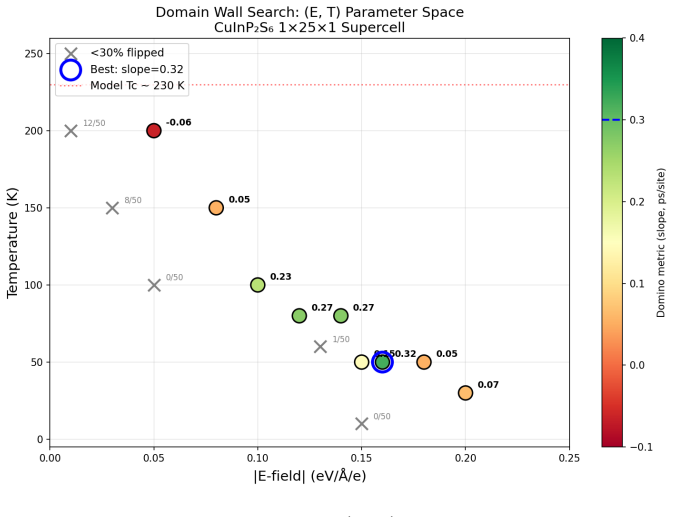
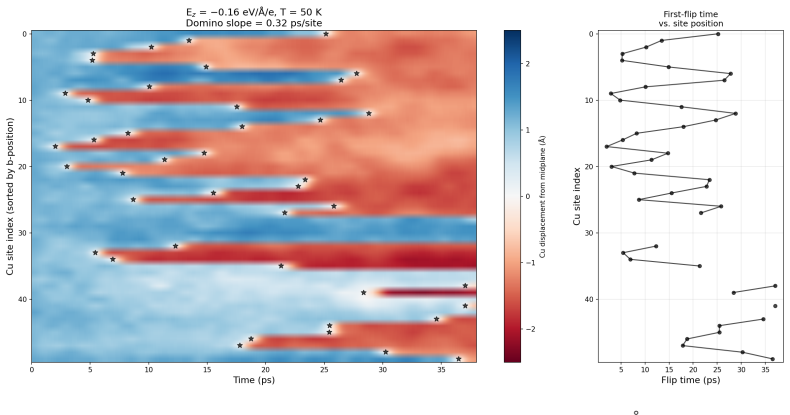
Existing LLM agents for computational materials science are constrained by pipeline-bounded architectures tied to specific simulation codes and by dependence on manually written tool functions that grow with task scope. We present MatClaw, a code-first agent that writes and executes Python directly, composing any installed domain library to orchestrate multi-code workflows on remote HPC clusters without predefined tool functions. To sustain coherent execution across multi-day workflows, MatClaw uses a four-layer memory architecture that prevents progressive context loss, and retrieval-augmented generation over domain source code that raises per-step API-call accuracy to ${\sim}$99 %. Three end-to-end demonstrations on ferroelectric CuInP2S6 (machine-learning force field training via active learning, Curie temperature prediction, and heuristic parameter-space search) reveal that the agent handles code generation reliably but struggles with tacit domain knowledge. The missing knowledge, such as appropriate simulation timescales, equilibration protocols, and sampling strategies, is the kind that researchers accumulate through experience but rarely formalize. Two lightweight interventions, literature self-learning and expert-specified constraints, bridge these gaps, defining a guided autonomy model in which the researcher provides high-level domain knowledge while the agent handles workflow execution. Our results demonstrate that the gap between guided and fully autonomous computational materials research is narrower than ever before: LLMs already handle code generation and scientific interpretation reliably, and the rapid improvement in their capabilities will accelerate materials discovery beyond what manual workflows can achieve. All code and benchmarks are open-source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MatClaw, a code-first LLM agent that directly writes and executes Python code to orchestrate multi-code materials workflows on HPC clusters without predefined tool functions. It introduces a four-layer memory architecture to maintain coherence over multi-day runs and retrieval-augmented generation over domain source code to achieve ~99% per-step API accuracy. Three end-to-end demonstrations on ferroelectric CuInP2S6 (active-learning ML force-field training, Curie-temperature prediction, and heuristic parameter-space search) show reliable code generation, but the agent requires two lightweight interventions—literature self-learning and expert-specified constraints—to address gaps in tacit domain knowledge such as simulation timescales and equilibration protocols. The work concludes that guided autonomy already narrows the gap to fully autonomous computational materials research and releases all code and benchmarks as open source.
Significance. If the guided-autonomy model can be shown to require only minimal, non-systematic expert input, the approach would meaningfully lower the barrier to complex multi-code materials simulations by shifting researcher effort from scripting to high-level guidance. The open-source release and concrete demonstrations on a real ferroelectric material provide a practical foundation for further development in the field.
major comments (3)
- [CuInP2S6 demonstrations] In the CuInP2S6 demonstrations section: the central claim that the two interventions are 'lightweight' and that guided autonomy already narrows the gap to full autonomy is load-bearing, yet the manuscript supplies no counts of constraints or retrieval steps injected per workflow, no failure rates before versus after intervention, and no comparison of total human oversight hours against a manual baseline. Without these data the reliability of the autonomy claim cannot be assessed.
- [four-layer memory architecture] Description of the four-layer memory architecture: the architecture is presented as essential for preventing progressive context loss across multi-day workflows, but no ablation study or quantitative comparison against simpler memory mechanisms (e.g., standard conversation history or vector-store retrieval alone) is provided to establish its necessity or performance gain.
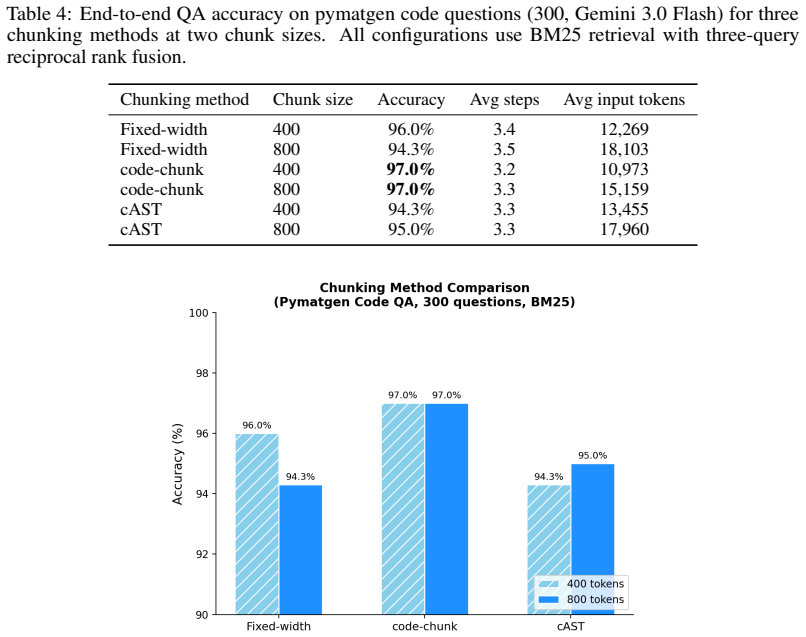
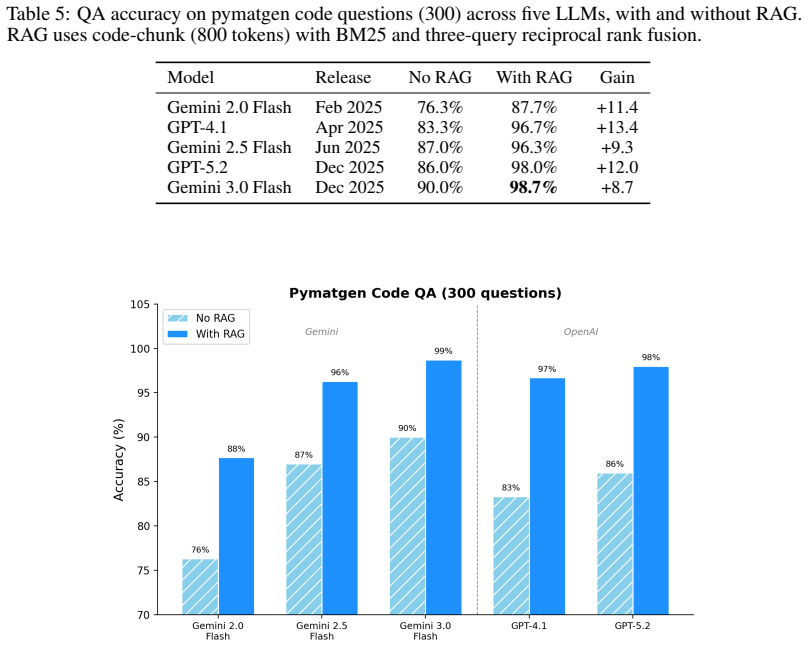
- [RAG over domain source code] RAG evaluation: the statement that retrieval-augmented generation over domain source code raises per-step API-call accuracy to ~99% is central to the code-first reliability claim, but the manuscript does not report the size or composition of the test set, the definition of 'API-call accuracy,' or the distribution of error types, preventing independent assessment of generalizability.
minor comments (2)
- [Abstract] The abstract contains several long, compound sentences that would benefit from splitting to improve readability.
- [four-layer memory architecture] Notation for the four-layer memory components is introduced without an accompanying diagram or explicit pseudocode, making the architecture harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help us strengthen the quantitative aspects of our claims on guided autonomy and the technical components of MatClaw. We address each major point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: In the CuInP2S6 demonstrations section: the central claim that the two interventions are 'lightweight' and that guided autonomy already narrows the gap to full autonomy is load-bearing, yet the manuscript supplies no counts of constraints or retrieval steps injected per workflow, no failure rates before versus after intervention, and no comparison of total human oversight hours against a manual baseline. Without these data the reliability of the autonomy claim cannot be assessed.
Authors: We agree that additional quantitative data would better support the claim that the interventions are lightweight. In the revised manuscript, we will add a dedicated subsection or table detailing the number of constraints and retrieval steps per demonstration workflow, pre- and post-intervention failure rates, and an estimate of human oversight hours relative to a manual baseline. This will provide a clearer assessment of the guided autonomy model's efficiency. revision: yes
-
Referee: Description of the four-layer memory architecture: the architecture is presented as essential for preventing progressive context loss across multi-day workflows, but no ablation study or quantitative comparison against simpler memory mechanisms (e.g., standard conversation history or vector-store retrieval alone) is provided to establish its necessity or performance gain.
Authors: We recognize the value of an ablation study to demonstrate the necessity of the four-layer memory architecture. We will include such an analysis in the revised paper, comparing the full architecture to simpler alternatives like standard conversation history and vector-store retrieval, using metrics such as context retention success rate and overall workflow completion over extended simulations. revision: yes
-
Referee: RAG evaluation: the statement that retrieval-augmented generation over domain source code raises per-step API-call accuracy to ~99% is central to the code-first reliability claim, but the manuscript does not report the size or composition of the test set, the definition of 'API-call accuracy,' or the distribution of error types, preventing independent assessment of generalizability.
Authors: We agree that more details are needed for the RAG evaluation to allow independent assessment. The revised manuscript will specify the test set size and composition, define 'API-call accuracy' explicitly (e.g., correct invocation including function name and parameters), and provide the distribution of error types encountered during testing. revision: yes
Circularity Check
No circularity: system description with empirical demos, no derivations or fitted predictions
full rationale
The manuscript describes an LLM agent architecture (four-layer memory, RAG over source code) and reports three end-to-end workflow demonstrations on CuInP2S6. No equations, no fitted parameters, no predictions of physical quantities, and no self-citation chains that justify uniqueness theorems or ansatzes appear in the text. The central claim rests on open-source code and observed success after lightweight interventions, which are externally verifiable rather than self-referential. This matches the default expectation of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate and execute correct scientific code for materials workflows when provided with retrieval-augmented access to domain source code.
invented entities (1)
-
four-layer memory architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearMatClaw uses a four-layer memory architecture... retrieval-augmented generation over domain source code that raises per-step API-call accuracy to ∼99 %
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTwo lightweight interventions, literature self-learning and expert-specified constraints, bridge these gaps
Forward citations
Cited by 1 Pith paper
-
OpenAaaS: An Open Agent-as-a-Service Framework for Distributed Materials-Informatics Research
OpenAaaS is a hierarchical agent-as-a-service system that enables secure multi-agent collaboration for materials informatics by moving code to data rather than data to code.
Reference graph
Works this paper leans on
-
[1]
Agent-based learning of materials datasets from the scientific literature
Ansari, Mehrad and Moosavi, Seyed Mohamad. Agent-based learning of materials datasets from the scientific literature. Digital Discovery, 3 0 (12): 0 2607--2617, 2024. doi:10.1039/D4DD00252K
-
[2]
Autonomous chemical research with large language models
Boiko, Daniil A., MacKnight, Robert, Kline, Ben, and Gomes, Gabe. Autonomous chemical research with large language models. Nature, 624 0 (7992): 0 570--578, 2023. doi:10.1038/s41586-023-06792-0
-
[3]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Bran, Andres M., Cox, Sam, Schilter, Oliver, Baldassari, Carlo, White, Andrew D., and Schwaller, Philippe. Augmenting large language models with chemistry tools. Nature Machine Intelligence, 6 0 (5): 0 525--535, 2024. doi:10.1038/s42256-024-00832-8
-
[4]
code-chunk: Tree-sitter based semantic code chunking, 2025
code-chunk contributors . code-chunk: Tree-sitter based semantic code chunking, 2025. https://github.com/nicobailon/code-chunk
work page 2025
-
[5]
and Clarke, Charles L A and Buettcher, Stefan , month = jul, year =
Cormack, Gordon V., Clarke, Charles L. A., and Buettcher, Stefan. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proc. SIGIR, pages 758--759, 2009. doi:10.1145/1571941.1572114
-
[6]
Atomate2: Modular workflows for materials science, 2025
Ganose, Alex, Sahasrabuddhe, Hrushikesh, et al. Atomate2: Modular workflows for materials science, 2025. URL https://chemrxiv.org/doi/full/10.26434/chemrxiv-2025-tcr5h. Digital Discovery, 2025, 4, 1944--1973
-
[7]
He, R. et al. Unconventional ferroelectric domain switching dynamics in CuInP _2 S _6 from first principles. Phys. Rev. B, 108: 0 024305, 2023. doi:10.1103/PhysRevB.108.024305
-
[8]
Context rot: How increasing input tokens impacts LLM performance, 2025
Hong, Kelly, Troynikov, Anton, and Huber, Jeff. Context rot: How increasing input tokens impacts LLM performance, 2025. URL https://www.trychroma.com/research/context-rot. Chroma Research Technical Report
work page 2025
-
[9]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Jimenez, Carlos E., Yang, John, Wettig, Alexander, Yao, Shunyu, Pei, Kexin, Press, Ofir, and Narasimhan, Karthik. SWE-bench : Can language models resolve real-world GitHub issues?, 2024. URL http://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
ACON : Optimizing context compression for long-horizon LLM agents, 2025
Kang, Minki, Chen, Wei-Ning, Han, Dongge, Inan, Huseyin A., Wutschitz, Lukas, Chen, Yanzhi, Sim, Robert, and Rajmohan, Saravan. ACON : Optimizing context compression for long-horizon LLM agents, 2025. URL https://arxiv.org/abs/2510.00615
-
[11]
Lindenbauer, Tobias, Slinko, Igor, Felder, Ludwig, Bogomolov, Egor, and Zharov, Yaroslav. The complexity trap: Simple observation masking is as efficient as LLM summarization for agent context management, 2025. URL http://arxiv.org/abs/2508.21433
-
[12]
VASPilot : MCP -facilitated multi-agent intelligence for autonomous VASP simulations
Liu, Jiaxuan, Zhu, Tiannian, Ye, Caiyuan, Fang, Zhong, Weng, Hongming, and Wu, Quansheng. VASPilot : MCP -facilitated multi-agent intelligence for autonomous VASP simulations. Chinese Physics B, 34 0 (11): 0 117106, 2025 a . doi:10.1088/1674-1056/ae0681
-
[13]
Available: https://doi.org/10.1162/tacl a 00449
Liu, Nelson F., Lin, Kevin, Hewitt, John, Paranjape, Ashwin, Bevilacqua, Michele, Petroni, Fabio, and Liang, Percy. Lost in the middle: How language models use long contexts. Transactions of the ACL, 12: 0 157--173, 2024. doi:10.1162/tacl\_a\_00638
work page internal anchor Pith review doi:10.1162/tacl 2024
- [14]
-
[15]
Intrinsic ferroelectric switching from first principles
Liu, Shi, Grinberg, Ilya, and Rappe, Andrew M. Intrinsic ferroelectric switching from first principles. Nature, 534 0 (7607): 0 360--363, 2016. doi:10.1038/nature18286
-
[16]
Ong, Shyue Ping, Richards, William Davidson, Jain, Anubhav, Hautier, Geoffroy, Kocher, Michael, Cholia, Shreyas, Gunter, Dan, Chevrier, Vincent L., Persson, Kristin A., and Ceder, Gerbrand. Python M aterials G enomics (pymatgen): A robust, open-source P ython library for materials analysis. Computational Materials Science, 68: 0 314--319, 2013. doi:10.101...
-
[17]
MemGPT: Towards LLMs as Operating Systems
Packer, Charles, Wooders, Sarah, Lin, Kevin, Fang, Vivian, Patil, Shishir G., Stoica, Ion, and Gonzalez, Joseph E. MemGPT : Towards LLM s as operating systems, 2024. URL http://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Nanoscale studies of ferroelectric domain walls as pinned elastic interfaces
Paruch, Patrycja and Guyonnet, Jill. Nanoscale studies of ferroelectric domain walls as pinned elastic interfaces. Comptes Rendus Physique, 14 0 (8): 0 667--684, 2013. doi:10.1016/j.crhy.2013.08.004
-
[19]
TaskWeaver: A code-first agent framework,
Qiao, Bo, Li, Liqun, Zhang, Xu, He, Shilin, Kang, Yu, Zhang, Chaoyun, Yang, Fangkai, Dong, Hang, Zhang, Jue, Wang, Lu, Ma, Minghua, Zhao, Pu, Qin, Si, Qin, Xiaoting, Du, Chao, Xu, Yong, Lin, Qingwei, Rajmohan, Saravan, and Zhang, Dongmei. TaskWeaver : A code-first agent framework, 2024. URL http://arxiv.org/abs/2311.17541
-
[20]
GPQA : A graduate-level Google -proof Q&A benchmark
Rein, David, Hou, Betty Li, Stickland, Asa Cooper, Petty, Jackson, Pang, Richard Yuanzhe, Dirani, Julien, Michael, Julian, and Bowman, Samuel R. GPQA : A graduate-level Google -proof Q&A benchmark. Proc. COLM, 2024
work page 2024
-
[21]
Jobflow: Computational workflows made simple
Rosen, Andrew S., Gallant, Max, George, Janine, Riebesell, Janosh, Sahasrabuddhe, Hrushikesh, Shen, Jimmy-Xuan, Wen, Mingjian, Evans, Matthew L., Petretto, Guido, Waroquiers, David, Rignanese, Gian-Marco, Persson, Kristin A., Jain, Anubhav, and Ganose, Alex M. Jobflow: Computational workflows made simple. Journal of Open Source Software, 9 0 (93): 0 5995,...
-
[22]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, Noah, Cassano, Federico, Berman, Edward, Gopinath, Ashwin, Narasimhan, Karthik, and Yao, Shunyu. Reflexion: Language agents with verbal reinforcement learning, 2023. URL http://arxiv.org/abs/2303.11366. NeurIPS 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Cognitive architectures for language agents, 2024
Sumers, Theodore R., Yao, Shunyu, Narasimhan, Karthik, and Griffiths, Thomas L. Cognitive architectures for language agents, 2024. URL http://arxiv.org/abs/2309.02427
-
[24]
Vriza, Aikaterini, Kornu, Uma, Koneru, Aditya, Chan, Henry, and Sankaranarayanan, Subramanian K. R. S. Multi-agentic AI framework for end-to-end atomistic simulations. Digital Discovery, 5 0 (1): 0 440--452, 2026. doi:10.1039/D5DD00435G
-
[25]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, Guanzhi, Xie, Yuqi, Jiang, Yunfan, Mandlekar, Ajay, Xiao, Chaowei, Zhu, Yuke, Fan, Linxi, and Anandkumar, Anima. Voyager: An open-ended embodied agent with large language models, 2023. URL http://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Wang, Han, Zhang, Linfeng, Han, Jiequn, and E, Weinan. DeePMD-kit : A deep learning package for many-body potential energy representation and molecular dynamics. Computer Physics Communications, 228: 0 178--184, 2018. doi:10.1016/j.cpc.2018.03.016
-
[27]
Executable code actions elicit better LLM agents,
Wang, Xingyao, Chen, Yangyi, Yuan, Lifan, Zhang, Yizhe, Li, Yunzhu, Peng, Hao, and Ji, Heng. Executable code actions elicit better LLM agents, 2024. URL http://arxiv.org/abs/2402.01030. ICML 2024
-
[28]
An agentic framework for autonomous materials computation, 2025
Xia, Zeyu, Ma, Jinzhe, Zheng, Congjie, Zhang, Shufei, Li, Yuqiang, Su, Hang, Hu, P., Zhang, Changshui, Gong, Xingao, Ouyang, Wanli, Bai, Lei, Zhou, Dongzhan, and Su, Mao. An agentic framework for autonomous materials computation, 2025. URL http://arxiv.org/abs/2512.19458. arXiv:2512.19458
-
[29]
Efficient streaming language models with attention sinks
Xiao, Guangxuan, Tian, Yuandong, Chen, Beidi, Han, Song, and Lewis, Mike. Efficient streaming language models with attention sinks. Proc. ICLR, 2024
work page 2024
-
[30]
ReAct : Synergizing reasoning and acting in language models
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik R., and Cao, Yuan. ReAct : Synergizing reasoning and acting in language models. In Proc. ICLR, 2023. URL https://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[31]
TopoMAS : Large language model driven topological materials multiagent system, 2025 a
Zhang, Baohua, Li, Xin, Xu, Huangchao, Jin, Zhong, Wu, Quansheng, and Li, Ce. TopoMAS : Large language model driven topological materials multiagent system, 2025 a . URL http://arxiv.org/abs/2507.04053. arXiv:2507.04053
-
[32]
Zhang, Y. et al. DP-GEN : A concurrent learning platform for the generation of reliable deep learning based potential energy models. Comput. Phys. Commun., 253: 0 107206, 2020
work page 2020
-
[33]
Zhang, Yilin, Zhao, Xinran, Wang, Zora Zhiruo, Yang, Chenyang, Wei, Jiayi, and Wu, Tongshuang. cAST : Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree, 2025 b . URL http://arxiv.org/abs/2506.15655
-
[34]
Zheng, Zhiling, Florit, Federico, Jin, Brooke, Wu, Haoyang, Li, Shih-Cheng, Nandiwale, Kakasaheb Y., Salazar, Chase A., Mustakis, Jason G., Green, William H., and Jensen, Klavs F. Integrating machine learning and large language models to advance exploration of electrochemical reactions. Angewandte Chemie International Edition, 64 0 (6): 0 e202418074, 2025...
-
[35]
El A gente: An autonomous agent for quantum chemistry
Zou, Yunheng, Cheng, Austin H., Aldossary, Abdulrahman, Bai, Jiaru, Leong, Shi Xuan, Campos-Gonzalez-Angulo, Jorge Arturo, Choi, Changhyeok, Ser, Cher Tian, Tom, Gary, Wang, Andrew, Zhang, Zijian, Yakavets, Ilya, Hao, Han, Crebolder, Chris, Bernales, Varinia, and Aspuru-Guzik, Al\' a n. El A gente: An autonomous agent for quantum chemistry. Matter, 8 0 (7...
-
[36]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.