Recognition: no theorem link
V2X-QA: A Comprehensive Reasoning Dataset and Benchmark for Multimodal Large Language Models in Autonomous Driving Across Ego, Infrastructure, and Cooperative Views
Pith reviewed 2026-05-13 20:35 UTC · model grok-4.3
The pith
A new benchmark shows viewpoint access changes how multimodal models reason about traffic scenes from vehicle, infrastructure, and cooperative perspectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
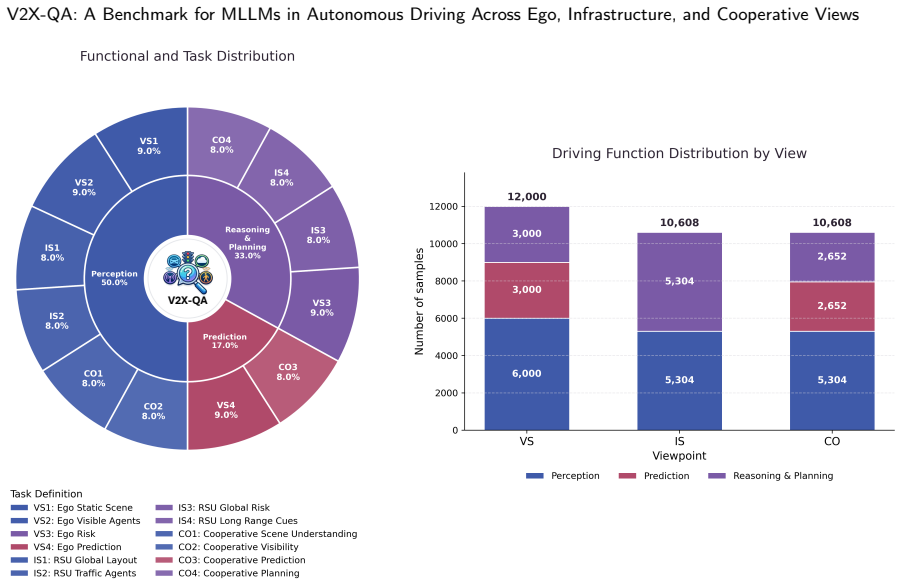
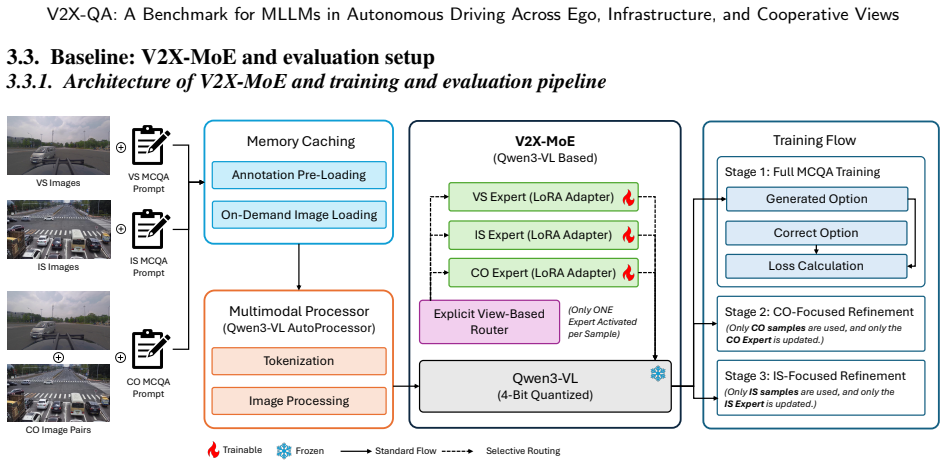
V2X-QA demonstrates that viewpoint accessibility substantially affects MLLM performance in autonomous driving, infrastructure-side reasoning supports meaningful macroscopic traffic understanding, and cooperative reasoning remains challenging because it requires cross-view alignment and evidence integration rather than simply additional visual input. The introduced V2X-MoE baseline with explicit view routing and viewpoint-specific LoRA experts achieves stronger results, indicating that viewpoint specialization improves multi-view reasoning.
What carries the argument
The view-decoupled evaluation protocol in V2X-QA that enables controlled comparisons of vehicle-only, infrastructure-only, and cooperative conditions inside a single MCQA framework.
If this is right
- Infrastructure views enable better macroscopic traffic understanding than vehicle views alone.
- Cooperative reasoning demands explicit cross-view alignment and evidence integration beyond adding more visual inputs.
- Models with explicit view routing and viewpoint-specific experts can achieve higher performance on multi-view tasks.
- The twelve-task taxonomy supports fine-grained diagnosis of model strengths across perception, prediction, and planning.
Where Pith is reading between the lines
- Connected autonomous driving systems may gain reliability by incorporating infrastructure data sources for broader scene context.
- New model architectures focused on cross-view fusion could be developed to overcome current cooperative reasoning limits.
- The benchmark can be extended to test physical intelligence in multi-agent scenarios that go beyond single-vehicle planning.
Load-bearing premise
Expert-verified MCQA annotations and the twelve-task taxonomy accurately and comprehensively capture real-world viewpoint-dependent capabilities without introducing annotation biases or coverage gaps.
What would settle it
Run the same ten models on a fresh collection of real-world driving scenes with independently collected ground-truth labels and check whether the reported performance gaps between vehicle, infrastructure, and cooperative conditions remain consistent.
Figures





read the original abstract
Multimodal large language models (MLLMs) have shown strong potential for autonomous driving, yet existing benchmarks remain largely ego-centric and therefore cannot systematically assess model performance in infrastructure-centric and cooperative driving conditions. In this work, we introduce V2X-QA, a real-world dataset and benchmark for evaluating MLLMs across vehicle-side, infrastructure-side, and cooperative viewpoints. V2X-QA is built around a view-decoupled evaluation protocol that enables controlled comparison under vehicle-only, infrastructure-only, and cooperative driving conditions within a unified multiple-choice question answering (MCQA) framework. The benchmark is organized into a twelve-task taxonomy spanning perception, prediction, and reasoning and planning, and is constructed through expert-verified MCQA annotation to enable fine-grained diagnosis of viewpoint-dependent capabilities. Benchmark results across ten representative state-of-the-art proprietary and open-source models show that viewpoint accessibility substantially affects performance, and infrastructure-side reasoning supports meaningful macroscopic traffic understanding. Results also indicate that cooperative reasoning remains challenging since it requires cross-view alignment and evidence integration rather than simply additional visual input. To address these challenges, we introduce V2X-MoE, a benchmark-aligned baseline with explicit view routing and viewpoint-specific LoRA experts. The strong performance of V2X-MoE further suggests that explicit viewpoint specialization is a promising direction for multi-view reasoning in autonomous driving. Overall, V2X-QA provides a foundation for studying multi-perspective reasoning, reliability, and cooperative physical intelligence in connected autonomous driving. The dataset and V2X-MoE resources are publicly available at: https://github.com/junwei0001/V2X-QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces V2X-QA, a real-world dataset and benchmark for evaluating MLLMs in autonomous driving across ego-vehicle, infrastructure, and cooperative viewpoints. It uses a view-decoupled MCQA protocol organized into a 12-task taxonomy spanning perception, prediction, and reasoning/planning, with expert-verified annotations. Benchmarking ten state-of-the-art proprietary and open-source models shows that viewpoint accessibility substantially affects performance, infrastructure views enable macroscopic traffic understanding, and cooperative reasoning is challenging due to the need for cross-view alignment rather than added visual input. The authors also propose V2X-MoE, a baseline with explicit view routing and viewpoint-specific LoRA experts, which outperforms standard models on the benchmark.
Significance. If the expert annotations are shown to be reliable and unbiased, V2X-QA would represent a meaningful advance by providing the first systematic benchmark for multi-view and cooperative reasoning in V2X settings. The empirical results on viewpoint effects and the V2X-MoE architecture offer concrete guidance for developing models suited to connected autonomous driving, while the public dataset release supports further research on reliability and physical intelligence.
major comments (2)
- [Section 3] Section 3 (Dataset Construction and Annotation): No inter-annotator agreement statistics or detailed verification protocol (e.g., how expert disagreements on infrastructure vs. ego questions were resolved) are reported. This is load-bearing for the central claim that viewpoint accessibility substantially affects performance, because unquantified annotation biases or coverage gaps in the 12-task taxonomy could produce the observed gaps without reflecting true model capabilities.
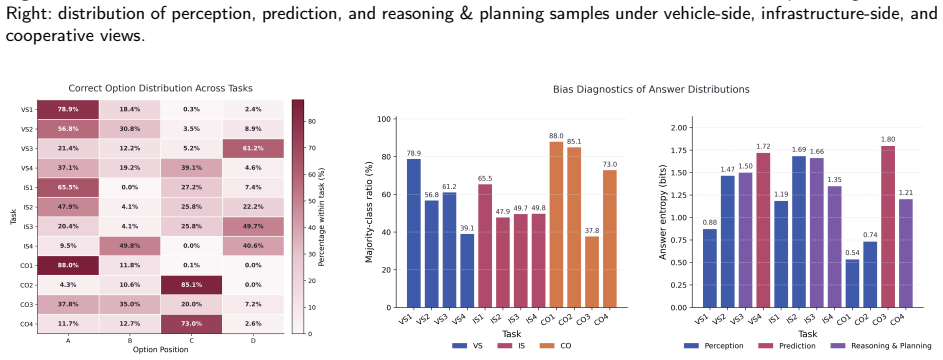
- [Section 4] Section 4 (Benchmark Results and Analysis): The conclusion that cooperative reasoning requires cross-view alignment and evidence integration (rather than simply additional visual input) rests on the assumption that task phrasing and answer distributions are balanced across views. Without an explicit check for systematic differences in question difficulty or option distributions by viewpoint, the performance gaps may partly reflect annotation artifacts.
minor comments (2)
- [Abstract] Abstract: The description of the twelve-task taxonomy would benefit from a one-sentence summary of the category distribution (e.g., how many tasks fall under perception vs. planning) to give readers immediate context.
- [Section 3.1] Figure 1 or Section 3.1: The view-decoupled evaluation protocol diagram should explicitly label the three conditions (vehicle-only, infrastructure-only, cooperative) to make the controlled comparison clearer.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The concerns regarding annotation reliability and potential distributional artifacts are well-taken and directly relevant to the strength of our central claims. We address each point below and will incorporate the requested additions and clarifications in the revised version.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Dataset Construction and Annotation): No inter-annotator agreement statistics or detailed verification protocol (e.g., how expert disagreements on infrastructure vs. ego questions were resolved) are reported. This is load-bearing for the central claim that viewpoint accessibility substantially affects performance, because unquantified annotation biases or coverage gaps in the 12-task taxonomy could produce the observed gaps without reflecting true model capabilities.
Authors: We acknowledge that quantitative inter-annotator agreement (IAA) statistics were omitted from the original submission. In the revised manuscript we will add a new paragraph in Section 3 reporting pairwise agreement rates and Fleiss' kappa computed over the expert annotations. The verification protocol consisted of independent review by two domain experts per item followed by a consensus discussion for any disagreements; viewpoint-specific questions (e.g., infrastructure-only vs. ego-only) were flagged and resolved by a third senior expert when necessary. We will also include a brief table summarizing disagreement rates broken down by task category and viewpoint to demonstrate that coverage gaps do not systematically favor any single view. revision: yes
-
Referee: [Section 4] Section 4 (Benchmark Results and Analysis): The conclusion that cooperative reasoning requires cross-view alignment and evidence integration (rather than simply additional visual input) rests on the assumption that task phrasing and answer distributions are balanced across views. Without an explicit check for systematic differences in question difficulty or option distributions by viewpoint, the performance gaps may partly reflect annotation artifacts.
Authors: We agree that an explicit balance audit is necessary to rule out annotation artifacts. In the revised Section 4 we will insert (i) summary statistics on question length, number of options, and lexical complexity stratified by viewpoint, and (ii) a control experiment reporting model performance under shuffled-answer and random-guessing baselines for each view. Our internal verification already shows no statistically significant differences in option entropy or question difficulty across the three views, but these numbers will now be reported transparently. This addition will directly support the claim that the observed cooperative-reasoning gap arises from the need for cross-view alignment rather than from unbalanced task phrasing. revision: yes
Circularity Check
No circularity: empirical dataset and benchmark evaluation
full rationale
The paper introduces V2X-QA as a new real-world dataset with expert-verified MCQA annotations organized into a twelve-task taxonomy spanning perception, prediction, and planning. It evaluates ten existing MLLMs under a view-decoupled protocol and proposes V2X-MoE as a baseline with view routing and LoRA experts. No equations, parameter fitting, or derivations are present. Claims about viewpoint effects and cooperative challenges rest directly on the empirical benchmark results rather than reducing to self-defined quantities, fitted inputs renamed as predictions, or load-bearing self-citations. The construction is self-contained against external model evaluations and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert verification produces unbiased and comprehensive MCQA annotations that reflect real driving capabilities
Forward citations
Cited by 1 Pith paper
-
MDrive: Benchmarking Closed-Loop Cooperative Driving for End-to-End Multi-agent Systems
MDrive benchmark shows multi-agent cooperative driving systems generally outperform single-agent ones in closed-loop settings but perception sharing does not always improve planning and negotiation can harm performanc...
Reference graph
Works this paper leans on
-
[1]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Bai, L., Cai, Z., Cao, M., Cao, W., Chen, C., et al., 2025a. Intern-s1: A scientific multimodal foundation model. arXiv preprint arXiv:2508.15763 doi:10.48550/arXiv.2508.15763. Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., et al., 2025b. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 doi:10.48550/arXiv. 2511.21631. Bai, S., et al., 2025c. Qw...
-
[2]
Monthly Weather Review 78, 1–3
Verification of forecasts expressed in terms of probability. Monthly Weather Review 78, 1–3. Chiu,H.k.,Hachiuma,R.,Wang,C.Y.,Smith,S.F.,Wang,Y.C.F.,Chen,M.H.,2025a. V2v-llm:Vehicle-to-vehiclecooperativeautonomousdriving with multi-modal large language models. arXiv preprint arXiv:2502.09980 . Chiu,H.k.,Hachiuma,R.,Wang,C.Y.,Wang,Y.C.F.,Chen,M.H.,Smith,S.F...
-
[3]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv:2507.06261. Cui,E.,Wang,W.,Li,Z.,Xie,J.,Zou,H.,Deng,H.,Luo,G.,Lu,L.,Zhu,X.,Dai,J.,2025. Drivemlm:aligningmulti-modallargelanguagemodels with behavioral planning states for autonomous driving. Visual Intelligence 3,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Junwei You et al.:Preprint submitted to ElsevierPage 22 of 24 V2X-QA: A Benchmark for MLLMs in Autonomous Driving Across Ego, Infrastructure, and Cooperative Views Gan,R.,Li,P.,Long,K.,An,B.,You,J.,Wu,K.,Ran,B.,2025. Planningsafetytrajectorieswithdual-phase,physics-informed,andtransportation knowledge-driven large language models. arXiv preprint arXiv:250...
-
[5]
NuRisk: A Visual Question Answering Dataset for Agent-Level Risk Assessment in Autonomous Driving
Nurisk: A visual question answering dataset for agent-level risk assessment in autonomous driving. arXiv preprint arXiv:2509.25944 . Google,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Google AI for Developers documentation
Gemini 3 Flash Preview.https://ai.google.dev/gemini-api/docs/models/gemini-3-flash-preview. Google AI for Developers documentation. Accessed: 2026-04-01. Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.,
work page 2026
-
[7]
Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262 . Kharlamova, A., Liu, J., Zhang, T., Yang, X., Alqasimi, H., Sun, Y., Xue, C.J.,
-
[8]
arXiv preprint arXiv:2511.18924
Llm-driven kernel evolution: Automating driver updates in linux. arXiv preprint arXiv:2511.18924 . Kim, J., Rohrbach, A., Darrell, T., Canny, J., Akata, Z.,
-
[9]
Textual explanations for self-driving vehicles, in: Proceedings of the European conference on computer vision (ECCV), pp. 563–578. Kim,Y.,Abdelrahman,A.S.,Abdel-Aty,M.,2025. Vru-accident:Avision-languagebenchmarkforvideoquestionansweringanddensecaptioning for accident scene understanding, in: Proceedings of the IEEE/CVF International Conference on Compute...
work page 2025
-
[10]
arXiv preprint arXiv:2511.11168
Cats-v2v: A real-world vehicle-to-vehicle cooperative perception dataset with complex adverse traffic scenarios. arXiv preprint arXiv:2511.11168 . Li, Y., Ma, D., An, Z., Wang, Z., Zhong, Y., Chen, S., Feng, C.,
-
[11]
Drama: Joint risk localization and captioning in driving, in: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 1043–1052. OpenAI, 2025a. GPT-5 mini Model.https://developers.openai.com/api/docs/models/gpt-5-mini. OpenAI API documentation; snapshot gpt-5-mini-2025-08-07. Accessed: 2026-04-01. OpenAI, 2025b. GPT-5.2 Model...
work page 2025
-
[12]
Nuplanqa: A large-scale dataset and benchmark for multi-view driving scene understanding in multi-modal large language models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8066–8076. Qian,T.,Chen,J.,Zhuo,L.,Jiao,Y.,Jiang,Y.G.,2024. Nuscenes-qa:Amulti-modalvisualquestionansweringbenchmarkforautonomousdriving scenario, in...
-
[13]
arXiv preprint arXiv:2602.00993
Hermes: A holistic end-to-end risk-aware multimodal embodied system with vision-language models for long-tail autonomous driving. arXiv preprint arXiv:2602.00993 . Tian, K., Mao, J., Zhang, Y., Jiang, J., Zhou, Y., Tu, Z.,
-
[14]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289 . Wang,Y.,Zheng,Y.,Fan,W.,Wang,T.,Chu,H.,Tian,D.,Gao,B.,Wang,J.,Chen,H.,2026. Scenepilot-bench:Alarge-scaledatasetandbenchmark for evaluation of vision-language models in autonomous driving. arXiv preprint arXiv:2601.19582 . Xiang, H., Zheng, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
IEEE Robotics and Automation Letters 9, 8186–8193
Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters 9, 8186–8193. You,J.,Jiang,Z.,Huang,Z.,Shi,H.,Gan,R.,Wu,K.,Cheng,X.,Li,X.,Ran,B.,2026. V2x-vlm:End-to-endv2xcooperativeautonomousdriving through large vision-language models. Transportation Research Part C: Emerging Technologies 183, 10545...
work page 2026
-
[16]
arXiv preprint arXiv:2506.21041
Seal: Vision-language model-based safe end-to-end cooperative autonomous driving with adaptive long-tail modeling. arXiv preprint arXiv:2506.21041 . Junwei You et al.:Preprint submitted to ElsevierPage 23 of 24 V2X-QA: A Benchmark for MLLMs in Autonomous Driving Across Ego, Infrastructure, and Cooperative Views Yu,G.,Li,H.,Wang,Y.,Chen,P.,Zhou,B.,2022a. A...
-
[17]
arXiv preprint arXiv:2511.20022
Waymoqa: A multi-view visual question answering dataset for safety-critical reasoning in autonomous driving. arXiv preprint arXiv:2511.20022 . Zeng, T., Wu, L., Shi, L., Zhou, D., Guo, F.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.