Recognition: no theorem link
ChatSVA: Bridging SVA Generation for Hardware Verification via Task-Specific LLMs
Pith reviewed 2026-05-13 18:59 UTC · model grok-4.3
The pith
ChatSVA shows multi-agent LLMs can generate SystemVerilog Assertions at 96 percent functional accuracy despite scarce data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
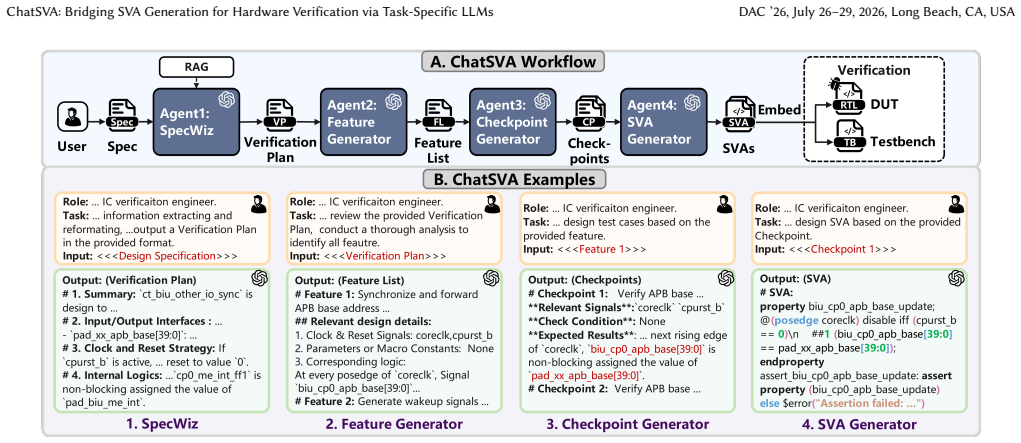
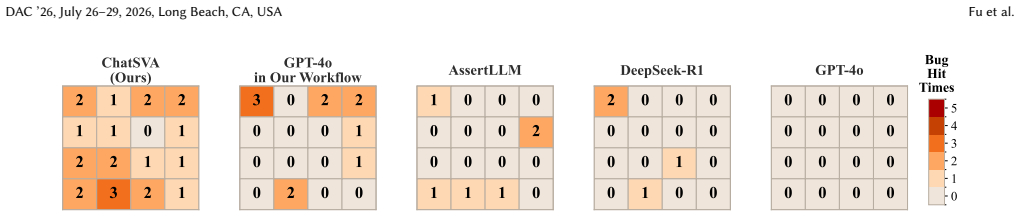
ChatSVA establishes that a multi-agent LLM architecture, supported by AgentBridge dataset generation, produces SVAs that pass syntax checks at 98.66 percent and functional checks at 96.12 percent across 24 RTL designs, while delivering 82.5 percent function coverage and 139.5 assertions per design, exceeding previous methods by 33 points in correctness and 11 times in coverage.
What carries the argument
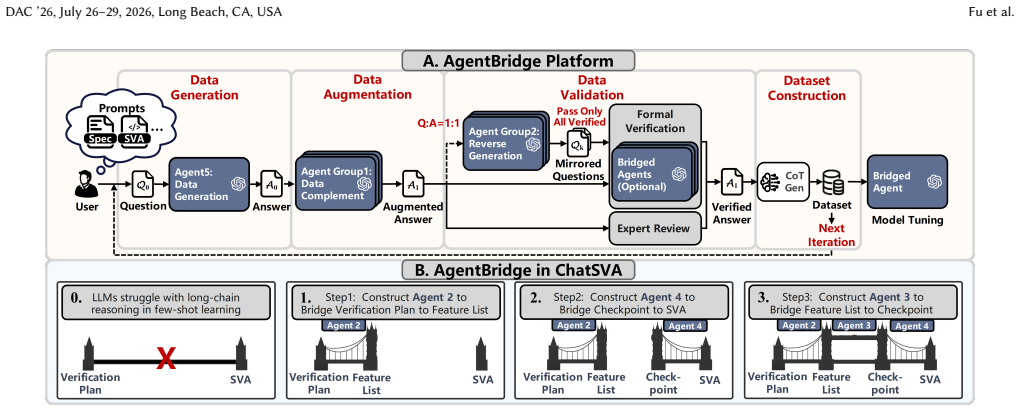
The AgentBridge multi-agent platform that systematically generates high-purity datasets to support few-shot SVA generation with task-specific LLMs.
If this is right
- Hardware verification teams can shift from manual SVA authoring to automated generation while maintaining high functional accuracy.
- The framework provides a template for solving other long-chain reasoning tasks in few-shot, domain-specific engineering settings.
- Verification effort, which consumes more than half of the IC development cycle, can be reduced through higher automation of property generation.
- The reported pass rates and coverage levels become new reference points for measuring progress in automated assertion generation.
Where Pith is reading between the lines
- Similar dataset purification steps could be applied to generate other verification artifacts such as test sequences or coverage points.
- The multi-agent structure may extend to additional hardware description languages beyond SystemVerilog if comparable high-purity data pipelines are built.
- If the approach scales to larger designs, function coverage could rise beyond the current 82.5 percent without additional manual intervention.
Load-bearing premise
The multi-agent framework with AgentBridge systematically produces high-purity datasets that overcome data scarcity and enable reliable few-shot SVA generation across diverse RTL designs.
What would settle it
Evaluating ChatSVA on a fresh collection of complex, previously unseen RTL designs and finding that the functional pass rate falls below 80 percent would show the reliability claim does not generalize.
Figures




read the original abstract
Functional verification consumes over 50% of the IC development lifecycle, where SystemVerilog Assertions (SVAs) are indispensable for formal property verification and enhanced simulation-based debugging. However, manual SVA authoring is labor-intensive and error-prone. While Large Language Models (LLMs) show promise, their direct deployment is hindered by low functional accuracy and a severe scarcity of domain-specific data. To address these challenges, we introduce ChatSVA, an end-to-end SVA generation system built upon a multi-agent framework. At its core, the AgentBridge platform enables this multi-agent approach by systematically generating high-purity datasets, overcoming the data scarcity inherent to few-shot scenarios. Evaluated on 24 RTL designs, ChatSVA achieves 98.66% syntax and 96.12% functional pass rates, generating 139.5 SVAs per design with 82.50% function coverage. This represents a 33.3 percentage point improvement in functional correctness and an over 11x enhancement in function coverage compared to the previous state-of-the-art (SOTA). ChatSVA not only sets a new SOTA in automated SVA generation but also establishes a robust framework for solving long-chain reasoning problems in few-shot, domain-specific scenarios. An online service has been publicly released at https://www.nctieda.com/CHATDV.html.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChatSVA, an end-to-end multi-agent LLM framework for automated SystemVerilog Assertion (SVA) generation in hardware verification. Its core contribution is the AgentBridge platform, which generates high-purity few-shot datasets to address data scarcity. Evaluated on 24 RTL designs, ChatSVA reports 98.66% syntax pass rate, 96.12% functional pass rate, an average of 139.5 SVAs per design, and 82.50% function coverage, claiming a 33.3 percentage point gain in functional correctness and over 11x improvement in coverage relative to prior SOTA.
Significance. If the reported metrics are supported by transparent, reproducible evaluation protocols, the work would meaningfully advance automated formal property generation in IC design, where SVA authoring remains a dominant cost. The multi-agent approach to high-purity dataset creation for long-chain, domain-specific reasoning could generalize to other data-scarce technical domains.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: the headline metrics (98.66% syntax pass rate, 96.12% functional pass rate, 82.50% function coverage, 33.3 pp and 11x gains) are stated without describing the verification oracle (formal tool, simulation harness, or manual review), the exact SOTA baseline implementation, design-selection criteria for the 24 RTL modules, or any statistical controls such as error bars or significance tests. These omissions render the central empirical claim unverifiable from the provided text.
- [AgentBridge platform description] AgentBridge platform description: the claim that the multi-agent pipeline produces high-purity datasets rests on internal self-consistency among agents sharing the same base LLM, with no mention of an independent external checker (formal verifier, cross-design oracle, or human audit). This setup risks correlated hallucinations being scored as functional passes on the same designs, undermining the assertion that the framework reliably overcomes data scarcity.
minor comments (2)
- [Abstract] The online service URL is given but no usage instructions, input/output formats, or reproducibility notes appear in the text.
- [Evaluation section] Notation for pass-rate and coverage calculations is introduced without an explicit equation or pseudocode definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of transparency in our evaluation. We have revised the manuscript to provide detailed descriptions of the verification process, baseline implementation, design selection, and additional validation steps for the AgentBridge platform. These changes strengthen the verifiability of our claims without altering the core methodology.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the headline metrics (98.66% syntax pass rate, 96.12% functional pass rate, 82.50% function coverage, 33.3 pp and 11x gains) are stated without describing the verification oracle (formal tool, simulation harness, or manual review), the exact SOTA baseline implementation, design-selection criteria for the 24 RTL modules, or any statistical controls such as error bars or significance tests. These omissions render the central empirical claim unverifiable from the provided text.
Authors: We agree that the original text lacked sufficient detail on the evaluation protocol. In the revised manuscript, we have expanded the Evaluation section (and updated the abstract accordingly) to explicitly describe: the verification oracle as the JasperGold formal verification tool used to check functional correctness of each generated SVA against the RTL design; the SOTA baseline as a direct reproduction of the prior work's prompting strategy using the same underlying LLM for fair comparison; the design-selection criteria as 24 diverse open-source RTL modules drawn from OpenCores and academic benchmarks, stratified by complexity and module type; and statistical controls including standard deviations across three independent generation runs per design plus paired t-test results confirming significance of the reported gains. These additions make the empirical claims fully verifiable. revision: yes
-
Referee: [AgentBridge platform description] AgentBridge platform description: the claim that the multi-agent pipeline produces high-purity datasets rests on internal self-consistency among agents sharing the same base LLM, with no mention of an independent external checker (formal verifier, cross-design oracle, or human audit). This setup risks correlated hallucinations being scored as functional passes on the same designs, undermining the assertion that the framework reliably overcomes data scarcity.
Authors: We acknowledge the concern regarding potential correlated hallucinations in a shared-LLM multi-agent system. The functional pass metric is computed by an independent external formal verifier (JasperGold) that checks each generated SVA against the target RTL design, providing an objective oracle separate from the generation agents. To further strengthen this, the revised manuscript now includes: (1) explicit description of this external verification step in the AgentBridge pipeline, (2) results from a human audit performed on a random 20% subset of generated SVAs across designs, and (3) cross-design validation where SVAs generated for one module are tested for portability on held-out designs. These additions address the risk while preserving the automated nature of the framework. revision: partial
Circularity Check
No circularity: empirical results on external RTL designs
full rationale
The paper presents performance metrics (syntax/functional pass rates, coverage) from direct evaluation of ChatSVA on 24 RTL designs, with gains reported relative to a cited prior SOTA. No equations, fitted parameters, self-definitional constructs, or derivations appear in the abstract or described content. The multi-agent AgentBridge component is described as a data-generation pipeline whose output is then measured on independent designs; no reduction of the reported metrics to the generation process by construction is shown. This is a standard empirical claim and receives score 0.
Axiom & Free-Parameter Ledger
invented entities (1)
-
AgentBridge platform
no independent evidence
Forward citations
Cited by 2 Pith papers
-
From Language to Logic: Bridging LLMs & Formal Representations for RTL Assertion Generation
ProofLoop achieves 93.7% syntax correctness and 82.0% functional correctness for SVA generation from natural language by combining retrieval, EDA tools, and up to three rounds of JasperGold formal feedback.
-
Automated SVA Generation with LLMs
SVA Generator improves semantic correctness of LLM-generated SystemVerilog Assertions by 22.7 percentage points on average for deeper properties using AST-grounded constraint injection and depth-stratified formal equi...
Reference graph
Works this paper leans on
-
[1]
Fnu Aditi and Michael S. Hsiao. 2022. Hybrid Rule-based and Machine Learning System for Assertion Generation from Natural Language Specifications. In2022 IEEE 31st Asian Test Symposium (ATS). 126–131. doi:10.1109/ATS56056.2022.00034
-
[2]
Fnu Aditi and Michael S. Hsiao. 2023. Validatable Generation of System Verilog Assertions from Natural Language Specifications. In2023 Fifth International Conference on Transdisciplinary AI (TransAI). 102–109. doi:10.1109/TransAI60598. 2023.00026
-
[3]
Yunsheng Bai, Ghaith Bany Hamad, Syed Suhaib, and Haoxing Ren. 2025. Asser- tionForge: Enhancing Formal Verification Assertion Generation with Structured Representation of Specifications and RTL. In2025 IEEE International Conference on LLM-Aided Design (ICLAD). Stanford, CA, USA, 85–92. doi:10.1109/ICLAD65226. 2025.00009
-
[4]
Jason Blocklove, Siddharth Garg, Ramesh Karri, and Hammond Pearce. 2023. Chip-chat: Challenges and opportunities in conversational hardware design. In 2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD). IEEE, 1–6. doi:10.1109/MLCAD58807.2023.10299874
-
[5]
Wen Chen, Sandip Ray, Jayanta Bhadra, Magdy Abadir, and Li-C Wang. 2017. Challenges and Trends in Modern SoC Design Verification.IEEE Design & Test 34, 5 (2017), 7–22. doi:10.1109/MDAT.2017.2735383
-
[6]
Alessandro Danese, Nicolò Dalla Riva, and Graziano Pravadelli. 2017. A-TEAM: Automatic template-based assertion miner. In2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC). 1–6. doi:10.1145/3061639.3062206
-
[7]
Babak Falsafi. 2023. What’s Missing in Agile Hardware Design? Verification!J. Comput. Sci. Technol.38, 4 (2023), 735–736. doi:10.1007/s11390-023-0005-3
-
[8]
Frederiksen, John Aromando, and Michael S
Steven J. Frederiksen, John Aromando, and Michael S. Hsiao. 2020. Automated Assertion Generation from Natural Language Specifications. In2020 IEEE Inter- national Test Conference (ITC). 1–5. doi:10.1109/ITC44778.2020.9325264
-
[9]
Samuele Germiniani and Graziano Pravadelli. 2022. HARM: A Hint-Based Asser- tion Miner.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems41, 11 (2022), 4277–4288. doi:10.1109/TCAD.2022.3197525
-
[10]
Christopher B. Harris and Ian G. Harris. 2016. GLAsT: Learning formal grammars to translate natural language specifications into hardware assertions. In2016 Design, Automation & Test in Europe Conference & Exhibition (DATE). 966–971
work page 2016
-
[11]
Harry Foster. 2019. The Weather Report: 2018 Study On IC/ASIC Verifica- tion Trends. https://semiengineering.com/the-weather-report-2018-study-on- ic-asic-verification-trends/. Accessed: 2025-07-14
work page 2019
-
[12]
Harry Foster. 2021. The 2020 Wilson Research Group Functional Verification Study. https://blogs.sw.siemens.com/verificationhorizons/2021/01/06/part-8-the- 2020-wilson-research-group-functional-verification-study/. Accessed: 2025-07- 14
work page 2021
-
[13]
Harry Foster. 2023. The 2022 Wilson Research Group Functional Verification Study. https://blogs.sw.siemens.com/verificationhorizons/2023/01/23/epilogue- the-2022-wilson-research-group-functional-verification-study/. Accessed: 2025- 07-14
work page 2023
-
[14]
Osman Hasan and Sofiene Tahar. 2015. Formal verification methods. InEncyclo- pedia of Information Science and Technology, Third Edition. IGI global, 7162–7170
work page 2015
-
[15]
Yuchen Hu, Junhao Ye, Ke Xu, Jialin Sun, Shiyue Zhang, Xinyao Jiao, Dingrong Pan, Jie Zhou, Ning Wang, Weiwei Shan, Xinwei Fang, Xi Wang, Nan Guan, and Zhe Jiang. 2025. Uvllm: An automated universal rtl verification framework using llms. InProceedings of the 62nd ACM/IEEE Design Automation Conference (DAC ’25). arXiv:2411.16238 https://arxiv.org/abs/2411....
-
[16]
Rahul Kande, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Shailja Thakur, Ramesh Karri, and Jeyavijayan Rajendran. 2024. (Security) Assertions by Large Language Models.IEEE Transactions on Information Forensics and Security 19 (2024), 4374–4389. doi:10.1109/TIFS.2024.3372809
-
[17]
Oliver Keszocze and Ian G. Harris. 2019. Chatbot-based assertion generation from natural language specifications. In2019 Forum for Specification and Design Languages (FDL). 1–6. doi:10.1109/FDL.2019.8876925
- [18]
-
[19]
Sakari Lahti, Panu Sjövall, Jarno Vanne, and Timo D. Hämäläinen. 2019. Are We There Yet? A Study on the State of High-Level Synthesis.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems38, 5 (2019), 898–911. doi:10.1109/TCAD.2018.2834439
-
[20]
Mingjie Liu, Minwoo Kang, Ghaith Bany Hamad, Syed Suhaib, and Haoxing Ren. 2024. Domain-Adapted LLMs for VLSI Design and Verification: A Case Study on Formal Verification. In2024 IEEE 42nd VLSI Test Symposium (VTS). 1–4. doi:10.1109/VTS60656.2024.10538589
-
[21]
Tianyang Liu, Qi Tian, Jianmin Ye, LikTung Fu, Shengchu Su, Junyan Li, Gwok- Waa Wan, Layton Zhang, Sam-Zaak Wong, Xi Wang, et al. 2024. ChatChisel: Enabling Agile Hardware Design with Large Language Models. In2024 2nd International Symposium of Electronics Design Automation (ISEDA). IEEE, 710–716. doi:10.1109/ISEDA62518.2024.10618053
-
[22]
Bhabesh Mali, Karthik Maddala, Vatsal Gupta, Sweeya Reddy, Chandan Karfa, and Ramesh Karri. 2024. ChIRAAG: ChatGPT Informed Rapid and Automated Assertion Generation. In2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). 680–683. doi:10.1109/ISVLSI61997.2024.00130
- [23]
-
[24]
Ganapathy Parthasarathy, Saurav Nanda, Parivesh Choudhary, and Pawan Patil
-
[25]
In2021 Second Document Intelligence Workshop at KDD
Spectosva: Circuit specification document to systemverilog assertion translation. In2021 Second Document Intelligence Workshop at KDD
-
[26]
Valentin Radu, Diana Dranga, Catalin Dumitrescu, Alina Iuliana Tabirca, and Maria Cristina Stefan. 2024. Generative AI Assertions in UVM-Based System Ver- ilog Functional Verification.Systems12, 10 (2024). doi:10.3390/systems12100390
-
[27]
Mohammad Shahidzadeh, Behnam Ghavami, Steven Wilton, and Lesley Shannon
-
[28]
https://api.semanticscholar.org/CorpusID:274235019
Automatic High-quality Verilog Assertion Generation through Subtask- Focused Fine-Tuned LLMs and Iterative Prompting.ArXivabs/2411.15442 (2024). https://api.semanticscholar.org/CorpusID:274235019
-
[29]
Tell, Yanqing Zhang, William J
Yakun Sophia Shao, Jason Clemons, Rangharajan Venkatesan, Brian Zimmer, Matthew Fojtik, Nan Jiang, Ben Keller, Alicia Klinefelter, Nathaniel Pinckney, Priyanka Raina, Stephen G. Tell, Yanqing Zhang, William J. Dally, Joel Emer, C. Thomas Gray, Brucek Khailany, and Stephen W. Keckler. 2019. Simba: Scal- ing Deep-Learning Inference with Multi-Chip-Module-Ba...
-
[30]
Chuyue Sun, Christopher Hahn, and Caroline Trippel. 2023. Towards Improving Verification Productivity with Circuit-Aware Translation of Natural Language to SystemVerilog Assertions. InFirst International Workshop on Deep Learning-aided Verification. https://openreview.net/forum?id=FKH8qCuM44
work page 2023
-
[31]
Synopsys. 2015. Delivering Functional Verification Engagements.Synopsys White Paper(2015). https://www.synopsys.com/content/dam/synopsys/services/ whitepapers/delivering-functional-verification-engagements.pdf
work page 2015
-
[32]
Shobha Vasudevan, David Sheridan, Sanjay Patel, David Tcheng, Bill Tuohy, and Daniel Johnson. 2010. GoldMine: Automatic assertion generation using data mining and static analysis. In2010 Design, Automation & Test in Europe Conference & Exhibition (DATE 2010). 626–629. doi:10.1109/DATE.2010.5457129
-
[33]
Gwok-Waa Wan, SamZaak Wong, Shengchu Su, Chenxu Niu, Ning Wang, Xin- lai Wan, Qixiang Chen, Mengnv Xing, Jingyi Zhang, Jianmin Ye, Yubo Wang, Rongchang Song, Tao Ni, Qiang Xu, Nan Guan, Zhe Jiang, Xi Wang, Yong Chen, and Jun Yang. 2026. FIXME: Towards End-to-End Benchmarking of LLM-Aided Design Verification.Proceedings of the AAAI Conference on Artificial...
-
[34]
Xi Wang, Gwok-Waa Wan, Sam-Zaak Wong, Layton Zhang, Tianyang Liu, Qi Tian, and Jianmin Ye. 2024. ChatCPU: An Agile CPU Design and Verification Platform with LLM. InProceedings of the 61st ACM/IEEE Design Automation Conference(San Francisco, CA, USA)(DAC ’24). Association for Computing Machinery, New York, NY, USA, Article 212, 6 pages. doi:10.1145/3649329.3658493
-
[35]
Hasini Witharana, Yangdi Lyu, Subodha Charles, and Prabhat Mishra. 2022. A Survey on Assertion-based Hardware Verification. 54, 11s, Article 225 (2022), 33 pages. doi:10.1145/3510578
-
[36]
2025.MEIC: Re-thinking RTL Debug Automation using LLMs
Ke Xu, Jialin Sun, Yuchen Hu, Xinwei Fang, Weiwei Shan, Xi Wang, and Zhe Jiang. 2025.MEIC: Re-thinking RTL Debug Automation using LLMs. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3676536. 3676801
-
[37]
Qiang Xu, Leon Stok, Rolf Drechsler, Xi Wang, Grace Li Zhang, and Igor L. Markov
-
[38]
In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD)
Revolution or Hype? Seeking the Limits of Large Models in Hardware Design. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). 1–9. doi:10.1109/ICCAD66269.2025.11240750
-
[39]
Zhiyuan Yan, Wenji Fang, Mengming Li, Min Li, Shang Liu, Zhiyao Xie, and Hongce Zhang. 2025. AssertLLM: Generating Hardware Verification Asser- tions from Design Specifications via Multi-LLMs. InProceedings of the 30th Asia and South Pacific Design Automation Conference(Tokyo, Japan)(ASP- DAC ’25). Association for Computing Machinery, New York, NY, USA, 6...
-
[40]
Bingkun Yao, Ning Wang, Jie Zhou, Xi Wang, Hong Gao, Zhe Jiang, and Nan Guan. 2025. Location is Key: Leveraging LLM for Functional Bug Localization in Verilog Design. InProceedings of the 62nd Annual ACM/IEEE Design Automation Conference(San Francisco, California, United States)(DAC ’25). IEEE Press, Article 394, 7 pages. doi:10.1109/DAC63849.2025.11133280
-
[41]
Junchen Zhao and Ian G. Harris. 2019. Automatic Assertion Generation from Natural Language Specifications Using Subtree Analysis. In2019 De- sign, Automation & Test in Europe Conference & Exhibition (DATE). 598–601. doi:10.23919/DATE.2019.8714857
-
[42]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Association for Computational Linguistics. http://arxiv.or...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.