Recognition: no theorem link
Toward an Artificial General Teacher: Procedural Geometry Data Generation and Visual Grounding with Vision-Language Models
Pith reviewed 2026-05-13 20:32 UTC · model grok-4.3
The pith
Procedural generation of 200000 synthetic diagrams lets fine-tuned vision-language models segment referred geometric elements at 49 percent IoU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A fully automated procedural data engine generates more than 200000 geometry diagrams complete with pixel-perfect segmentation masks and linguistically diverse referring expressions. Domain-specific fine-tuning of a vision-language model such as Florence-2 on this corpus produces 49 percent IoU and 85 percent Buffered IoU on geometric diagrams, compared with less than 1 percent IoU in the zero-shot regime. The authors also define Buffered IoU to better capture localization quality on thin geometric structures and present the pipeline as the foundation for Artificial General Teachers that deliver visually grounded explanations.
What carries the argument
Fully automated procedural data engine that synthesizes geometry diagrams, pixel-perfect masks, and referring expressions to train referring image segmentation models on abstract, textureless schematics.
If this is right
- Zero-shot vision-language models produce near-zero accuracy on geometric diagrams because of the shift from textured photographs to line drawings.
- Fine-tuning on the procedurally generated corpus raises both standard IoU and the geometry-aware Buffered IoU by large margins.
- Buffered IoU penalizes thin-line errors less harshly than standard IoU and therefore ranks models more consistently with human judgment of diagram quality.
- The same engine can supply unlimited labeled examples for any geometric construction without further annotation cost.
Where Pith is reading between the lines
- The same procedural approach could generate training data for other abstract visual domains such as physics free-body diagrams or electrical schematics.
- Pairing the segmentation model with a language model would allow tutoring systems to generate both verbal steps and visual pointers inside the same diagram.
- Measuring performance on diagrams drawn by students rather than by the procedural engine would reveal how robust the learned grounding remains under natural drawing variation.
Load-bearing premise
The synthetic diagrams and referring expressions generated by the procedural engine are sufficiently representative of real geometry education materials and natural language queries to enable effective transfer.
What would settle it
Running the fine-tuned model on a collection of scanned real textbook geometry diagrams and measuring whether mean IoU stays above 30 percent would directly test whether performance transfers beyond the synthetic distribution.
Figures





read the original abstract
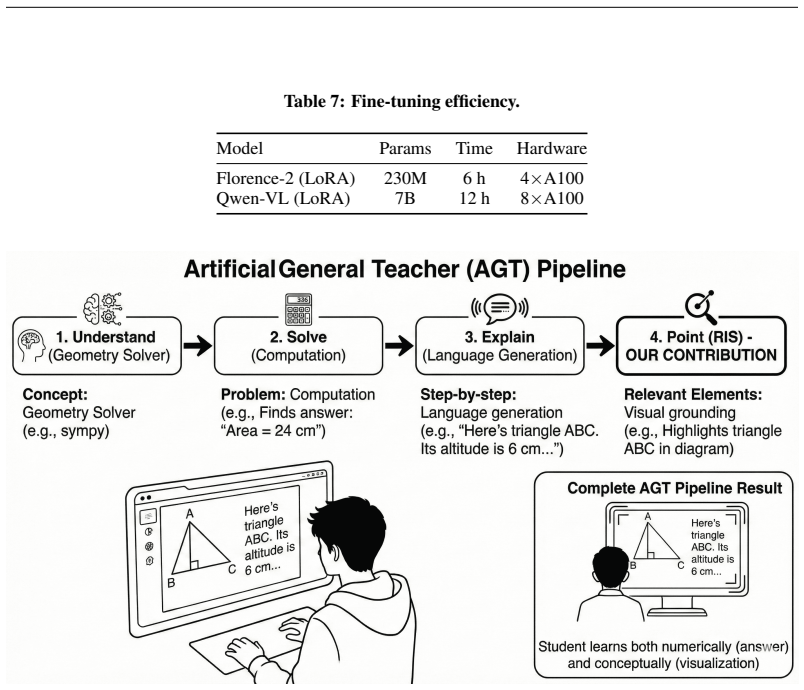
We study visual explanation in geometry education as a Referring Image Segmentation (RIS) problem: given a diagram and a natural language description, the task is to produce a pixel-level mask for the referred geometric element. However, existing RIS models trained on natural image benchmarks such as RefCOCO fail catastrophically on geometric diagrams due to the fundamental domain shift between photographic scenes and abstract, textureless schematics. To address the absence of suitable training data, we present a fully automated procedural data engine that generates over 200,000 synthetic geometry diagrams with pixel-perfect segmentation masks and linguistically diverse referring expressions, requiring zero manual annotation. We further propose domain-specific fine-tuning of vision-language models (VLMs), demonstrating that a fine-tuned Florence-2 achieves 49% IoU and 85% Buffered IoU (BIoU), compared to <1% IoU in zero-shot settings. We introduce Buffered IoU, a geometry-aware evaluation metric that accounts for thin-structure localization, and show that it better reflects true segmentation quality than standard IoU. Our results establish a foundation for building Artificial General Teachers (AGTs) capable of providing visually grounded, step-by-step explanations of geometry problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames visual grounding in geometry education as a referring image segmentation task and introduces a fully automated procedural engine that generates over 200,000 synthetic diagrams with pixel-perfect masks and diverse referring expressions. It fine-tunes Florence-2 on this data to report 49% IoU and 85% Buffered IoU on a held-out synthetic test split (versus <1% zero-shot), introduces Buffered IoU as a geometry-aware metric for thin structures, and positions the work as a foundation for Artificial General Teachers.
Significance. The procedural data engine and Buffered IoU metric represent useful engineering contributions that could scale training data for educational VLMs if the synthetic distribution proves representative. However, the reported performance gains are obtained exclusively on in-distribution synthetic test data, so the significance for real-world geometry education remains conditional on untested transfer.
major comments (3)
- [Experiments / Results] Experiments / Results: All headline numbers (49% IoU, 85% BIoU) are measured on a test split drawn from the identical procedural generator used for the 200k training diagrams. No cross-domain evaluation on authentic textbook or classroom diagrams is reported, leaving the synthetic-to-real transfer—the central premise for AGT utility—unverified.
- [Data generation] Data generation section: The manuscript provides no quantitative description of the sampling distribution over diagram types, line thicknesses, label placements, or referring-expression templates used to produce the 200k diagrams. This absence prevents assessment of dataset diversity and potential mode collapse.
- [Evaluation protocol] Evaluation protocol: No ablation studies on fine-tuning hyperparameters, no comparisons against other VLMs, and no error bars or multiple-run statistics accompany the reported IoU/BIoU figures, making it impossible to judge whether the gains are robust or sensitive to random seeds.
minor comments (2)
- [Abstract] Abstract: The phrase 'zero manual annotation' is technically correct but could explicitly note that human effort was still required to design the procedural rules and templates.
- [Metric definition] Notation: The exact buffering radius and implementation details for Buffered IoU are not provided in a reproducible form (e.g., pseudocode or parameter values).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's claims regarding data diversity, evaluation robustness, and real-world applicability.
read point-by-point responses
-
Referee: [Experiments / Results] Experiments / Results: All headline numbers (49% IoU, 85% BIoU) are measured on a test split drawn from the identical procedural generator used for the 200k training diagrams. No cross-domain evaluation on authentic textbook or classroom diagrams is reported, leaving the synthetic-to-real transfer—the central premise for AGT utility—unverified.
Authors: We acknowledge that all reported metrics are computed on in-distribution synthetic data, which limits direct claims about real-world transfer. This choice was intentional to first validate the procedural engine and the Buffered IoU metric in a controlled setting. We agree that synthetic-to-real transfer is essential for the AGT premise. In the revised version we will add a preliminary cross-domain experiment using a small collection of authentic textbook diagrams (approximately 200 images) with manually annotated masks, report the corresponding IoU/BIoU numbers, and include a dedicated discussion of observed domain gaps and mitigation strategies. revision: yes
-
Referee: [Data generation] Data generation section: The manuscript provides no quantitative description of the sampling distribution over diagram types, line thicknesses, label placements, or referring-expression templates used to produce the 200k diagrams. This absence prevents assessment of dataset diversity and potential mode collapse.
Authors: We agree that a quantitative characterization of the sampling process is necessary. The engine samples diagram complexity uniformly (1–6 primitives), line thickness from {1,2,3,4,5} pixels, label placement offsets from a discrete set of 8 directions, and referring expressions from 12 template families with controlled synonym substitution. In the revision we will insert a new table that reports the exact parameter ranges, sampling probabilities, and resulting empirical frequencies for each category, together with a brief analysis of coverage and potential mode-collapse risks. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: No ablation studies on fine-tuning hyperparameters, no comparisons against other VLMs, and no error bars or multiple-run statistics accompany the reported IoU/BIoU figures, making it impossible to judge whether the gains are robust or sensitive to random seeds.
Authors: We accept that the current single-run results are insufficient to demonstrate robustness. The revised manuscript will include (i) an ablation table varying learning rate, batch size, and number of epochs, (ii) a comparison against two additional VLMs (LLaVA-1.5 and a fine-tuned Segment Anything Model variant) under identical data conditions, and (iii) mean and standard deviation of IoU/BIoU computed over three independent random seeds. These additions will be placed in a new “Ablation and Robustness” subsection. revision: yes
Circularity Check
No circularity: empirical performance measured on independently generated synthetic test data
full rationale
The paper describes a procedural data engine that generates over 200,000 synthetic geometry diagrams with pixel-perfect masks and referring expressions, followed by fine-tuning of Florence-2 and reporting of IoU/BIoU metrics on a held-out test split from the same generator. No equations, derivations, or fitted parameters are presented that reduce the reported performance numbers to quantities defined inside the paper by construction. The introduction of Buffered IoU is an explicit new metric definition rather than a self-referential claim. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The central result is therefore an ordinary empirical measurement on self-generated but independently sampled data, making the derivation self-contained with no reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic diagrams and referring expressions sufficiently represent real geometry education materials.
invented entities (1)
-
Buffered IoU metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric P. Xing, and Liang Lin. Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp.\ 513--523. Association for Computational Linguistics, August 2021
work page 2021
-
[4]
Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression
Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression. arXiv preprint arXiv:2212.02746, 2022
-
[5]
Carla: An open urban driving simulator
Alexey Dosovitskiy et al. Carla: An open urban driving simulator. In Conference on Robot Learning (CoRL), 2017
work page 2017
-
[6]
G-llava: Solving geometric problem with multi-modal large language model
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, et al. G-llava: Solving geometric problem with multi-modal large language model. arXiv preprint arXiv:2312.11370, 2023
-
[7]
Explaining math: Gesturing lightens the load
Susan Goldin-Meadow, Howard Nusbaum, Spencer Kelly, and Susan Cook. Explaining math: Gesturing lightens the load. Psychological science, 12: 0 516--22, 12 2001. doi:10.1111/1467-9280.00395
-
[8]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[9]
Segmentation from natural language expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In European Conference on Computer Vision (ECCV), 2016
work page 2016
-
[10]
R efer I t G ame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. R efer I t G ame: Referring to objects in photographs of natural scenes. In Alessandro Moschitti, Bo Pang, and Walter Daelemans (eds.), Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pp.\ 787--798, Doha, Qatar, October 2014. Association for...
-
[11]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 9579--9589, June 2024
work page 2024
-
[12]
Chenxi Liu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, and Alan L. Yuille. Recurrent multimodal interaction for referring image segmentation. In 2017 IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[13]
Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021
work page 2021
-
[14]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu et al. Mathvista: Evaluating mathematical reasoning in visual contexts. In arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L. Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
work page 2016
-
[16]
Richard E. Mayer. Multimedia Learning. Cambridge University Press, 2002
work page 2002
-
[17]
Richard E. Mayer. The past, present, and future of the cognitive theory of multimedia learning. Educational Psychology Review, 36, 2024. URL https://api.semanticscholar.org/CorpusID:267130958
work page 2024
-
[18]
Hai Nguyen-Truong, E-Ro Nguyen, Tuan-Anh Vu, Minh-Triet Tran, Binh-Son Hua, and Sai-Kit Yeung. Vision-aware text features in referring image segmentation: From object understanding to context understanding. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), pp.\ 4988--4998, February 2025
work page 2025
-
[19]
Math-llava: Boosting visual mathematical reasoning for large language models
Yuan Shi et al. Math-llava: Boosting visual mathematical reasoning for large language models. In arXiv preprint arXiv:2401.XXXX, 2024
work page 2024
-
[20]
Cris: Clip-driven referring image segmentation
Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 11686--11695, June 2022
work page 2022
-
[21]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 4818--4829, June 2024
work page 2024
-
[22]
Lavt: Language-aware vision transformer for referring image segmentation
Zhao Yang, Jiaqi Wang, Yansong Tang, Kai Chen, Hengshuang Zhao, and Philip HS Torr. Lavt: Language-aware vision transformer for referring image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 18155--18165, 2022
work page 2022
-
[23]
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions. In European Conference on Computer Vision (ECCV), pp.\ 69--85. Springer, 2016
work page 2016
-
[24]
Mathverse: A benchmark for multi-modal math reasoning
Yuhui Zhang et al. Mathverse: A benchmark for multi-modal math reasoning. In arXiv preprint arXiv:2403.XXXX, 2024 a
work page 2024
-
[25]
Mavis: Math-aware visual instruction tuning
Yuhui Zhang et al. Mavis: Math-aware visual instruction tuning. In arXiv preprint arXiv:2404.XXXX, 2024 b
work page 2024
-
[26]
Publaynet: Largest dataset ever for document layout analysis
Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. Publaynet: Largest dataset ever for document layout analysis. In Proceedings of ICDAR, 2019
work page 2019
-
[27]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[28]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[29]
Line segment from point A to point B
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.