Recognition: no theorem link
PRISM: LLM-Guided Semantic Clustering for High-Precision Topics
Pith reviewed 2026-05-13 20:40 UTC · model grok-4.3
The pith
PRISM fine-tunes a sentence encoder on sparse LLM labels to create more separable topic clusters than frontier models or traditional methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRISM fine-tunes a sentence encoding model on a sparse sample of LLM-provided labels drawn from the corpus of interest, then segments the resulting embedding space with thresholded clustering to produce clusters that separate closely related topics more effectively than state-of-the-art local topic models or direct clustering on large frontier embeddings.
What carries the argument
The student-teacher pipeline that distills sparse LLM supervision into a lightweight sentence encoder, improving local geometry for subsequent thresholded clustering.
If this is right
- Enables locally deployable, interpretable models for tracking nuanced subtopics in large online text collections.
- Reduces the number of LLM queries needed while still outperforming both traditional topic models and direct use of large embedding models.
- Supports analysis of narrow domains where global models fail to resolve fine distinctions.
Where Pith is reading between the lines
- The sampling strategy for choosing which documents receive LLM labels may itself be tuned to further sharpen cluster boundaries.
- The same distillation pattern could apply to other embedding tasks beyond topic modeling, such as entity resolution in domain-specific text.
- Once trained, the lightweight encoder could support incremental updates as new documents arrive without re-querying the LLM.
Load-bearing premise
LLM labels on a small sample are accurate and representative enough that fine-tuning the encoder on them improves cluster separability across the full corpus.
What would settle it
On a held-out corpus, thresholded clustering of the fine-tuned embeddings yields no gain in separability metrics such as adjusted mutual information or silhouette score relative to baselines using the original frontier embeddings.
Figures

read the original abstract
In this paper, we propose Precision-Informed Semantic Modeling (PRISM), a structured topic modeling framework combining the benefits of rich representations captured by LLMs with the low cost and interpretability of latent semantic clustering methods. PRISM fine-tunes a sentence encoding model using a sparse set of LLM- provided labels on samples drawn from some corpus of interest. We segment this embedding space with thresholded clustering, yielding clusters that separate closely related topics within some narrow domain. Across multiple corpora, PRISM improves topic separability over state-of-the-art local topic models and even over clustering on large, frontier embedding models while requiring only a small number of LLM queries to train. This work contributes to several research streams by providing (i) a student-teacher pipeline to distill sparse LLM supervision into a lightweight model for topic discovery; (ii) an analysis of the efficacy of sampling strategies to improve local geometry for cluster separability; and (iii) an effective approach for web-scale text analysis, enabling researchers and practitioners to track nuanced claims and subtopics online with an interpretable, locally deployable framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, a student-teacher framework that fine-tunes a lightweight sentence encoder on a sparse set of LLM-provided labels sampled from a target corpus, then applies thresholded clustering in the resulting embedding space to produce high-precision topics within narrow domains. It claims superior topic separability compared to state-of-the-art local topic models and to direct clustering on unmodified frontier embeddings, while using only a small number of LLM queries.
Significance. If the empirical claims are substantiated, PRISM would provide a practical, low-cost method for distilling sparse LLM supervision into interpretable, locally deployable topic models, with potential value for web-scale analysis of nuanced subtopics. The approach also contributes an analysis of sampling strategies for improving local embedding geometry.
major comments (3)
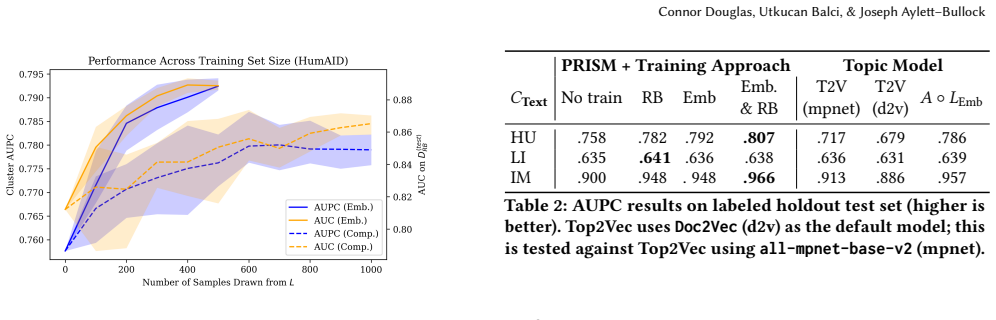
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of improved separability over frontier embeddings and SOTA local models is asserted without any reported metrics, baselines, dataset sizes, error bars, or ablation tables, leaving the quantitative improvement unsupported by visible evidence.
- [§3 and §4] §3 (Method) and §4: the comparison to frontier embeddings does not include an ablation that applies the identical thresholded clustering procedure to the unmodified frontier embeddings; without this control, it remains unclear whether reported gains arise from the LLM-guided fine-tuning step or from the clustering procedure itself.
- [§3.2] §3.2 (Labeling and Sampling): the method assumes LLM-provided labels on the sparse sample are sufficiently accurate and representative to improve cluster geometry; no validation of label quality, inter-annotator agreement, or sensitivity analysis to label noise is described, which is load-bearing for the fine-tuning efficacy claim.
minor comments (2)
- [§3.1] Clarify the exact definition and selection procedure for the clustering threshold parameter listed among the free parameters.
- [§4] Add explicit dataset citations and preprocessing details for the multiple corpora mentioned in the abstract.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our submission. We appreciate the opportunity to clarify and strengthen the presentation of our results. Below we respond point-by-point to the major comments, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of improved separability over frontier embeddings and SOTA local models is asserted without any reported metrics, baselines, dataset sizes, error bars, or ablation tables, leaving the quantitative improvement unsupported by visible evidence.
Authors: We agree that the abstract and experimental section would benefit from more explicit quantitative support. In the revised manuscript, we will include specific metrics (e.g., normalized mutual information, purity scores), dataset sizes, number of runs for error bars, and full ablation tables in §4 to directly support the claims of improved separability. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: the comparison to frontier embeddings does not include an ablation that applies the identical thresholded clustering procedure to the unmodified frontier embeddings; without this control, it remains unclear whether reported gains arise from the LLM-guided fine-tuning step or from the clustering procedure itself.
Authors: This is a valid point. The current manuscript compares to clustering on frontier embeddings but we will add an explicit ablation in the revised §4 that applies the exact same thresholded clustering procedure to the unmodified embeddings. This will isolate the contribution of the fine-tuning step. revision: yes
-
Referee: [§3.2] §3.2 (Labeling and Sampling): the method assumes LLM-provided labels on the sparse sample are sufficiently accurate and representative to improve cluster geometry; no validation of label quality, inter-annotator agreement, or sensitivity analysis to label noise is described, which is load-bearing for the fine-tuning efficacy claim.
Authors: We acknowledge the importance of validating the LLM labels. In revision, we will add a section on label quality assessment through manual verification of a sample of labels and a sensitivity analysis to label noise by introducing controlled perturbations. Note that inter-annotator agreement is not directly applicable as labels come from a single LLM, but we will discuss potential noise sources. revision: partial
Circularity Check
No circularity: method uses external LLM labels and reports held-out performance
full rationale
The PRISM pipeline fine-tunes an encoder on sparse external LLM labels then applies thresholded clustering; the central claims rest on empirical comparisons to independent baselines (local topic models and unmodified frontier embeddings) evaluated on held-out corpora. No equations, sampling strategies, or performance metrics reduce by construction to the fitted parameters or to self-citations that carry the load of the result. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- clustering threshold
- number of LLM labels
axioms (1)
- domain assumption LLM labels on sparse samples are accurate and representative for the target domain
Reference graph
Works this paper leans on
-
[1]
Firoj Alam, Umair Qazi, Muhammad Imran, and Ferda Ofli. 2021. Humaid: Human-annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks. InICWSM, Vol. 15. 933–942
work page 2021
- [2]
-
[3]
David M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent Dirichlet Alloca- tion.Journal of Machine Learning Research3, Jan (2003), 993–1022
work page 2003
-
[4]
Roman Egger and Joanne Yu. 2022. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts.Frontiers in Sociology 7 (2022), 886498
work page 2022
-
[5]
Maarten Grootendorst. 2022. BERTopic: Neural Topic Modeling with a Class- based TF-IDF Procedure.arXiv:2203.05794(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Alexander Miserlis Hoyle, Pranav Goel, and Philip Resnik. 2020. Improving Neural Topic Models Using Knowledge Distillation. InEMNLP. 1752–1771
work page 2020
-
[7]
Xiang Huang, Hao Peng, Dongcheng Zou, Zhiwei Liu, Jianxin Li, Kay Liu, Jia Wu, Jianlin Su, and Philip S Yu. 2024. CoSENT: Consistent Sentence Embedding via Similarity Ranking.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2800–2813
work page 2024
-
[8]
Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. InACL. 142–150
work page 2011
-
[9]
Jay Mohta, Kenan Ak, Yan Xu, and Mingwei Shen. 2023. Are Large Language Models Good Annotators?. InNeurIPS 2023 Workshops (Proceedings of Machine Learning Research, Vol. 239). PMLR, 38–48
work page 2023
-
[10]
Anup Pattnaik, Cijo George, Rishabh Kumar Tripathi, Sasanka Vutla, and Jithen- dra Vepa. 2024. Improving Hierarchical Text Clustering with LLM-guided Multi- view Cluster Representation. InEMNLP. 719–727
work page 2024
-
[11]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. 2024. TopicGPT: A Prompt-based Topic Modeling Framework. InNAACL. 2956–2984
work page 2024
-
[12]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InEMNLP-IJCNLP. 3982–3992
work page 2019
-
[13]
Vijay Viswanathan, Kiril Gashteovski, Carolin Lawrence, Tongshuang Wu, and Graham Neubig. 2024. Large Language Models Enable Few-shot Clustering. TACL12 (2024), 321–333
work page 2024
-
[14]
Han Wang, Nirmalendu Prakash, Nguyen Khoi Hoang, Ming Shan Hee, Usman Naseem, and Roy Ka-Wei Lee. 2023. Prompting Large Language Models for Topic Modeling. InIEEE BigData. IEEE, 1236–1241
work page 2023
-
[15]
William Yang Wang. 2017. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. InACL. ACL, Vancouver, Canada, 422–426
work page 2017
-
[16]
Yuwei Zhang, Zihan Wang, and Jingbo Shang. 2023. ClusterLLM: Large Language Models as a Guide for Text Clustering. InEMNLP. Association for Computational Linguistics, 13903–13920. 4
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.