Recognition: no theorem link
Safe Decentralized Operation of EV Virtual Power Plant with Limited Network Visibility via Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-15 00:56 UTC · model grok-4.3
The pith
A transformer-assisted multi-agent RL method lets virtual power plants coordinate EV charging stations safely with only aggregated network data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
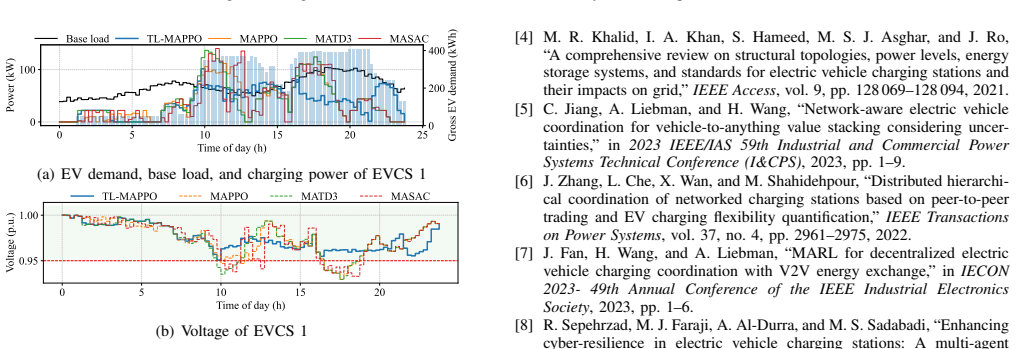
The TL-MAPPO framework enables EVCS agents to learn decentralized charging policies through centralized training, where Lagrangian regularization enforces voltage and demand-satisfaction constraints despite limited network visibility. Transformer embeddings capture temporal correlations among prices, loads, and charging demands to improve decision quality. On a realistic 33-bus PDN, the method reduces voltage violations by approximately 45 percent and operational costs by approximately 10 percent compared with representative multi-agent DRL baselines.
What carries the argument
Transformer-assisted Lagrangian Multi-Agent Proximal Policy Optimization (TL-MAPPO), in which a transformer embedding layer captures temporal correlations and Lagrangian regularization during centralized training enforces voltage and demand constraints for decentralized policy execution.
If this is right
- Voltage violations drop by approximately 45 percent compared with standard multi-agent DRL baselines.
- Operational costs fall by approximately 10 percent while demand is still met.
- VPP operators can maintain voltage security using only aggregated data shared by the distribution system operator.
- Decentralized execution becomes feasible without requiring full real-time network state at each EV charging station.
Where Pith is reading between the lines
- The same training structure could coordinate other behind-the-meter resources such as stationary batteries or solar inverters under similar visibility limits.
- Performance gains from the transformer layer may appear in other power-system tasks that involve time-series price and load data.
- Scaling tests on networks larger than 33 buses or with added communication delays would clarify practical deployment limits.
Load-bearing premise
Lagrangian regularization applied during centralized training will reliably prevent voltage and demand violations when the learned decentralized policies run with only aggregated information in conditions beyond the simulation.
What would settle it
Deploy the trained decentralized policies on a physical 33-bus distribution network and measure actual voltage violation frequency and total operational cost against the simulated results.
Figures



read the original abstract
As power systems advance toward net-zero targets, behind-the-meter renewables are driving rapid growth in distributed energy resources (DERs). Virtual power plants (VPPs) increasingly coordinate these resources to support power distribution network (PDN) operation, with EV charging stations (EVCSs) emerging as a key asset due to their strong impact on local voltages. However, in practice, VPPs must make operational decisions with only partial visibility of PDN states, relying on limited, aggregated information shared by the distribution system operator. This work proposes a safety-enhanced VPP framework for coordinating multiple EVCSs under such realistic information constraints to ensure voltage security while maintaining economic operation. We develop Transformer-assisted Lagrangian Multi-Agent Proximal Policy Optimization (TL-MAPPO), in which EVCS agents learn decentralized charging policies via centralized training with Lagrangian regularization to enforce voltage and demand-satisfaction constraints. A transformer-based embedding layer deployed on each EVCS agent captures temporal correlations among prices, loads, and charging demand to improve decision quality. Experiments on a realistic 33-bus PDN show that the proposed framework reduces voltage violations by approximately 45% and operational costs by approximately 10% compared to representative multi-agent DRL baselines, highlighting its potential for practical VPP deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TL-MAPPO, a transformer-assisted Lagrangian multi-agent proximal policy optimization method, for safe decentralized coordination of EV charging stations in a virtual power plant under limited PDN visibility. Using centralized training with decentralized execution and Lagrangian regularization for voltage and demand constraints, along with transformer embeddings for temporal data, the approach is tested on a 33-bus PDN, claiming ~45% fewer voltage violations and ~10% lower costs versus baselines.
Significance. If the constraint transfer holds, this addresses a key practical gap in VPP operation by enabling safe decentralized EVCS control with only aggregated signals, which is essential for scaling DER coordination in distribution networks. The CTDE-plus-Lagrangian design combined with transformer temporal modeling offers a concrete path toward constraint-aware multi-agent RL for power systems.
major comments (2)
- [Abstract and Section 5] Abstract and experimental results: the central claim of ~45% voltage-violation reduction and ~10% cost reduction is reported without baseline implementation details, statistical significance tests, error bars, or exact per-constraint violation counts, leaving the quantitative improvement difficult to verify or reproduce.
- [Section 4] Section 4 (TL-MAPPO and Lagrangian regularization): the safety claim rests on Lagrangian terms enforcing voltage and demand constraints during centralized training, yet no post-training verification, dual-variable analysis, or decentralized-execution constraint-violation statistics are provided to confirm that the learned policies continue to satisfy the limits when each agent receives only aggregated price/load/demand signals.
minor comments (1)
- [Section 3.2] Clarify the exact form of the aggregated observation vector passed to each EVCS agent at execution time and confirm it matches the training distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and verifiability of our results. We will revise the manuscript to provide additional experimental details, statistical analysis, and explicit verification of constraint satisfaction under decentralized execution.
read point-by-point responses
-
Referee: [Abstract and Section 5] Abstract and experimental results: the central claim of ~45% voltage-violation reduction and ~10% cost reduction is reported without baseline implementation details, statistical significance tests, error bars, or exact per-constraint violation counts, leaving the quantitative improvement difficult to verify or reproduce.
Authors: We agree that the current presentation lacks sufficient detail for full reproducibility and statistical rigor. In the revised version we will: (i) document all baseline implementations (hyperparameters, network architectures, training seeds), (ii) report mean and standard deviation across at least five independent runs with error bars, (iii) include paired t-tests or Wilcoxon tests for significance, and (iv) add a table with exact per-constraint violation counts (voltage, demand) for each method. These additions will be placed in Section 5 and the appendix. revision: yes
-
Referee: [Section 4] Section 4 (TL-MAPPO and Lagrangian regularization): the safety claim rests on Lagrangian terms enforcing voltage and demand constraints during centralized training, yet no post-training verification, dual-variable analysis, or decentralized-execution constraint-violation statistics are provided to confirm that the learned policies continue to satisfy the limits when each agent receives only aggregated price/load/demand signals.
Authors: We acknowledge that explicit post-training verification is necessary to substantiate the safety claim under decentralized execution. In the revision we will add: (1) constraint-violation statistics collected during fully decentralized test episodes using only aggregated signals, (2) plots of the learned dual-variable trajectories showing convergence to stable multipliers that keep violations near zero, and (3) an ablation comparing violation rates with and without the Lagrangian term. These results will be reported in Section 4 and a new subsection of the experiments. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents TL-MAPPO as a standard CTDE multi-agent RL algorithm augmented with Lagrangian regularization for constraints and a transformer embedding for temporal features. Performance metrics (voltage violation reduction and cost savings) are computed directly from simulation rollouts on the 33-bus PDN against external baselines; they are not defined in terms of the learned parameters or fitted quantities. No equations reduce a claimed prediction to a fitted input by construction, no uniqueness theorems are imported from self-citations, and no ansatz is smuggled via prior work. The method trains on simulated trajectories and reports out-of-sample test performance, keeping the derivation chain self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Net zero by 2050: A roadmap for the global energy sector
International Energy Agency (IEA), “Net zero by 2050: A roadmap for the global energy sector.” [Online]. Available: https://www.iea.org/repo rts/net-zero-by-2050
work page 2050
-
[2]
IEA (2024), global EV outlook 2024
——, “IEA (2024), global EV outlook 2024.” [Online]. Available: https://www.iea.org/reports/global-ev-outlook-2024
work page 2024
-
[3]
Virtual power plant and system integration of distributed energy resources,
D. Pudjianto, C. Ramsay, and G. Strbac, “Virtual power plant and system integration of distributed energy resources,”IET Renewable power generation, vol. 1, no. 1, pp. 10–16, 2007
work page 2007
-
[4]
M. R. Khalid, I. A. Khan, S. Hameed, M. S. J. Asghar, and J. Ro, “A comprehensive review on structural topologies, power levels, energy storage systems, and standards for electric vehicle charging stations and their impacts on grid,”IEEE Access, vol. 9, pp. 128 069–128 094, 2021
work page 2021
-
[5]
C. Jiang, A. Liebman, and H. Wang, “Network-aware electric vehicle coordination for vehicle-to-anything value stacking considering uncer- tainties,” in2023 IEEE/IAS 59th Industrial and Commercial Power Systems Technical Conference (I&CPS), 2023, pp. 1–9
work page 2023
-
[6]
J. Zhang, L. Che, X. Wan, and M. Shahidehpour, “Distributed hierarchi- cal coordination of networked charging stations based on peer-to-peer trading and EV charging flexibility quantification,”IEEE Transactions on Power Systems, vol. 37, no. 4, pp. 2961–2975, 2022
work page 2022
-
[7]
MARL for decentralized electric vehicle charging coordination with V2V energy exchange,
J. Fan, H. Wang, and A. Liebman, “MARL for decentralized electric vehicle charging coordination with V2V energy exchange,” inIECON 2023- 49th Annual Conference of the IEEE Industrial Electronics Society, 2023, pp. 1–6
work page 2023
-
[8]
R. Sepehrzad, M. J. Faraji, A. Al-Durra, and M. S. Sadabadi, “Enhancing cyber-resilience in electric vehicle charging stations: A multi-agent deep reinforcement learning approach,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 11, pp. 18 049–18 062, 2024
work page 2024
-
[9]
J. Zhang, Y . Guan, L. Che, and M. Shahidehpour, “EV charging command fast allocation approach based on deep reinforcement learning with safety modules,”IEEE Transactions on Smart Grid, vol. 15, no. 1, pp. 757–769, 2024
work page 2024
-
[10]
S. Lee and D.-H. Choi, “Three-stage deep reinforcement learning for privacy-and safety-aware smart electric vehicle charging station schedul- ing and volt/var control,”IEEE Internet of Things Journal, vol. 11, no. 5, pp. 8578–8589, 2024
work page 2024
-
[11]
F. Rossi, C. Diaz-Londono, Y . Li, C. Zou, and G. Gruosso, “Smart electric vehicle charging algorithm to reduce the impact on power grids: a reinforcement learning based methodology,”IEEE Open Journal of V ehicular Technology, pp. 1–13, 2025
work page 2025
-
[12]
Responsive safety in reinforce- ment learning by pid lagrangian methods,
A. Stooke, J. Achiam, and P. Abbeel, “Responsive safety in reinforce- ment learning by pid lagrangian methods,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 9133–9143
work page 2020
-
[13]
S. Zhang, R. Jia, H. Pan, and Y . Cao, “A safe reinforcement learning- based charging strategy for electric vehicles in residential microgrid,” Applied Energy, vol. 348, p. 121490, 2023
work page 2023
-
[14]
Advanced VPP grid integration project,
Australian Renewable Energy Agency (ARENA), “Advanced VPP grid integration project,” 2021, https://arena.gov.au/assets/2021/05/advanced- vpp-grid-integration-final-report.pdf
work page 2021
-
[15]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[16]
ACN-data: Analysis and applications of an open EV charging dataset,
Z. J. Lee, T. Li, and S. H. Low, “ACN-data: Analysis and applications of an open EV charging dataset,” inProceedings of the Tenth ACM International Conference on Future Energy Systems, 2019, pp. 139–149
work page 2019
-
[17]
Residential load and rooftop pv generation: an australian distribution network dataset,
E. L. Ratnam, S. R. Weller, C. M. Kellett, and A. T. Murray, “Residential load and rooftop pv generation: an australian distribution network dataset,”International Journal of Sustainable Energy, vol. 36, no. 8, pp. 787–806, 2017
work page 2017
-
[18]
Australian Energy Market Operator (AEMO), “NEM data dash- board,” 2023, https://aemo.com.au/energy-systems/electricity/national- electricity-market-nem/data-nem/data-dashboard-nem. APPENDIX A. Methodological Details
work page 2023
-
[19]
Transformer:To address partial observability in EVCS coordination, a Transformer-based temporal encoder is em- ployed to extract compact representations from historical observations. Specifically, at each decision time stept, a temporal observation window is constructed by stacking the local observations defined in Eq. (13) over a fixed horizon, forming a...
-
[20]
Overall Algorithm:As shown in Algorithm 1, the train- ing loop of TL-MAPPO is explicitly outlined, including the Transformer-based observation embedding and Lagrangian up- date, as provided below to improve clarity and reproducibility. B. Discussion
-
[21]
Communication and Computation:We consider a high- level coordination architecture between the DSO and the VPP, which is consistent with common abstractions adopted in power system operation studies. In this architecture, the DSO is responsible for monitoring the distribution network and provides the VPP with limited and aggregated network in- formation to...
-
[22]
Scalability:The proposed framework is designed with scalability in mind from an architectural standpoint. As the number of EVCSs increases, communication and computa- tional overhead primarily scale at the VPP side during cen- tralized training, since aggregated information from multiple EVCSs is used to update centralized critics. In contrast, the commun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.