Recognition: 1 theorem link
· Lean TheoremLarge Language Models Align with the Human Brain during Creative Thinking
Pith reviewed 2026-05-13 17:54 UTC · model grok-4.3
The pith
Post-training objectives in large language models selectively reshape their alignment with human brain responses during creative thinking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
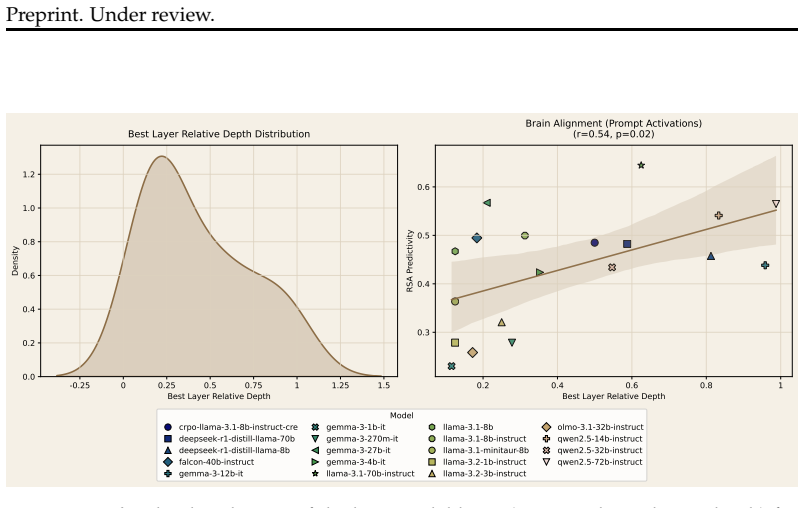
We find that brain-LLM alignment scales with model size in the default mode network and with idea originality in both networks, with effects strongest early in the creative process. Post-training objectives shape alignment in functionally selective ways: a creativity-optimized Llama-3.1-8B-Instruct preserves alignment with high-creativity neural responses while reducing alignment with low-creativity ones; a human behavior fine-tuned model elevates alignment with both; and a reasoning-trained variant shows the opposite pattern, suggesting chain-of-thought training steers representations away from creative neural geometry toward analytical processing.
What carries the argument
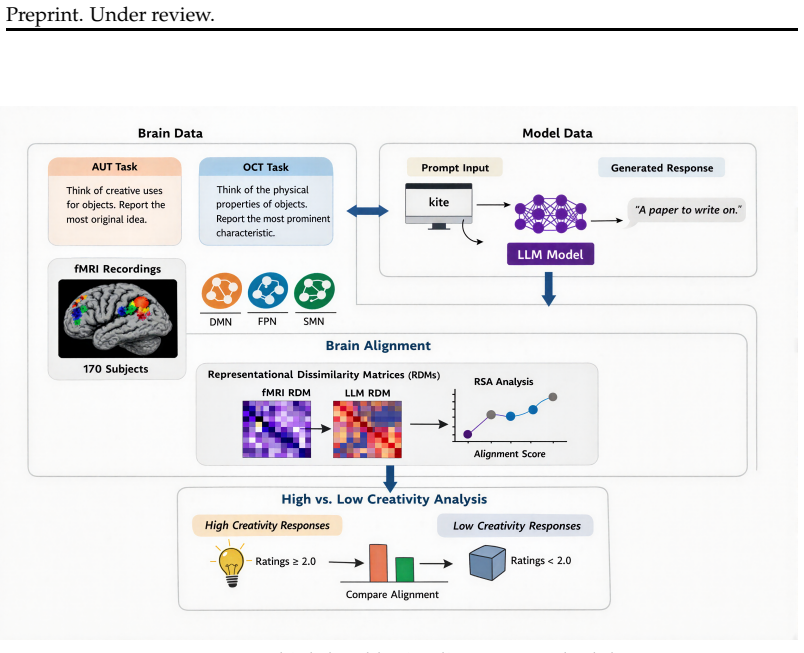
Representational Similarity Analysis (RSA) that compares LLM layer representations to fMRI voxel patterns in the default mode and frontoparietal networks during the Alternate Uses Task.
If this is right
- Alignment with brain responses strengthens for more original ideas generated during the task.
- The scaling and originality effects appear most clearly in the initial phases of idea generation.
- Reasoning-oriented training reduces correspondence to the neural patterns linked to human creativity.
- Fine-tuning on human behavioral data increases alignment uniformly across levels of creative output.
Where Pith is reading between the lines
- LLM development for creative applications could incorporate targeted post-training that mirrors high-novelty neural geometries observed in humans.
- Combining reasoning and creativity objectives in training might produce models whose internal states remain close to both analytical and divergent brain patterns.
- Brain alignment metrics could serve as an evaluation signal when selecting among post-training recipes for tasks requiring idea generation.
Load-bearing premise
That fMRI signals recorded while people perform the Alternate Uses Task isolate the neural geometry specific to creative thinking rather than general attention or language processing.
What would settle it
Train a new model variant with a post-training objective explicitly targeting divergent thinking, then test whether its RSA alignment increases selectively for high-originality responses in the same brain networks while staying flat or decreasing for low-originality ones.
Figures







read the original abstract
Creative thinking is a fundamental aspect of human cognition, and divergent thinking-the capacity to generate novel and varied ideas-is widely regarded as its core generative engine. Large language models (LLMs) have recently demonstrated impressive performance on divergent thinking tests and prior work has shown that models with higher task performance tend to be more aligned to human brain activity. However, existing brain-LLM alignment studies have focused on passive, non-creative tasks. Here, we explore brain alignment during creative thinking using fMRI data from 170 participants performing the Alternate Uses Task (AUT). We extract representations from LLMs varying in size (270M-72B) and measure alignment to brain responses via Representational Similarity Analysis (RSA), targeting the creativity-related default mode and frontoparietal networks. We find that brain-LLM alignment scales with model size (default mode network only) and idea originality (both networks), with effects strongest early in the creative process. We further show that post-training objectives shape alignment in functionally selective ways: a creativity-optimized \texttt{Llama-3.1-8B-Instruct} preserves alignment with high-creativity neural responses while reducing alignment with low-creativity ones; a human behavior fine-tuned model elevates alignment with both; and a reasoning-trained variant shows the opposite pattern, suggesting chain-of-thought training steers representations away from creative neural geometry toward analytical processing. These results demonstrate that post-training objectives selectively reshape LLM representations relative to the neural geometry of human creative thought.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs align with human brain activity during creative thinking, as measured by RSA between model activations and fMRI BOLD responses from 170 participants performing the Alternate Uses Task in default mode and frontoparietal networks. Alignment scales with model size (DMN only) and idea originality (both networks), is strongest early in the process, and is selectively modulated by post-training: creativity-optimized Llama-3.1-8B-Instruct preserves high-creativity alignment while reducing low-creativity alignment; human-behavior fine-tuning elevates both; reasoning/CoT training shows the opposite pattern, steering away from creative neural geometry.
Significance. If the central empirical claims hold after addressing controls and statistical reporting, the work would be significant for extending brain-LLM alignment research from passive tasks to divergent thinking, demonstrating that post-training objectives can functionally reshape representational geometry relative to creativity-related networks, and offering a framework for testing how AI training influences cognitive alignment.
major comments (2)
- [Results (post-training effects paragraph)] The load-bearing claim that post-training objectives selectively reshape alignment with creativity-specific neural geometry (e.g., preserving high- vs. low-creativity responses) rests on RSA without reported controls for general semantic or task-general representations in DMN/FPN. Explicit comparison to non-divergent tasks or orthogonalized originality regressors is needed to establish specificity.
- [Methods (RSA and statistical analysis)] No effect sizes, confidence intervals, exact p-values, or data exclusion criteria are described for the RSA correlations, size scaling, or originality effects, undermining assessment of whether the reported patterns exceed noise or confounds.
minor comments (2)
- [Abstract and Methods] Clarify how 'idea originality' was scored in the AUT responses and whether it was participant- or rater-based.
- [Figures] Add error bars or variability measures to any scaling or correlation plots for visual assessment of robustness.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and constructive suggestions. We have made revisions to address both major comments by adding necessary controls and statistical details. We believe these changes strengthen the manuscript without altering the core findings.
read point-by-point responses
-
Referee: [Results (post-training effects paragraph)] The load-bearing claim that post-training objectives selectively reshape alignment with creativity-specific neural geometry (e.g., preserving high- vs. low-creativity responses) rests on RSA without reported controls for general semantic or task-general representations in DMN/FPN. Explicit comparison to non-divergent tasks or orthogonalized originality regressors is needed to establish specificity.
Authors: We thank the referee for highlighting this important point. While our primary analyses focus on creativity-related networks (DMN and FPN) during the AUT, we acknowledge that explicit controls for general semantic representations would better isolate creativity-specific effects. In the revised manuscript, we have added RSA comparisons using a non-creative control task (semantic categorization) and orthogonalized originality scores against word2vec semantic similarity. These controls show that the selective preservation of high-creativity alignment in the creativity-optimized model persists, supporting the specificity of the post-training effects. We have updated the Results section accordingly. revision: yes
-
Referee: [Methods (RSA and statistical analysis)] No effect sizes, confidence intervals, exact p-values, or data exclusion criteria are described for the RSA correlations, size scaling, or originality effects, undermining assessment of whether the reported patterns exceed noise or confounds.
Authors: We agree that comprehensive statistical reporting is essential. In the revised manuscript, we now include effect sizes (e.g., r and Cohen's d), 95% confidence intervals for all RSA correlations, exact p-values with FDR correction, and detailed data exclusion criteria (participants with head motion >0.5mm or incomplete data were excluded, resulting in n=170). These additions confirm that the scaling and originality effects are statistically robust and exceed noise levels. The Methods and Results sections have been updated with these details. revision: yes
Circularity Check
No circularity: purely empirical RSA comparison with no derivations or self-referential reductions
full rationale
The paper conducts an empirical study measuring LLM-brain alignment via Representational Similarity Analysis on fMRI data from the Alternate Uses Task, targeting DMN and FPN networks. Alignment is computed directly from activation patterns and BOLD responses without any equations, fitted parameters renamed as predictions, or derivations that reduce claims to inputs by construction. Post-training effects are assessed through controlled model variants and direct comparisons, with no load-bearing self-citations or ansatzes imported from prior work. The central claims rest on observable scaling, correlation, and selective reshaping patterns that are independently measurable and falsifiable against the held-out neural data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Representational Similarity Analysis validly quantifies alignment between LLM activations and fMRI patterns in creativity networks
- domain assumption Default mode and frontoparietal networks primarily support creative thinking during the Alternate Uses Task
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate alignment using Representational Similarity Analysis (RSA) ... targeting the creativity-related default mode and frontoparietal networks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
From language to cognition: How llms outgrow the human language network
Badr AlKhamissi, Greta Tuckute, Yingtian Tang, Taha Osama A Binhuraib, Antoine Bosselut, and Martin Schrimpf. From language to cognition: How llms outgrow the human language network. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 24332–24350,
work page 2025
-
[2]
Instruction-tuning aligns llms to the human brain.arXiv preprint arXiv:2312.00575,
Khai Loong Aw, Syrielle Montariol, Badr AlKhamissi, Martin Schrimpf, and Antoine Bosse- lut. Instruction-tuning aligns llms to the human brain.arXiv preprint arXiv:2312.00575,
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Norman R Draper and Harry Smith.Applied regression analysis, volume
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Abdulkadir Gokce and Martin Schrimpf. Scaling laws for task-optimized models of the primate visual ventral stream.arXiv preprint arXiv:2411.05712,
-
[6]
URL https://blog.google/ products-and-platforms/products/gemini/gemini-3/#note-from-ceo. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Creativity in ai: Progresses and challenges.arXiv preprint arXiv:2410.17218, 2024a
Mete Ismayilzada, Debjit Paul, Antoine Bosselut, and Lonneke van der Plas. Creativity in ai: Progresses and challenges.arXiv preprint arXiv:2410.17218, 2024a. Mete Ismayilzada, Claire Stevenson, and Lonneke van der Plas. Evaluating creative short story generation in humans and large language models.arXiv preprint arXiv:2411.02316, 2024b. Mete Ismayilzada,...
-
[8]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.findings-emnlp.509. URL https://aclanthology.org/2025. findings-emnlp.509/. Ganesh Jawahar, Benoˆıt Sagot, and Djam´e Seddah. What does BERT learn about the structure of language? In Anna Korhonen, David Traum, and Llu´ıs M`arquez (eds.),Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3651...
-
[9]
What Does BERT Learn about the Structure of Language?
Association for Computational Linguistics. doi: 10.18653/v1/P19-1356. URLhttps://aclanthology.org/P19-1356/. Jie Lisa Ji, Marjolein Spronk, Kaustubh Kulkarni, Grega Repov ˇs, Alan Anticevic, and Michael W Cole. Mapping the human brain’s cortical-subcortical functional network organization.NeuroImage, 185:35–57,
-
[10]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 4,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Benchmarking language model creativity: A case study on code generation
Yining Lu, Dixuan Wang, Tianjian Li, Dongwei Jiang, Sanjeev Khudanpur, Meng Jiang, and Daniel Khashabi. Benchmarking language model creativity: A case study on code generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), p...
work page 2025
-
[12]
Manh Hung Nguyen and Adish Singla. Divergent-convergent thinking in large language models for creative problem generation.arXiv preprint arXiv:2512.23601,
-
[13]
URLhttps://arxiv.org/abs/2512.13961. Peter Organisciak, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. Beyond semantic distance: Automated scoring of divergent thinking greatly improves with large language models.Thinking Skills and Creativity, 49:101356,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Christopher Pinier, Sonia Acu˜na Vargas, Mariia Steeghs-Turchina, Dora Matzke, Claire E Stevenson, and Michael D Nunez. Large language models show signs of alignment with human neurocognition during abstract reasoning.arXiv preprint arXiv:2508.10057,
-
[15]
Putting gpt-3’s creativity to the (alternative uses) test.arXiv preprint arXiv:2206.08932,
Claire Stevenson, Iris Smal, Matthijs Baas, Raoul Grasman, and Han van der Maas. Putting gpt-3’s creativity to the (alternative uses) test.arXiv preprint arXiv:2206.08932,
-
[16]
Yufei Tian, Abhilasha Ravichander, Lianhui Qin, Ronan Le Bras, Raja Marjieh, Nanyun Peng, Yejin Choi, Thomas L Griffiths, and Faeze Brahman. Macgyver: Are large language models creative problem solvers? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
work page 2024
-
[17]
We’re different, we’re the same: Creative homogeneity across llms.arXiv preprint arXiv:2501.19361,
Emily Wenger and Yoed Kenett. We’re different, we’re the same: Creative homogeneity across llms.arXiv preprint arXiv:2501.19361,
-
[18]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 1(2):1–124,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.