Recognition: 2 theorem links
· Lean TheoremFocus Matters: Phase-Aware Suppression for Hallucination in Vision-Language Models
Pith reviewed 2026-05-13 18:43 UTC · model grok-4.3
The pith
Vision-language models hallucinate less when low-attention tokens are suppressed during the focus phase of visual processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
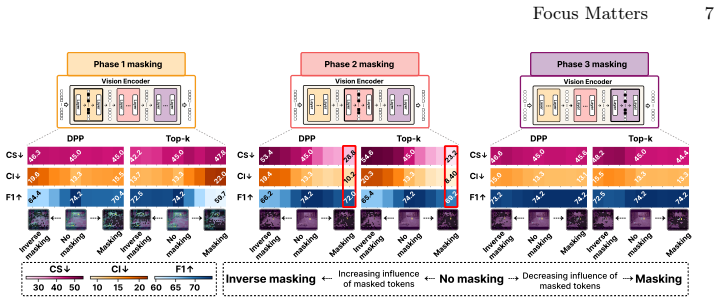
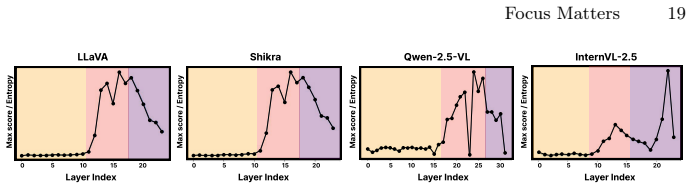
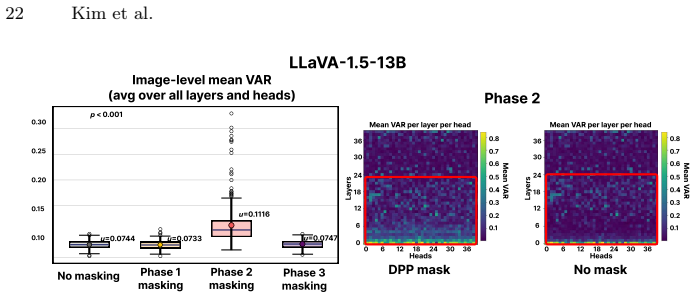
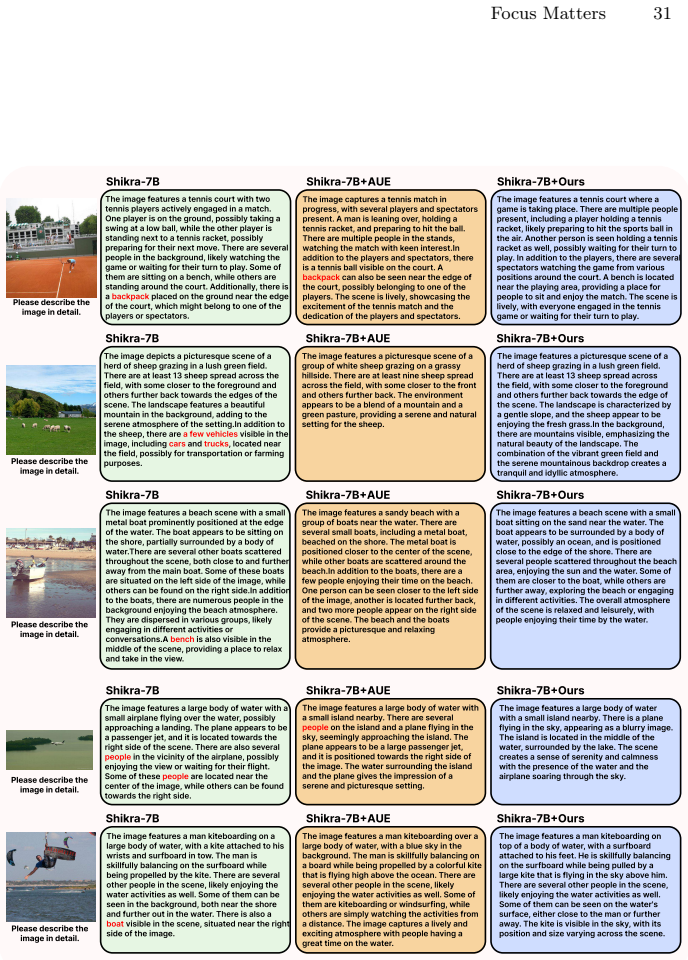
Hallucination behavior in LVLMs is particularly sensitive to tokens receiving low attention during the focus phase of a consistent three-phase attention structure (diffusion, focus, rediffusion) in vision encoders; selectively suppressing such tokens during the focus phase via a Determinantal Point Process reduces hallucination metrics while maintaining competitive caption quality in a lightweight, training-free manner.
What carries the argument
The three-phase attention structure (diffusion, focus, rediffusion) in vision encoders, with selective suppression of low-attention tokens in the focus phase using a Determinantal Point Process to preserve visual diversity.
If this is right
- Hallucination reduction improves reliability of generated descriptions for downstream tasks such as image captioning and visual question answering.
- The inference-time, training-free design allows direct application to existing deployed models without retraining costs.
- Comparable hallucination mitigation to heavier adversarial methods is achieved with negligible extra latency.
- The approach generalizes across multiple vision-language model architectures and different decoding strategies.
Where Pith is reading between the lines
- If the phase structure generalizes, similar phase-aware suppression could be tested on other multimodal architectures such as audio-language or video-language models.
- Task-specific tuning of the suppression threshold might further improve results on visual reasoning benchmarks beyond captioning.
- Combining this focus-phase filter with encoder-level uncertainty methods could yield additive gains in hallucination control.
Load-bearing premise
The three-phase attention structure is consistent across LVLM backbones and decoding strategies, and suppressing low-attention tokens in the focus phase reduces hallucinations without introducing new errors or degrading visual reasoning capabilities.
What would settle it
Apply the suppression method to an untested LVLM backbone, verify whether the diffusion-focus-rediffusion phases remain identifiable, and check if hallucination rates drop without loss in caption quality or introduction of new errors.
Figures




















read the original abstract
Large Vision-Language Models (LVLMs) have achieved impressive progress in multimodal reasoning, yet they remain prone to object hallucinations, generating descriptions of objects that are not present in the input image. Recent approaches attempt to mitigate hallucinations by suppressing unreliable visual signals in the vision encoder, but many rely on iterative optimization for each input, resulting in substantial inference latency. In this work, we investigate the internal attention dynamics of vision encoders in LVLMs and identify a consistent three-phase structure of visual information processing: diffusion, focus, and rediffusion. Our analysis reveals that hallucination behavior is particularly sensitive to tokens receiving low attention during the focus phase. Motivated by this observation, we propose a lightweight inference-time intervention that selectively suppresses such tokens during the focus phase. The method operates in a training-free manner using statistics from a single forward pass and employs a Determinantal Point Process (DPP) to preserve diverse visual cues while filtering redundant tokens. Extensive experiments across multiple LVLM backbones and decoding strategies demonstrate that the proposed approach consistently reduces hallucination metrics while maintaining competitive caption quality. Moreover, compared to adversarial uncertainty estimation methods, our approach achieves comparable hallucination mitigation with negligible additional inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision encoders in LVLMs exhibit a consistent three-phase attention structure (diffusion, focus, rediffusion) identifiable from a single forward pass. Hallucination behavior is particularly sensitive to low-attention tokens during the focus phase. The authors introduce a training-free inference-time intervention that applies Determinantal Point Process (DPP) suppression to those tokens in the focus phase, reporting consistent reductions in hallucination metrics while preserving caption quality across multiple backbones and decoding strategies, with negligible added latency compared to optimization-based baselines.
Significance. If the phase structure and intervention prove robust, the work offers a practical, efficient advance in hallucination mitigation for LVLMs. Notable strengths include the training-free design, reliance on single-forward-pass input statistics rather than iterative optimization, and the use of DPP to preserve visual diversity, which supports competitive caption quality.
major comments (2)
- [§3] The demarcation of the focus phase lacks a formal, reproducible definition. No explicit criterion (e.g., layer range, attention entropy threshold, or head selection rule) is stated for identifying the focus phase from the attention maps computed in a single forward pass, rendering the central mechanism difficult to verify or transfer.
- [§4] The experimental claims of consistent gains across backbones rest on reported metric reductions, but the manuscript provides insufficient detail on statistical significance testing, run-to-run variance, and uniform application of data exclusion rules, which are necessary to substantiate the robustness assertions.
minor comments (2)
- [Figure 2] Attention visualizations would be clearer with explicit annotations marking the identified phase boundaries.
- A brief limitations paragraph discussing cases where the three-phase structure may not hold would improve completeness.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and statistical detail where appropriate.
read point-by-point responses
-
Referee: [§3] The demarcation of the focus phase lacks a formal, reproducible definition. No explicit criterion (e.g., layer range, attention entropy threshold, or head selection rule) is stated for identifying the focus phase from the attention maps computed in a single forward pass, rendering the central mechanism difficult to verify or transfer.
Authors: We agree that an explicit, reproducible definition is required. The phases were identified by consistent patterns in per-layer attention entropy computed from a single forward pass, with the focus phase corresponding to the middle layers exhibiting a sharp drop in entropy relative to early (diffusion) and late (rediffusion) layers. In the revision we will add a formal criterion: the focus phase is the contiguous layer range where normalized attention entropy falls below 0.5 and remains stable across heads (averaged over all heads). We will include pseudocode in §3 and report the exact layer indices per backbone for verification. revision: yes
-
Referee: [§4] The experimental claims of consistent gains across backbones rest on reported metric reductions, but the manuscript provides insufficient detail on statistical significance testing, run-to-run variance, and uniform application of data exclusion rules, which are necessary to substantiate the robustness assertions.
Authors: We acknowledge that additional statistical reporting is needed to support the robustness claims. The original experiments used fixed random seeds and followed the standard data splits and exclusion rules of POPE and CHAIR without further filtering. In the revision we will report standard deviations over three independent runs for all metrics, include p-values from paired t-tests for claimed improvements, and explicitly state the data exclusion protocol in §4. These additions will be placed in the experimental results tables and text. revision: yes
Circularity Check
No significant circularity; derivation is empirical observation plus direct intervention
full rationale
The paper identifies a three-phase attention structure via direct analysis of internal dynamics from a single forward pass on the input, then applies a DPP-based suppression motivated by that observation. No step reduces by construction to a fitted parameter, self-referential definition, or load-bearing self-citation chain. The intervention uses per-input statistics and does not rename known results or smuggle ansatzes. The central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- low-attention threshold
axioms (1)
- domain assumption Vision encoders in LVLMs exhibit a consistent three-phase attention structure (diffusion, focus, rediffusion) across inputs and models.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we identify a consistent three-phase structure of visual information processing: diffusion, focus, and rediffusion... hallucination behavior is particularly sensitive to tokens receiving low attention during the focus phase
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The method operates in a training-free manner using statistics from a single forward pass and employs a Determinantal Point Process (DPP)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023)2(3), 6 (2023)
work page 2023
-
[5]
In: The Twelfth International Conference on Learning Representations (2024)
Chuang, Y.S., Xie, Y., Luo, H., Kim, Y., Glass, J.R., He, P.: Dola: Decoding by contrasting layers improves factuality in large language models. In: The Twelfth International Conference on Learning Representations (2024)
work page 2024
-
[6]
The Ninth International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. The Ninth International Conference on Learning Representations (2021)
work page 2021
-
[7]
In: Findings of the Association for Computational Linguistics: ACL 2025
Fu, Y., Xie, R., Sun, X., Kang, Z., Li, X.: Mitigating hallucination in multimodal large language model via hallucination-targeted direct preference optimization. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 16563– 16577 (2025)
work page 2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13418–13427 (2024)
work page 2024
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, Z., Chen, J., Zhu, B., Luo, T., Shen, Y., Yang, X.: Devils in middle lay- ers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25004–25014 (2025)
work page 2025
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13872–13882 (2024)
work page 2024
-
[11]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, X., Wen, J.R.: Evaluating object hallu- cination in large vision-language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 292–305. Association for Computational Linguistics (2023)
work page 2023
-
[12]
Liu, H., Xue, W., Chen, Y., Chen, D., Zhao, X., Wang, K., Hou, L., Li, R., Peng, W.: A survey on hallucination in large vision-language models (2024)
work page 2024
-
[13]
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2023)
work page 2023
-
[14]
In: NeurIPS (2023) 16 Kim et al
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023) 16 Kim et al
work page 2023
-
[15]
In: European Conference on Com- puter Vision
Liu, S., Zheng, K., Chen, W.: Paying more attention to image: A training-free method for alleviating hallucination in lvlms. In: European Conference on Com- puter Vision. pp. 125–140. Springer (2024)
work page 2024
-
[16]
Advances in Applied Probability7(1), 83–122 (1975)
Macchi, O.: The coincidence approach to stochastic point processes. Advances in Applied Probability7(1), 83–122 (1975)
work page 1975
-
[17]
The Sixth International Conference on Learning Representations (2017)
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. The Sixth International Conference on Learning Representations (2017)
work page 2017
-
[18]
In: Proceedings of the 38th International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. pp. 8748–8763. PMLR (2021)
work page 2021
-
[19]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045 (2018)
work page 2018
-
[20]
Advances in neural information processing systems (2025)
Seo, H., Kang, D.U., Cho, H., Lee, J., Chun, S.Y.: On epistemic uncertainty of visual tokens for object hallucinations in large vision-language models. Advances in neural information processing systems (2025)
work page 2025
-
[21]
In: Findings of the Association for Computational Linguistics: ACL 2024
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.X., Yang, Y., et al.: Aligning large multimodal models with factually augmented rlhf. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 13088–13110 (2024)
work page 2024
-
[22]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y., Wu, C., Wang, B., Xie, Z., Wu, Y., Hu, K., Wang, J., Sun, Y., Li, Y., Piao, Y., Guan, K., Liu, A., Xie, X., You, Y., Dong, K., Yu, X., Zhang, H., Zhao, L., Wang, Y., Ruan, C.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding (2024)
work page 2024
-
[25]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Xie, Y., Li, G., Xu, X., Kan, M.Y.: V-dpo: Mitigating hallucination in large vision language models via vision-guided direct preference optimization. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 13258–13273 (2024)
work page 2024
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Z., Luo, X., Han, D., Xu, Y., Li, D.: Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10610– 10620 (2025)
work page 2025
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
work page 2023
-
[28]
Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization,
Zhao, Z., Wang, B., Ouyang, L., Dong, X., Wang, J., He, C.: Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839 (2023) Focus Matters 17 Organization of the Supplementary Thissupplementarymaterialprovidesadditionaltechnicaldetails,extendedanal- yses, and qualitative results that...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.