Recognition: 2 theorem links
· Lean TheoremStabilizing Unsupervised Self-Evolution of MLLMs via Continuous Softened Retracing reSampling
Pith reviewed 2026-05-13 17:43 UTC · model grok-4.3
The pith
CSRS improves MLLM self-evolution stability by using retracing mechanisms and softened continuous rewards instead of majority voting, reaching SOTA on geometric reasoning benchmarks like MathVision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experimental results demonstrate that CSRS significantly enhances the reasoning performance of Qwen2.5-VL-7B on benchmarks such as MathVision. We achieve state-of-the-art (SOTA) results in unsupervised self-evolution on geometric tasks.
Load-bearing premise
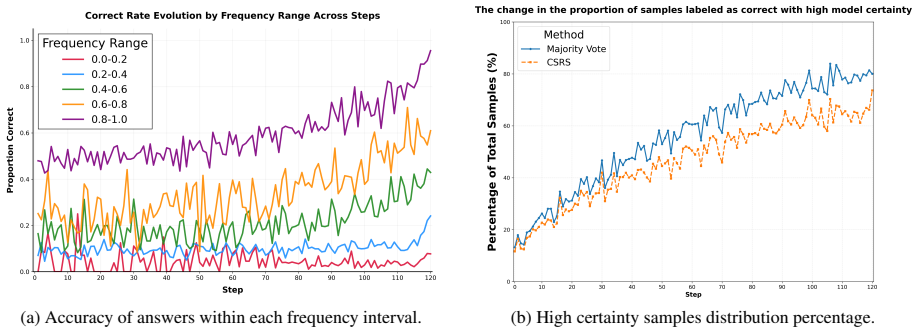
The assumption that frequency of answers across sampled reasoning paths (even after softening) reliably indicates objective correctness rather than shared model biases, combined with the claim that visual semantic perturbation successfully shifts focus to mathematical logic.
Figures




read the original abstract
In the unsupervised self-evolution of Multimodal Large Language Models, the quality of feedback signals during post-training is pivotal for stable and effective learning. However, existing self-evolution methods predominantly rely on majority voting to select the most frequent output as the pseudo-golden answer, which may stem from the model's intrinsic biases rather than guaranteeing the objective correctness of the reasoning paths. To counteract the degradation, we propose Continuous Softened Retracing reSampling (CSRS) in MLLM self-evolution. Specifically, we introduce a Retracing Re-inference Mechanism (RRM) that the model re-inferences from anchor points to expand the exploration of long-tail reasoning paths. Simultaneously, we propose Softened Frequency Reward (SFR), which replaces binary rewards with continuous signals, calibrating reward based on the answers' frequency across sampled reasoning sets. Furthermore, incorporated with Visual Semantic Perturbation (VSP), CSRS ensures the model prioritizes mathematical logic over visual superficiality. Experimental results demonstrate that CSRS significantly enhances the reasoning performance of Qwen2.5-VL-7B on benchmarks such as MathVision. We achieve state-of-the-art (SOTA) results in unsupervised self-evolution on geometric tasks. Our code is avaible at https://github.com/yyy195/CSRS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Continuous Softened Retracing reSampling (CSRS) to stabilize unsupervised self-evolution in multimodal LLMs. It introduces a Retracing Re-inference Mechanism (RRM) to expand exploration of long-tail reasoning paths, a Softened Frequency Reward (SFR) that replaces binary majority-voting rewards with continuous frequency-based signals, and Visual Semantic Perturbation (VSP) to reduce reliance on visual superficial cues in favor of mathematical logic. Experiments on Qwen2.5-VL-7B report significant gains on geometric reasoning benchmarks such as MathVision, reaching SOTA results for unsupervised self-evolution.
Significance. If the central empirical claims hold after proper controls, the work would offer a practical alternative to majority-voting self-training that mitigates model bias amplification. The combination of retracing sampling, continuous rewards, and targeted perturbation addresses a recognized weakness in current self-evolution pipelines for MLLMs on tasks requiring precise visual-mathematical alignment.
major comments (3)
- [Experimental Results / Abstract] The central claim that SFR supplies a more reliable training signal than majority voting rests on the unverified assumption that softened answer frequencies correlate with objective correctness rather than shared model biases. The manuscript provides no quantitative validation (e.g., Pearson correlation between SFR scores and ground-truth accuracy on a labeled subset of MathVision, or accuracy lift when training on SFR-selected vs. majority-voted paths).
- [Experimental Results] The paper asserts that VSP successfully shifts model focus from visual superficiality to mathematical logic, yet no ablation isolates the contribution of VSP (e.g., CSRS without VSP vs. full CSRS) or measures reduction in visual-error modes on geometric problems. Without these controls, the SOTA claim on MathVision cannot be attributed to the proposed mechanisms.
- [Experimental Results] No information is given on experimental controls: number of independent runs, statistical significance of reported gains, hyper-parameter sensitivity of the softening temperature in SFR, or comparison against strong supervised baselines and recent self-evolution methods beyond majority voting.
minor comments (2)
- [Abstract] Abstract contains a typo: 'avaible' should be 'available'.
- [Method] Notation for RRM, SFR, and VSP is introduced without a clear summary table or diagram showing how the three components interact during a single training iteration.
Simulated Author's Rebuttal
Thank you for the valuable feedback. We address each major comment below and will update the manuscript accordingly to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Experimental Results / Abstract] The central claim that SFR supplies a more reliable training signal than majority voting rests on the unverified assumption that softened answer frequencies correlate with objective correctness rather than shared model biases. The manuscript provides no quantitative validation (e.g., Pearson correlation between SFR scores and ground-truth accuracy on a labeled subset of MathVision, or accuracy lift when training on SFR-selected vs. majority-voted paths).
Authors: We agree this validation is important. In the revised manuscript, we will add a quantitative analysis including the Pearson correlation between SFR scores and ground-truth accuracy on a labeled subset of MathVision, as well as performance comparison between SFR-selected and majority-voted paths to demonstrate the reliability of the softened reward signal. revision: yes
-
Referee: [Experimental Results] The paper asserts that VSP successfully shifts model focus from visual superficiality to mathematical logic, yet no ablation isolates the contribution of VSP (e.g., CSRS without VSP vs. full CSRS) or measures reduction in visual-error modes on geometric problems. Without these controls, the SOTA claim on MathVision cannot be attributed to the proposed mechanisms.
Authors: We will include an ablation study comparing CSRS with and without VSP in the revised version. We will also provide an analysis of error modes on geometric problems to quantify the reduction in reliance on visual superficial cues, thereby isolating VSP's contribution. revision: yes
-
Referee: [Experimental Results] No information is given on experimental controls: number of independent runs, statistical significance of reported gains, hyper-parameter sensitivity of the softening temperature in SFR, or comparison against strong supervised baselines and recent self-evolution methods beyond majority voting.
Authors: The revised manuscript will report the number of independent runs (with statistical significance via t-tests), include hyper-parameter sensitivity analysis for the SFR softening temperature, and add comparisons to additional self-evolution methods. For supervised baselines, we will include them where relevant to contextualize the unsupervised gains. revision: partial
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper defines CSRS via three new mechanisms (RRM for re-inference from anchors, SFR for continuous frequency-based rewards, VSP for visual perturbation) without any equations or claims reducing to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. Frequency signals are external observations across samples, not internal to the model output by construction. Performance is validated on external benchmarks (MathVision), so the chain does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frequency of sampled answers correlates with objective correctness after softening
- domain assumption Visual semantic perturbation successfully decouples reasoning from superficial image features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Softened Frequency Reward (SFR)... Rf_final = (γ tanh(β (fr/fbase + ϵ - 1)) + 1) × Rbase ... GSR = exp(η(ρ - ϵ)) < GMV = exp(η)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Continuous Rewards as a Stabilizer Compared to 0-1 Rewards... exponential self-reinforcement process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Direct preference optimization: Y our lan- guage model is secretly a reward model. Advances in neural information processing systems, 36:53728– 53741. 9 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. SentenceTransformers. 2024. all-minilm-l6-v2....
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
The curse of recursion: Training on gen- erated data makes models forget. arXiv preprint arXiv:2305.17493. Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhi- wei Steven Wu, and J Andrew Bagnell. 2025. All roads lead to likelihood: The value of rein- forcement learning in fine-tuning. arXiv preprint arXiv:2503.01067. Omkar Thawakar, Shravan V enkatraman, Ritesh...
-
[3]
arXiv preprint arXiv:2509.16456
Gpo: Learning from critical steps to improve llm reasoning. arXiv preprint arXiv:2509.16456. Jihun Y un, Juno Kim, Jongho Park, Junhyuck Kim, Jongha Jon Ryu, Jaewoong Cho, and Kwang-Sung Jun. 2025. Alignment as Distribution Learning: Y our Preference Model is Explicitly a Language Model. arXiv preprint. ArXiv:2506.01523 [cs]. Renrui Zhang, Dongzhi Jiang, ...
-
[4]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Springer. Andrew Zhao, Yiran Wu, Y ang Y ue, Tong Wu, Quentin Xu, Y ang Y ue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. 2025. Absolute Zero: Reinforced Self-play Reasoning with Zero Data . arXiv preprint. ArXiv:2505.03335 [cs]. Y ujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Y u, Kishan Panaganti, Linfeng Song, Dian Y u, Xi- angl...
work page internal anchor Pith review arXiv 2025
-
[5]
Maternal Rollouts for Problem Maternal Response 1 : To find angle BDA, we note that the inscribed angle BDC intercepts arc CB (94◦), so ∠BDC = 47 ◦. Since AB ∥ DC , ∠BDA = ∠BDC . Therefore, ∠BDA = 47 ◦. Maternal Response 2 : Using cyclic quadrilateral properties, ∠BCA intercepts arc CB , so ∠BCA = 47◦. Opposite angles in a cyclic quadrilateral sum to 180◦,...
-
[6]
The inscribed angle BDA subtends the same arc BA
Cut rollouts for Problem Re-inference Response 9 : The central angle BZA is given as 104◦. The inscribed angle BDA subtends the same arc BA. By the inscribed angle theorem, ∠BDA = 1 2 · ∠BZA = 52 ◦. The parallel lines con- dition is not needed for this calculation. Re-inference Response 15 : The reasoning is as fol- lows: The central angle BZA is 104◦. Si...
-
[7]
Maternal Rollout Example prompt:"system Y ou are a helpful assistant. user For the pair of similar figures, use the given areas to find x. Y ou FIRST think about the reasoning process as an internal monologue and then provide the final an- swer. The reasoning process MUST BE enclosed within <think> </think> tags. The final answer MUST BE put in \\boxed.assist...
-
[8]
Solving for k, we get k = \sqrt{\frac{50}{72}} = \sqrt{\frac{25}{36}} = \frac{5}{6} . 7. The side length x corresponds to the smaller figure, and the side length of the larger figure is 6 inches. 8. Therefore, x = 6 times \frac{5}{6} = 5 . So, the value of x is 5 inches.</think> \\boxed{5}"
-
[9]
Retracing Rollout Example prompt:"system Y ou are a helpful assistant. user Find x. Assume that segments that appear to be tangent are tangent. Y ou FIRST think about the reasoning process as an internal monologue and then provide the final answer. The reasoning process MUST BE enclosed 14 within <think> </think> tags. The final answer MUST BE put in \\boxe...
-
[10]
Bad Cases Concatenated Prompt: Y ou are a helpful assistant. user. Find J L, if KP = 4 and P M = 7 . Y ou FIRST think about the reasoning process as an internal mono- logue and then provide the final answer. The reasoning process MUST BE enclosed within <think> </think> tags. The final answer MUST BE put in \boxed{}. In the diagram, we have a kite shape wit...
-
[11]
22 Incorrect Response 4: Assuming symmetry incorrectly leads to J L = KP = 4, then the full diagonal length is doubled: J L = 2 × 4 = 8 . 8 15 Question:Quadrilateral $A B C D$ is inscribed in $\odot Z$ such that $m \angle B Z A=104, m \widehat{C B}=94,$ and $\overline{A B} \| \overline{D C} .$ Find $m \angle B D A$ Answer:52 Maternal Response 1: To find a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.