Recognition: 2 theorem links
· Lean TheoremOP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
Pith reviewed 2026-05-13 16:41 UTC · model grok-4.3
The pith
Off-policy GRPO reaches comparable flow-matching generation quality using 34 percent of the original training steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OP-GRPO is the first off-policy GRPO framework for flow-matching models. It selects high-quality trajectories and stores them in a replay buffer for reuse, applies sequence-level importance sampling to correct distribution shift while preserving GRPO clipping, and truncates late denoising steps that produce ill-conditioned ratios. These changes allow the method to deliver comparable or superior performance to on-policy Flow-GRPO while using only 34.2 percent of the training steps on average across image and video generation tasks.
What carries the argument
Sequence-level importance sampling correction together with adaptive replay-buffer reuse and truncation of late denoising steps, which together stabilize off-policy updates without breaking the original GRPO clipping mechanism.
If this is right
- Trajectory reuse through the replay buffer directly reduces the number of new samples that must be generated per iteration.
- The importance sampling correction keeps policy updates stable even when old trajectories are drawn from a different distribution.
- Truncation at late steps removes the main source of unstable ratios while the retained early steps still provide sufficient signal for quality improvement.
- The same efficiency pattern holds for both image and video flow-matching models without architecture changes.
- Total wall-clock training time drops substantially while output quality stays the same or improves.
Where Pith is reading between the lines
- The replay-buffer approach could be combined with other on-policy reinforcement methods in generative modeling to gain similar sample-efficiency gains.
- Truncating late steps may apply to diffusion models or other iterative generative processes where final steps also produce high-variance corrections.
- Selecting which trajectories enter the replay buffer could be made more adaptive by using quality scores computed from the current policy.
- The framework opens the door to scaling post-training of flow models to larger datasets where on-policy sampling would otherwise become prohibitive.
Load-bearing premise
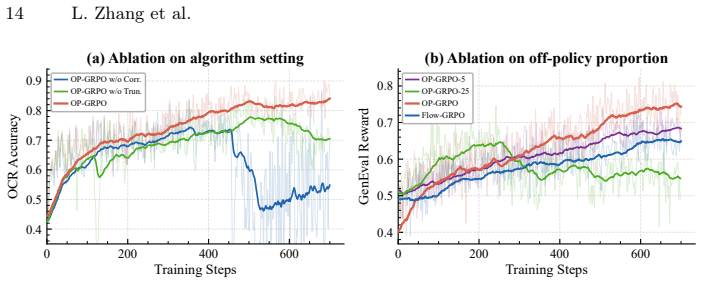
That truncating late denoising steps removes only ill-conditioned importance ratios without discarding information essential to the policy update.
What would settle it
Running the identical OP-GRPO procedure on the same image and video benchmarks but without the late-step truncation, then measuring whether generation quality falls or training variance rises sharply due to ill-conditioned ratios.
Figures
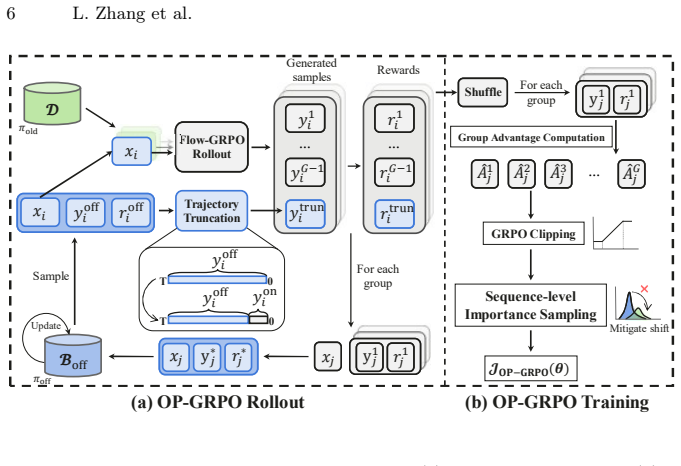

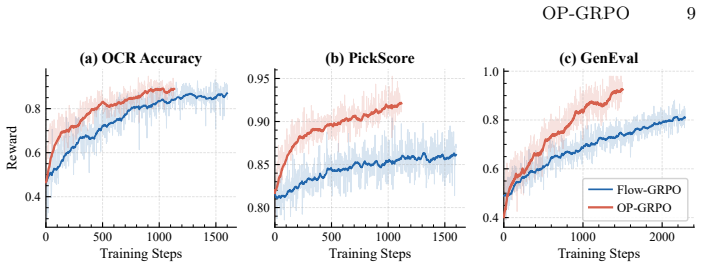
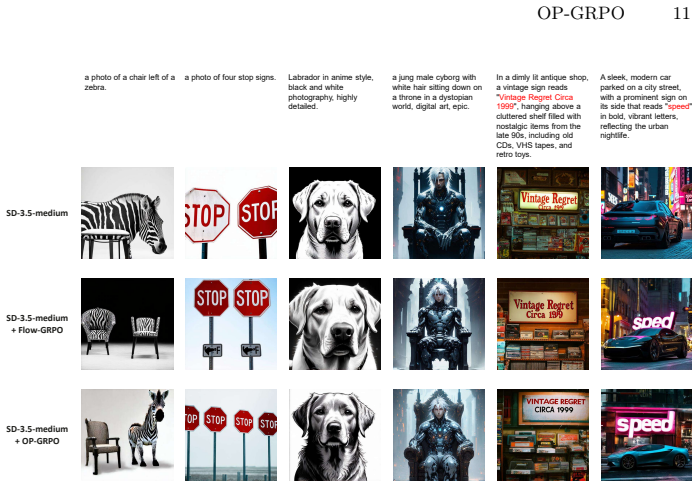

read the original abstract
Post training via GRPO has demonstrated remarkable effectiveness in improving the generation quality of flow-matching models. However, GRPO suffers from inherently low sample efficiency due to its on-policy training paradigm. To address this limitation, we present OP-GRPO, the first Off-Policy GRPO framework tailored for flow-matching models. First, we actively select high-quality trajectories and adaptively incorporate them into a replay buffer for reuse in subsequent training iterations. Second, to mitigate the distribution shift introduced by off-policy samples, we propose a sequence-level importance sampling correction that preserves the integrity of GRPO's clipping mechanism while ensuring stable policy updates. Third, we theoretically and empirically show that late denoising steps yield ill-conditioned off-policy ratios, and mitigate this by truncating trajectories at late steps. Across image and video generation benchmarks, OP-GRPO achieves comparable or superior performance to Flow-GRPO with only 34.2% of the training steps on average, yielding substantial gains in training efficiency while maintaining generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OP-GRPO, an off-policy extension of GRPO for post-training flow-matching models. It uses a replay buffer to select and reuse high-quality trajectories, proposes sequence-level importance sampling to handle off-policy distribution shift while aiming to preserve GRPO's clipping, and truncates late denoising steps to avoid ill-conditioned importance ratios. The central empirical claim is that OP-GRPO matches or exceeds Flow-GRPO performance on image and video benchmarks using only 34.2% of the training steps on average.
Significance. If the theoretical guarantees and empirical results hold, particularly the preservation of clipping under sequence-level corrections and the validity of truncation, this work could substantially improve the efficiency of RL-based post-training for generative models, reducing the computational burden for high-quality image and video generation.
major comments (3)
- [sequence-level importance sampling correction] The claim that sequence-level importance sampling preserves GRPO's clipping mechanism (described in the proposed method) requires rigorous verification. Under the continuous trajectory distribution of flow-matching models, an averaged sequence-level ratio can mask per-step spikes that would have triggered clipping on-policy; if this occurs, the stability mechanism central to GRPO is violated. Please provide the exact estimator form and either a proof of equivalence or an analysis showing when the clipping semantics are retained.
- [truncation rule for late steps] The truncation of late denoising steps is motivated by ill-conditioned ratios, but the manuscript does not quantify the bias this introduces into the policy update or demonstrate that essential gradient information is not lost. An ablation comparing truncated vs. full trajectories on a controlled benchmark is needed to confirm that the efficiency gain does not come at the cost of degraded final performance.
- [experimental results] The headline efficiency result (34.2% of training steps with comparable or superior quality) is reported as an average across benchmarks, but the supporting tables or figures lack per-benchmark breakdowns, standard deviations, and statistical tests. Without these, it is impossible to assess whether the claim is robust or driven by a subset of tasks.
minor comments (1)
- [method overview] Notation for the importance weights and replay buffer selection criteria should be defined more explicitly with equations to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications, additional analysis, and revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [sequence-level importance sampling correction] The claim that sequence-level importance sampling preserves GRPO's clipping mechanism (described in the proposed method) requires rigorous verification. Under the continuous trajectory distribution of flow-matching models, an averaged sequence-level ratio can mask per-step spikes that would have triggered clipping on-policy; if this occurs, the stability mechanism central to GRPO is violated. Please provide the exact estimator form and either a proof of equivalence or an analysis showing when the clipping semantics are retained.
Authors: We agree rigorous verification is needed. The sequence-level ratio is defined as ρ(τ) = ∏_t π_θ(x_t|x_{t+1}) / π_θ_old(x_t|x_{t+1}), with clipping applied directly to this aggregated ratio in the GRPO surrogate objective (Eq. 7 in the manuscript). We will add the exact estimator form to Section 3.2 and include an appendix derivation showing that, under the deterministic flow ODE discretization, the product form bounds per-step deviations such that clipping semantics are retained whenever the per-step ratios remain positive and finite; an analysis of edge cases where equivalence holds will also be provided. revision: yes
-
Referee: [truncation rule for late steps] The truncation of late denoising steps is motivated by ill-conditioned ratios, but the manuscript does not quantify the bias this introduces into the policy update or demonstrate that essential gradient information is not lost. An ablation comparing truncated vs. full trajectories on a controlled benchmark is needed to confirm that the efficiency gain does not come at the cost of degraded final performance.
Authors: We will add the requested ablation on a controlled benchmark (CIFAR-10) in the revised experiments section. The new results will report the bias via KL divergence between truncated and full-trajectory gradients, gradient norm statistics, and final generation metrics, confirming that truncation at step T/2 introduces negligible bias while preserving performance and improving stability. revision: yes
-
Referee: [experimental results] The headline efficiency result (34.2% of training steps with comparable or superior quality) is reported as an average across benchmarks, but the supporting tables or figures lack per-benchmark breakdowns, standard deviations, and statistical tests. Without these, it is impossible to assess whether the claim is robust or driven by a subset of tasks.
Authors: We will expand the experimental results with per-benchmark tables showing individual metrics, standard deviations over 3 random seeds, and paired t-test p-values against Flow-GRPO. This will substantiate that the 34.2% average step reduction holds robustly across image and video tasks. revision: yes
Circularity Check
No significant circularity; derivation introduces independent algorithmic components
full rationale
The paper's core claims rest on three explicitly proposed components—replay buffer trajectory selection, sequence-level importance sampling correction, and late-step truncation—each described as adaptations of standard off-policy RL practices to the continuous trajectories of flow-matching models. Performance results are reported as direct empirical comparisons on image and video benchmarks (34.2% training steps with comparable quality), without any reduction of the efficiency metric to a fitted parameter, self-defined quantity, or self-citation chain. No equations or uniqueness theorems are shown that collapse the off-policy correction back onto on-policy GRPO by construction, and the clipping-preservation argument is presented as a theoretical and empirical verification rather than an input assumption. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Importance sampling can be applied at sequence level while preserving the clipping behavior of GRPO
- domain assumption Late denoising steps produce ill-conditioned off-policy ratios that can be safely truncated
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsequence-level importance sampling correction that preserves the integrity of GRPO’s clipping mechanism... Pπold(τ)/Pπoff(τ) = ∏ pθold(zi t−1|zi t,c)/pθoff(zi t−1|zi t,c)
Forward citations
Cited by 2 Pith papers
-
MotionGRPO: Overcoming Low Intra-Group Diversity in GRPO-Based Egocentric Motion Recovery
MotionGRPO models diffusion sampling as a Markov decision process optimized with Group Relative Policy Optimization, using hybrid rewards and noise injection to boost sample diversity and local joint precision in egoc...
-
MotionGRPO: Overcoming Low Intra-Group Diversity in GRPO-Based Egocentric Motion Recovery
MotionGRPO applies GRPO with noise injection and hybrid rewards to diffusion-based egocentric motion recovery, overcoming vanishing gradients from low intra-group diversity to reach state-of-the-art performance.
Reference graph
Works this paper leans on
-
[1]
Arkhipkin, V., Korviakov, V., Gerasimenko, N., Parkhomenko, D., Vasilev, V., Letunovskiy, A., Vaulin, N., Kovaleva, M., Kirillov, I., Novitskiy, L., Koposov, D., Kiselev, N., Varlamov, A., Mikhailov, D., Polovnikov, V., Shutkin, A., Agafonova, J., Vasiliev, I., Kargapoltseva, A., Dmitrienko, A., Maltseva, A., Averchenkova, A., Kim, O., Nikulina, T., Dimit...
-
[2]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Advances in Neural Information Processing Systems36, 9353–9387 (2023) 10
Chen, J., Huang, Y., Lv, T., Cui, L., Chen, Q., Wei, F.: Textdiffuser: Diffusion models as text painters. Advances in Neural Information Processing Systems36, 9353–9387 (2023) 10
work page 2023
-
[4]
Advances in neural information processing systems31(2018) 4
Chen, R.T., Rubanova, Y., Bettencourt, J., Duvenaud, D.K.: Neural ordinary dif- ferential equations. Advances in neural information processing systems31(2018) 4
work page 2018
-
[5]
In: Forty-first international conference on machine learning (2024) 1, 10, 13
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 1, 10, 13
work page 2024
-
[6]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2, 10
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2, 10
work page 2023
-
[7]
In: International conference on machine learning
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S.: Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor. In: International conference on machine learning. pp. 1861–1870. Pmlr (2018) 2
work page 2018
-
[8]
arXiv preprint arXiv:2511.16955 (2025) 3
He, D., Feng, G., Ge, X., Niu, Y., Zhang, Y., Ma, B., Song, G., Liu, Y., Li, H.: Neighbor grpo: Contrastive ode policy optimization aligns flow models. arXiv preprint arXiv:2511.16955 (2025) 3
-
[9]
Advances in neural information processing systems33, 6840–6851 (2020) 1, 4
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 1, 4
work page 2020
-
[10]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(5), 3563–3579 (2025) 12
Huang, K., Duan, C., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench++: An en- hanced and comprehensive benchmark for compositional text-to-image generation. IEEE Transactions on Pattern Analysis and Machine Intelligence47(5), 3563–3579 (2025) 12
work page 2025
-
[11]
Advances in Neural Information Processing Systems36, 78723–78747 (2023) 12
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems36, 78723–78747 (2023) 12
work page 2023
-
[12]
Advances in neural information processing systems36, 36652–36663 (2023) 2, 10, 11
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023) 2, 10, 11
work page 2023
-
[13]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024) 13
work page 2024
-
[14]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Li, J., Cui, Y., Huang, T., Ma, Y., Fan, C., Yang, M., Zhong, Z.: Mixgrpo: Unlock- ing flow-based grpo efficiency with mixed ode-sde. arXiv preprint arXiv:2507.21802 (2025) 3 OP-GRPO 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
arXiv preprint arXiv:2506.09340 (2025) 3
Li, S., Zhou, Z., Lam, W., Yang, C., Lu, C.: Repo: Replay-enhanced policy opti- mization. arXiv preprint arXiv:2506.09340 (2025) 3
-
[17]
arXiv preprint arXiv:2509.06040 (2025) 2, 3
Li, Y., Wang, Y., Zhu, Y., Zhao, Z., Lu, M., She, Q., Zhang, S.: Branchgrpo: Stable and efficient grpo with structured branching in diffusion models. arXiv preprint arXiv:2509.06040 (2025) 2, 3
-
[18]
arXiv preprint arXiv:2507.06892 (2025) 3
Liang, J., Tang, H., Ma, Y., Liu, J., Zheng, Y., Hu, S., Bai, L., Hao, J.: Squeeze the soaked sponge: Efficient off-policy reinforcement finetuning for large language model. arXiv preprint arXiv:2507.06892 (2025) 3
-
[19]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024) 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Liu, J., Li, Y., Fu, Y., Wang, J., Liu, Q., Shen, Y.: When speed kills stability: Demystifying RL collapse from the training-inference mismatch (Sep 2025),https: //richardli.xyz/rl-collapse4
work page 2025
-
[22]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 3
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., ZHANG, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 3
work page 2025
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Playing Atari with Deep Reinforcement Learning
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M.: Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 (2013) 2
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[26]
Advances in Neural Information Processing Systems36, 62244–62269 (2023) 6
Nakamoto, M., Zhai, S., Singh, A., Sobol Mark, M., Ma, Y., Finn, C., Kumar, A., Levine, S.: Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. Advances in Neural Information Processing Systems36, 62244–62269 (2023) 6
work page 2023
-
[27]
Advances in neural information processing sys- tems35, 27730–27744 (2022) 8
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022) 8
work page 2022
-
[28]
Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., Wang, Y., Ye, A., Ren, G., Ma, Q., Liang, W., Lian, X., Wu, X., Zhong, Y., Li, Z., Gong, C., Lei, G., Cheng, L., Zhang, L., Li, M., Zhang, R., Hu, S., Huang, S., Wang, X., Zhao, Y., Wang, Y., Wei, Z., You, Y.: Open-sora 2.0: Training a commercial-level video g...
-
[29]
Schuhmann, C.: Laion aesthetics (Aug 2022) 11
work page 2022
-
[30]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017) 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., Wu, C.: Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
In: International conference on machine learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: International conference on machine learning. pp. 2256–2265. pmlr (2015) 1, 4 18 L. Zhang et al
work page 2015
-
[33]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[34]
arXiv preprint arXiv:2210.06718 (2022) 6
Song, Y., Zhou, Y., Sekhari, A., Bagnell, J.A., Krishnamurthy, A., Sun, W.: Hy- brid rl: Using both offline and online data can make rl efficient. arXiv preprint arXiv:2210.06718 (2022) 6
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024) 1
work page 2024
-
[36]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
arXiv preprint arXiv:2602.20722 (2026) 3
Wan, X., Wang, Y., Huang, W., Sun, M.: Buffer matters: Unleashing the power of off-policy reinforcement learning in large language model reasoning. arXiv preprint arXiv:2602.20722 (2026) 3
-
[38]
arXiv preprint arXiv:2510.22319 (2025) 3
Wang, J., Liang, J., Liu, J., Liu, H., Liu, G., Zheng, J., Pang, W., Ma, A., Xie, Z., Wang, X., et al.: Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping. arXiv preprint arXiv:2510.22319 (2025) 3
-
[39]
Unified Reward Model for Multimodal Understanding and Generation
Wang, Y., Zang, Y., Li, H., Jin, C., Wang, J.: Unified reward model for multimodal understanding and generation. arXiv preprint arXiv:2503.05236 (2025) 11
work page internal anchor Pith review arXiv 2025
-
[40]
Machine learning8(3), 279–292 (1992) 2
Watkins, C.J., Dayan, P.: Q-learning. Machine learning8(3), 279–292 (1992) 2
work page 1992
-
[41]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 1, 11
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 1, 11
work page 2023
-
[44]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025) 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Yang, X., Chen, C., yang, x., Liu, F., Lin, G.: Text-to-image rectified flow as plug-and-play priors. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Learning Representations. vol. 2025, pp. 13896– 13920 (2025),https://proceedings.iclr.cc/paper_files/paper/2025/file/ 2460396f2d0d421885997dd1612ac56b-Paper-Conference.pdf1
work page 2025
-
[46]
In: Proceedings of OP-GRPO 19 the Computer Vision and Pattern Recognition Conference
You, Z., Cai, X., Gu, J., Xue, T., Dong, C.: Teaching large language models to regress accurate image quality scores using score distribution. In: Proceedings of OP-GRPO 19 the Computer Vision and Pattern Recognition Conference. pp. 14483–14494 (2025) 11
work page 2025
-
[47]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Zhao,Y.,Gu,A.,Varma,R.,Luo,L.,Huang,C.C.,Xu,M.,Wright,L.,Shojanazeri, H., Ott, M., Shleifer, S., et al.: Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
arXiv preprint arXiv:2510.01982 (2025) 3
Zhou, Y., Ling, P., Bu, J., Wang, Y., Zang, Y., Wang, J., Niu, L., Zhai, G.: Fine-grained grpo for precise preference alignment in flow models. arXiv preprint arXiv:2510.01982 (2025) 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.