Recognition: no theorem link
MotionGRPO: Overcoming Low Intra-Group Diversity in GRPO-Based Egocentric Motion Recovery
Pith reviewed 2026-05-13 07:47 UTC · model grok-4.3
The pith
MotionGRPO improves full-body motion recovery from head-mounted signals by using noise injection to fix low intra-group diversity in GRPO optimization of diffusion sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling diffusion sampling as a Markov decision process and optimizing it via Group Relative Policy Optimization (GRPO) with a hybrid reward for global plausibility and local joint precision, MotionGRPO overcomes vanishing gradients caused by low intra-group sample diversity through a noise-injection strategy that explicitly increases sample variance and stabilizes learning, yielding state-of-the-art performance in egocentric motion recovery.
What carries the argument
Group Relative Policy Optimization (GRPO) applied to diffusion sampling as an MDP, augmented by a noise-injection strategy that raises intra-group sample variance and a hybrid reward combining perceptual and joint constraints.
If this is right
- The hybrid reward produces motions with both global visual plausibility and precise local joint positions.
- Noise injection prevents vanishing gradients during policy optimization of the diffusion process.
- The resulting framework outperforms prior diffusion-only methods on visual fidelity metrics for egocentric recovery.
- Treating sampling as an MDP allows reinforcement learning to supply fine-grained control signals inside the diffusion loop.
Where Pith is reading between the lines
- The same diversity-injection tactic could apply to other diffusion models that rely on group-based policy optimization for generation tasks.
- Better local accuracy from head-mounted signals may improve downstream uses such as real-time avatar control in virtual environments.
- Varying the noise schedule during training could reveal whether the stabilization benefit holds across different motion speeds or action types.
Load-bearing premise
The added noise increases useful sample variance in a way that stabilizes GRPO learning without introducing artifacts that harm motion quality or joint accuracy.
What would settle it
Experiments that measure intra-group sample diversity and gradient norms before and after noise injection, showing no increase in diversity or reduction in vanishing gradients while motion reconstruction quality stays the same or worsens.
Figures




read the original abstract
This paper studies full-body 3D human motion recovery from head-mounted device signals. Existing diffusion-based methods often rely on global distribution matching, leading to local joint reconstruction errors. We propose MotionGRPO, a novel framework leveraging reinforcement learning post-training to inject fine-grained guidance into the diffusion process. Technically, we model diffusion sampling as a Markov decision process optimized via Group Relative Policy Optimization (GRPO). To this end, we introduce a hybrid reward mechanism that combines a learned conditioned perceptual model for global visual plausibility and explicit constraints for local joint precision. Our key technical insight is that policy optimization in diffusion-based recovery suffers from vanishing gradients due to limited intra-group sample diversity. To address this, we further introduce a noise-injection strategy that explicitly increases sample variance and stabilizes learning. Extensive experiments demonstrate that MotionGRPO achieves state-of-the-art performance with superior visual fidelity
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MotionGRPO, a reinforcement learning post-training framework for full-body 3D human motion recovery from head-mounted device signals. It models diffusion sampling as a Markov decision process optimized via Group Relative Policy Optimization (GRPO), introduces a hybrid reward combining a learned perceptual model for global plausibility with explicit joint constraints, and adds a noise-injection strategy to counteract vanishing gradients from low intra-group sample diversity, claiming state-of-the-art results with improved visual fidelity and local accuracy.
Significance. If the central claims hold, the work offers a targeted way to stabilize policy optimization in diffusion-based motion recovery by explicitly increasing sample variance, which could reduce local joint errors that arise from global distribution matching. The hybrid reward and noise-injection ideas have potential applicability to other RL-augmented diffusion pipelines in egocentric vision and AR/VR motion estimation.
major comments (2)
- [Abstract / Technical Insight] The key technical insight (Abstract) asserts that GRPO policy optimization suffers vanishing gradients specifically due to limited intra-group sample diversity and that noise injection increases useful variance to stabilize learning, yet the manuscript contains no measurements of gradient norms, intra-group motion variance, or diversity statistics before versus after injection to verify this diagnosis.
- [Experiments] Experiments report SOTA quantitative and qualitative gains but provide no ablation studies or tables isolating the noise-injection component from the hybrid reward; without these, it remains possible that observed improvements derive entirely from the reward design rather than the claimed diversity mechanism.
minor comments (1)
- [Abstract] The final sentence of the abstract is truncated at 'superior visual fidelity'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our technical contributions. We address each major point below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract / Technical Insight] The key technical insight (Abstract) asserts that GRPO policy optimization suffers vanishing gradients specifically due to limited intra-group sample diversity and that noise injection increases useful variance to stabilize learning, yet the manuscript contains no measurements of gradient norms, intra-group motion variance, or diversity statistics before versus after injection to verify this diagnosis.
Authors: We acknowledge that the current manuscript lacks explicit quantitative measurements of gradient norms, intra-group motion variance, or diversity statistics. In the revised version, we will add a dedicated analysis subsection (with supporting figures in the appendix) that reports these statistics before and after noise injection, along with gradient norm curves across training steps. This will provide direct empirical verification of the vanishing-gradient diagnosis and the stabilizing effect of the proposed strategy. revision: yes
-
Referee: [Experiments] Experiments report SOTA quantitative and qualitative gains but provide no ablation studies or tables isolating the noise-injection component from the hybrid reward; without these, it remains possible that observed improvements derive entirely from the reward design rather than the claimed diversity mechanism.
Authors: We agree that isolating the contribution of noise injection is necessary to substantiate the central claim. The revised manuscript will include new ablation experiments and tables that compare four variants: (1) full MotionGRPO, (2) hybrid reward only (no noise injection), (3) noise injection only (with a baseline reward), and (4) neither component. These results will quantify the incremental gains attributable to the diversity mechanism. revision: yes
Circularity Check
No circularity: derivation extends GRPO/diffusion with independent components
full rationale
The manuscript models diffusion sampling as an MDP solved by GRPO, adds a hybrid reward (perceptual model + joint constraints), and introduces a noise-injection strategy motivated by an observed vanishing-gradient issue. No equations, self-citations, or definitions are provided that make the central claims (vanishing gradients from low intra-group diversity, or the noise fix) reduce to tautologies or to the fitted inputs by construction. The method is presented as an extension whose grounding is external to the target performance numbers; experiments are claimed to validate it. This is the normal case of a self-contained technical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training diffusion models with reinforcement learning
Black, K., Janner, M., Du, Y ., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. In International Conference on Learning Representations, volume 2024, pp. 4965–4987,
work page 2024
-
[3]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Engel, J., Somasundaram, K., Goesele, M., Sun, A., Gamino, A., Turner, A., Talattof, A., Yuan, A., Souti, B., Meredith, B., et al. Project aria: A new tool for egocentric multi-modal ai research.arXiv preprint arXiv:2308.13561,
work page internal anchor Pith review arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
What’s in the image? a deep-dive into the vision of vision language models
doi: 10.1109/CVPR52734.2025.01492. Liu, Y ., Zhang, K., Li, Y ., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y ., Sun, H., Gao, J., et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177,
-
[6]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Adhmr: Aligning diffusion-based human mesh recovery via direct prefer- ence optimization
Shen, W., Yin, W., Yang, X., Chen, C., Song, C., Cai, Z., Yang, L., Wang, H., and Lin, G. Adhmr: Aligning diffusion-based human mesh recovery via direct prefer- ence optimization. InInternational Conference on Ma- chine Learning, pp. 54632–54643. PMLR, 2025a. Shen, W., Zhang, G., Zhang, J., Feng, Y ., Yao, N., Zhang, X., and Wang, H. Smpl normal map is al...
-
[10]
DanceGRPO: Unleashing GRPO on Visual Generation
URL https://arxiv.org/abs/2505.07818. Yao, N., Zhang, G., Shen, W., Shu, J., Feng, Y ., and Wang, H. Multigo++: Monocular 3d clothed human reconstruc- tion via geometry-texture collaboration.arXiv preprint arXiv:2603.04993,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
Zhang, G., Shu, J., Yao, N., and Wang, H. Sat: Supervi- sor regularization and animation augmentation for two- process monocular texture 3d human reconstruction. In Proceedings of the 33rd ACM International Conference on Multimedia, pp. 10563–10572, 2025a. Zhang, G., Yao, N., Zhang, S., Zhao, H., Pang, G., Shu, J., and Wang, H. Multigo: Towards multi-leve...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zhang, Y ., Lv, N., Wang, T., and Dang, J. Fastgrpo: Accel- erating policy optimization via concurrency-aware specu- lative decoding and online draft learning.arXiv preprint arXiv:2509.21792, 2025c. Zhuang, Y ., Lv, J., Wen, H., Shuai, Q., Zeng, A., Zhu, H., Chen, S., Yang, Y ., Cao, X., and Liu, W. Idol: Instant photorealistic 3d human creation from a si...
-
[13]
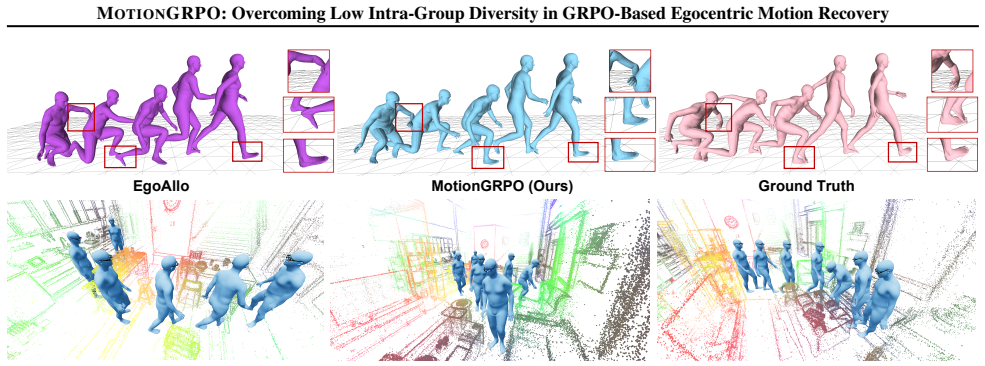
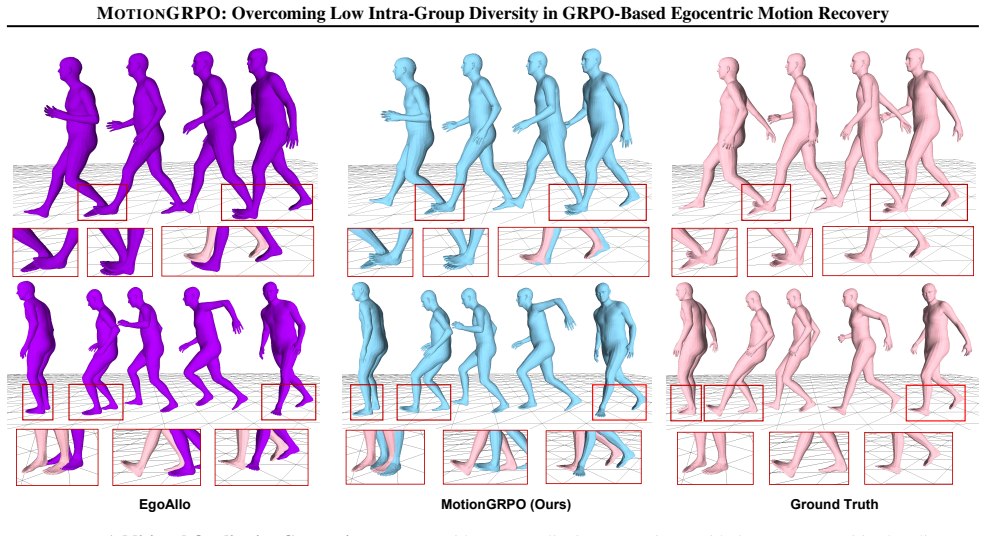
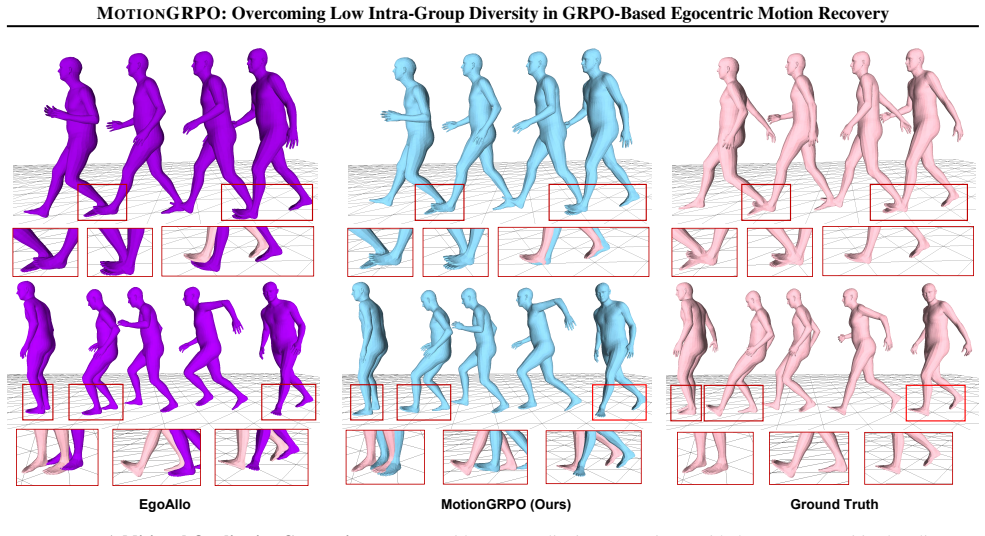
12 MOTIONGRPO: Overcoming Low Intra-Group Diversity in GRPO-Based Egocentric Motion Recovery EgoAllo MotionGRPO (Ours) Ground Truth Figure 5.Additional Qualitative Comparisons.We provide more qualitative comparisons with the most competitive baseline. A. Additional Qualitative Comparisons This section presents supplementary qualitative comparisons against...
work page 2025
-
[14]
The training process takes about 8GPU Hours and47.2GB VRAM. GRPO Training.In the post-training phase, we treat the diffusion sampling process as a multi-step MDP to optimize the pre-trained diffusion backbone. We initialize the policy model using the weights of the officially released checkpoint from EgoAllo (Yi et al., 2025). During training, our sequenc...
work page 2025
-
[15]
The post-training process takes about 72 GPU hours (∼2000 iteration, about 3 Epoches) and47.5GB VRAM. Inference.During inference, the model recovers full-body motion solely from raw head trajectory signals captured by HMDs. For AMASS, we follow the test splits of EgoAllo (Yi et al., 2025). For the RICH dataset, we utilize the standardized test splits, as ...
work page 2000
-
[16]
to ensure a fair and direct comparison with the current state-of-the-art. Specifically, the training set comprises a comprehensive collection of motion capture sub- sets, including “ACCAD”, “BMLhandball”, “BMLmovi”, “BioMotionLabNTroje”, “CMU”, “DFaust67”, “DanceDB”, “EKUT”, “Eyes Japan Dataset”, “KIT”, “MPI Limits”, “TCD handMocap”, and “TotalCapture”. F...
work page 2025
-
[17]
to enable physically consistent interactions with complex environments. 15 MOTIONGRPO: Overcoming Low Intra-Group Diversity in GRPO-Based Egocentric Motion Recovery Training Efficiency.The training process of GRPO involves a noticeable computational cost. While this algorithm effectively injects guidance, it requires the sampling of a diverse group of out...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.