Recognition: 2 theorem links
· Lean TheoremReinforce to Learn, Elect to Reason: A Dual Paradigm for Video Reasoning
Pith reviewed 2026-05-10 19:36 UTC · model grok-4.3
The pith
Training models to produce explicit evidence and electing answers by evidence consistency improves video reasoning reliability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
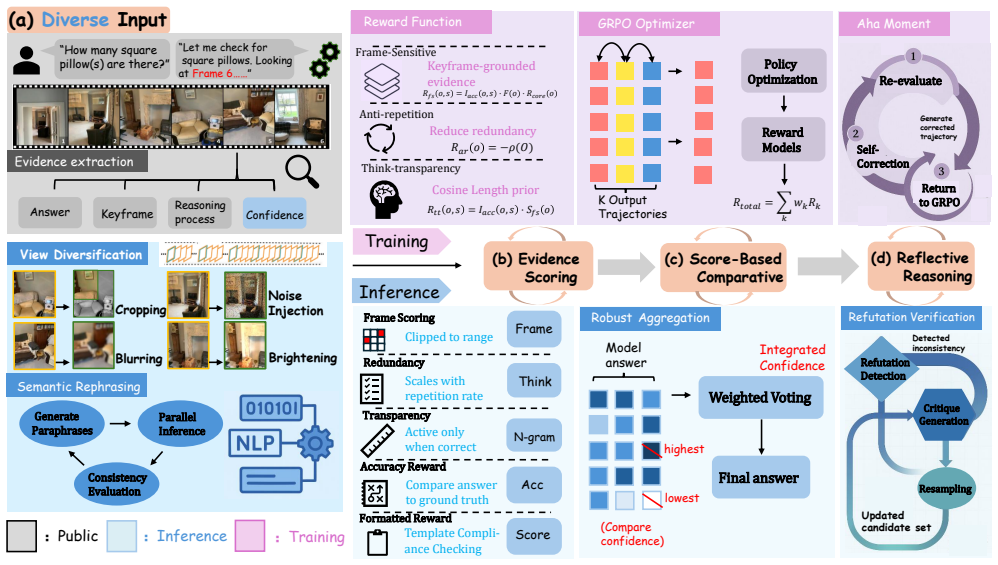
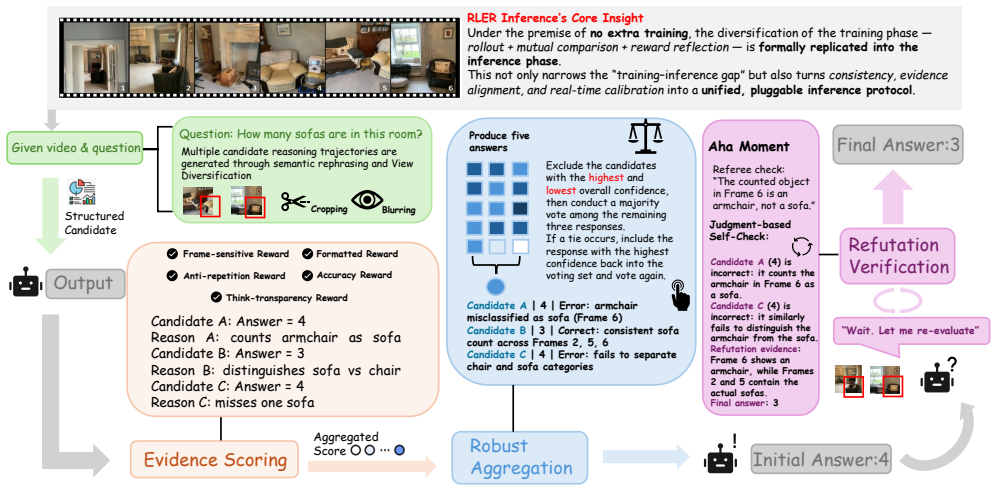
RLER decouples evidence production from answer selection by optimizing a policy during training with group-relative reinforcement learning plus three task-driven rewards that ground reasoning on key frames, enforce readable traces, and increase information density, then applying a train-free orchestrator at inference that generates diverse candidates, parses their cited frames and answers, scores them for evidence consistency and related criteria, and performs an evidence-weighted election, yielding state-of-the-art results across eight benchmarks with a 6.3 percent average gain over base models at an average cost of 3.1 candidates per question.
What carries the argument
The RLER dual paradigm of evidence-focused RL training with frame-sensitive, think-transparency, and anti-repetition rewards paired with an evidence-consistency orchestrator that elects among candidates at inference.
If this is right
- Models emit structured, machine-checkable reasoning that cites explicit frames.
- Inference quality rises while keeping the number of candidates low.
- Interpretability improves because elected answers rest on parsed evidence rather than opaque single-pass output.
- The same base model can be reused across benchmarks without retraining the orchestrator.
Where Pith is reading between the lines
- The separation of evidence training from evidence election could be tested on non-video multimodal tasks such as image or audio question answering to check transfer.
- Human raters could independently verify whether the frames and traces produced under the three rewards match actual video content more closely than standard outputs.
- The low candidate count suggests the method may scale to longer videos where exhaustive search becomes expensive.
- If the election step is removed at inference, performance would likely drop to base-model levels, isolating the contribution of evidence-weighted selection.
Load-bearing premise
The three novel rewards together with the evidence-consistency scoring truly drive alignment to video content rather than benchmark-specific fitting.
What would settle it
Running the trained model on a fresh set of video reasoning benchmarks drawn from sources outside the original evaluation suite and checking whether accuracy gains and cited-frame alignment hold.
Figures


read the original abstract
Video reasoning has advanced with large multimodal models (LMMs), yet their inference is often a single pass that returns an answer without verifying whether the reasoning is evidence-aligned. We introduce Reinforce to Learn, Elect to Reason (RLER), a dual paradigm that decouples learning to produce evidence from obtaining a reliable answer. In RLER-Training, we optimize the policy with group-relative reinforcement learning (RL) and 3 novel task-driven rewards: Frame-sensitive reward grounds reasoning on explicit key frames, Think-transparency reward shapes readable and parsable reasoning traces, and Anti-repetition reward boosts information density. These signals teach the model to emit structured, machine-checkable evidence and potentiate reasoning capabilities. In RLER-Inference, we apply a train-free orchestrator that generates a small set of diverse candidates, parses their answers and cited frames, scores them by evidence consistency, confidence, transparency, and non-redundancy, and then performs a robust evidence-weighted election. This closes the loop between producing and using evidence, improving reliability and interpretability without enlarging the model. We comprehensively evaluate RLER against various open-source and RL-based LMMs on 8 representative benchmarks. RLER achieves state of the art across all benchmarks and delivers an average improvement of 6.3\% over base models, while using on average 3.1 candidates per question, indicating a favorable balance between compute and quality. The results support a simple thesis: making evidence explicit during learning and electing by evidence during inference is a robust path to trustworthy video reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RLER (Reinforce to Learn, Elect to Reason), a dual-paradigm approach for video reasoning in large multimodal models. During training, group-relative reinforcement learning is applied using three novel rewards—Frame-sensitive, Think-transparency, and Anti-repetition—to encourage evidence-grounded, transparent, and dense reasoning traces. At inference, a train-free orchestrator generates multiple candidates, parses them for answers and frames, scores them on evidence consistency, confidence, transparency, and non-redundancy, and elects the final answer via evidence-weighted voting. The paper reports state-of-the-art performance on eight video reasoning benchmarks, with an average 6.3% improvement over base models while using only 3.1 candidates per question on average.
Significance. If the central claims hold, the work is significant for demonstrating that decoupling evidence production (via RL with task-driven rewards) from answer selection (via evidence-based election) can improve reliability and interpretability in video reasoning without scaling model size. The efficiency of the inference stage with few candidates is a practical strength. Credit is due for the train-free orchestrator design that balances compute and quality.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the reported 6.3% average gain and SOTA status are presented without ablation studies isolating the contribution of each of the three rewards or the four scoring criteria in the orchestrator. This is load-bearing for the central claim that the novel rewards and evidence-weighted election produce genuine alignment, as opposed to gains from generic RL or multi-candidate generation.
- [§3.2] §3.2 (Rewards) and §3.3 (Orchestrator): no equations, pseudocode, or hyperparameter details are supplied for the Frame-sensitive, Think-transparency, or Anti-repetition rewards, nor for the evidence-consistency scoring. Without these, it is impossible to verify whether the signals enforce verifiable video grounding or merely correlate with patterns in the eight evaluation benchmarks.
minor comments (2)
- [Abstract] The abstract states 'comprehensively evaluate' yet omits any reference to statistical tests, variance across runs, or error analysis; this should be added for clarity even if details appear in the full experimental section.
- [§3] Notation for the three rewards and the election scores is introduced without a consolidated table or consistent symbols across sections, which hinders readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate the requested details and analyses, thereby strengthening the verifiability of our contributions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the reported 6.3% average gain and SOTA status are presented without ablation studies isolating the contribution of each of the three rewards or the four scoring criteria in the orchestrator. This is load-bearing for the central claim that the novel rewards and evidence-weighted election produce genuine alignment, as opposed to gains from generic RL or multi-candidate generation.
Authors: We acknowledge that the absence of component-wise ablations limits the strength of our claims regarding the specific value of the proposed rewards and scoring criteria. The current results emphasize end-to-end gains, but we agree that isolating each element is necessary to distinguish our approach from generic RL or multi-candidate baselines. In the revised manuscript we will add ablation tables that remove or replace each reward individually and each orchestrator scoring criterion, reporting the resulting performance drops on the eight benchmarks. This will directly support the central thesis that evidence-grounded training and election drive the observed improvements. revision: yes
-
Referee: [§3.2] §3.2 (Rewards) and §3.3 (Orchestrator): no equations, pseudocode, or hyperparameter details are supplied for the Frame-sensitive, Think-transparency, or Anti-repetition rewards, nor for the evidence-consistency scoring. Without these, it is impossible to verify whether the signals enforce verifiable video grounding or merely correlate with patterns in the eight evaluation benchmarks.
Authors: We agree that the lack of explicit formulations prevents full verification and reproducibility. The revised manuscript will include the mathematical definitions of the three reward functions (including how frame sensitivity, transparency, and anti-repetition are quantified), pseudocode for the orchestrator's parsing, scoring, and evidence-weighted voting steps, and the complete set of training and inference hyperparameters. These additions will allow readers to assess whether the signals promote verifiable grounding rather than benchmark-specific correlations. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes an empirical dual-paradigm method: RL training with three explicitly task-driven rewards (Frame-sensitive, Think-transparency, Anti-repetition) defined from observable properties such as key frames and parsability, followed by a train-free orchestrator that parses candidates and scores them on consistency, confidence, transparency, and non-redundancy before election. No equations, fitted parameters, or self-citations are shown reducing the SOTA claims or 6.3% gains to tautological inputs by construction. Performance numbers arise from benchmark evaluations rather than any self-referential redefinition or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Group-relative reinforcement learning can optimize the proposed task-driven rewards for video reasoning.
- domain assumption Model outputs can be reliably parsed for answers and cited frames.
invented entities (4)
-
Frame-sensitive reward
no independent evidence
-
Think-transparency reward
no independent evidence
-
Anti-repetition reward
no independent evidence
-
Evidence-weighted election orchestrator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We optimize the policy with group-relative reinforcement learning (RL) and 3 novel task-driven rewards: Frame-sensitive reward grounds reasoning on explicit key frames, Think-transparency reward shapes readable and parsable reasoning traces, and Anti-repetition reward boosts information density.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RLER achieves state of the art across all benchmarks and delivers an average improvement of 6.3% over base models, while using on average 3.1 candidates per question
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Class-based n-gram mod- els of natural language.Computational linguistics, 18(4): 467–480, 1992
Peter F Brown, Vincent J Della Pietra, Peter V Desouza, Jen- nifer C Lai, and Robert L Mercer. Class-based n-gram mod- els of natural language.Computational linguistics, 18(4): 467–480, 1992. 4
1992
-
[4]
CG- bench: Clue-grounded question answering benchmark for long video understanding
Guo Chen, Yicheng Liu, Yifei Huang, Baoqi Pei, Jilan Xu, Yuping He, Tong Lu, Yali Wang, and Limin Wang. CG- bench: Clue-grounded question answering benchmark for long video understanding. InThe Thirteenth International Conference on Learning Representations, 2025. 1
2025
-
[5]
Sharegpt4video: Improving video understand- ing and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2024
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understand- ing and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2024. 6
2024
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[8]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Openvlthinker: An early ex- ploration to complex vision-language reasoning via iterative self-improvement.arXiv preprint arXiv:2503.17352, 2025. 2
-
[9]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review arXiv
-
[10]
Xidong Feng, Ziyu Wan, Muning Wen, Stephen Mar- cus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero-like tree-search can guide large language model decoding and training.arXiv preprint arXiv:2309.17179,
-
[11]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 5
2025
-
[12]
Bonbon alignment for large language models and the sweetness of best-of-n sampling.Advances in Neural Information Pro- cessing Systems, 37:2851–2885, 2024
Lin Gui, Cristina G ˆarbacea, and Victor Veitch. Bonbon alignment for large language models and the sweetness of best-of-n sampling.Advances in Neural Information Pro- cessing Systems, 37:2851–2885, 2024. 1, 2
2024
-
[13]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025. 1, 2, 3
2025
-
[14]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline pro- fessional videos.arXiv preprint arXiv:2501.13826, 2025. 5
work page internal anchor Pith review arXiv 2025
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
On the consistency of video large language models in temporal comprehension
Minjoon Jung, Junbin Xiao, Byoung-Tak Zhang, and Angela Yao. On the consistency of video large language models in temporal comprehension. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13713– 13722, 2025. 1
2025
-
[18]
Learning to purification for unsupervised per- son re-identification.IEEE Transactions on Image Process- ing, 32:3338–3353, 2023
Long Lan, Xiao Teng, Jing Zhang, Xiang Zhang, and Dacheng Tao. Learning to purification for unsupervised per- son re-identification.IEEE Transactions on Image Process- ing, 32:3338–3353, 2023. 2
2023
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding
Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9098–9108, 2025. 2
2025
-
[21]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024. 5
2024
-
[22]
arXiv preprint arXiv:2504.06958 (2025)
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025. 6
-
[23]
Zongzhao Li, Zongyang Ma, Mingze Li, Songyou Li, Yu Rong, Tingyang Xu, Ziqi Zhang, Deli Zhao, and Wenbing Huang. Star-r1: Spatial transformation reasoning by rein- forcing multimodal llms.arXiv preprint arXiv:2505.15804,
-
[24]
Vila: On pre-training for vi- sual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for vi- sual language models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 26689–26699, 2024. 6
2024
-
[25]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 2
2023
-
[26]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 1, 2
2024
-
[27]
Common- sense video question answering through video-grounded en- tailment tree reasoning
Huabin Liu, Filip Ilievski, and Cees GM Snoek. Common- sense video question answering through video-grounded en- tailment tree reasoning. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3262–3271,
-
[28]
Tempcompass: Do video llms really understand videos?,
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcom- pass: Do video llms really understand videos?arXiv preprint arXiv:2403.00476, 2024. 5
-
[29]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual- rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[30]
Nee- dle in a video haystack: A scalable synthetic evaluator for video mllms
Haoyu Lu, Yuqi Huo, Yifan Du, Zijia Zhao, Longteng Guo, Bingning Wang, Weipeng Chen, and Jing Liu. Nee- dle in a video haystack: A scalable synthetic evaluator for video mllms. InInternational Conference on Representation Learning, pages 99750–99782, 2025. 1
2025
-
[31]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation.https://ai
AI Meta. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation.https://ai. meta. com/blog/llama-4-multimodal-intelligence/, checked on, 4 (7):2025, 2025. 2
2025
-
[32]
arXiv preprint arXiv:2503.07536 , year =
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl. arXiv preprint arXiv:2503.07536, 2025. 2
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuo- fan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a com- prehensive dataset and benchmark for chain-of-thought rea- soning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024. 1, 2
2024
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Moss-chatv: Reinforcement learning with process reasoning reward for video temporal reasoning
Sicheng Tao, Jungang Li, Yibo Yan, Junyan Zhang, Yubo Gao, Hanqian Li, ShuHang Xun, Yuxuan Fan, Hong Chen, Jianxiang He, et al. Moss-chatv: Reinforcement learning with process reasoning reward for video temporal reasoning. arXiv preprint arXiv:2509.21113, 2025. 6
-
[37]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434,
-
[38]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiao- han Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025. 5
2025
-
[39]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3272– 3283, 2025. 2
2025
-
[40]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024. 5
2024
-
[41]
Videoqa in the era of llms: An empir- ical study.International Journal of Computer Vision, pages 1–24, 2025
Junbin Xiao, Nanxin Huang, Hangyu Qin, Dongyang Li, Yi- cong Li, Fengbin Zhu, Zhulin Tao, Jianxing Yu, Liang Lin, Tat-Seng Chua, et al. Videoqa in the era of llms: An empir- ical study.International Journal of Computer Vision, pages 1–24, 2025. 1
2025
-
[42]
Self-evaluation guided beam search for reasoning.Advances in Neural In- formation Processing Systems, 36:41618–41650, 2023
Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie. Self-evaluation guided beam search for reasoning.Advances in Neural In- formation Processing Systems, 36:41618–41650, 2023. 1, 2
2023
-
[43]
Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception,
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce mul- timodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100, 2025. 2, 6
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 5
2025
-
[46]
Wildvideo: Bench- marking lmms for understanding video-language interaction
Songyuan Yang, Weijiang Yu, Wenjing Yang, Xinwang Liu, Huibin Tan, Long Lan, and Nong Xiao. Wildvideo: Bench- marking lmms for understanding video-language interaction. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025. 5
2025
-
[47]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[48]
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024. 6
-
[49]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[50]
Yufei Zhan, Yousong Zhu, Shurong Zheng, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Vision-r1: Evolv- ing human-free alignment in large vision-language models via vision-guided reinforcement learning.arXiv preprint arXiv:2503.18013, 2025. 1, 2
-
[51]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 2, 6
work page internal anchor Pith review arXiv 2025
-
[52]
VReST: Enhancing reasoning in large vision-language mod- els through tree search and self-reward mechanism
Congzhi Zhang, Jiawei Peng, Zhenglin Wang, Yilong Lai, Haowen Sun, Heng Chang, Fei Ma, and Weijiang Yu. VReST: Enhancing reasoning in large vision-language mod- els through tree search and self-reward mechanism. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025. 2
2025
-
[53]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[54]
arXiv preprint arXiv:2503.12937 , year =
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learn- ing to reason with multimodal large language models via step-wise group relative policy optimization.arXiv preprint arXiv:2503.12937, 2025. 2
-
[55]
Tinyllava-video-r1: Towards smaller lmms for video reason- ing.arXiv preprint arXiv:2504.09641, 2025
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Tinyllava-video-r1: Towards smaller lmms for video reason- ing.arXiv preprint arXiv:2504.09641, 2025. 6
-
[56]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 2, 6
work page Pith review arXiv 2024
-
[57]
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero’s” aha moment” in visual reasoning on a 2b non-sft model.arXiv preprint arXiv:2503.05132, 2025. 2
-
[58]
Heqing Zou, Tianze Luo, Guiyang Xie, Fengmao Lv, Guangcong Wang, Junyang Chen, Zhuochen Wang, Han- sheng Zhang, Huaijian Zhang, et al. From seconds to hours: Reviewing multimodal large language models on comprehensive long video understanding.arXiv preprint arXiv:2409.18938, 2024. 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.