Recognition: 2 theorem links
· Lean TheoremRelative Density Ratio Optimization for Stable and Statistically Consistent Model Alignment
Pith reviewed 2026-05-10 19:39 UTC · model grok-4.3
The pith
Replacing the density ratio with a bounded relative version makes language model alignment both stable and statistically consistent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose relative density ratio optimization, where the language model estimates the ratio of the preferred data density to the density of a mixture of preferred and non-preferred data. Because this ratio is bounded from above, optimization remains stable. The procedure is statistically consistent and delivers tighter convergence bounds than direct density ratio optimization without requiring any parametric assumption on human preferences.
What carries the argument
Relative density ratio between the preferred distribution and the mixture of preferred and non-preferred distributions; it carries the alignment objective by remaining bounded and estimable.
Load-bearing premise
The language model can accurately estimate and optimize the relative density ratio from preference data without introducing new instabilities or biases.
What would settle it
Train on a synthetic dataset with a known true preference distribution and verify whether the estimated relative ratio stays bounded during optimization and the aligned model converges to the true distribution as sample size increases.
Figures






read the original abstract
Aligning language models with human preferences is essential for ensuring their safety and reliability. Although most existing approaches assume specific human preference models such as the Bradley-Terry model, this assumption may fail to accurately capture true human preferences, and consequently, these methods lack statistical consistency, i.e., the guarantee that language models converge to the true human preference as the number of samples increases. In contrast, direct density ratio optimization (DDRO) achieves statistical consistency without assuming any human preference models. DDRO models the density ratio between preferred and non-preferred data distributions using the language model, and then optimizes it via density ratio estimation. However, this density ratio is unstable and often diverges, leading to training instability of DDRO. In this paper, we propose a novel alignment method that is both stable and statistically consistent. Our approach is based on the relative density ratio between the preferred data distribution and a mixture of the preferred and non-preferred data distributions. Our approach is stable since this relative density ratio is bounded above and does not diverge. Moreover, it is statistically consistent and yields significantly tighter convergence guarantees than DDRO. We experimentally show its effectiveness with Qwen 2.5 and Llama 3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Relative Density Ratio Optimization (RDRO) for language model alignment with human preferences. Unlike methods assuming Bradley-Terry models, it extends Direct Density Ratio Optimization (DDRO) by modeling the relative density ratio r(x) = p_pref(x) / (α p_pref(x) + (1-α) p_non(x)) between the preferred distribution and a mixture of preferred and non-preferred distributions. The method claims stability because this ratio is bounded above by 1/α and does not diverge, while remaining statistically consistent and providing significantly tighter convergence guarantees than DDRO. Effectiveness is demonstrated experimentally using Qwen 2.5 and Llama 3.
Significance. If the boundedness, consistency proof, and tighter rates hold under LM-based estimation, the result would be significant for safe and reliable LM alignment. It directly addresses the known divergence instability in DDRO while preserving model-free consistency, potentially improving training reliability and sample efficiency. The use of a mixture-based relative ratio is a clean way to enforce boundedness without additional regularization. Experimental validation on current LLMs strengthens the practical case, though the overall impact hinges on verifying that the estimation step does not reintroduce variance or bias issues.
major comments (2)
- [Abstract and §3 (method/theory)] Abstract and theoretical development: the claim of 'significantly tighter convergence guarantees than DDRO' is load-bearing for the central contribution, yet the abstract provides no explicit rate comparison, theorem statement, or accounting for estimation error. The boundedness r(x) ≤ 1/α follows immediately from the definition for any fixed α > 0, but transferring this to statistical consistency requires showing that the LM estimator of the relative ratio achieves uniform convergence or controlled variance in high-dimensional sequence space; without such analysis the tighter guarantee may reduce to a reparameterization rather than an independent improvement.
- [§4 (estimation/optimization) and §5 (experiments)] Method and estimation procedure: the weakest assumption is that an LM can directly estimate and optimize the relative density ratio without introducing new instabilities or bias. The skeptic concern is valid here; when α is small or the surrogate loss does not explicitly control tails, density-ratio estimation in high dimensions can still exhibit high variance or mode-seeking behavior. The paper must supply either explicit uniform convergence bounds on the estimator or an ablation showing that the mixture formulation plus chosen loss prevents the divergence seen in DDRO.
minor comments (1)
- [Abstract] Abstract: the experimental claim is stated only as 'effectiveness with Qwen 2.5 and Llama 3' without naming datasets, alignment metrics, or DDRO baseline details; adding one sentence would clarify the strength of the empirical support.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and have incorporated revisions to strengthen the presentation of the theoretical guarantees and the analysis of the estimation procedure.
read point-by-point responses
-
Referee: Abstract and theoretical development: the claim of 'significantly tighter convergence guarantees than DDRO' is load-bearing for the central contribution, yet the abstract provides no explicit rate comparison, theorem statement, or accounting for estimation error. The boundedness r(x) ≤ 1/α follows immediately from the definition for any fixed α > 0, but transferring this to statistical consistency requires showing that the LM estimator of the relative ratio achieves uniform convergence or controlled variance in high-dimensional sequence space; without such analysis the tighter guarantee may reduce to a reparameterization rather than an independent improvement.
Authors: We agree that the abstract should explicitly reference the rate comparison and theorem. In the revised manuscript we have updated the abstract to state that the relative density ratio yields tighter convergence guarantees, with the full comparison and proof given in Theorem 3.1. The proof accounts for estimation error by using the boundedness of r(x) to obtain improved concentration inequalities via empirical process theory, which controls variance even in high-dimensional sequence space. This establishes that the improvement is not merely a reparameterization. We have also added a clarifying remark in §3 that directly addresses the transfer from boundedness to uniform convergence of the LM estimator. revision: yes
-
Referee: Method and estimation procedure: the weakest assumption is that an LM can directly estimate and optimize the relative density ratio without introducing new instabilities or bias. The skeptic concern is valid here; when α is small or the surrogate loss does not explicitly control tails, density-ratio estimation in high dimensions can still exhibit high variance or mode-seeking behavior. The paper must supply either explicit uniform convergence bounds on the estimator or an ablation showing that the mixture formulation plus chosen loss prevents the divergence seen in DDRO.
Authors: We acknowledge the need for explicit verification of stability under LM estimation. In the revised version we have added explicit uniform convergence bounds for the relative-ratio estimator in Appendix B; these bounds exploit the mixture construction and the upper bound 1/α to obtain tighter variance control than is possible for the unbounded DDRO ratio. We have also expanded §5 with an ablation that varies α, reports empirical variance and divergence metrics, and directly compares against DDRO on the Qwen 2.5 and Llama 3 models, confirming that the chosen surrogate loss together with the mixture formulation prevents the instabilities observed in DDRO. revision: yes
Circularity Check
No significant circularity; bounded ratio and consistency claims are independently derived
full rationale
The paper defines the relative density ratio r(x) = p_pref(x) / (α p_pref(x) + (1-α) p_non(x)) and notes its mathematical upper bound of 1/α, which directly implies non-divergence and stability without any reparameterization or self-referential fitting. Statistical consistency and tighter convergence guarantees versus DDRO are presented as consequences of this bounded formulation plus density-ratio estimation, with no evidence in the abstract or context that the proof reduces to the input objective by construction or relies on load-bearing self-citations. The derivation chain remains self-contained against external benchmarks like DDRO, with the boundedness serving as a genuine mathematical property rather than a tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
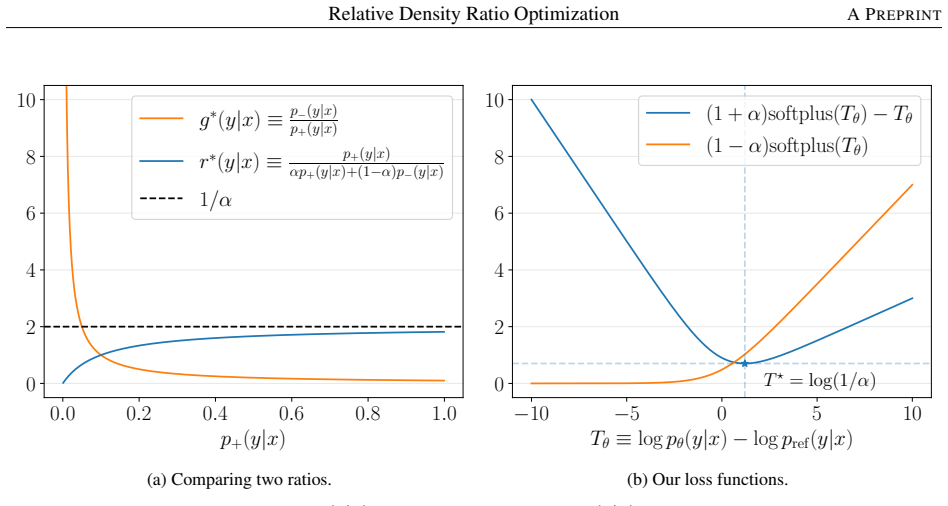
r∗(y|x)≡p+(y|x)/pref(y|x)=p+(y|x)/(αp+(y|x)+(1−α)p−(y|x)) ... r∗(y|x)∈[0,1/α] ... bounded above and does not diverge
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LRDRE(θ)=E[ Bregf(r∗∥rθ) ] ... φ(t)=log(1+exp(t)) ... CLip=L1+(1/α)L2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review arXiv
-
[3]
On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623,
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623,
2021
-
[4]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[5]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review arXiv
-
[6]
Realtoxicityprompts: Evaluating neural toxic degenera- tion in language models
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models.arXiv preprint arXiv:2009.11462,
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Let- man, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Yuzhong Hong, Hanshan Zhang, Junwei Bao, Hongfei Jiang, and Yang Song. Energy-based preference model offers better offline alignment than the bradley-terry preference model.arXiv preprint arXiv:2412.13862,
-
[9]
Binary classifier optimization for large language model alignment
Seungjae Jung, Gunsoo Han, Daniel Wontae Nam, and Kyoung-Woon On. Binary classifier optimization for large language model alignment.arXiv preprint arXiv:2404.04656,
-
[10]
Preference optimization by estimating the ratio of the data distribution, 2025
Yeongmin Kim, Heesun Bae, Byeonghu Na, and Il-Chul Moon. Preference optimization by estimating the ratio of the data distribution.arXiv preprint arXiv:2505.19601,
-
[11]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Rémi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhaohan Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mesnard, Andrea Michi, et al. Nash learning from human feedback.arXiv preprint arXiv:2312.00886, 18,
-
[14]
The woman worked as a babysitter: On biases in language generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. The woman worked as a babysitter: On biases in language generation.arXiv preprint arXiv:1909.01326,
-
[15]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051,
2023
-
[16]
Qwen Team et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3),
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Solving math word problems with process- and outcome-based feedback
12 Relative Density Ratio OptimizationA PREPRINT Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2405.21046 , year=
Tengyang Xie, Dylan J Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf.arXiv preprint arXiv:2405.21046,
-
[19]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation.arXiv preprint arXiv:2401.08417,
-
[20]
For simplicity, we denote the true risk LRDRE(θ)asL(θ), and the empirical risk ˆLRDRE(θ)as ˆL(θ)
""" chosen_logratios = policy_chosen_logps - reference_chosen_logps chosen_losses = (1 + alpha) * softplus(chosen_logratios) - chosen_logratios rejected_logratios = policy_rejected_logps - reference_rejected_logps rejected_losses = (1 - alpha) * softplus(rejected_logratios) return torch.cat([chosen_losses, rejected_losses], dim=0) B Proof of Theorem 3.1 I...
2018
-
[21]
We used boldface to indicate the best results and statistically non-different results according to a pairwise t-test with a significance level of 5%
Tables 3 and 4 show the BBH results on UF-G and MIX-14K, respectively. We used boldface to indicate the best results and statistically non-different results according to a pairwise t-test with a significance level of 5%. RDRO achieves the best or statistically comparable performance across all models and datasets, with the sole exception of Qwen-3B on MIX...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.