Recognition: 2 theorem links
· Lean TheoremHandDreamer: Zero-Shot Text to 3D Hand Model Generation using Corrective Hand Shape Guidance
Pith reviewed 2026-05-10 18:57 UTC · model grok-4.3
The pith
HandDreamer generates view-consistent 3D hand models from text prompts by initializing with the MANO model and applying skeleton guidance plus a corrective shape loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
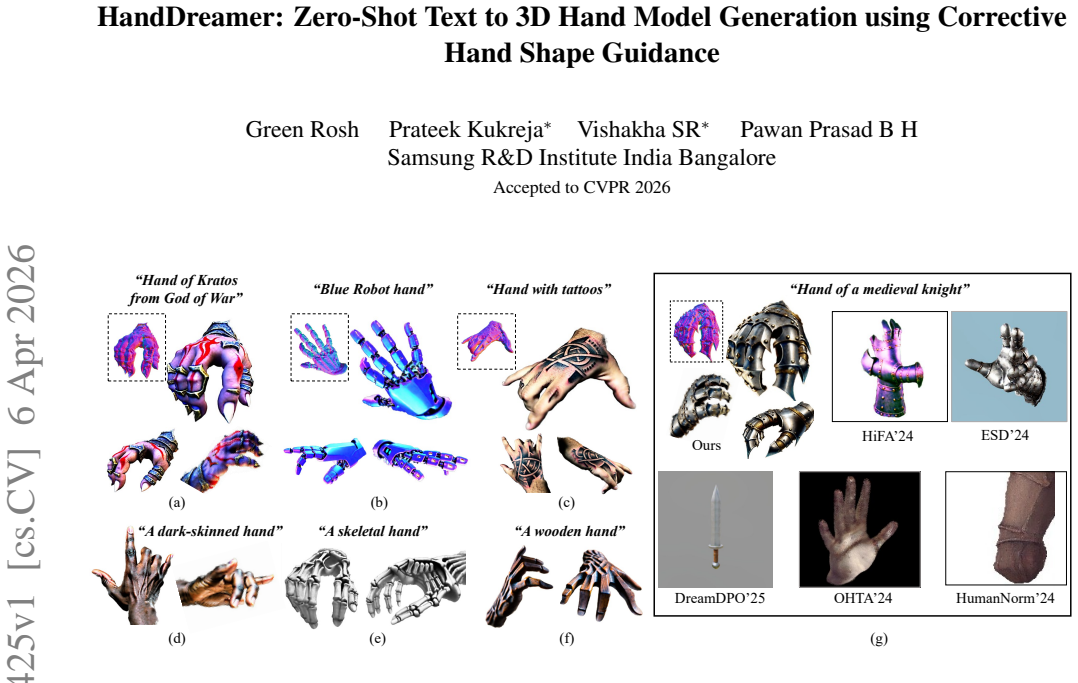
HandDreamer is the first method for zero-shot 3D hand model generation from text prompts. View-inconsistencies in SDS arise mainly from ambiguity in the text-prompt probability landscape, which causes similar views to converge to different distribution modes. This problem is especially severe for hands because of large pose and articulation variations. The method counters it with MANO hand model based initialization and a hand skeleton guided diffusion process that supplies a strong prior for structure and enforces view and pose consistency. A novel corrective hand shape guidance loss further ensures that all rendered views converge to consistent modes without causing geometric distortions.
What carries the argument
The corrective hand shape guidance loss, combined with MANO model initialization and hand skeleton guided diffusion, that supplies structural priors and pulls multiple views of the generated hand toward matching consistent modes.
If this is right
- Users can obtain pose-consistent, detailed 3D hands suitable for VR interaction directly from natural language descriptions.
- The need for post-generation cleanup or manual rigging of hand models is reduced for many common use cases.
- Score distillation sampling can be made reliable for other articulated objects by adding similar domain-specific priors and corrective terms.
- Text-driven hand generation becomes fast enough to support interactive customization in real time applications.
Where Pith is reading between the lines
- The same combination of parametric initialization and cross-view corrective loss could be tested on other high-articulation objects such as full human bodies or animal limbs where SDS currently fails.
- If the MANO prior is loosened or replaced with a more flexible shape model, the method might allow even greater shape diversity while retaining consistency.
- The corrective loss might improve text-to-3D results for symmetric or repeating structures beyond hands, such as feet or mechanical parts.
Load-bearing premise
The main source of view inconsistencies in SDS for hands is ambiguity in the text prompt probability landscape, and that MANO initialization, skeleton guidance, and the corrective loss will resolve it without introducing distortions or limiting pose variety.
What would settle it
Running HandDreamer on a set of diverse text prompts and observing that a substantial fraction of the resulting 3D hands still show view-dependent pose changes or unnatural finger structures when inspected from multiple angles.
Figures


















read the original abstract
The emergence of virtual reality has necessitated the generation of detailed and customizable 3D hand models for interaction in the virtual world. However, the current methods for 3D hand model generation are both expensive and cumbersome, offering very little customizability to the users. While recent advancements in zero-shot text-to-3D synthesis have enabled the generation of diverse and customizable 3D models using Score Distillation Sampling (SDS), they do not generalize very well to 3D hand model generation, resulting in unnatural hand structures, view-inconsistencies and loss of details. To address these limitations, we introduce HandDreamer, the first method for zero-shot 3D hand model generation from text prompts. Our findings suggest that view-inconsistencies in SDS is primarily caused due to the ambiguity in the probability landscape described by the text prompt, resulting in similar views converging to different modes of the distribution. This is particularly aggravated for hands due to the large variations in articulations and poses. To alleviate this, we propose to use MANO hand model based initialization and a hand skeleton guided diffusion process to provide a strong prior for the hand structure and to ensure view and pose consistency. Further, we propose a novel corrective hand shape guidance loss to ensure that all the views of the 3D hand model converges to view-consistent modes, without leading to geometric distortions. Extensive evaluations demonstrate the superiority of our method over the state-of-the-art methods, paving a new way forward in 3D hand model generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HandDreamer as the first zero-shot text-to-3D hand model generation method from text prompts. It diagnoses view-inconsistencies in Score Distillation Sampling (SDS) as stemming primarily from ambiguity in the text-prompt probability landscape, worsened by hand articulation variety. The approach uses MANO hand model initialization for structural prior, a hand skeleton guided diffusion process for pose/view consistency, and a novel corrective hand shape guidance loss to force convergence to consistent modes without geometric distortions. The authors claim superiority over state-of-the-art methods based on extensive evaluations.
Significance. If the proposed initialization, guidance, and loss components prove effective at resolving SDS inconsistencies for articulated hands without reducing pose diversity or introducing MANO-biased artifacts, the work could advance practical zero-shot 3D hand synthesis for VR and interaction applications. The explicit framing of a root cause (probability landscape ambiguity) and the additive guidance terms are constructive contributions. However, the absence of quantitative metrics, ablations, or failure analyses in the manuscript limits assessment of whether the fixes address the claimed cause or merely trade one failure mode for another.
major comments (2)
- [Abstract] Abstract: The assertion that view-inconsistencies in SDS arise primarily from ambiguity in the text-prompt probability landscape (aggravated by hand articulations) is load-bearing for the entire method but is presented without any supporting analysis, derivation, ablation, or quantitative isolation from alternative causes such as optimization dynamics or diffusion prior mismatch.
- [Abstract] Abstract: The claim of 'superiority of our method over the state-of-the-art methods' via 'extensive evaluations' is unsupported by any reported metrics, tables, figures, or specific comparisons; this undermines verification of whether the MANO initialization, skeleton guidance, and corrective loss actually deliver the promised consistency gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that view-inconsistencies in SDS arise primarily from ambiguity in the text-prompt probability landscape (aggravated by hand articulations) is load-bearing for the entire method but is presented without any supporting analysis, derivation, ablation, or quantitative isolation from alternative causes such as optimization dynamics or diffusion prior mismatch.
Authors: We acknowledge that the abstract condenses this diagnosis without full supporting details. The full manuscript (Section 3.1 and associated figures) presents empirical observations from repeated SDS runs on hand prompts, where different camera views converge to inconsistent articulations despite identical text conditioning. We will revise the abstract for precision and add a short subsection with additional controlled experiments (e.g., varying prompt specificity and comparing against non-hand objects) to better isolate prompt-landscape ambiguity from optimization dynamics or prior mismatch. A full mathematical derivation is not feasible without internal access to the diffusion model's probability outputs, but the empirical isolation can be strengthened. revision: partial
-
Referee: [Abstract] Abstract: The claim of 'superiority of our method over the state-of-the-art methods' via 'extensive evaluations' is unsupported by any reported metrics, tables, figures, or specific comparisons; this undermines verification of whether the MANO initialization, skeleton guidance, and corrective loss actually deliver the promised consistency gains.
Authors: The manuscript contains qualitative comparisons (Figures 4-6) and a user study (Section 4.3) demonstrating visual improvements. We agree that quantitative metrics are needed to substantiate superiority. In the revised version we will add a results table reporting view-consistency error (average LPIPS across rendered views), text-alignment CLIP score, and a component ablation (MANO init, skeleton guidance, corrective loss) against baselines such as DreamFusion and Magic3D. This will allow direct verification of the consistency gains. revision: yes
Circularity Check
No circularity: new guidance terms and losses are additive proposals, not reductions to prior fits or self-citations.
full rationale
The paper's core chain—identifying text-prompt ambiguity as the source of SDS view-inconsistencies for hands, then countering it with MANO initialization, skeleton-guided diffusion, and a novel corrective hand shape guidance loss—is presented as an empirical observation plus additive engineering. No equation or claim reduces by construction to a fitted parameter renamed as prediction, nor does any load-bearing premise collapse to a self-citation whose content is itself unverified. The method description introduces distinct new terms without tautological redefinition of inputs as outputs. This is the common case of an honest method paper whose central claims remain independent of the inputs they modify.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
view-inconsistencies in SDS is primarily caused due to the ambiguity in the probability landscape... MANO hand model based initialization and a hand skeleton guided diffusion process... corrective hand shape guidance loss
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... expected absolute score... MANO based hand model for a low-score initialization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Panohead: Geometry-aware 3d full- head synthesis in 360deg
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Y Ogras, and Linjie Luo. Panohead: Geometry-aware 3d full- head synthesis in 360deg. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20950–20959, 2023. 2
2023
-
[2]
Dreamavatar: Text-and-shape guided 3d hu- man avatar generation via diffusion models
Yukang Cao, Yan-Pei Cao, Kai Han, Ying Shan, and Kwan- Yee K Wong. Dreamavatar: Text-and-shape guided 3d hu- man avatar generation via diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 958–968, 2024. 3, 6, 7, 15
2024
-
[3]
Openpose: Realtime multi-person 2d pose estimation using part affinity fields.IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186,
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields.IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186,
-
[4]
Efficient geometry-aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022. 2
2022
-
[5]
Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation. InProceedings of the IEEE/CVF international conference on computer vision, pages 22246–22256, 2023. 2, 7, 13, 15
2023
-
[6]
It3d: Improved text-to-3d generation with explicit view synthesis
Yiwen Chen, Chi Zhang, Xiaofeng Yang, Zhongang Cai, Gang Yu, Lei Yang, and Guosheng Lin. It3d: Improved text-to-3d generation with explicit view synthesis. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 1237–1244, 2024. 2
2024
-
[7]
Dreamcraft: Text-guided generation of functional 3d environments in minecraft
Sam Earle, Filippos Kokkinos, Yuhe Nie, Julian Togelius, and Roberta Raileanu. Dreamcraft: Text-guided generation of functional 3d environments in minecraft. InProceedings of the 19th International Conference on the Foundations of Digital Games, pages 1–15, 2024. 2
2024
-
[8]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2
2020
-
[9]
threestudio: A unified framework for 3d content generation
Yuan-Chen Guo, Ying-Tian Liu, Ruizhi Shao, Christian Laforte, Vikram V oleti, Guan Luo, Chia-Hao Chen, Zi- Xin Zou, Chen Wang, Yan-Pei Cao, and Song-Hai Zhang. threestudio: A unified framework for 3d content generation. https://github.com/threestudio- project/ threestudio, 2023. 2, 6
2023
-
[10]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review arXiv
-
[11]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
2020
-
[12]
Eva3d: Compositional 3d human generation from 2d image collections.arXiv preprint arXiv:2210.04888,
Fangzhou Hong, Zhaoxi Chen, Yushi Lan, Liang Pan, and Ziwei Liu. Eva3d: Compositional 3d human generation from 2d image collections.arXiv preprint arXiv:2210.04888,
-
[13]
Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. Avatarclip: Zero-shot text- driven generation and animation of 3d avatars.arXiv preprint arXiv:2205.08535, 2022. 3
-
[14]
Humanliff: Layer-wise 3d human generation with diffusion model.arXiv preprint arXiv:2308.09712, 2023
Shoukang Hu, Fangzhou Hong, Tao Hu, Liang Pan, Haiyi Mei, Weiye Xiao, Lei Yang, and Ziwei Liu. Humanliff: Layer-wise 3d human generation with diffusion model.arXiv preprint arXiv:2308.09712, 2023. 2
-
[15]
Humannorm: Learning normal diffusion model for high-quality and realistic 3d hu- man generation
Xin Huang, Ruizhi Shao, Qi Zhang, Hongwen Zhang, Ying Feng, Yebin Liu, and Qing Wang. Humannorm: Learning normal diffusion model for high-quality and realistic 3d hu- man generation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 4568–4577, 2024. 3, 6, 7, 15
2024
-
[16]
Yukun Huang, Jianan Wang, Yukai Shi, Xianbiao Qi, Zheng- Jun Zha, and Lei Zhang. Dreamtime: An improved optimiza- tion strategy for text-to-3d content creation.arXiv preprint arXiv:2306.12422, 3(5):14, 2023. 3
-
[17]
Dreamwaltz: Make a scene with complex 3d animatable avatars.Advances in Neural Information Processing Systems, 36:4566–4584,
Yukun Huang, Jianan Wang, Ailing Zeng, He Cao, Xianbiao Qi, Yukai Shi, Zheng-Jun Zha, and Lei Zhang. Dreamwaltz: Make a scene with complex 3d animatable avatars.Advances in Neural Information Processing Systems, 36:4566–4584,
-
[18]
Zero-shot text-guided object genera- tion with dream fields
Ajay Jain, Ben Mildenhall, Jonathan T Barron, Pieter Abbeel, and Ben Poole. Zero-shot text-guided object genera- tion with dream fields. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 867–876, 2022. 2
2022
-
[19]
Avatar- craft: Transforming text into neural human avatars with pa- rameterized shape and pose control
Ruixiang Jiang, Can Wang, Jingbo Zhang, Menglei Chai, Mingming He, Dongdong Chen, and Jing Liao. Avatar- craft: Transforming text into neural human avatars with pa- rameterized shape and pose control. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14371–14382, 2023. 3
2023
-
[20]
Harp: Personalized hand reconstruction from a monocular rgb video
Korrawe Karunratanakul, Sergey Prokudin, Otmar Hilliges, and Siyu Tang. Harp: Personalized hand reconstruction from a monocular rgb video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12802–12813, 2023. 2
2023
-
[21]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[22]
Dreamhuman: Animatable 3d avatars from text.Advances in Neural Information Processing Systems, 36:10516–10529,
Nikos Kolotouros, Thiemo Alldieck, Andrei Zanfir, Ed- uard Bazavan, Mihai Fieraru, and Cristian Sminchisescu. Dreamhuman: Animatable 3d avatars from text.Advances in Neural Information Processing Systems, 36:10516–10529,
-
[23]
Tada! text to animatable digital avatars
Tingting Liao, Hongwei Yi, Yuliang Xiu, Jiaxiang Tang, Yangyi Huang, Justus Thies, and Michael J Black. Tada! text to animatable digital avatars. In2024 International Con- ference on 3D Vision (3DV), pages 1508–1519. IEEE, 2024. 3
2024
-
[24]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023. 2
2023
-
[25]
Humangaus- sian: Text-driven 3d human generation with gaussian splat- ting
Xian Liu, Xiaohang Zhan, Jiaxiang Tang, Ying Shan, Gang Zeng, Dahua Lin, Xihui Liu, and Ziwei Liu. Humangaus- sian: Text-driven 3d human generation with gaussian splat- ting. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6646–6657,
-
[26]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023. 2, 3
2023
-
[27]
Score distillation via reparametrized ddim.Advances in Neural Information Pro- cessing Systems, 37:26011–26044, 2024
Artem Lukoianov, Haitz S ´aez de Oc ´ariz Borde, Kristjan Greenewald, Vitor Guizilini, Timur Bagautdinov, Vincent Sitzmann, and Justin M Solomon. Score distillation via reparametrized ddim.Advances in Neural Information Pro- cessing Systems, 37:26011–26044, 2024. 2, 7, 15
2024
-
[28]
Scaledreamer: Scalable text-to- 3d synthesis with asynchronous score distillation
Zhiyuan Ma, Yuxiang Wei, Yabin Zhang, Xiangyu Zhu, Zhen Lei, and Lei Zhang. Scaledreamer: Scalable text-to- 3d synthesis with asynchronous score distillation. InEuro- pean Conference on Computer Vision, pages 1–19. Springer,
-
[29]
Latent-nerf for shape-guided generation of 3d shapes and textures
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12663–12673, 2023. 2, 7, 15
2023
-
[30]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2, 3, 5
2021
-
[31]
Clip-mesh: Generating textured meshes from text using pretrained image-text models
Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, and Tiberiu Popa. Clip-mesh: Generating textured meshes from text using pretrained image-text models. InSIGGRAPH Asia 2022 conference papers, pages 1–8, 2022. 2
2022
-
[32]
Interhand2
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shiratori, and Kyoung Mu Lee. Interhand2. 6m: A dataset and base- line for 3d interacting hand pose estimation from a single rgb image. InComputer Vision–ECCV 2020: 16th Euro- pean Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part XX 16, pages 548–564. Springer, 2020. 2
2020
-
[33]
Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 6
2022
-
[34]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019. 3
2019
-
[35]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 2, 3, 4, 7, 15
work page internal anchor Pith review arXiv 2022
-
[36]
Handy: Towards a high fidelity 3d hand shape and appearance model
Rolandos Alexandros Potamias, Stylianos Ploumpis, Stylianos Moschoglou, Vasileios Triantafyllou, and Stefanos Zafeiriou. Handy: Towards a high fidelity 3d hand shape and appearance model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4670–4680, 2023. 2
2023
-
[37]
Html: A para- metric hand texture model for 3d hand reconstruction and personalization
Neng Qian, Jiayi Wang, Franziska Mueller, Florian Bernard, Vladislav Golyanik, and Christian Theobalt. Html: A para- metric hand texture model for 3d hand reconstruction and personalization. InComputer Vision–ECCV 2020: 16th Eu- ropean Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part XI 16, pages 54–71. Springer, 2020. 2
2020
-
[38]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[39]
Texture: Text-guided texturing of 3d shapes
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023. 2
2023
-
[40]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 6
2022
-
[41]
Javier Romero, Dimitrios Tzionas, and Michael J Black. Em- bodied hands: Modeling and capturing hands and bodies to- gether.arXiv preprint arXiv:2201.02610, 2022. 13
-
[42]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 2
2022
-
[43]
Clip-forge: Towards zero-shot text-to-shape genera- tion
Aditya Sanghi, Hang Chu, Joseph G Lambourne, Ye Wang, Chin-Yi Cheng, Marco Fumero, and Kamal Rahimi Malek- shan. Clip-forge: Towards zero-shot text-to-shape genera- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 18603–18613,
-
[44]
arXiv preprint arXiv:2308.16512 , year=
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration.arXiv preprint arXiv:2308.16512, 2023. 2
-
[45]
Hand keypoint detection in single images using mul- tiview bootstrapping
Tomas Simon, Hanbyul Joo, Iain Matthews, and Yaser Sheikh. Hand keypoint detection in single images using mul- tiview bootstrapping. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1145– 1153, 2017. 2
2017
-
[46]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[47]
arXiv preprint arXiv:2309.16653 , year=
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation.arXiv preprint arXiv:2309.16653,
-
[48]
Diverse text-to-3d synthesis with aug- mented text embedding
Uy Dieu Tran, Minh Luu, Phong Ha Nguyen, Khoi Nguyen, and Binh-Son Hua. Diverse text-to-3d synthesis with aug- mented text embedding. InEuropean Conference on Com- puter Vision, pages 217–235. Springer, 2024. 2
2024
-
[49]
Neus: learning neural implicit surfaces by volume rendering for multi-view reconstruction
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: learning neural implicit surfaces by volume rendering for multi-view reconstruction. InProceedings of the 35th International Conference on Neu- ral Information Processing Systems, pages 27171–27183,
-
[50]
Taming mode collapse in score distillation for text-to-3d generation
Peihao Wang, Dejia Xu, Zhiwen Fan, Dilin Wang, Sreyas Mohan, Forrest Iandola, Rakesh Ranjan, Yilei Li, Qiang Liu, Zhangyang Wang, et al. Taming mode collapse in score distillation for text-to-3d generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 9037–9047, 2024. 2, 3, 6, 13, 22, 23, 24, 25, 26
2024
-
[51]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in Neural Information Processing Systems, 36:8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in Neural Information Processing Systems, 36:8406–8441, 2023. 2, 6
2023
-
[52]
Bayesian learning via stochas- tic gradient langevin dynamics
Max Welling and Yee W Teh. Bayesian learning via stochas- tic gradient langevin dynamics. InProceedings of the 28th international conference on machine learning (ICML-11), pages 681–688. Citeseer, 2011. 2
2011
-
[53]
Tpa3d: Triplane attention for fast text- to-3d generation
Bin-Shih Wu, Hong-En Chen, Sheng-Yu Huang, and Yu- Chiang Frank Wang. Tpa3d: Triplane attention for fast text- to-3d generation. InEuropean Conference on Computer Vi- sion, pages 438–455. Springer, 2024. 2
2024
-
[54]
Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.CoRR, 2023
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.CoRR, 2023. 6
2023
-
[55]
Get3dhuman: Lifting stylegan-human into a 3d generative model using pixel-aligned reconstruction priors
Zhangyang Xiong, Di Kang, Derong Jin, Weikai Chen, Lin- chao Bao, Shuguang Cui, and Xiaoguang Han. Get3dhuman: Lifting stylegan-human into a 3d generative model using pixel-aligned reconstruction priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9287–9297, 2023. 2
2023
-
[56]
Yinghao Xu, Wang Yifan, Alexander W Bergman, Menglei Chai, Bolei Zhou, and Gordon Wetzstein. Efficient 3d articu- lated human generation with layered surface volumes.arXiv preprint arXiv:2307.05462, 2023. 2
-
[57]
Consis- tent flow distillation for text-to-3d generation
Runjie Yan, Yinbo Chen, and Xiaolong Wang. Consis- tent flow distillation for text-to-3d generation. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 2, 6, 7, 13, 15, 22, 23, 24, 25, 26
2025
-
[58]
Dreamdissector: Learning disentangled text-to-3d generation from 2d diffusion priors
Zizheng Yan, Jiapeng Zhou, Fanpeng Meng, Yushuang Wu, Lingteng Qiu, Zisheng Ye, Shuguang Cui, Guanying Chen, and Xiaoguang Han. Dreamdissector: Learning disentangled text-to-3d generation from 2d diffusion priors. InEuropean Conference on Computer Vision, pages 124–141. Springer,
-
[59]
Yifei Zeng, Yuanxun Lu, Xinya Ji, Yao Yao, Hao Zhu, and Xun Cao. Avatarbooth: High-quality and customizable 3d human avatar generation.arXiv preprint arXiv:2306.09864,
-
[60]
Avatarverse: High-quality & stable 3d avatar creation from text and pose
Huichao Zhang, Bowen Chen, Hao Yang, Liao Qu, Xu Wang, Li Chen, Chao Long, Feida Zhu, Daniel Du, and Min Zheng. Avatarverse: High-quality & stable 3d avatar creation from text and pose. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7124–7132, 2024. 3
2024
-
[61]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 5, 6, 7, 13
2023
-
[62]
Getavatar: Generative textured meshes for animatable human avatars
Xuanmeng Zhang, Jianfeng Zhang, Rohan Chacko, Hongyi Xu, Guoxian Song, Yi Yang, and Jiashi Feng. Getavatar: Generative textured meshes for animatable human avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2273–2282, 2023. 2
2023
-
[63]
Ohta: One-shot hand avatar via data-driven implicit priors
Xiaozheng Zheng, Chao Wen, Zhuo Su, Zeran Xu, Zhaohu Li, Yang Zhao, and Zhou Xue. Ohta: One-shot hand avatar via data-driven implicit priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 799–810, 2024. 2, 7, 13, 15
2024
-
[64]
Open3D: A Modern Library for 3D Data Processing
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3d: A modern library for 3d data processing.arXiv preprint arXiv:1801.09847, 2018. 13
work page internal anchor Pith review arXiv 2018
-
[65]
Dreamdpo: Aligning text-to-3d genera- tion with human preferences via direct preference optimiza- tion
Zhenglin Zhou, Xiaobo Xia, Fan Ma, Hehe Fan, Yi Yang, and Tat-Seng Chua. Dreamdpo: Aligning text-to-3d genera- tion with human preferences via direct preference optimiza- tion. InForty-second International Conference on Machine Learning, 2025. 2, 13, 22, 23, 24, 25, 26
2025
-
[66]
Junzhe Zhu, Peiye Zhuang, and Sanmi Koyejo. Hifa: High- fidelity text-to-3d generation with advanced diffusion guid- ance.arXiv preprint arXiv:2305.18766, 2023. 2, 5, 6, 13
-
[67]
Additional studies are provided in section A.3, additional quantitative results in section A.4 and more results in section A.5
Supplementary We provide proofs and derivations for the results presented in the main paper in section A.1 We provide additional im- plementation details in section A.2. Additional studies are provided in section A.3, additional quantitative results in section A.4 and more results in section A.5. We also pro- vide multi-view videos in the multimedia suppl...
-
[68]
A.1 Proofs and Derivations In this section, we provide proofs and derivations for the theorems and definitions defined in the main paper. 9.1. Proof for Theorem 1 Theorem 1.Letx v latent andx v init denote the set of views rendered from an ideal latent 3D model (m latent 3D ) and an initial 3D model (m init 3D ) respectively. Then the expected absolute sc...
-
[69]
A.2 Additional Implementation Details 10.1. Hand Shape Initialization Obtaining hand silhouette groundtruth:As explained in the main paper, we use hand silhouette mask obtained from MANO mesh to initialize the NeRFs in stage 1. To this end, we first obtain hand mesh in diverse articulations using the code provided by MANO [41]. The hand mesh is then place...
-
[70]
A.3 Additional Studies In section 5.2 of the main paper, we justified CHS anneal- ing by the observation that SDS tends to perform more ge- ometric updates at higher noiset(lower iteration) and more texture updates at lowert(higher iteration). In Fig. 10 we provide two examples on this observation. It can be seen that the geometry of the 3D model is optim...
-
[71]
A.4 Additional Quantitative Analysis In this section, we provide analysis of both mean and stan- dard deviation of the proposed method compared to state- of-the-art in Table. 1. While methods such as OHTA [63] and Fantasia3D [5] generates results with lower standard deviation for CLIP L14, their mean scores are much lower compared to our method. Further, ...
-
[72]
Hand of Groot from Marvel
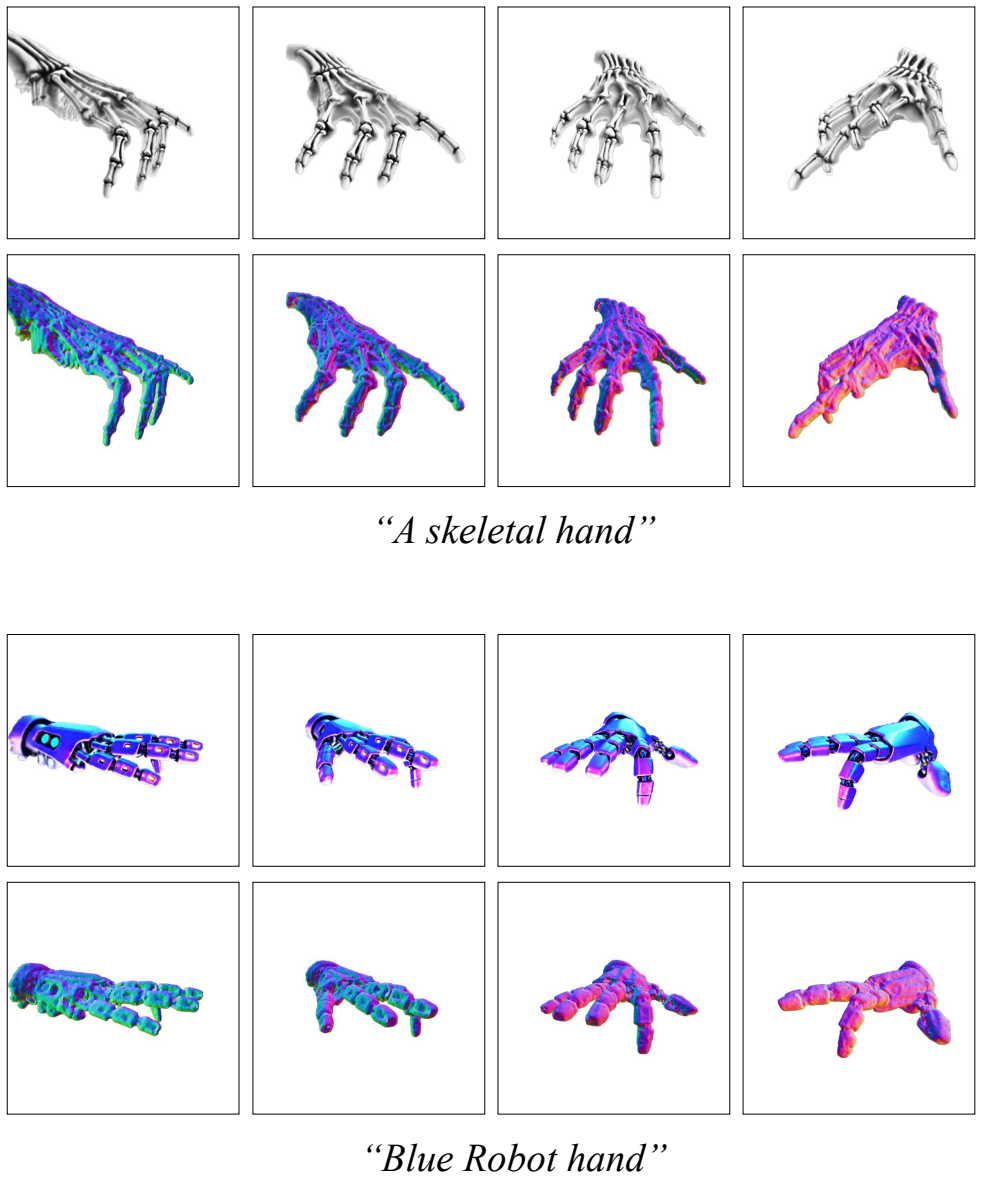
A.5 Additional Results We provide additional results from our method for multiple viewpoints for several prompts in Figures 11 to 16. It can be seen that our method generates high fidelity 3D models for a variety of text prompts. We have also provided videos in the multimedia supplementary. We also provide additional comparative studies against state-of-t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.