Recognition: 2 theorem links
· Lean TheoremRuling Out to Rule In: Contrastive Hypothesis Retrieval for Medical Question Answering
Pith reviewed 2026-05-10 20:08 UTC · model grok-4.3
The pith
By generating both a target diagnosis hypothesis and its most plausible incorrect alternative, CHR redirects retrieval to avoid hard-negative documents in medical QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CHR generates a target hypothesis H+ for the likely correct answer and a mimic hypothesis H- for the most plausible incorrect alternative, then scores documents by promoting H+-aligned evidence while penalizing H--aligned content.
What carries the argument
Contrastive Hypothesis Retrieval, which generates paired hypotheses and uses their contrast to promote target-aligned documents while suppressing mimic-aligned ones.
If this is right
- Retrieval sets change substantially rather than undergoing only light re-ranking.
- Performance gains hold across multiple benchmarks and answer generators.
- Hard-negative contamination from clinically similar conditions is reduced.
- Retrieval design can directly incorporate the logic of ruling out alternatives.
Where Pith is reading between the lines
- The same contrastive approach could be tested in other domains that feature plausible but incorrect alternatives, such as legal document retrieval.
- Improvements in how mimic hypotheses are generated might further increase the method's effectiveness without changing the core scoring step.
- Lower rates of retrieving near-miss conditions may reduce downstream errors in AI-supported clinical workflows.
Load-bearing premise
The automatically generated mimic hypothesis accurately identifies the most plausible wrong diagnosis and that penalizing its aligned documents does not remove evidence needed to support the correct diagnosis.
What would settle it
A new medical QA test set where CHR shows no accuracy gain over standard retrievers or where its top-5 documents largely overlap with those of a baseline even on cases where the final answers differ.
Figures




read the original abstract
Retrieval-augmented generation (RAG) grounds large language models in external medical knowledge, yet standard retrievers frequently surface hard negatives that are semantically close to the query but describe clinically distinct conditions. While existing query-expansion methods improve query representation to mitigate ambiguity, they typically focus on enriching target-relevant semantics without an explicit mechanism to selectively suppress specific, clinically plausible hard negatives. This leaves the system prone to retrieving plausible mimics that overshadow the actual diagnosis, particularly when such mimics are dominant within the corpus. We propose Contrastive Hypothesis Retrieval (CHR), a framework inspired by the process of clinical differential diagnosis. CHR generates a target hypothesis $H^+$ for the likely correct answer and a mimic hypothesis $H^-$ for the most plausible incorrect alternative, then scores documents by promoting $H^+$-aligned evidence while penalizing $H^-$-aligned content. Across three medical QA benchmarks and three answer generators, CHR outperforms all five baselines in every configuration, with improvements of up to 10.4 percentage points over the next-best method. On the $n=587$ pooled cases where CHR answers correctly while embedded hypothetical-document query expansion does not, 85.2\% have no shared documents between the top-5 retrieval lists of CHR and of that baseline, consistent with substantive retrieval redirection rather than light re-ranking of the same candidates. By explicitly modeling what to avoid alongside what to find, CHR bridges clinical reasoning with retrieval mechanism design and offers a practical path to reducing hard-negative contamination in medical RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contrastive Hypothesis Retrieval (CHR) for medical RAG-based QA. CHR generates a target hypothesis H+ for the likely correct diagnosis and a mimic hypothesis H- for the most plausible incorrect alternative, then scores documents by promoting H+-aligned evidence while penalizing H--aligned content. Evaluated on three medical QA benchmarks using three answer generators, CHR outperforms all five baselines in every configuration (gains up to 10.4 pp) and, on the 587 pooled cases where it succeeds over embedded hypothetical-document query expansion, 85.2% of CHR's top-5 retrieval sets share no documents with the baseline.
Significance. If the core assumptions hold, CHR offers a clinically motivated mechanism for reducing hard-negative contamination in medical retrieval by explicitly modeling differential diagnosis. The reported non-overlapping top-5 sets provide concrete evidence of retrieval redirection rather than superficial re-ranking, which is a strength. The approach could influence RAG design in high-stakes domains, but its significance is currently limited by the absence of validation for the mimic hypothesis quality and isolation of the penalization effect.
major comments (3)
- [Abstract] Abstract and Methods: No prompt templates, generation model details, or human/clinical validation of the mimic hypothesis H- are provided. This is load-bearing for the central claim, as the contrastive scoring (promote H+, penalize H-) only yields reliable redirection if H- is the single most plausible incorrect alternative; without such checks the 10.4 pp gains and 85.2% non-overlap could be artifacts of LLM priors rather than a clinical contrastive signal.
- [Experiments] Experiments: No ablation isolating the H- penalization term from the H+ expansion term is reported. The outperformance over all baselines and the non-overlapping retrieval statistic cannot be attributed specifically to the contrastive mechanism without this control, weakening the claim that explicitly modeling 'what to avoid' is the key innovation.
- [Results] Results: The manuscript states consistent outperformance across configurations but supplies no statistical significance tests, variance estimates, or controls for query difficulty, making it impossible to verify whether the reported improvements are robust or merely reflect baseline variability.
minor comments (2)
- [Methods] Notation for H^+ and H^- is introduced in the abstract but would benefit from an explicit formal definition and scoring equation in the methods section.
- The description of the five baselines should include precise citations and implementation details to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods: No prompt templates, generation model details, or human/clinical validation of the mimic hypothesis H- are provided. This is load-bearing for the central claim, as the contrastive scoring (promote H+, penalize H-) only yields reliable redirection if H- is the single most plausible incorrect alternative; without such checks the 10.4 pp gains and 85.2% non-overlap could be artifacts of LLM priors rather than a clinical contrastive signal.
Authors: We agree that prompt templates and generation model details are necessary for reproducibility and will add the exact prompts for H+ and H- generation, along with the LLM used and its parameters, to the Methods section. Regarding human or clinical validation of H-, this was not performed in the original study. The 85.2% non-overlap statistic and consistent gains across benchmarks provide supporting evidence that the contrastive signal contributes beyond generic LLM behavior, but we acknowledge the limitation and will add an explicit discussion of it plus suggestions for future clinician validation. revision: partial
-
Referee: [Experiments] Experiments: No ablation isolating the H- penalization term from the H+ expansion term is reported. The outperformance over all baselines and the non-overlapping retrieval statistic cannot be attributed specifically to the contrastive mechanism without this control, weakening the claim that explicitly modeling 'what to avoid' is the key innovation.
Authors: We agree that an ablation isolating the penalization term is needed to strengthen attribution to the contrastive mechanism. We will add this ablation (full CHR versus H+-only expansion) to the Experiments section and report the resulting performance differences. revision: yes
-
Referee: [Results] Results: The manuscript states consistent outperformance across configurations but supplies no statistical significance tests, variance estimates, or controls for query difficulty, making it impossible to verify whether the reported improvements are robust or merely reflect baseline variability.
Authors: We accept this critique on statistical rigor. We will add paired significance tests (e.g., McNemar's test) with p-values, variance estimates, and, where feasible, stratification by query difficulty to the Results section. revision: yes
- Human or clinical validation of the mimic hypotheses H- was not conducted in the original experiments.
Circularity Check
No circularity: CHR is a novel contrastive framework evaluated on external benchmarks
full rationale
The paper defines Contrastive Hypothesis Retrieval (CHR) as a new method that generates H+ (target hypothesis) and H- (mimic hypothesis) then applies contrastive scoring to promote aligned evidence for H+ while penalizing H--aligned content. This construction is presented as an original design inspired by clinical differential diagnosis, with performance claims resting on comparisons to five external baselines across three medical QA benchmarks. No equations, parameters, or steps in the abstract or described framework reduce by construction to fitted inputs, self-definitions, or prior self-citations. The reported gains (up to 10.4 pp) and non-overlapping retrieval sets are framed as empirical outcomes on held-out data rather than statistical artifacts of the method's own inputs. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a load-bearing way. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
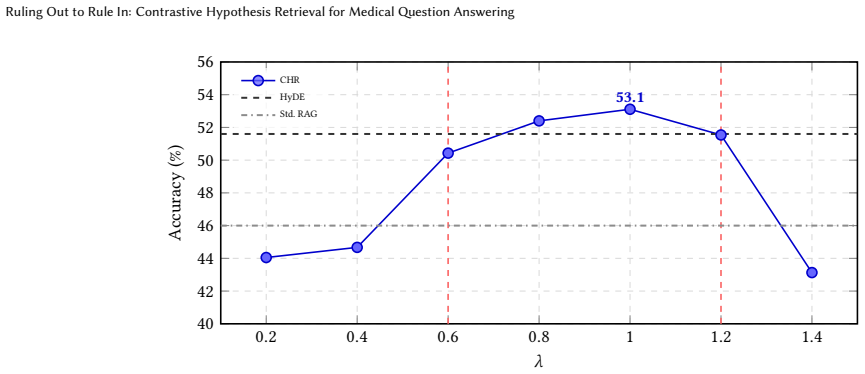
S(d)=Sim(d,H+)-λ·Sim(d,H-) ... equivalent to retrieving with a shifted query vector (H+ - λ H-)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CHR generates a target hypothesis H+ ... and a mimic hypothesis H- ... mirroring clinical differential diagnosis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InProceedings of the Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
2024
-
[2]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4854–4865. doi:10. 1145/3637528.3671470
-
[4]
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise Zero-Shot Dense Retrieval without Relevance Labels. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 1762–1777
2023
-
[5]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang
-
[6]
InProceed- ings of the 37th International Conference on Machine Learning (PMLR, Vol
REALM: Retrieval-Augmented Language Model Pre-Training. InProceed- ings of the 37th International Conference on Machine Learning (PMLR, Vol. 119). 3929–3938. Kim et al
-
[7]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Un- derstanding. InProceedings of the International Conference on Learning Represen- tations
2021
-
[8]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences11, 14 (2021), 6421. doi:10.3390/app11146421
-
[9]
Qiao Jin, Won Kim, Qingyu Chen, Donald C. Comeau, Lana Yeganova, W. John Wilbur, and Zhiyong Lu. 2023. MedCPT: Contrastive Pre-trained Transformers with Large-Scale PubMed Search Logs for Zero-Shot Biomedical Information Retrieval.Bioinformatics39, 11 (2023), btad651. doi:10.1093/bioinformatics/ btad651
-
[10]
Yibin Lei, Yu Cao, Tianyi Zhou, Tao Shen, and Andrew Yates. 2024. Corpus- Steered Query Expansion with Large Language Models. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Linguistics, 393–401. doi:10.18653/v1/2024.eacl-short.34
-
[11]
Yibin Lei, Tao Shen, and Andrew Yates. 2025. ThinkQE: Query Expansion via an Evolving Thinking Process. InFindings of the Association for Computational Linguistics: EMNLP 2025. 17772–17781. doi:10.18653/v1/2025.findings-emnlp.965
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. 9459–9474
2020
-
[13]
Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, et al. 2024. Gemma 2: Im- proving Open Language Models at a Practical Size.arXiv preprint arXiv:2408.00118 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Gumilang, Robert Wiliam, and Derwin Suhartono
Jessica Ryan, Alexander I. Gumilang, Robert Wiliam, and Derwin Suhartono. 2026. Self-MedRAG: A Self-Reflective Hybrid Retrieval-Augmented Generation Frame- work for Reliable Medical Question Answering.arXiv preprint arXiv:2601.04531 (2026)
-
[15]
Jiwoong Sohn, Yein Park, Chanwoong Yoon, Sihyeon Park, Hyeon Hwang, Mu- jeen Sung, Hyunjae Kim, and Jaewoo Kang. 2025. Rationale-Guided Retrieval Augmented Generation for Medical Question Answering. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computa- tional Linguistics. 12739–12753. doi:10.18653/v1/2025.naacl...
-
[16]
Albers, Dirk Akkermans, Paul Backfried, Sanne Hage, Anastasia Krithara, Georgios Paliouras, et al
George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R. Albers, Dirk Akkermans, Paul Backfried, Sanne Hage, Anastasia Krithara, Georgios Paliouras, et al. 2015. An Overview of the BIOASQ Large-Scale Biomedical Semantic Indexing and Question Answering Competition.BMC Bioinformatics16 (2015), 138. doi:10...
-
[17]
Liang Wang, Nan Yang, and Furu Wei. 2023. Query2doc: Query Expansion with Large Language Models. InProceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics, 9414–9423. doi:10.18653/v1/2023.emnlp-main.585
-
[18]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. 2024. Benchmarking Retrieval-Augmented Generation for Medicine. InFindings of the Association for Computational Linguistics: ACL 2024. doi:10.18653/v1/2024.findings-acl.372
-
[19]
An Yang, Baosong Yang, Beichen Zhang, et al. 2024. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115(2024). Ruling Out to Rule In: Contrastive Hypothesis Retrieval for Medical Question Answering A Additional Case Study Figure 4 presents an additional case study from MedQA, demonstrat- ing that CHR’s discriminative mechanism generalizes effectively...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.