Recognition: no theorem link
Is a Picture Worth a Thousand Words? Adaptive Multimodal Fact-Checking with Visual Evidence Necessity
Pith reviewed 2026-05-14 21:05 UTC · model grok-4.3
The pith
A two-model system that decides when visual evidence is needed outperforms standard multimodal fact-checking that always uses images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
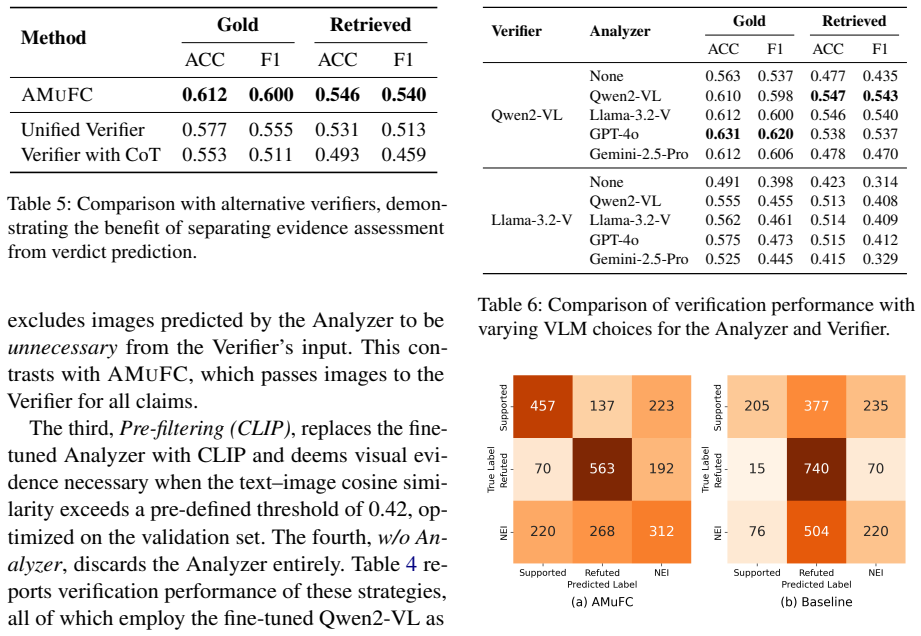
The central claim is that the indiscriminate use of multimodal evidence can reduce accuracy, and that incorporating the Analyzer's assessment of visual evidence necessity into the Verifier's prediction yields substantial improvements in verification performance on three datasets.
What carries the argument
The Analyzer-Verifier pair of collaborative vision-language models, where the Analyzer determines whether visual evidence is necessary and the Verifier conditions its veracity prediction on both the evidence and the Analyzer's output.
If this is right
- Selective use of visual evidence avoids accuracy losses that occur when irrelevant images are always incorporated.
- The two-model Analyzer-Verifier setup outperforms standard multimodal fusion methods across the evaluated datasets.
- Adaptive conditioning on necessity judgments improves claim veracity prediction reliability.
- The approach enables more targeted use of vision-language models rather than blanket multimodal input.
Where Pith is reading between the lines
- The same selective-modality idea could apply to deciding when to include audio or video evidence in verification tasks.
- Real-world deployment might gain efficiency by skipping image processing when the Analyzer deems it unnecessary.
- Future extensions could train the Analyzer and Verifier jointly to further reduce error propagation between them.
- The pattern connects to other multimodal problems where choosing which inputs to use beats always fusing everything.
Load-bearing premise
The Analyzer can reliably judge visual evidence necessity without introducing errors that degrade the Verifier's final predictions.
What would settle it
A side-by-side test on the three datasets in which adding the Analyzer's assessment produces no accuracy gain or an accuracy drop compared with standard multimodal fusion that always includes images.
Figures




read the original abstract
Automated fact-checking is a crucial task that supports a responsible information ecosystem. While recent research has progressed from text-only to multimodal fact-checking, a prevailing assumption is that incorporating visual evidence universally improves performance. In this work, we challenge this assumption and show that the indiscriminate use of multimodal evidence can reduce accuracy. To address this challenge, we propose AMuFC, a multimodal fact-checking framework that employs two collaborative vision-language models with distinct roles for the adaptive use of visual evidence: an Analyzer determines whether visual evidence is necessary for claim verification, and a Verifier predicts claim veracity conditioned on both the retrieved evidence and the Analyzer's assessment. Experimental results on three datasets show that incorporating the Analyzer's assessment of visual evidence necessity into the Verifier's prediction yields substantial improvements in verification performance. We will release all code and datasets at https://github.com/ssu-humane/AMuFC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AMuFC, a two-model collaborative framework for multimodal fact-checking in which an Analyzer vision-language model first determines whether visual evidence is necessary for verifying a given claim, and a Verifier model then predicts claim veracity conditioned on both the retrieved evidence and the Analyzer's necessity assessment. The central claim is that this adaptive conditioning yields measurable gains over text-only and always-multimodal baselines on three datasets, challenging the assumption that visual evidence should be used indiscriminately.
Significance. If the empirical gains are robustly demonstrated with ablations and error analysis, the work would be moderately significant for multimodal fact-checking: it supplies a concrete, testable mechanism for selective visual evidence use rather than universal fusion, and the planned release of code and datasets would support reproducibility and follow-up research.
minor comments (3)
- Abstract: the statement that the approach 'yields substantial improvements' is not accompanied by any numerical deltas, baseline names, or dataset identifiers; adding one or two concrete figures would make the contribution summary self-contained.
- Section 3 (framework description): the precise interface between Analyzer output and Verifier input (e.g., whether the necessity flag is a binary token, a soft probability, or a natural-language rationale) is not fully specified; a short pseudocode or input-format diagram would remove ambiguity.
- Experimental section: while the abstract mentions three datasets, the main text should explicitly list their names, sizes, and the exact train/dev/test splits used, together with the full set of baselines and the statistical significance tests applied to the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We are encouraged by the recognition that AMuFC provides a concrete mechanism for selective visual evidence use. We address the points below and will incorporate all suggested improvements in the revised manuscript.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces AMuFC as a new architecture with two distinct vision-language models (Analyzer for visual evidence necessity and Verifier for claim veracity), validated empirically on three external datasets via ablation comparisons to text-only and always-multimodal baselines. No equations, fitted parameters, or mathematical derivations are described that reduce to self-definition, self-citation chains, or imported ansatzes. The central performance claim rests on direct experimental measurements rather than any internal reduction to inputs by construction, rendering the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ChartCheck: Explainable fact-checking over real-world chart images. InFindings of the Associa- tion for Computational Linguistics: ACL 2024, pages 13921–13937, Bangkok, Thailand. Association for Computational Linguistics. Firoj Alam, Stefano Cresci, Tanmoy Chakraborty, Fab- rizio Silvestri, Dimiter Dimitrov, Giovanni Da San Martino, Shaden Shaar, Hamed Fi...
-
[2]
InProceedings of the 23rd in- ternational conference on world wide web, pages 743–748
Challenges of computational verification in social multimedia. InProceedings of the 23rd in- ternational conference on world wide web, pages 743–748. Brooke Borel. 2023.The Chicago guide to fact- checking. University of Chicago Press. Tobias Braun, Mark Rothermel, Marcus Rohrbach, and Anna Rohrbach. 2025. DEFAME: Dynamic Evidence-based FAct-checking with ...
-
[3]
MetaSumPerceiver: Multimodal multi- document evidence summarization for fact-checking. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8742–8757, Bangkok, Thailand. Association for Computational Linguistics. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachd...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
InProceedings of the 24th acm in- ternational on conference on information and knowl- edge management, pages 1835–1838
Detecting check-worthy factual claims in pres- idential debates. InProceedings of the 24th acm in- ternational on conference on information and knowl- edge management, pages 1835–1838. Silvan Heller, Luca Rossetto, and Heiko Schuldt
-
[5]
The PS-Battles Dataset - an Image Collection for Image Manipulation Detection
The ps-battles dataset-an image collection for image manipulation detection.arXiv preprint arXiv:1804.04866. Minyoung Huh, Andrew Liu, Andrew Owens, and Alexei A Efros. 2018. Fighting fake news: Image splice detection via learned self-consistency. InPro- ceedings of the European conference on computer vision (ECCV), pages 101–117. Aaron Hurst, Adam Lerer,...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Diversify-verify-adapt: Efficient and robust retrieval-augmented ambiguous question answering. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 1212–1233, Albuquerque, New Mexico. Association for Compu- tational Lingu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 360–381, Vienna, Austria
FACT-AUDIT: An adaptive multi-agent frame- work for dynamic fact-checking evaluation of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 360–381, Vienna, Austria. Association for Computational Lin- guistics. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae ...
2023
-
[8]
InPro- ceedings of the Twelfth Language Resources and Evaluation Conference, pages 6149–6157, Marseille, France
Fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. InPro- ceedings of the Twelfth Language Resources and Evaluation Conference, pages 6149–6157, Marseille, France. European Language Resources Association. Hui Pang, Chaozhuo Li, Litian Zhang, Senzhang Wang, and Xi Zhang. 2025. Beyond text: Fine-grained multi-modal fact verif...
2025
-
[9]
InCompanion Proceedings of the ACM on Web Con- ference 2025, pages 785–788
Fin-fact: A benchmark dataset for multimodal financial fact-checking and explanation generation. InCompanion Proceedings of the ACM on Web Con- ference 2025, pages 785–788. Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language P...
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Detecting cross-modal inconsistency to de- fend against neural fake news. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2081–2106, Online. Association for Computational Linguistics. Xiaqiang Tang, Qiang Gao, Jian Li, Nan Du, Qi Li, and Sihong Xie. 2025. MBA-RAG: a bandit approach for adaptive retri...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Fact-checking meets fauxtography: Verify- ing claims about images. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2099–2108, Hong Kong, China. Association for Computational Linguistics. Appendix A Experimental Details...
2019
-
[12]
Analyze the claim and the text evidence to understand the context
-
[13]
Assess whether the image evidence provides critical information not conveyed by the text alone
-
[14]
Google PhoneBook
Decide if the image evidence is necessary for verification or clarification. Respond only with ‘Yes’ if the image evidence is necessary or ‘No’ if it is not. Figure A1: Prompt used for Pre-filtering (Analyzer). Pre-filtering (CLIP)The fine-tuned CLIP model provided by Yao et al. (2023) was used to compute the cosine similarity between the claim text and t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.