Recognition: 3 theorem links
· Lean TheoremHallucination Basins: A Dynamic Framework for Understanding and Controlling LLM Hallucinations
Pith reviewed 2026-05-10 18:52 UTC · model grok-4.3
The pith
Hallucinations in large language models arise from task-dependent basin structures in their latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
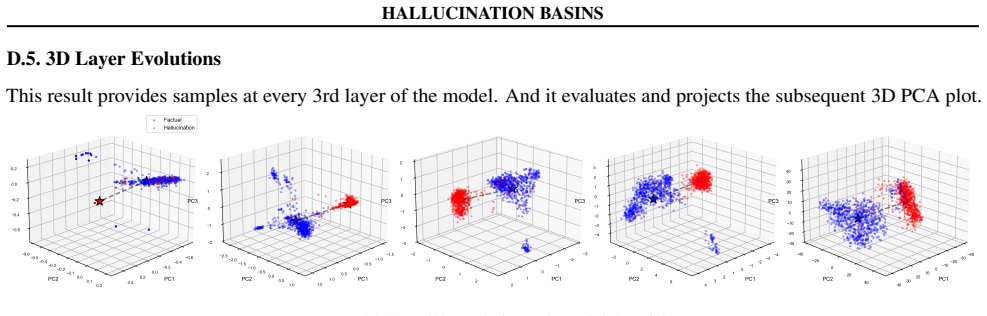
Hallucinations emerge from task-dependent basin structure in latent space. Autoregressive hidden-state trajectories exhibit separability that varies strongly with task type, formalized through task-complexity and multi-basin theorems that characterize basin emergence across transformer layers. Geometry-aware steering then reduces hallucination probability by manipulating these structures.
What carries the argument
Task-dependent basin structure in latent space, identified via separability of autoregressive hidden-state trajectories and manipulated through geometry-aware steering.
If this is right
- Geometry-aware steering lowers hallucination rates on factoid tasks while leaving the underlying model weights unchanged.
- Basin separability weakens on summarization and complex-reasoning tasks, limiting the immediate reach of steering.
- Task-complexity and multi-basin theorems predict how basins form across the layers of an L-layer transformer.
- The same geometric view can be used to compare hallucination behavior across different open-source model families.
Where Pith is reading between the lines
- If the basins prove causal, the same steering approach could be tested on other generation failures such as inconsistency or bias.
- Accessing hidden states in closed models would require new interfaces before the method can be applied at scale.
- Training objectives that penalize basin formation might yield more robust models from the start.
- The dynamical-systems framing invites direct comparisons with basin analyses in other sequential models such as those used in reinforcement learning.
Load-bearing premise
The separated regions visible in hidden-state trajectories reflect causal basin structures that can be steered reliably rather than mere correlations or model-specific artifacts.
What would settle it
Apply the proposed geometry-aware steering to a held-out model and task and measure whether hallucination rates stay the same or increase instead of decreasing.
Figures




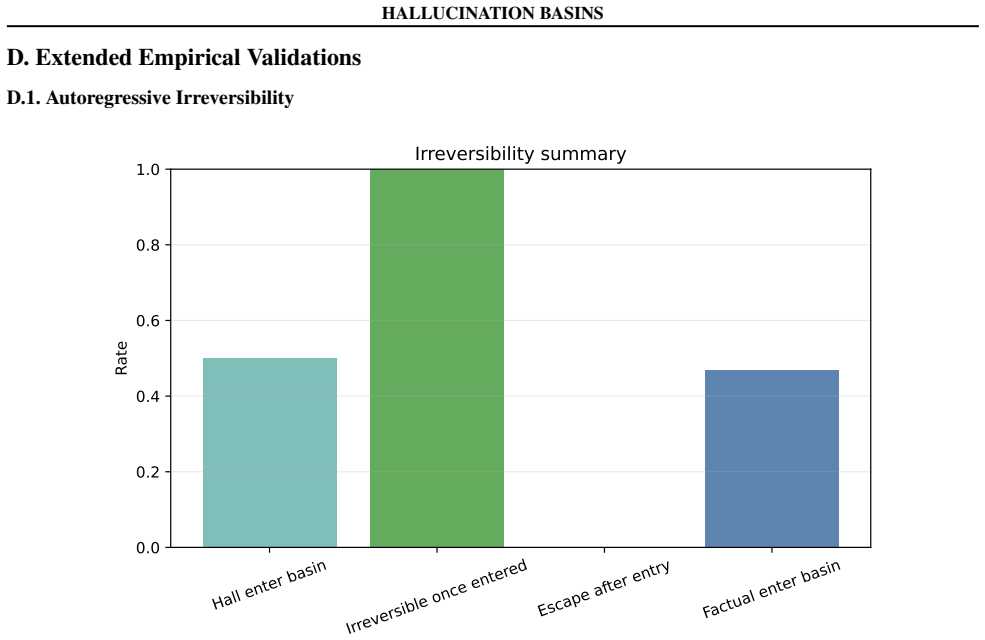
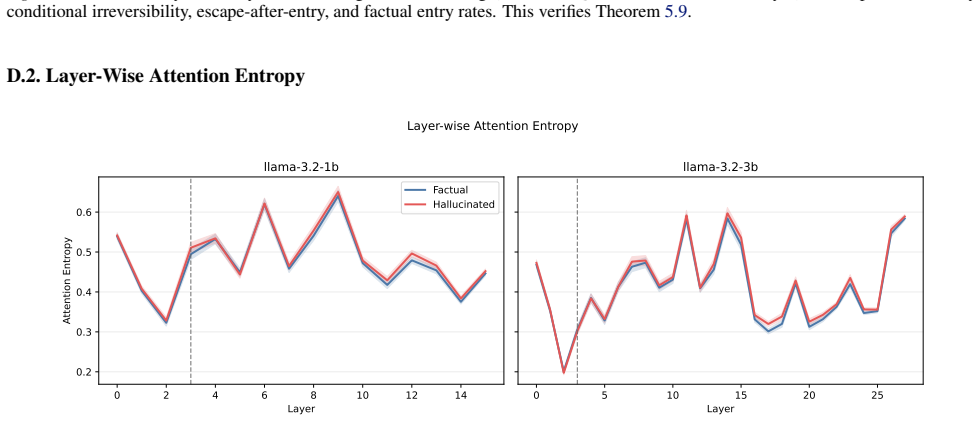
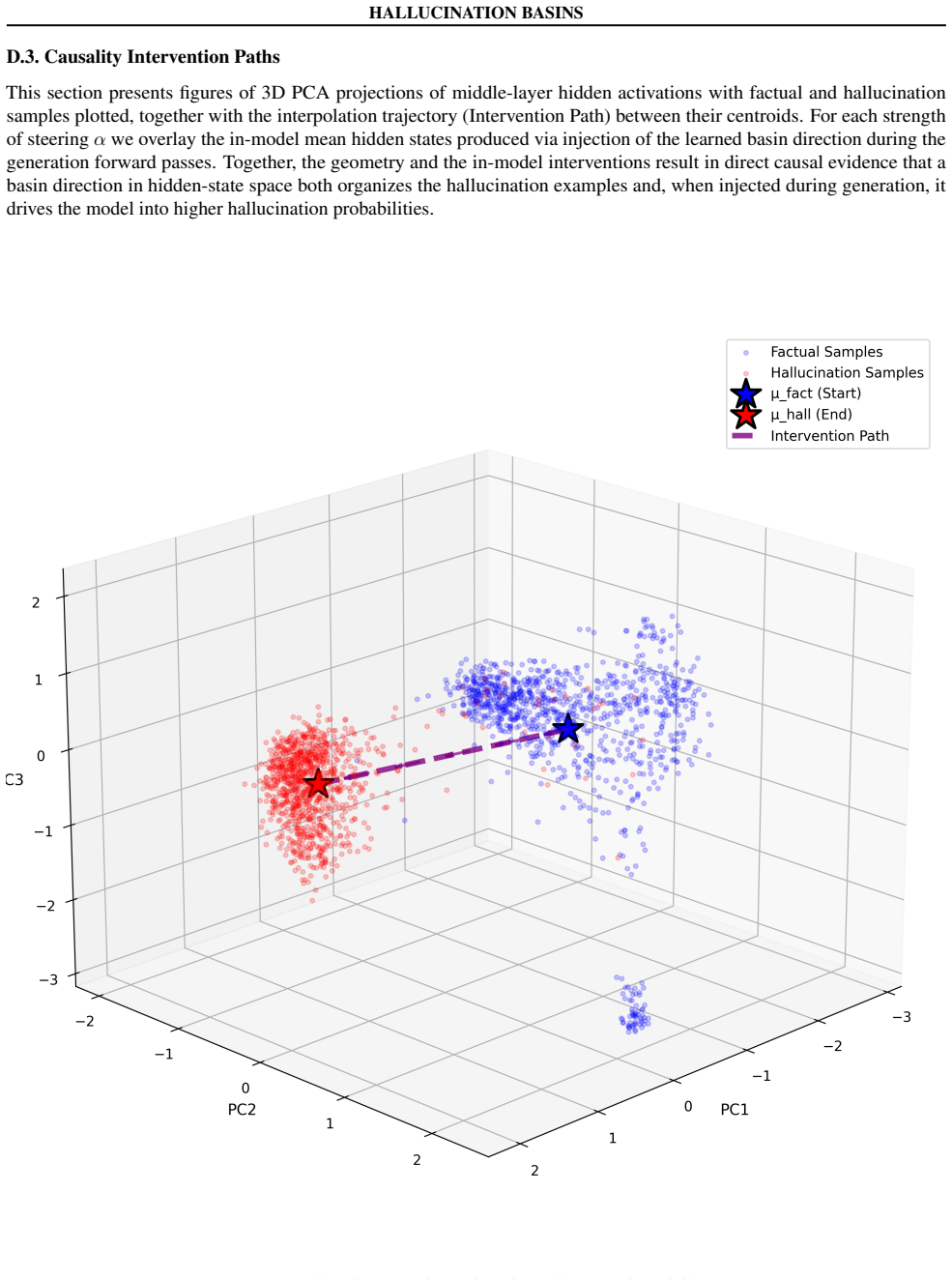
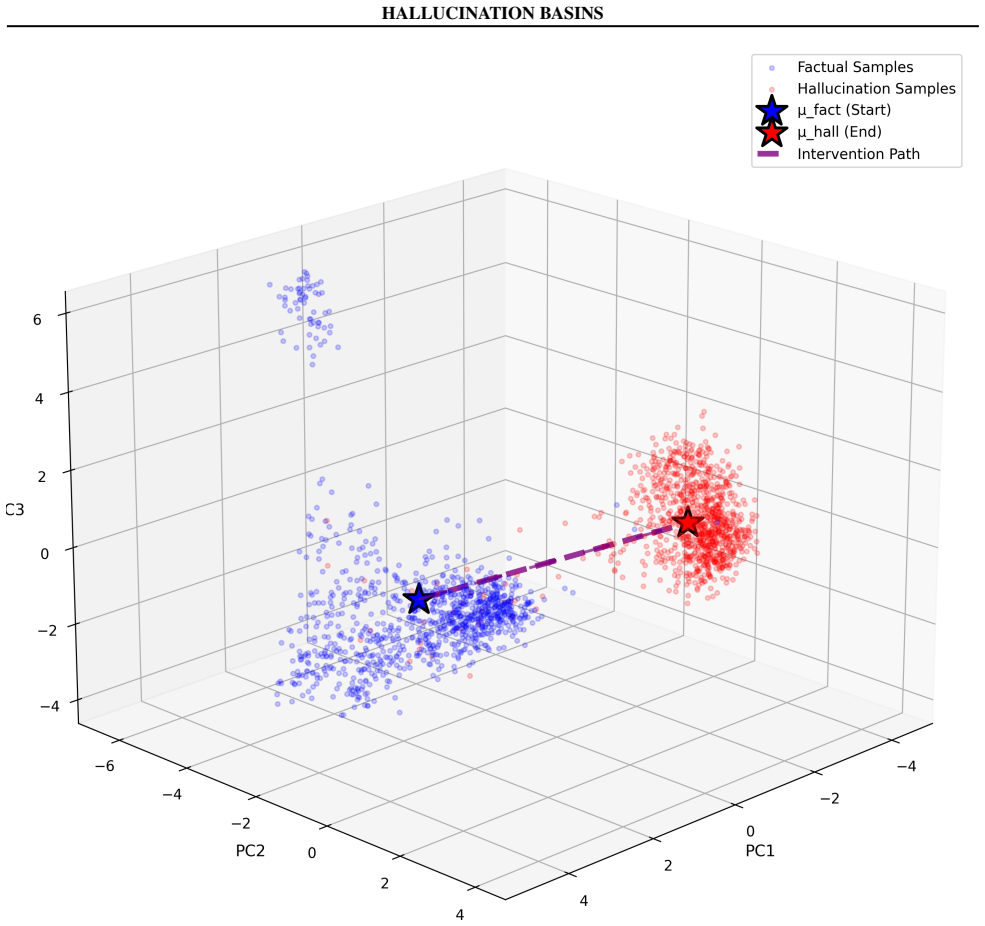








read the original abstract
Large language models (LLMs) hallucinate: they produce fluent outputs that are factually incorrect. We present a geometric dynamical systems framework in which hallucinations arise from task-dependent basin structure in latent space. Using autoregressive hidden-state trajectories across multiple open-source models and benchmarks, we find that separability is strongly task-dependent rather than universal: factoid settings can show clearer basin separation, whereas summarization and misconception-heavy settings are typically less stable and often overlap. We formalize this behavior with task-complexity and multi-basin theorems, characterize basin emergence in L-layer transformers, and show that geometry-aware steering can reduce hallucination probability without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a geometric dynamical systems framework in which LLM hallucinations arise from task-dependent basin structures in latent space, identified via autoregressive hidden-state trajectories. It reports that basin separability varies by task (clearer in factoid settings, less stable in summarization or misconception-heavy ones), formalizes this via task-complexity and multi-basin theorems, characterizes basin emergence in L-layer transformers, and shows that geometry-aware steering of hidden states during generation reduces hallucination probability without retraining, across multiple open-source models and benchmarks.
Significance. If the central claims hold, the framework would supply a new dynamical-systems lens on hallucinations and a practical, training-free control method via latent-space steering. The task-dependent separability finding and the theorems on basin emergence could influence both mechanistic interpretability and deployment strategies for reliable generation.
major comments (3)
- [Steering Experiments] The steering experiments (described after the theorems) do not include controls that preserve magnitude and directional statistics of the hidden-state updates while removing the specific basin-derived geometry; without such isolation it is impossible to attribute the reported drop in hallucination probability to basin navigation rather than generic distributional shifts.
- [Formal Theorems] The task-complexity and multi-basin theorems are stated without proof sketches, derivation steps, or explicit assumptions on the hidden-state dynamics; this leaves the formalization of separability unverified and makes it difficult to assess whether the reported task dependence follows from the geometry or is partly definitional.
- [Abstract and Experimental Results] The abstract and experimental sections assert results across multiple models and benchmarks, yet supply no methods subsection detailing trajectory extraction, basin identification procedure, evaluation metrics, or error analysis; the central empirical claims therefore cannot be reproduced or evaluated from the provided information.
minor comments (2)
- [Notation] Notation for basin boundaries and the separability metric is introduced without a dedicated definitions subsection, making cross-references to the theorems harder to follow.
- [Results] The manuscript would benefit from a table summarizing separability statistics (e.g., overlap measures) per task and model rather than only qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below with clarifications and commit to targeted revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The steering experiments (described after the theorems) do not include controls that preserve magnitude and directional statistics of the hidden-state updates while removing the specific basin-derived geometry; without such isolation it is impossible to attribute the reported drop in hallucination probability to basin navigation rather than generic distributional shifts.
Authors: We agree that isolating the contribution of basin-derived geometry from generic distributional shifts would strengthen causal attribution. In the revised manuscript we will add control conditions that generate hidden-state updates matching the empirical magnitude and directional statistics of the steering vectors but drawn from non-basin directions; we will report the resulting hallucination rates alongside the original geometry-aware results. revision: yes
-
Referee: The task-complexity and multi-basin theorems are stated without proof sketches, derivation steps, or explicit assumptions on the hidden-state dynamics; this leaves the formalization of separability unverified and makes it difficult to assess whether the reported task dependence follows from the geometry or is partly definitional.
Authors: The theorems formalize observed separability patterns under the autoregressive trajectory model; however, we acknowledge that explicit assumptions and derivation steps are needed for verification. We will append a supplementary section containing the full statements with proof sketches, the precise dynamical assumptions on hidden-state evolution, and a discussion of how task dependence emerges from the geometry rather than by definition. revision: yes
-
Referee: The abstract and experimental sections assert results across multiple models and benchmarks, yet supply no methods subsection detailing trajectory extraction, basin identification procedure, evaluation metrics, or error analysis; the central empirical claims therefore cannot be reproduced or evaluated from the provided information.
Authors: We recognize that a self-contained methods subsection is required for reproducibility. Although the main text describes the overall pipeline, we will expand the experimental section with a dedicated methods subsection that specifies the exact trajectory extraction procedure, basin identification algorithm, evaluation metrics, statistical tests, and error analysis protocol, including any preprocessing steps applied to the hidden states. revision: yes
Circularity Check
Basin separability observed in trajectories is used both to define and to evidence the claimed causal basin structure
specific steps
-
self definitional
[Abstract]
"Using autoregressive hidden-state trajectories across multiple open-source models and benchmarks, we find that separability is strongly task-dependent rather than universal: factoid settings can show clearer basin separation, whereas summarization and misconception-heavy settings are typically less stable and often overlap. We formalize this behavior with task-complexity and multi-basin theorems, characterize basin emergence in L-layer transformers, and show that geometry-aware steering can reduce hallucination probability without retraining."
Separability is measured in the trajectories and immediately labeled 'basin separation'; the same separability is then cited as evidence that hallucinations arise from the basin structure. Because the basin structure is defined by the observed separability patterns in the identical data, the causal attribution reduces to a restatement of the input observation rather than an independent derivation.
full rationale
The paper's core claim is that hallucinations arise from task-dependent basin structure in latent space, with separability in autoregressive hidden-state trajectories presented as evidence. However, the basins appear to be characterized directly from the separability patterns in those same trajectories (factoid vs. summarization settings), after which the framework formalizes the behavior via theorems and attributes causality. This makes the reported separability partly definitional rather than an independent test of an a priori basin model. Steering results are not shown to isolate the specific geometry from generic distributional shifts. No load-bearing self-citations or external uniqueness theorems are invoked in the provided text, so the circularity is limited to the observation-to-framework step rather than a full self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive hidden-state trajectories capture the relevant dynamical structure that determines factual correctness.
invented entities (1)
-
task-dependent hallucination basins
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a geometric dynamical systems framework in which hallucinations arise from task-dependent basin structure in latent space... reference states μ(ℓ)... radial contraction... variance ratio ρ_var ≥ C log(|A|+1)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.9 (Trajectory trapping under a persistent contraction)... ∥h(ℓ)(x)−μ(ℓ)∥₂ ≤ ᾱ^{ℓ−ℓ₁} r
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.12 (Multi-basin partitioning)... Voronoi tessellation into K basins
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Hallucination as Trajectory Commitment: Causal Evidence for Asymmetric Attractor Dynamics in Transformer Generation
Hallucination is an early trajectory commitment in transformers governed by asymmetric attractor dynamics, with prompt encoding selecting the basin and correction needing multi-step intervention.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Large language models hallucination: A comprehensive survey.arXiv preprint arXiv:2510.06265, 2025
Alansari, A. and Luqman, H. Large language models hallucination: A comprehensive survey. arXiv:2510.06265, 2025
-
[3]
Chen, B. and Zhang, H. High-order rotor H opfield neural networks for associative memory. Neurocomputing, 616: 0 128893, 2025. doi:10.1016/j.neucom.2024.128893
-
[4]
Chen, C., Liu, K., Chen, Z., Gu, Y., Wu, Y., Tao, M., Fu, Z., and Ye, J. INSIDE : LLMs' internal states retain the power of hallucination detection. arXiv:2402.03744, 2024 a
-
[5]
In-context sharpness as alerts: An inner representation perspective for hallucination mitigation
Chen, S., Xiong, M., Liu, J., Wu, Z., Xiao, T., Gao, S., and He, J. In-context sharpness as alerts: An inner representation perspective for hallucination mitigation. In Proceedings of the 41st International Conference on Machine Learning, pp.\ 7553--7567, 2024 b
2024
-
[6]
Essex, A. E., Janson, N. B., Norris, R. A., and Balanov, A. G. Memorisation and forgetting in a learning H opfield neural network: bifurcation mechanisms, attractors and basins. arXiv:2508.10765, 2025
-
[7]
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y. Detecting hallucinations in large language models using semantic entropy. Nature, 630: 0 625--630, 2024. doi:10.1038/s41586-024-07421-0
-
[8]
Hopfield, J. J. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, 79 0 (8): 0 2554--2558, 1982. doi:10.1073/pnas.79.8.2554
-
[9]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43 0 (2): 0 42, 2025. doi:10.1145/3703155
-
[10]
Associative memory model with neural networks: Memorizing multiple images with one neuron
Inazawa, H. Associative memory model with neural networks: Memorizing multiple images with one neuron. arXiv:2510.06542, 2025
-
[11]
S., Krotov, D., Bicknell, B
Kafraj, M. S., Krotov, D., Bicknell, B. A., and Latham, P. E. A biologically plausible associative memory network. In ICLR 2025 Workshop on New Frontiers in Associative Memories, 2025. URL https://openreview.net/forum?id=u4YzOzEMfR
2025
-
[12]
(Im) possibility of automated hallucination detection in large language models
Karbasi, A., Montasser, O., Sous, J., and Velegkas, G. (Im) possibility of automated hallucination detection in large language models. In ICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025. URL https://openreview.net/forum?id=B4SFmNvBNz
2025
-
[13]
Li, J., Cheng, X., Zhao, W. X., Nie, J.-Y., and Wen, J.-R. HaluEval : A large-scale hallucination evaluation benchmark for large language models. arXiv:2305.11747, 2023
-
[14]
Dynamic analysis and implementation of a multi-stable H opfield neural network
Li, X., Luo, M., Zhang, B., and Liu, S. Dynamic analysis and implementation of a multi-stable H opfield neural network. Chaos, Solitons & Fractals, 199: 0 116657, 2025. doi:10.1016/j.chaos.2025.116657
-
[15]
TruthfulQA : Measuring how models mimic human falsehoods
Lin, S., Hilton, J., and Evans, O. TruthfulQA : Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pp.\ 3214--3252, 2022
2022
-
[16]
Least Squares Quantization in PCM,
Lloyd, S. Least squares quantization in PCM . IEEE Transactions on Information Theory, 28 0 (2): 0 129--137, 1982. doi:10.1109/TIT.1982.1056489
-
[17]
SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models
Manakul, P., Liusie, A., and Gales, M. SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 9004--9017, 2023
2023
-
[18]
The Meta Llama 3.2 collection of multilingual language models
Meta AI . The Meta Llama 3.2 collection of multilingual language models. https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md, 2024. Accessed: 2026-01-15
2024
-
[19]
Steer LLM latents for hallucination detection
Park, S., Du, X., Yeh, M.-H., Wang, H., and Li, Y. Steer LLM latents for hallucination detection. In Proceedings of the Forty-second International Conference on Machine Learning, pp.\ 47971--47990, 2025
2025
-
[20]
Pezzulo, G., LaPalme, J., Durant, F., and Levin, M. Bistability of somatic pattern memories: stochastic outcomes in bioelectric circuits underlying regeneration. Philosophical Transactions of the Royal Society B: Biological Sciences, 376 0 (1821): 0 20190765, 2021. doi:10.1098/rstb.2019.0765
-
[21]
K., Klambauer, G., Brandstetter, J., and Hochreiter, S
Ramsauer, H., Sch \" a fl, B., Lehner, J., Seidl, P., Widrich, M., Gruber, L., Holzleitner, M., Adler, T., Kreil, D., Kopp, M. K., Klambauer, G., Brandstetter, J., and Hochreiter, S. Hopfield networks is all you need. In Proceedings of the 9th International Conference on Learning Representations, 2021
2021
-
[22]
Gemma 2: Improving Open Language Models at a Practical Size
Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram \'e , A., et al. Gemma 2: Improving open language models at a practical size. arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
R., Saxena, A., Maharaj, K., Ahmad, A
Sahoo, N. R., Saxena, A., Maharaj, K., Ahmad, A. A., Mishra, A., and Bhattacharyya, P. Addressing bias and hallucination in large language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, pp.\ 73--79, 2024
2024
-
[24]
S., Saha, S., Kattakinda, P., and Feizi, S
Sriramanan, G., Bharti, S., Sadasivan, V. S., Saha, S., Kattakinda, P., and Feizi, S. LLM-Check : Investigating detection of hallucinations in large language models. In Advances in Neural Information Processing Systems, volume 37, pp.\ 34188--34216. 2024
2024
-
[25]
Why and how LLM s hallucinate: Connecting the dots with subsequence associations
Sun, Y., Gai, Y., Chen, L., Ravichander, A., Choi, Y., Dziri, N., and Song, D. Why and how LLM s hallucinate: Connecting the dots with subsequence associations. In Advances in Neural Information Processing Systems, volume 37, pp.\ 34188--34216. 2025 a
2025
-
[26]
Associative transformer
Sun, Y., Ochiai, H., Wu, Z., Lin, S., and Kanai, R. Associative transformer. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference, pp.\ 4518--4527, 2025 b
2025
-
[27]
Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability,
Sun, Z., Zang, X., Zheng, K., Song, Y., Xu, J., Zhang, X., Yu, W., and Li, H. ReDeEP : Detecting hallucination in retrieval-augmented generation via mechanistic interpretability. arXiv:2410.11414, 2024
-
[28]
InterpDetect : Interpretable signals for detecting hallucinations in retrieval-augmented generation
Tan, L., Huang, K.-W., Shi, J., and Wu, K. InterpDetect : Interpretable signals for detecting hallucinations in retrieval-augmented generation. arXiv:2510.21538, 2025
-
[29]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mittal, A. FEVER : a large-scale dataset for F act E xtraction and VER ification. In Walker, M., Ji, H., and Stent, A. (eds.), Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics , pp.\ 809--819, June 2018. doi:10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[30]
M u S i Q ue: Multihop questions via single-hop question composition
Trivedi, H., Balasubramanian, N., Khot, T., and Sabharwal, A. MuSiQue : Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10: 0 539--554, 2022. doi:10.1162/tacl_a_00475
-
[31]
Varshney, K. R. Generalization error of linear discriminant analysis in spatially-correlated sensor networks. IEEE Transactions on Signal Processing, 60 0 (6): 0 3295--3301, 2012. doi:10.1109/TSP.2012.2190063
-
[32]
Adaptive activation steering: A tuning-free LLM truthfulness improvement method for diverse hallucinations categories
Wang, T., Jiao, X., Zhu, Y., Chen, Z., He, Y., Chu, X., Gao, J., Wang, Y., and Ma, L. Adaptive activation steering: A tuning-free LLM truthfulness improvement method for diverse hallucinations categories. In Proceedings of the ACM on Web Conference 2025, pp.\ 2562--2578, 2025
2025
-
[33]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Alleviating hallucinations in large language models through multi-model contrastive decoding and dynamic hallucination detection
Zhu, C., Liu, Y., Zhang, H., Wang, A., Chen, G., Wang, L., Luo, W., Zhang, K., et al. Alleviating hallucinations in large language models through multi-model contrastive decoding and dynamic hallucination detection. In Advances in Neural Information Processing Systems, volume 39. 2025
2025
-
[35]
Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models
Zou, X., Wang, Y., Yan, Y., Lyu, Y., Zheng, K., Huang, S., Chen, J., Jiang, P., Liu, J., Tang, C., and Hu, X. Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models. In Proceedings of the 42nd International Conference on Machine Learning, pp.\ 80873--80899, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.