Recognition: 2 theorem links
· Lean TheoremAnyUser: Translating Sketched User Intent into Domestic Robots
Pith reviewed 2026-05-10 19:14 UTC · model grok-4.3
The pith
AnyUser translates free-form sketches on camera images, with optional language, into executable domestic robot actions without prior maps or models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
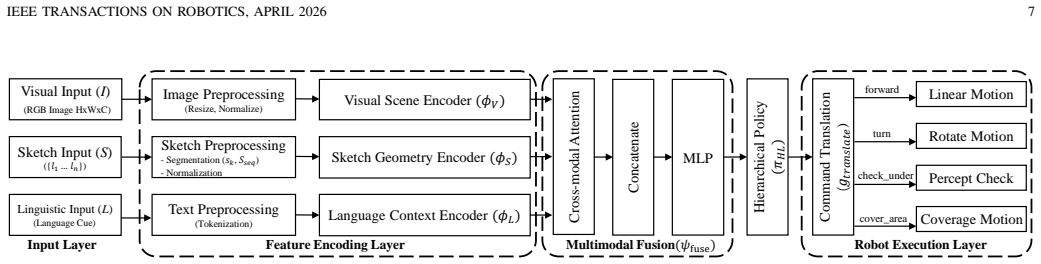
AnyUser interprets multimodal inputs (sketch, vision, language) as spatial-semantic primitives to generate executable robot actions requiring no prior maps or models. Novel components include multimodal fusion for understanding and a hierarchical policy for robust action generation. Efficacy is shown via quantitative benchmarks on large-scale datasets, real-world validation on two robotic platforms performing targeted wiping and area cleaning, and a user study with diverse demographics achieving 85.7%-96.4% task completion rates.
What carries the argument
Interpretation of sketches on camera images together with vision and optional language as spatial-semantic primitives, fused multimodally and executed by a hierarchical policy.
If this is right
- High accuracy interpreting diverse sketch commands across simulated domestic scenes.
- Reliable execution of tasks such as targeted wiping and area cleaning on two distinct physical robots.
- Significant usability gains and high task completion for elderly users, simulated non-verbal users, and those with low technical literacy.
- Removal of the need for prior maps or models in domestic robot instruction.
Where Pith is reading between the lines
- The same sketch-on-image method could be tested in non-domestic settings such as workshops or warehouses where quick visual instructions are useful.
- Combining the primitive extraction with existing language models might allow more complex multi-step commands without additional training data.
- If the mapping from sketch to primitive holds across lighting and clutter variations, it could lower the cost of deploying robots in new homes.
Load-bearing premise
Free-form user sketches on camera images can be reliably mapped to spatial-semantic primitives that produce correct robot actions across diverse real domestic scenes without prior environment models.
What would settle it
A controlled trial in which participants draw sketches for unseen domestic scenes on a new robot platform and the system produces incorrect or incomplete actions more than 20 percent of the time.
Figures





read the original abstract
We introduce AnyUser, a unified robotic instruction system for intuitive domestic task instruction via free-form sketches on camera images, optionally with language. AnyUser interprets multimodal inputs (sketch, vision, language) as spatial-semantic primitives to generate executable robot actions requiring no prior maps or models. Novel components include multimodal fusion for understanding and a hierarchical policy for robust action generation. Efficacy is shown via extensive evaluations: (1) Quantitative benchmarks on the large-scale dataset showing high accuracy in interpreting diverse sketch-based commands across various simulated domestic scenes. (2) Real-world validation on two distinct robotic platforms, a statically mounted 7-DoF assistive arm (KUKA LBR iiwa) and a dual-arm mobile manipulator (Realman RMC-AIDAL), performing representative tasks like targeted wiping and area cleaning, confirming the system's ability to ground instructions and execute them reliably in physical environments. (3) A comprehensive user study involving diverse demographics (elderly, simulated non-verbal, low technical literacy) demonstrating significant improvements in usability and task specification efficiency, achieving high task completion rates (85.7%-96.4%) and user satisfaction. AnyUser bridges the gap between advanced robotic capabilities and the need for accessible non-expert interaction, laying the foundation for practical assistive robots adaptable to real-world human environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnyUser, a unified system for domestic robot instruction that translates free-form sketches drawn on camera images (optionally augmented with language) into executable actions. It interprets multimodal inputs as spatial-semantic primitives via a novel multimodal fusion module and generates actions through a hierarchical policy, explicitly without requiring prior maps or environment models. Efficacy is demonstrated in three pillars: quantitative benchmarks on a large-scale simulated dataset, real-robot validation on a KUKA LBR iiwa arm and a Realman dual-arm mobile manipulator for targeted wiping and area cleaning, and a user study with diverse participants (including elderly and low-literacy users) reporting task completion rates of 85.7–96.4 %.
Significance. If the supporting evidence is robust, AnyUser would advance accessible HRI by removing the need for environment modeling, a practical barrier for domestic deployment. The multi-platform physical validation and inclusion of non-expert user demographics are strengths that align with real-world assistive robotics needs. Credit is due for the explicit no-prior-map design and the three-pillar evaluation structure that directly tests generalization.
major comments (2)
- [§5.1] §5.1 (Quantitative benchmarks): The abstract and evaluation summary state 'high accuracy' for sketch-based command interpretation across simulated scenes, but no numerical accuracy values, baseline comparisons, or error breakdowns are provided; this is load-bearing for the central claim that multimodal fusion reliably extracts spatial-semantic primitives.
- [§5.2] §5.2 (Real-world validation): Successful execution is claimed on two distinct platforms for wiping and cleaning tasks without prior maps, yet no per-task success rates, failure-mode analysis, or quantitative grounding metrics are reported (in contrast to the user-study percentages); this weakens support for reliable action generation in physical domestic scenes.
minor comments (2)
- [Abstract] The abstract would be strengthened by including the exact accuracy figures from the simulated benchmarks to allow immediate assessment of the quantitative claims.
- [Methods] Notation for the spatial-semantic primitives and the hierarchical policy decomposition should be defined more explicitly in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the quantitative support of our claims. We address each major comment point by point below, indicating revisions to the manuscript.
read point-by-point responses
-
Referee: [§5.1] §5.1 (Quantitative benchmarks): The abstract and evaluation summary state 'high accuracy' for sketch-based command interpretation across simulated scenes, but no numerical accuracy values, baseline comparisons, or error breakdowns are provided; this is load-bearing for the central claim that multimodal fusion reliably extracts spatial-semantic primitives.
Authors: We agree that the abstract and high-level summary would benefit from explicit numerical values to support the 'high accuracy' claim. Section 5.1 presents results from the large-scale simulated dataset, including accuracy for the multimodal fusion module across tasks and scenes. In the revision, we will update the abstract and §5.1 summary to report specific metrics (e.g., overall accuracy, per-primitive F1 scores) along with baseline comparisons and an expanded error breakdown by sketch type and environmental complexity. revision: yes
-
Referee: [§5.2] §5.2 (Real-world validation): Successful execution is claimed on two distinct platforms for wiping and cleaning tasks without prior maps, yet no per-task success rates, failure-mode analysis, or quantitative grounding metrics are reported (in contrast to the user-study percentages); this weakens support for reliable action generation in physical domestic scenes.
Authors: The real-world experiments in §5.2 validate the no-prior-map design on the KUKA LBR iiwa and Realman platforms for targeted wiping and area cleaning. While success is shown qualitatively and via the user study, we concur that quantitative per-task rates and analysis would improve rigor. We will revise §5.2 to include a table of success rates per task and platform, a failure-mode discussion (e.g., grounding errors from ambiguous sketches), and quantitative grounding metrics such as mean pixel deviation between sketched intent and executed regions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript is a system-description paper that introduces AnyUser as a multimodal robotic instruction framework. It defines components (multimodal fusion, hierarchical policy) and evaluates them via independent benchmarks on a large-scale dataset, physical robot trials on two platforms, and a user study with reported completion rates. No equations, parameter-fitting steps, derivations, or self-referential claims appear in the provided text or abstract. All load-bearing assertions are supported by external empirical results rather than reducing to definitions or prior self-citations, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User sketches on images can be consistently interpreted as spatial-semantic primitives for robot actions
invented entities (1)
-
AnyUser system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AnyUser interprets multimodal inputs (sketch, vision, language) as spatial-semantic primitives to generate executable robot actions requiring no prior maps or models. Novel components include multimodal fusion for understanding and a hierarchical policy for robust action generation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The multimodal fusion network then associates sketch elements with visual regions using cross-modal attention and conditions interpretation on language.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Understanding natural language commands for robotic navigation and mobile manipulation,
S. Tellex, T. Kollar, S. Dickerson, M. Walter, A. Banerjee, S. Teller, and N. Roy, “Understanding natural language commands for robotic navigation and mobile manipulation,” inProceedings of the AAAI conference on artificial intelligence, vol. 25, no. 1, 2011, pp. 1507– 1514
2011
-
[3]
Natural language communication with robots,
Y . Bisk, D. Yuret, and D. Marcu, “Natural language communication with robots,” inProceedings of the 2016 conference of the North American chapter of the association for computational linguistics: Human language technologies, 2016, pp. 751–761
2016
-
[4]
Alfred: A benchmark for interpret- ing grounded instructions for everyday tasks,
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpret- ing grounded instructions for everyday tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 740–10 749
2020
-
[5]
Ghallab, D
M. Ghallab, D. Nau, and P. Traverso,Automated Planning: theory and practice. Elsevier, 2004
2004
-
[6]
Fan-out: Measuring human control of multiple robots,
D. R. Olsen Jr and S. B. Wood, “Fan-out: Measuring human control of multiple robots,” inProceedings of the SIGCHI conference on Human factors in computing systems, 2004, pp. 231–238
2004
-
[7]
Vid2param: Modeling of dynamics parameters from video,
M. Asenov, M. Burke, D. Angelov, T. Davchev, K. Subr, and S. Ra- mamoorthy, “Vid2param: Modeling of dynamics parameters from video,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 414– 421, 2019
2019
-
[8]
Learning hand-eye coordination for robotic grasping with deep learning and large- scale data collection,
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large- scale data collection,”The International journal of robotics research, vol. 37, no. 4-5, pp. 421–436, 2018
2018
-
[9]
P. R. Florence, L. Manuelli, and R. Tedrake, “Dense object nets: Learn- ing dense visual object descriptors by and for robotic manipulation,” arXiv preprint arXiv:1806.08756, 2018
-
[10]
Robonet: Large-scale multi-robot learning,
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn, “Robonet: Large-scale multi-robot learning,”arXiv preprint arXiv:1910.11215, 2019
-
[11]
Using a hand-drawn sketch to control a team of robots,
M. Skubic, D. Anderson, S. Blisard, D. Perzanowski, and A. Schultz, “Using a hand-drawn sketch to control a team of robots,”Autonomous Robots, vol. 22, pp. 399–410, 2007
2007
-
[12]
Interactive sketch-driven image synthesis,
D. Turmukhambetov, N. D. Campbell, D. B. Goldman, and J. Kautz, “Interactive sketch-driven image synthesis,” inComputer graphics fo- rum, vol. 34, no. 8. Wiley Online Library, 2015, pp. 130–142
2015
-
[13]
Sketch-moma: Teleoperation for mobile manipulator via interpretation of hand-drawn sketches,
K. Tanada, Y . Iwanaga, M. Tsuchinaga, Y . Nakamura, T. Mori, R. Sakai, and T. Yamamoto, “Sketch-moma: Teleoperation for mobile manipulator via interpretation of hand-drawn sketches,”arXiv preprint arXiv:2412.19153, 2024
-
[14]
Challenges for robot manipulation in human environments [grand challenges of robotics],
C. C. Kemp, A. Edsinger, and E. Torres-Jara, “Challenges for robot manipulation in human environments [grand challenges of robotics],” IEEE Robotics & Automation Magazine, vol. 14, no. 1, pp. 20–29, 2007
2007
-
[15]
The domesticated robot: design guidelines for assisting older adults to age in place,
J. M. Beer, C.-A. Smarr, T. L. Chen, A. Prakash, T. L. Mitzner, C. C. Kemp, and W. A. Rogers, “The domesticated robot: design guidelines for assisting older adults to age in place,” inProceedings of the seventh annual ACM/IEEE international conference on Human-Robot Interaction, 2012, pp. 335–342
2012
-
[16]
Towards robotic assistants in nursing homes: Challenges and results,
J. Pineau, M. Montemerlo, M. Pollack, N. Roy, and S. Thrun, “Towards robotic assistants in nursing homes: Challenges and results,”Robotics and autonomous systems, vol. 42, no. 3-4, pp. 271–281, 2003
2003
-
[17]
Robotic grasping of novel objects using vision,
A. Saxena, J. Driemeyer, and A. Y . Ng, “Robotic grasping of novel objects using vision,”The International Journal of Robotics Research, vol. 27, no. 2, pp. 157–173, 2008
2008
-
[18]
iRobot Roomba Vacuum Cleaning Robot,
iRobot Corporation, “iRobot Roomba Vacuum Cleaning Robot,” https: //www.irobot.com/, 2024, a commercially available robotic vacuum cleaner with advanced navigation and cleaning capabilities
2024
-
[19]
Neato Robotics Vacuum Cleaner,
Neato Robotics, “Neato Robotics Vacuum Cleaner,” https://www. neatorobotics.com/, 2024, a robotic vacuum cleaner known for its laser- based navigation system
2024
-
[20]
Design and use paradigms for gazebo, an open-source multi-robot simulator,
N. Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator,” in2004 IEEE/RSJ international conference on intelligent robots and systems (IROS)(IEEE Cat. No. 04CH37566), vol. 3. Ieee, 2004, pp. 2149–2154
2004
-
[21]
Herb: a home exploring robotic butler,
S. S. Srinivasa, D. Ferguson, C. J. Helfrich, D. Berenson, A. Collet, R. Diankov, G. Gallagher, G. Hollinger, J. Kuffner, and M. V . Weghe, “Herb: a home exploring robotic butler,”Autonomous Robots, vol. 28, pp. 5–20, 2010
2010
-
[22]
Mobile manipulation in unstructured environments: Perception, planning, and execution,
S. Chitta, E. G. Jones, M. Ciocarlie, and K. Hsiao, “Mobile manipulation in unstructured environments: Perception, planning, and execution,” IEEE Robotics & Automation Magazine, vol. 19, no. 2, pp. 58–71, 2012
2012
-
[23]
Probabilistic object maps for long- term robot localization,
A. Adkins, T. Chen, and J. Biswas, “Probabilistic object maps for long- term robot localization,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 931–938
2022
-
[24]
A review of robot learning for manipulation: Challenges, representations, and algorithms,
O. Kroemer, S. Niekum, and G. Konidaris, “A review of robot learning for manipulation: Challenges, representations, and algorithms,”Journal of machine learning research, vol. 22, no. 30, pp. 1–82, 2021
2021
-
[25]
Lifelong localiza- tion in changing environments,
G. D. Tipaldi, D. Meyer-Delius, and W. Burgard, “Lifelong localiza- tion in changing environments,”The International Journal of Robotics Research, vol. 32, no. 14, pp. 1662–1678, 2013
2013
-
[26]
Semantic 3d object maps for everyday manipulation in human living environments,
R. B. Rusu, “Semantic 3d object maps for everyday manipulation in human living environments,”KI-Künstliche Intelligenz, vol. 24, pp. 345– 348, 2010
2010
-
[27]
Learning to interpret natural language commands through human-robot dialog
J. Thomason, S. Zhang, R. J. Mooney, and P. Stone, “Learning to interpret natural language commands through human-robot dialog.” in IJCAI, vol. 15, 2015, pp. 1923–1929
2015
-
[28]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500
2023
-
[29]
Pearl: A mobile robotic assistant for the elderly,
M. E. Pollack, L. Brown, D. Colbry, C. Orosz, B. Peintner, S. Ramakr- ishnan, S. Engberg, J. T. Matthews, J. Dunbar-Jacob, C. E. McCarthy et al., “Pearl: A mobile robotic assistant for the elderly,” inAAAI IEEE TRANSACTIONS ON ROBOTICS, APRIL 2026 20 workshop on automation as eldercare, vol. 2002. AAAI Press Menlo Park, California, United States, 2002
2026
-
[30]
A comprehensive review of vision-based robotic applications: current state, components, approaches, barriers, and potential solutions,
M. T. Shahria, M. S. H. Sunny, M. I. I. Zarif, J. Ghommam, S. I. Ahamed, and M. H. Rahman, “A comprehensive review of vision-based robotic applications: current state, components, approaches, barriers, and potential solutions,”Robotics, vol. 11, no. 6, p. 139, 2022
2022
-
[31]
Robotic vision for human-robot interaction and collaboration: A survey and systematic review,
N. Robinson, B. Tidd, D. Campbell, D. Kuli ´c, and P. Corke, “Robotic vision for human-robot interaction and collaboration: A survey and systematic review,”ACM Transactions on Human-Robot Interaction, vol. 12, no. 1, pp. 1–66, 2023
2023
-
[32]
Orb-slam: A versatile and accurate monocular slam system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: A versatile and accurate monocular slam system,”IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[33]
Lsd-slam: Large-scale direct monocular slam,
J. Engel, T. Schöps, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” inEuropean conference on computer vision. Springer, 2014, pp. 834–849
2014
-
[34]
An overview on visual slam: From tradition to semantic,
W. Chen, G. Shang, A. Ji, C. Zhou, X. Wang, C. Xu, Z. Li, and K. Hu, “An overview on visual slam: From tradition to semantic,”Remote Sensing, vol. 14, no. 13, p. 3010, 2022
2022
-
[35]
Slam++: Simultaneous localisation and mapping at the level of objects,
R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat, P. H. Kelly, and A. J. Davison, “Slam++: Simultaneous localisation and mapping at the level of objects,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 1352–1359
2013
-
[36]
Semanticfu- sion: Dense 3d semantic mapping with convolutional neural networks,
J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “Semanticfu- sion: Dense 3d semantic mapping with convolutional neural networks,” in2017 IEEE International Conference on Robotics and automation (ICRA). IEEE, 2017, pp. 4628–4635
2017
-
[37]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[39]
Depth map prediction from a single image using a multi-scale deep network,
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[40]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779– 788
2016
-
[41]
Mask r-cnn,
K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969
2017
-
[42]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,”Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40, 2016
2016
-
[43]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 3357–3364
2017
-
[44]
arXiv preprint arXiv:2402.08191 (2024) 14
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox, “The colosseum: A benchmark for evaluating generalization for robotic manipulation,”arXiv preprint arXiv:2402.08191, 2024
-
[45]
Regularizing action policies for smooth control with reinforcement learning,
S. Mysore, B. Mabsout, R. Mancuso, and K. Saenko, “Regularizing action policies for smooth control with reinforcement learning,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 1810–1816
2021
-
[46]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sünderhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[47]
Language conditioned imitation learning over unstructured data,
C. Lynch and P. Sermanet, “Language conditioned imitation learning over unstructured data,”arXiv preprint arXiv:2005.07648, 2020
-
[48]
Chatgpt for robotics: Design principles and model abilities,
S. H. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities,”Ieee Access, 2024
2024
-
[49]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[50]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[51]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxposer: Composable 3d value maps for robotic manipulation with language models,”arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review arXiv 2023
-
[52]
Taxonomies of visual programming and program visual- ization,
B. A. Myers, “Taxonomies of visual programming and program visual- ization,”Journal of Visual Languages & Computing, vol. 1, no. 1, pp. 97–123, 1990
1990
-
[53]
Blockly goes to work: Block-based programming for industrial robots,
D. Weintrop, D. C. Shepherd, P. Francis, and D. Franklin, “Blockly goes to work: Block-based programming for industrial robots,” in2017 IEEE Blocks And Beyond Workshop (B&B). IEEE, 2017, pp. 29–36
2017
-
[54]
Scratch - imagine, program, share,
M. M. Lab, “Scratch - imagine, program, share,” https://scratch.mit.edu/, accessed: 2025-02-18
2025
-
[55]
Depth camera based indoor mobile robot localization and navigation,
J. Biswas and M. Veloso, “Depth camera based indoor mobile robot localization and navigation,” in2012 IEEE International Conference on Robotics and Automation. IEEE, 2012, pp. 1697–1702
2012
-
[56]
Probabilistic robotics,
S. Thrun, “Probabilistic robotics,”Communications of the ACM, vol. 45, no. 3, pp. 52–57, 2002
2002
-
[57]
A survey of robot learning from demonstration,
B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,”Robotics and autonomous systems, vol. 57, no. 5, pp. 469–483, 2009
2009
-
[58]
Survey: Robot programming by demonstration,
A. Billard, S. Calinon, R. Dillmann, and S. Schaal, “Survey: Robot programming by demonstration,”Springer handbook of robotics, pp. 1371–1394, 2008
2008
-
[59]
An algorithmic perspective on imitation learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters et al., “An algorithmic perspective on imitation learning,”Foundations and Trends® in Robotics, vol. 7, no. 1-2, pp. 1–179, 2018
2018
-
[60]
A sketch interface for mobile robots,
M. Skubic, C. Bailey, and G. Chronis, “A sketch interface for mobile robots,” inSMC’03 Conference Proceedings. 2003 IEEE International Conference on Systems, Man and Cybernetics. Conference Theme- System Security and Assurance (Cat. No. 03CH37483), vol. 1. IEEE, 2003, pp. 919–924
2003
-
[61]
A sketch- based interface for multi-robot formations,
M. Skubic, D. Anderson, M. Khalilia, and S. Kavirayani, “A sketch- based interface for multi-robot formations,”AAAI Mobile Robot Com- petition, 2004
2004
-
[62]
Instructing robots by sketching: Learning from demonstration via probabilistic diagrammatic teaching,
W. Zhi, T. Zhang, and M. Johnson-Roberson, “Instructing robots by sketching: Learning from demonstration via probabilistic diagrammatic teaching,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 15 047–15 053
2024
-
[63]
Sketch- to-skill: Bootstrapping robot learning with human drawn trajectory sketches,
P. Yu, A. Bhaskar, A. Singh, Z. Mahammad, and P. Tokekar, “Sketch- to-skill: Bootstrapping robot learning with human drawn trajectory sketches,”arXiv preprint arXiv:2503.11918, 2025
-
[64]
Rt-sketch: Goal-conditioned imitation learning from hand-drawn sketches,
P. Sundaresan, Q. Vuong, J. Gu, P. Xu, T. Xiao, S. Kirmani, T. Yu, M. Stark, A. Jain, K. Hausmanet al., “Rt-sketch: Goal-conditioned imitation learning from hand-drawn sketches,” in8th Annual Conference on Robot Learning, 2024
2024
-
[65]
G., Rao, K., Yu, W., Fu, C., Gopalakrishnan, K., Xu, Z., et al
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakrishnan, Z. Xuet al., “Rt-trajectory: Robotic task generalization via hindsight trajectory sketches,”arXiv preprint arXiv:2311.01977, 2023
-
[66]
A. Smith and M. Kennedy III, “An augmented reality interface for tele- operating robot manipulators: Reducing demonstrator task load through digital twin control,”arXiv preprint arXiv:2409.18394, 2024
-
[67]
igibson 2.0: Object- centric simulation for robot learning of everyday household tasks,
C. Li, F. Xia, R. Martín-Martín, M. Lingelbach, S. Srivastava, B. Shen, K. Vainio, C. Gokmen, G. Dharan, T. Jain, A. Kurenkov, C. K. Liu, H. Gweon, J. Wu, L. Fei-Fei, and S. Savarese, “igibson 2.0: Object- centric simulation for robot learning of everyday household tasks,” 2021
2021
-
[68]
Ai2-thor: An interactive 3d environment for visual ai,
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhu, A. Kembhavi, A. Gupta, and A. Farhadi, “Ai2-thor: An interactive 3d environment for visual ai,” 2022
2022
-
[69]
Matterport3d: Learning from rgb-d data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”International Conference on 3D Vision (3DV), 2017
2017
-
[70]
Virtualhome: Simulating household activities via programs,
X. Puig, K. Ra, M. Boben, J. Li, T. Wang, S. Fidler, and A. Torralba, “Virtualhome: Simulating household activities via programs,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 8494–8502
2018
-
[71]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[72]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[73]
Learning transferable IEEE TRANSACTIONS ON ROBOTICS, APRIL 2026 21 visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable IEEE TRANSACTIONS ON ROBOTICS, APRIL 2026 21 visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2026
-
[74]
Minimum prediction residual principle applied to speech recognition,
F. Itakura, “Minimum prediction residual principle applied to speech recognition,”IEEE Transactions on acoustics, speech, and signal pro- cessing, vol. 23, no. 1, pp. 67–72, 2003
2003
-
[75]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, “Pytorch: An imperative style, high-performance deep learn- ing library,”arXiv preprint arXiv:1912.01703, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[76]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[77]
Ros: an open-source robot operating system,
M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y . Nget al., “Ros: an open-source robot operating system,” inICRA workshop on open source software, vol. 3, no. 3.2. Kobe, 2009, p. 5
2009
-
[78]
Fetch and freight: Standard platforms for service robot applications,
M. Wise, M. Ferguson, D. King, E. Diehr, and D. Dymesich, “Fetch and freight: Standard platforms for service robot applications,” inWorkshop on autonomous mobile service robots, 2016, pp. 1–6. IX. PARAMETERIZATION ANDPRACTICAL CONFIGURATION This section documents the rationale and practical config- uration of the parameters used in Algorithm 1 (in the mai...
2016
-
[79]
cover_area
Area segments: 28If is_area=true or is_closed=true -> output ["cover_area"] only. 29
-
[80]
32If in [22.5deg, 67.5deg) -> 45deg turn: turn_p45 if dpsi_deg>0 else turn_n45
Turns for path segments (by |dpsi_deg|): 31If >= 67.5deg -> 90deg turn: turn_p90 if dpsi_deg>0 else turn_n90. 32If in [22.5deg, 67.5deg) -> 45deg turn: turn_p45 if dpsi_deg>0 else turn_n45. 33Else -> prefer "forward" (see Rule 3). 34
-
[81]
37When eta_t=0, ignore obstacle/clearance fields (use I-based priors)
Forward for path segments: 36Prefer ["forward"] when |dpsi_deg|<22.5deg and is_path=true. 37When eta_t=0, ignore obstacle/clearance fields (use I-based priors). 38
-
[82]
unknown" -> [
Obstacle-under check (only if eta_t=1): 40If obs_ahead=true and h_est_m="unknown" -> ["check_under"]. 41If obs_ahead=true and h_est_m < h_clearance -> do NOT output "forward"; 42instead choose the best turn per Rule 2. 43If obs_ahead=true and h_est_m >= h_clearance -> "forward" allowed. 44
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.