Recognition: 2 theorem links
· Lean TheoremClickAIXR: On-Device Multimodal Vision-Language Interaction with Real-World Objects in Extended Reality
Pith reviewed 2026-05-10 19:24 UTC · model grok-4.3
The pith
Click-based selection with a local vision-language model lets users query real objects in XR while keeping all data private.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining controller-based clicking for precise object selection with local ONNX inference of a vision-language model, ClickAIXR achieves multimodal question answering about real objects in XR while keeping all computation on-device, yielding moderate latency and positive usability scores in direct comparison with cloud-based alternatives.
What carries the argument
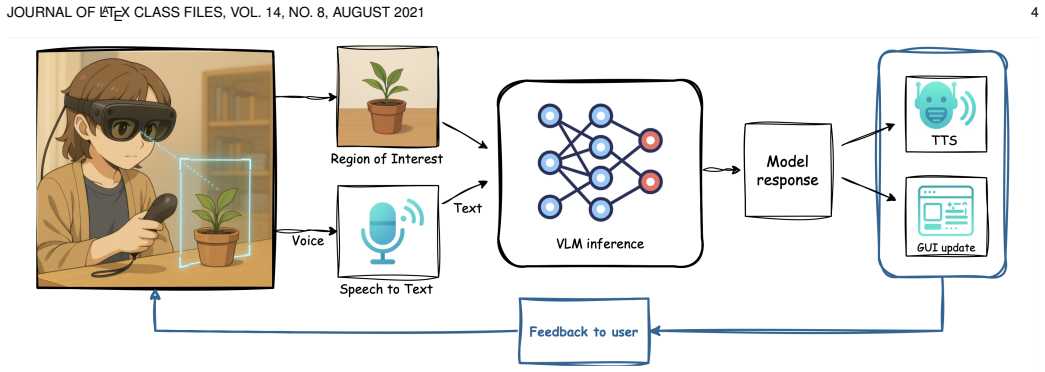
Controller-based click selection that isolates a real-world object image for immediate on-device VLM processing to generate text and speech responses.
Load-bearing premise
The on-device vision-language model produces sufficiently accurate answers quickly enough to support natural conversation without users noticing frequent errors or long waits.
What would settle it
A controlled test in which participants ask questions about selected objects and the rate of incorrect or irrelevant answers from the local model exceeds 20 percent, or average end-to-end latency surpasses 3 seconds.
Figures






read the original abstract
We present ClickAIXR, a novel on-device framework for multimodal vision-language interaction with objects in extended reality (XR). Unlike prior systems that rely on cloud-based AI (e.g., ChatGPT) or gaze-based selection (e.g., GazePointAR), ClickAIXR integrates an on-device vision-language model (VLM) with a controller-based object selection paradigm, enabling users to precisely click on real-world objects in XR. Once selected, the object image is processed locally by the VLM to answer natural language questions through both text and speech. This object-centered interaction reduces ambiguity inherent in gaze- or voice-only interfaces and improves transparency by performing all inference on-device, addressing concerns around privacy and latency. We implemented ClickAIXR in the Magic Leap SDK (C API) with ONNX-based local VLM inference. We conducted a user study comparing ClickAIXR with Gemini 2.5 Flash and ChatGPT 5, evaluating usability, trust, and user satisfaction. Results show that latency is moderate and user experience is acceptable. Our findings demonstrate the potential of click-based object selection combined with on-device AI to advance trustworthy, privacy-preserving XR interactions. The source code and supplementary materials are available at: nanovis.org/ClickAIXR.html
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClickAIXR, an on-device XR framework that combines controller-based click selection of real-world objects with a local vision-language model (VLM) running via ONNX on Magic Leap hardware. Selected object crops are processed locally to generate text and speech answers to natural-language queries. The system is positioned as an improvement over cloud-based VLMs (Gemini, ChatGPT) and gaze-based interfaces by reducing ambiguity and keeping all inference on-device. A comparative user study is reported to show moderate latency and acceptable user experience, supporting the claim that click-based on-device interaction advances trustworthy, privacy-preserving XR.
Significance. If the missing quantitative results and implementation details are supplied, the work would provide a concrete, reproducible demonstration of click-driven object-centric VLM interaction in XR, with source code released. This addresses real deployment concerns around privacy and latency that cloud-only systems cannot meet. The emphasis on controller selection over gaze is a practical contribution, but the current absence of model specifications, accuracy numbers, and latency distributions limits the paper's ability to substantiate its usability and trustworthiness claims.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The user study is described only as yielding 'latency is moderate and user experience is acceptable' with no participant count, no quantitative metrics (e.g., SUS, NASA-TLX, task completion time, error rates), no statistical tests, and no per-condition latency distributions or failure rates. These omissions make it impossible to verify whether the on-device VLM actually supports the claimed natural interaction quality.
- [Implementation section] Implementation section (likely §3): No identity, parameter count, quantization scheme, or accuracy metrics are given for the on-device VLM, nor are device-measured per-query latency histograms or object-centric VQA failure cases reported. Without these load-bearing details the central claim that local inference delivers sufficiently accurate and fast responses cannot be evaluated.
minor comments (2)
- The source-code link is a positive feature; ensure the released repository contains the exact model weights, ONNX export scripts, and raw user-study logs referenced in the text.
- [Abstract] Abstract: the phrase 'user experience is acceptable' is vague; replace with a brief quantitative summary once metrics are added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional detail will improve clarity and verifiability. We address each major comment below and commit to revisions that supply the requested quantitative and implementation information without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The user study is described only as yielding 'latency is moderate and user experience is acceptable' with no participant count, no quantitative metrics (e.g., SUS, NASA-TLX, task completion time, error rates), no statistical tests, and no per-condition latency distributions or failure rates. These omissions make it impossible to verify whether the on-device VLM actually supports the claimed natural interaction quality.
Authors: We agree that the current high-level summary in the abstract and evaluation section limits the ability to assess the strength of the usability claims. The full manuscript reports a comparative user study, but we acknowledge the description is insufficiently detailed. In the revised version we will expand the evaluation section to report the participant count, SUS and NASA-TLX scores, task completion times, error rates, appropriate statistical tests, per-condition latency distributions, and observed failure rates. These additions will be drawn from the existing study data and will be presented with clear tables and figures. revision: yes
-
Referee: [Implementation section] Implementation section (likely §3): No identity, parameter count, quantization scheme, or accuracy metrics are given for the on-device VLM, nor are device-measured per-query latency histograms or object-centric VQA failure cases reported. Without these load-bearing details the central claim that local inference delivers sufficiently accurate and fast responses cannot be evaluated.
Authors: We accept this criticism. The implementation section currently focuses on the integration architecture and ONNX runtime but omits model-level specifications. In the revision we will add the exact VLM identity and version, parameter count, quantization scheme employed, measured accuracy on object-centric VQA benchmarks, device-specific per-query latency histograms, and representative failure cases. These details will be placed in a new subsection or table to allow direct evaluation of the on-device performance claims. revision: yes
Circularity Check
No circularity: system implementation and user study with no derivations or fitted predictions
full rationale
The paper describes an XR framework implementation (Magic Leap SDK + ONNX VLM) and reports a comparative user study on usability/trust. No equations, no parameter fitting, no predictions derived from inputs, and no self-citation chains invoked as uniqueness theorems or ansatzes. Central claims rest on the described system behavior and study outcomes rather than reducing to self-referential definitions or renamings. Absence of quantitative VLM metrics is a verification gap, not circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present ClickAIXR, a novel on-device framework for multimodal vision-language interaction with objects in extended reality (XR)... implemented... with ONNX-based local VLM inference... user study comparing ClickAIXR with Gemini 2.5 Flash and ChatGPT 5
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mean inference time of 5.36 s (Books)–5.48 s (COCO) per image and a consistent token-generation speed of 3.36 tokens/s
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GazePointAR: A context-aware multimodal voice assistant for pronoun disambiguation in wearable augmented reality,
J. Lee, J. Wang, E. Brown, L. Chu, S. S. Rodriguez, and J. E. Froehlich, “GazePointAR: A context-aware multimodal voice assistant for pronoun disambiguation in wearable augmented reality,” inProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, ser. CHI ’24. New York, NY , USA: Association for Computing Machinery,
2024
-
[2]
[Online]. Available: https://doi.org/10.1145/3613904.3642230
-
[3]
XaiR: An XR platform that integrates large language models with the physical world,
S. Srinidhi, E. Lu, and A. Rowe, “XaiR: An XR platform that integrates large language models with the physical world,” inIEEE Int. Symposium on Mixed and Augmented Reality (ISMAR), 2024, pp. 759–767
2024
-
[4]
The on-line effects of semantic context on syntactic processing,
L. K. Tyler and W. D. Marslen-Wilson, “The on-line effects of semantic context on syntactic processing,”Journal of verbal learning and verbal behavior, vol. 16, no. 6, pp. 683–692, 1977
1977
-
[5]
Ultralytics YOLO,
G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO,” Jan. 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
2023
-
[6]
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2301.12597
work page internal anchor Pith review arXiv 2023
-
[7]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023. [Online]. Available: https://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[8]
Mobilevlm : A fast, strong and open vision language assistant for mobile devices
X. Chu, L. Qiao, X. Lin, S. Xu, Y . Yang, Y . Hu, F. Wei, X. Zhang, B. Zhang, X. Wei, and C. Shen, “MobileVLM : A fast, strong and open vision language assistant for mobile devices,” 2023. [Online]. Available: https://arxiv.org/abs/2312.16886
-
[9]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2304.10592
work page internal anchor Pith review arXiv 2023
-
[10]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[11]
On-device execution of deep learning models on hololens2 for real-time augmented reality medical applications,
S. Zaccardi, T. Frantz, D. Beckw ’ee, E. Swinnen, and B. Jansen, “On-device execution of deep learning models on hololens2 for real-time augmented reality medical applications,”Sensors, vol. 23, no. 21, p. 8698, oct 2023. [Online]. Available: https://www.mdpi.com/1424-8220/23/21/8698
2023
-
[12]
Model compression in practice: Lessons learned from practitioners creating on-device machine learning experiences,
F. Hohman, M. B. Kery, D. Ren, and D. Moritz, “Model compression in practice: Lessons learned from practitioners creating on-device machine learning experiences,” inProceedings of the CHI Conference on Human Factors in Computing Systems, ser. CHI ’24. New York, NY , USA: ACM, may 2024, pp. 1–18
2024
-
[13]
TinyVLA: Towards fast, data- efficient vision-language-action models for robotic manipulation,
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, Y . Peng, F. Feng, and J. Tang, “TinyVLA: Towards fast, data- efficient vision-language-action models for robotic manipulation,”IEEE Robotics and Automation Letters, p. 1–8, Jan 2025
2025
-
[14]
Palm- e: an embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “Palm- e: an embodied multimodal language model,” inProceedings of the 40th International Conf...
2023
-
[15]
LLMs on XR (LoXR): Performance evaluation of llms executed locally on extended reality devices,
X. Liu, D. Khan, O. Mena, D. Jia, A. Kouyoumdjian, and I. Viola, “LLMs on XR (LoXR): Performance evaluation of llms executed locally on extended reality devices,” in2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 2025, pp. 1212–1213
2025
-
[16]
AIvaluateXR: an evaluation framework for on-device AI in XR with benchmarking results,
D. Khan, X. Liu, O. Mena, D. Jia, A. Kouyoumdjian, and I. Viola, “AIvaluateXR: an evaluation framework for on-device AI in XR with benchmarking results,”arXiv preprint arXiv:2502.15761, 2025. [Online]. Available: https://arxiv.org/abs/2502.15761
work page internal anchor Pith review arXiv 2025
-
[17]
What’s this? a voice and touch multimodal approach for ambiguity resolution in voice assistants,
J. Lee, S. S. Rodriguez, R. Natarrajan, J. Chen, H. Deep, and A. Kirlik, “What’s this? a voice and touch multimodal approach for ambiguity resolution in voice assistants,” inICMI 2021 - Proceedings of the 2021 International Conference on Multimodal Interaction, ser. ICMI ’21. New York, NY , USA: Association for Computing Machinery, 2021, pp. 512–520
2021
-
[18]
Walkie-Talkie: Exploring longitudinal natural gaze, llms, and vlms for query disambiguation in xr,
J. Lee, T. Wang, J. Fashimpaur, N. Sendhilnathan, and T. R. Jonker, “Walkie-Talkie: Exploring longitudinal natural gaze, llms, and vlms for query disambiguation in xr,” inExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, ser. CHI. New York, NY , USA: Association for Computing Machinery, 2025
2025
-
[19]
Llmr: Real-time prompting of interactive worlds using large language models,
F. De La Torre, C. M. Fang, H. Huang, A. Banburski-Fahey, J. Amores Fernandez, and J. Lanier, “Llmr: Real-time prompting of interactive worlds using large language models,” inProceedings of the CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–22
2024
-
[20]
Gesprompt: Leveraging co-speech gestures to augment llm-based interaction in virtual reality,
X. Hu, D. Ma, F. He, Z. Zhu, S.-K. Hsia, C. Zhu, Z. Liu, and K. Ramani, “Gesprompt: Leveraging co-speech gestures to augment llm-based interaction in virtual reality,” inProceedings of the 2025 ACM Designing Interactive Systems Conference, ser. DIS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 59–80. [Online]. Available: https://d...
-
[21]
Towards spatial computing: recent advances in multimodal natural interaction for extended reality headsets,
Z.-M. Wang, M.-H. Rao, S.-H. Ye, W.-T. Song, and F. Lu, “Towards spatial computing: recent advances in multimodal natural interaction for extended reality headsets,”Frontiers of Computer Science, vol. 19, no. 12, Jun 2025
2025
-
[22]
Onnx runtime,
Microsoft, “Onnx runtime,” https://onnxruntime.ai, 2023, high- performance inference engine for ONNX models
2023
-
[23]
V osk: Offline speech recognition toolkit,
Alpha Cephei, “V osk: Offline speech recognition toolkit,” https://github. com/alphacep/vosk-api, 2024, offline, streaming ASR with 20 + lan- guages; accessed 9 Sep 2025
2024
-
[24]
vit-gpt2-image-captioning (model card),
nlpconnect, “vit-gpt2-image-captioning (model card),” https: //huggingface.co/nlpconnect/vit-gpt2-image-captioning, 2023, hugging Face model card
2023
-
[25]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Un- terthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[26]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI, Tech. Rep., 2019, technical report
2019
-
[27]
Optimum: Efficient inference and training for transform- ers,
Hugging Face, “Optimum: Efficient inference and training for transform- ers,” https://github.com/huggingface/optimum, 2023, software library
2023
-
[28]
Microsoft coco: Common objects in con- text,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in con- text,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 740–755
2014
-
[29]
B. K. Iwana, S. T. Raza Rizvi, S. Ahmed, A. Dengel, and S. Uchida, “Judging a book by its cover,”arXiv preprint arXiv:1610.09204, 2016
-
[30]
SUS-A quick and dirty usability scale,
J. Brooke, “SUS-A quick and dirty usability scale,”Usability evaluation in industry, vol. 189, no. 194, pp. 4–7, 1996
1996
-
[31]
Item benchmarks for the system usability scale
J. R. Lewis and J. Sauro, “Item benchmarks for the system usability scale.”Journal of Usability studies, vol. 13, no. 3, 2018
2018
-
[32]
Determining what individual sus scores mean: Adding an adjective rating scale,
A. Bangor, P. T. Kortum, and J. T. Miller, “Determining what individual sus scores mean: Adding an adjective rating scale,”Journal of Usability Studies, vol. 4, no. 3, pp. 114–123, 2009
2009
-
[33]
Item benchmarks for the system usability scale,
J. R. Lewis and J. Sauro, “Item benchmarks for the system usability scale,”J. Usability Studies, vol. 13, no. 3, p. 158–167, May 2018
2018
-
[34]
Nielsen,Usability engineering
J. Nielsen,Usability engineering. Morgan Kaufmann, 1994
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.