Recognition: 2 theorem links
· Lean TheoremHow AI Aggregation Affects Knowledge
Pith reviewed 2026-05-10 18:56 UTC · model grok-4.3
The pith
AI aggregation fails to robustly improve social learning when updates are too fast, though local systems can succeed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a threshold exists in the speed of the AI aggregator's updates such that, when updating is too fast, there is no positive-measure set of training weights that robustly reduces the learning gap across a broad class of environments, whereas such weights do exist when updating is sufficiently slow. Local architectures trained on proximate or topic-specific data robustly improve learning in all environments, so replacing them with a global aggregator worsens learning in at least one state dimension.
What carries the argument
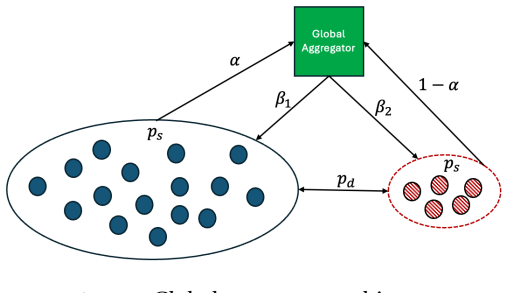
The AI aggregator in the extended DeGroot dynamics, which trains on population beliefs and feeds synthesized signals back to agents, with update speed and training weights as parameters that control the size of the learning gap relative to the efficient benchmark.
If this is right
- When the aggregator updates slowly enough, there exist training weights that bring long-run beliefs closer to the efficient benchmark in a broad class of environments.
- Local aggregators trained on proximate or topic-specific data reduce the learning gap in every environment.
- Switching from specialized local aggregators to one global aggregator increases the learning gap in at least one dimension of the state.
- The architecture and speed of AI feedback jointly determine whether social learning converges closer to or farther from the truth.
Where Pith is reading between the lines
- Platforms using fast global AI models for information synthesis may need to slow update rates or segment by topic to avoid widening belief distortions.
- Empirical studies could compare belief convergence in networks with fast versus slow AI interventions to test the threshold prediction.
- The result limits how far a single universal AI aggregator can be scaled without careful controls on speed and data locality.
Load-bearing premise
Agents continue to update beliefs according to the extended DeGroot rule using the AI's signals, and a well-defined efficient benchmark exists for measuring the learning gap.
What would settle it
Simulate the extended model under fast update rates across many environments and check whether any training weights produce a positive reduction in the learning gap; if none do, the threshold claim holds.
Figures

read the original abstract
Artificial intelligence (AI) changes social learning when aggregated outputs become training data for future predictions. To study this, we extend the DeGroot model by introducing an AI aggregator that trains on population beliefs and feeds synthesized signals back to agents. We define the learning gap as the deviation of long-run beliefs from the efficient benchmark, allowing us to capture how AI aggregation affects learning. Our main result identifies a threshold in the speed of updating: when the aggregator updates too quickly, there is no positive-measure set of training weights that robustly improves learning across a broad class of environments, whereas such weights exist when updating is sufficiently slow. We then compare global and local architectures. Local aggregators trained on proximate or topic-specific data robustly improve learning in all environments. Consequently, replacing specialized local aggregators with a single global aggregator worsens learning in at least one dimension of the state.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the DeGroot model of social learning by introducing an AI aggregator that trains on population beliefs and feeds synthesized signals back to agents. It defines the learning gap as the long-run deviation from an efficient benchmark and establishes a threshold result on aggregator update speed: when updates are too fast, no positive-measure set of training weights robustly reduces the gap across a broad class of environments, whereas such weights exist for sufficiently slow updates. The analysis further shows that local aggregators trained on proximate or topic-specific data improve learning in all environments, while replacing them with a global aggregator worsens learning in at least one dimension of the state.
Significance. If the central threshold result holds, the paper offers a clean theoretical account of how AI aggregation can either stabilize or destabilize collective beliefs depending on update speed and training scope. The self-contained extension of DeGroot dynamics, with explicit free parameters for training weights and update speed, yields falsifiable comparative-static predictions and avoids ad-hoc axioms. The local-versus-global comparison supplies a concrete mechanism for why specialized aggregators may outperform a single global one, which is directly relevant to the design of AI-mediated information systems.
minor comments (3)
- [§2.2] §2.2: the definition of the efficient benchmark (relative to which the learning gap is measured) should explicitly state whether it remains invariant when the aggregator's training support changes; a short remark would remove any residual ambiguity.
- [Theorem 1] The proof of the non-existence result for fast updates (Theorem 1) would benefit from a brief remark on whether the positive-measure claim continues to hold if the environment class is restricted to finite-state Markov chains.
- [Notation] Notation: the symbol for the aggregator's update-speed parameter is easily confused with the standard DeGroot weight matrix; a distinct symbol or explicit reminder in the text would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the clear summary of our results, and the recommendation for minor revision. We are pleased that the threshold result on aggregator speed and the local-versus-global comparison were viewed as providing a clean theoretical account with falsifiable predictions.
Circularity Check
No significant circularity; derivation is self-contained within the extended model
full rationale
The paper extends the classic DeGroot framework by adding an AI aggregator that trains on population beliefs and feeds signals back. It defines the learning gap as long-run belief deviation from an efficient benchmark and derives a threshold result on aggregator update speed for existence/non-existence of positive-measure training weights that reduce the gap uniformly. The local-vs-global comparison follows directly from restricting the aggregator's training support. All steps are explicit mathematical constructions inside the fixed architecture and benchmark; no step reduces by definition or by self-citation to its own inputs. The model is self-contained against its stated assumptions and does not rely on fitted parameters or load-bearing prior results from the same authors.
Axiom & Free-Parameter Ledger
free parameters (2)
- training weights
- update speed parameter
axioms (2)
- domain assumption Agents update beliefs according to the DeGroot averaging rule
- domain assumption The learning gap is measured relative to an efficient benchmark
invented entities (1)
-
AI aggregator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe extend the DeGroot model by introducing an AI aggregator... learning gap as the deviation of long-run beliefs from the efficient benchmark... threshold in the speed of updating... robust improvement set Λ_ρ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearaugmented transition matrix Γ... closed-form consensus via perturbation (Schweitzer 1968)
Reference graph
Works this paper leans on
-
[1]
Ifρ < ρ ⋆, thenµ(Λ ρ) = 0
-
[2]
This completes the proof
Ifρ > ρ ⋆, thenµ(Λ ρ)>0. This completes the proof. A.4 Proofs from Section 5 Proof of Proposition 2.We have ∆⋆ ≡∆ 1(ρ, α, β, β, h, π)−∆ 0(h, π) =| ¯∆1(ρ, α, β, h, π)| −∆ 0(h, π), where ¯∆1(ρ, α, β, h, π) = (1−ρ)(hπ2+π)+α(β(1+β−ρ)h 2π+βhπ2+βh+β(1−β+ρ)π) (1−ρ)(hπ2+2π+h)+(β(1+β−ρ)h 2π+βhπ2+βh+β(1−β+ρ)π) − π π+1 . 36 Fixingρ∈(0,1)andπ >1, we have ∂ ¯∆1 ∂h (ρ,...
-
[3]
Becauseα < hπ2+π hπ2+2π+h , we have ∂ ¯∆1 ∂β (ρ, α, β, h, π)<0, implying that − ¯∆1(ρ, α, β, h, π)−∆ 0(h, π)as a function ofβis increasing over[0,1]
Indeed, we show whyβ ⋆ 1 exists and is unique. Becauseα < hπ2+π hπ2+2π+h , we have ∂ ¯∆1 ∂β (ρ, α, β, h, π)<0, implying that − ¯∆1(ρ, α, β, h, π)−∆ 0(h, π)as a function ofβis increasing over[0,1]. Fixing anyh >1, we have − ¯∆1(ρ, α,0, h, π)−∆ 0(h, π) = 2π π+1 − 2(hπ2+π) hπ2+2π+h <0. In addition, we have − ¯∆1(ρ, α,1, h, π)−∆ 0(h, π) = 2π π+1 − hπ2+π hπ2+2...
-
[4]
This implies− ¯∆1(ρ, α, β, hβ, π)−∆ 0(hβ, π)<0
Indeed, ifβ < β ⋆ 1, then by the definition of supremum there exists someh β >1such thatβ < β ⋆ 1(hβ). This implies− ¯∆1(ρ, α, β, hβ, π)−∆ 0(hβ, π)<0. Thus, we haveP(h β)<0, as desired. Lemma A.4.Fixingρ, β∈(0,1),α∈(0, 1 2)andπ >1. For eachh >1, letβ ⋆ 2(h)∈(0,1)denote the (unique) threshold such that− ¯∆1(ρ, α, β, h, π)≤0if and only ifβ∈[β ⋆ 2(h),1]. The...
-
[5]
Becauseα < hπ2+π hπ2+2π+h , we have ∂ ¯∆1 ∂β (ρ, α, β, h, π)<0, implying that ¯∆1(ρ, α, β, h, π)as a function ofβis decreasing over[0,1]
Indeed, we show whyβ ⋆ 2 exists and is unique. Becauseα < hπ2+π hπ2+2π+h , we have ∂ ¯∆1 ∂β (ρ, α, β, h, π)<0, implying that ¯∆1(ρ, α, β, h, π)as a function ofβis decreasing over[0,1]. Fixing anyh >1, we have ¯∆1(ρ, α,0, h, π) = hπ2+π hπ2+2π+h − π π+1 >0. In addition, we have ¯∆1(ρ, α,1, h, π) = (1−ρ)(hπ2+π)+α((2−ρ)h2π+hπ2+h+ρπ) (1−ρ)(hπ2+2π+h)+((2−ρ)h2π+...
-
[6]
This implies ¯∆1(ρ, α, β, hβ, π)>0, as desired
Indeed, ifβ < β ⋆ 2, then by the definition of supremum there exists some hβ >1such thatβ < β ⋆ 2(hβ). This implies ¯∆1(ρ, α, β, hβ, π)>0, as desired. Back to the original claim of Proposition 3. We setβ ⋆ = min{β ⋆ 1, β⋆ 2, π−1 2π−2α(π+1) } ∈(0,1). By 40 Lemma A.3, we have that there exists1< ¯h1 < ¯h1 <∞such that − ¯∆1(ρ, α, β, h, π)−∆ 0(h, π) ( ≥0,if1≤...
-
[7]
For the former case, we have ∆1(ρ, α, β, h, π)−∆ 0(h, π) = ¯∆1(ρ, α, β, h, π)−∆ 0(h, π)<max n α, hπ2+π hπ2+2π+h o − hπ2+π hπ2+2π+h = 0
Otherwise, we consider: ¯∆1(ρ, α, β, h, π)≥0or ¯∆1(ρ, α, β, h, π)<0. For the former case, we have ∆1(ρ, α, β, h, π)−∆ 0(h, π) = ¯∆1(ρ, α, β, h, π)−∆ 0(h, π)<max n α, hπ2+π hπ2+2π+h o − hπ2+π hπ2+2π+h = 0. For the latter case, we have ∆1(ρ, α, β, h, π)−∆ 0(h, π) =− ¯∆1(ρ, α, β, h, π)−∆ 0(h, π)<0. Putting these pieces together yields ∆⋆ ≡∆ 1(ρ, α, β, h, π)−...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.