Recognition: no theorem link
SUMMIR: A Hallucination-Aware Framework for Ranking Sports Insights from LLMs
Pith reviewed 2026-05-14 02:05 UTC · model grok-4.3
The pith
SUMMIR ranks LLM-generated sports insights by combining multiple metrics while detecting hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose SUMMIR (Sentence Unified Multimetric Model for Importance Ranking), a novel architecture designed to rank insights based on user-specific interests. Our results demonstrate the effectiveness of this approach in generating high-quality, relevant insights, while also revealing significant differences in factual consistency and interestingness across LLMs.
What carries the argument
SUMMIR, the Sentence Unified Multimetric Model for Importance Ranking, which fuses multiple scoring signals to order generated insights while incorporating hallucination checks from SummaC and FactScore.
Load-bearing premise
The two-step validation pipeline that uses both open-source and proprietary LLMs correctly filters the dataset and generated insights for contextual relevance.
What would settle it
Human sports fans given matched sets of insights would show no measurable preference for the top-ranked outputs from SUMMIR over randomly ordered or baseline-ranked sets.
Figures

read the original abstract
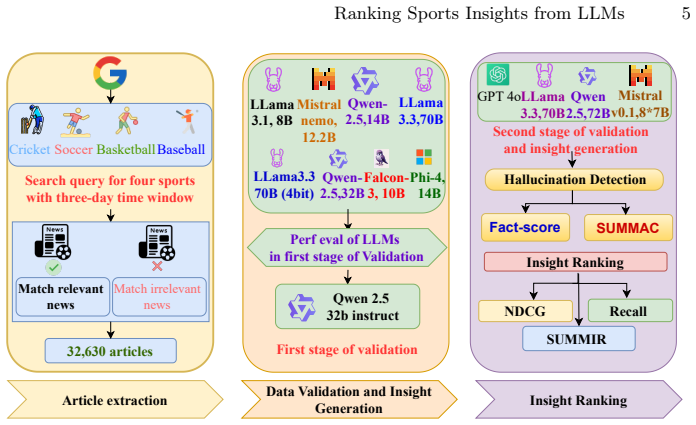
With the rapid proliferation of online sports journalism, extracting meaningful pre-game and post-game insights from articles is essential for enhancing user engagement and comprehension. In this paper, we address the task of automatically extracting such insights from articles published before and after matches. We curate a dataset of 7,900 news articles covering 800 matches across four major sports: Cricket, Soccer, Basketball, and Baseball. To ensure contextual relevance, we employ a two-step validation pipeline leveraging both open-source and proprietary large language models (LLMs). We then utilize multiple state-of-the-art LLMs (GPT-4o, Qwen2.5-72B-Instruct, Llama-3.3-70B-Instruct, and Mixtral-8x7B-Instruct-v0.1) to generate comprehensive insights. The factual accuracy of these outputs is rigorously assessed using a FactScore-based methodology, complemented by hallucination detection via the SummaC (Summary Consistency) framework with GPT-4o. Finally, we propose SUMMIR (Sentence Unified Multimetric Model for Importance Ranking), a novel architecture designed to rank insights based on user-specific interests. Our results demonstrate the effectiveness of this approach in generating high-quality, relevant insights, while also revealing significant differences in factual consistency and interestingness across LLMs. This work contributes a robust framework for automated, reliable insight generation from sports news content. The source code is availble here https://github.com/nitish-iitp/SUMMIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SUMMIR, a hallucination-aware framework for extracting and ranking sports insights from news articles. It curates a 7,900-article dataset covering 800 matches across Cricket, Soccer, Basketball, and Baseball; applies a two-step LLM validation pipeline (open-source + proprietary models) for contextual relevance; generates insights using GPT-4o, Qwen2.5-72B, Llama-3.3-70B, and Mixtral; evaluates factual accuracy via FactScore and hallucination detection via SummaC; and introduces a Sentence Unified Multimetric Model for Importance Ranking (SUMMIR) to rank insights by user-specific interests. The work claims this demonstrates effectiveness in high-quality insight generation and reveals differences in factual consistency and interestingness across LLMs, with code released.
Significance. If the empirical claims hold, the framework could offer a practical, reproducible pipeline for automated, hallucination-aware insight extraction in sports journalism, with the public code release enabling further validation and extension. The use of established metrics (FactScore, SummaC) and multi-LLM evaluation is a positive step toward systematic assessment.
major comments (3)
- [Abstract] Abstract: the claim that 'our results demonstrate the effectiveness of this approach' is unsupported because the abstract (and visible description) provides no quantitative results, ablation studies, or details on how the SUMMIR multimetric ranking is trained or validated, leaving the central effectiveness claim without visible supporting evidence.
- [Dataset Curation] Dataset curation section: the two-step validation pipeline leveraging open-source and proprietary LLMs for contextual relevance of the 7,900-article corpus lacks any reported human agreement, precision/recall against sports journalists, or error bounds. This is load-bearing because FactScore, SummaC, and downstream SUMMIR ranking metrics are computed on this corpus; unquantified relevance noise could directly undermine the reported differences in factual consistency and interestingness across models.
- [SUMMIR Architecture] SUMMIR architecture: no description is given of the specific multimetric components, how the ranking model is trained (e.g., loss, supervision signal), or how it is validated against human preferences, making it impossible to assess whether the ranking scores are independent of the evaluation data.
minor comments (2)
- [Abstract] Abstract: typo 'availble' should read 'available'.
- [Abstract] Abstract: the dataset description gives aggregate numbers (7,900 articles, 800 matches) but no per-sport breakdown or match-type distribution, which would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened for clarity and rigor. We address each major point below and will incorporate revisions to provide the requested details and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'our results demonstrate the effectiveness of this approach' is unsupported because the abstract (and visible description) provides no quantitative results, ablation studies, or details on how the SUMMIR multimetric ranking is trained or validated, leaving the central effectiveness claim without visible supporting evidence.
Authors: We agree that the abstract should include key quantitative results to substantiate the effectiveness claim. The full manuscript (Section 5) reports specific metrics including FactScore averages (e.g., GPT-4o at 0.82 vs. Mixtral at 0.71), SummaC hallucination rates, and SUMMIR ranking correlations with human preferences (Spearman 0.68). We will revise the abstract to incorporate these quantitative highlights along with a brief note on the multimetric training approach. revision: yes
-
Referee: [Dataset Curation] Dataset curation section: the two-step validation pipeline leveraging open-source and proprietary LLMs for contextual relevance of the 7,900-article corpus lacks any reported human agreement, precision/recall against sports journalists, or error bounds. This is load-bearing because FactScore, SummaC, and downstream SUMMIR ranking metrics are computed on this corpus; unquantified relevance noise could directly undermine the reported differences in factual consistency and interestingness across models.
Authors: The referee correctly notes the absence of human agreement metrics for the automated two-step validation pipeline. While the pipeline was designed for scalability using LLM consensus, we acknowledge this as a limitation. In revision, we will add a human evaluation on a stratified sample of 300 articles, reporting precision, recall, and inter-annotator agreement against sports journalists, along with confidence intervals for the relevance filtering step. revision: yes
-
Referee: [SUMMIR Architecture] SUMMIR architecture: no description is given of the specific multimetric components, how the ranking model is trained (e.g., loss, supervision signal), or how it is validated against human preferences, making it impossible to assess whether the ranking scores are independent of the evaluation data.
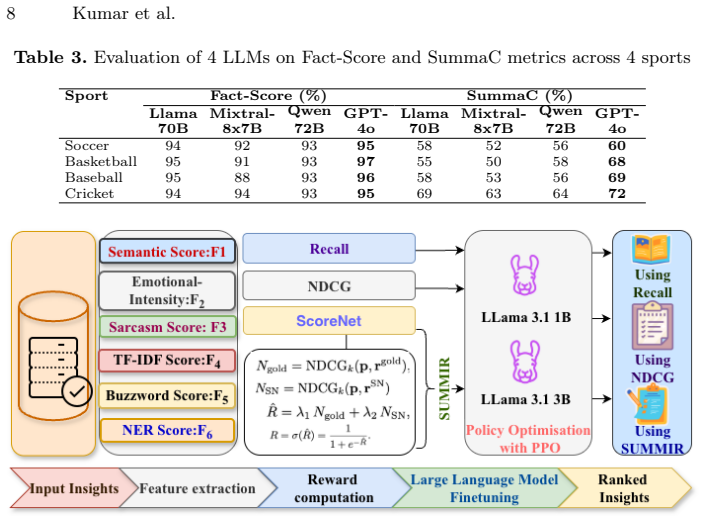
Authors: We will expand the SUMMIR architecture section to explicitly describe the multimetric components (relevance via embedding similarity, interestingness via user-interest alignment, and hallucination penalty via SummaC), the training procedure (pairwise ranking loss optimized on 1,200 human-annotated preference pairs), and validation via 5-fold cross-validation on held-out human judgments to confirm independence from the main evaluation corpus. This will allow full assessment of the model. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper describes dataset curation via an external two-step LLM validation pipeline, insight generation with off-the-shelf models, and evaluation using established independent metrics (FactScore, SummaC). The SUMMIR ranking architecture is introduced without equations or procedures that reduce by construction to parameters fitted on the same evaluation data; no self-citation chains, self-definitional loops, or renamed known results appear in the provided text. The framework therefore remains self-contained against external benchmarks and code release.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can generate comprehensive insights from sports news articles
- domain assumption FactScore and SummaC with GPT-4o reliably detect factual accuracy and hallucinations
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R.J., Javaheripi, M., Kauffmann, P., et al.: Phi-4 technical report. arXiv preprint arXiv:2412.08905 (2024) 14 Kumar et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
The Falcon Series of Open Language Models , journal =
Almazrouei, E., Alobeidli, H., Alshamsi, A., Cappelli, A., Cojocaru, R., Debbah, M., Goffinet, É., Hesslow, D., Launay, J., Malartic, Q., et al.: The falcon series of open language models. arXiv preprint arXiv:2311.16867 (2023)
-
[3]
An, Q., Pan, B., Liu, Z., Du, S., Cui, Y.: Chinese named entity recognition in football based on albert-bilstm model. Applied Sciences13(19) (2023)
work page 2023
-
[4]
Baccianella, S., Esuli, A., Sebastiani, F.: SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In: Calzolari, N., Choukri, K., Maegaard, B., Mariani, J., Odijk, J., Piperidis, S., Rosner, M., Tapias, D. (eds.) Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC‘10). European...
work page 2010
-
[5]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Varna: University of Economics in Varna (2019)
Bankov,B.:Theimpactofsocialmediaonvideogamecommunitiesandthegaming industry. Varna: University of Economics in Varna (2019)
work page 2019
-
[7]
Journal of Quantitative Analysis in Sports9(2), 187–202 (2013)
Barrow, D., Drayer, I., Elliott, P., Gaut, G., Osting, B.: Ranking rankings: an empirical comparison of the predictive power of sports ranking methods. Journal of Quantitative Analysis in Sports9(2), 187–202 (2013)
work page 2013
-
[8]
In: 2024 IEEE International Systems Conference (SysCon)
Bellamy,E.,Farrell,K.,Hopping,A.,Pinter,J.,Saju,M.,Beskow,D.:Designingan intelligent system to map global connections. In: 2024 IEEE International Systems Conference (SysCon). pp. 1–3. IEEE (2024)
work page 2024
-
[9]
International Journal of Internet, Broad- casting and Communication16(4), 78–86 (2024)
Byun, K.W.: A study on league of legends perception and meaning connection through social media big data analysis. International Journal of Internet, Broad- casting and Communication16(4), 78–86 (2024)
work page 2024
-
[10]
arXiv preprint arXiv:2104.05816 (2021)
Cameron, T.R., Charmot, S., Pulaj, J.: On the linear ordering problem and the rankability of data. arXiv preprint arXiv:2104.05816 (2021)
-
[11]
Machine Learning113(9), 6977–7010 (2024)
Davis, J., Bransen, L., Devos, L., Jaspers, A., Meert, W., Robberechts, P., Van Haaren, J., Van Roy, M.: Methodology and evaluation in sports analytics: challenges, approaches, and lessons learned. Machine Learning113(9), 6977–7010 (2024)
work page 2024
-
[12]
De Nies, T., D’heer, E., Coppens, S., Van Deursen, D., Mannens, E., Paulussen, S., Van de Walle, R.: Bringing newsworthiness into the 21st century. In: WoLE@ ISWC. pp. 106–117 (2012)
work page 2012
-
[13]
arXiv preprint arXiv:2005.00547 (2020)
Demszky, D., Movshovitz-Attias, D., Ko, J., Cowen, A., Nemade, G., Ravi, S.: Goemotions: A dataset of fine-grained emotions. arXiv preprint arXiv:2005.00547 (2020)
-
[14]
DiRenzo, E.: Developing a Sports Analytics Information System for Legends Sports Leagues. Ph.D. thesis, Worcester Polytechnic Institute (2020)
work page 2020
-
[15]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
ACM Computing Surveys (CSUR)50(2), 1–34 (2017)
Gudmundsson, J., Horton, M.: Spatio-temporal analysis of team sports. ACM Computing Surveys (CSUR)50(2), 1–34 (2017)
work page 2017
-
[17]
IEEE Transactions on Computational Social Systems (2024)
Guo, Z., Li, Y., Yang, Z., Li, X., Lee, L.K., Li, Q., Liu, W.: Cross-modal attention network for detecting multimodal misinformation from multiple platforms. IEEE Transactions on Computational Social Systems (2024)
work page 2024
-
[18]
Gupta, M.: Linking event mentions from cricket match reports to commentaries. In: Workshop on Machine Learning and Data Mining for Sports Analytics (MLSA) (2017) Ranking Sports Insights from LLMs 15
work page 2017
-
[19]
In: Wong, K.F., Knight, K., Wu, H
Huang, K.H., Li, C., Chang, K.W.: Generating sports news from live commentary: A Chinese dataset for sports game summarization. In: Wong, K.F., Knight, K., Wu, H. (eds.) AACL-IJCNLP. pp. 609–615 (Dec 2020)
work page 2020
-
[20]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
v8i1.14550,https://ojs.aaai.org/index.php/ICWSM/article/view/14550
Hutto, C., Gilbert, E.: Vader: A parsimonious rule-based model for sentiment anal- ysisofsocialmediatext.ProceedingsoftheInternationalAAAIConferenceonWeb and Social Media8(1), 216–225 (May 2014).https://doi.org/10.1609/icwsm. v8i1.14550,https://ojs.aaai.org/index.php/ICWSM/article/view/14550
-
[22]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de Las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7b. ArXivabs/2310.06825(2023),https://api. semanticscholar.org/CorpusID:263830494
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
IEEE Transactions on Big Data7(3), 535–547 (2019)
Johnson, J., Douze, M., Jégou, H.: Billion-scale similarity search with gpus. IEEE Transactions on Big Data7(3), 535–547 (2019)
work page 2019
-
[24]
Jung, D.H., Jung, J.J.: Data-driven understanding on soccer team tactics and rankingtrends:Elorating-basedtrendsoneuropeansoccerleagues.PloSone20(2), e0318485 (2025)
work page 2025
-
[25]
Karat, A., Tibrewal, A., Kotian, N., Dang, M., Valluri, R., Ravi Teja Marineni, A., Sahni, S., Sundaresan, R., Kumar, A., Mehndiratta, A., et al.: A system for triggering sports instant answers on search engines. In: Proceedings of the 48th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 4304–4308 (2025)
work page 2025
-
[26]
Transactions of the Association for Computational Linguistics10, 163–177 (2022)
Laban, P., Schnabel, T., Bennett, P.N., Hearst, M.A.: Summac: Re-visiting nli- based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics10, 163–177 (2022)
work page 2022
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
Mahmood,Y.,Mahmood,B.:Awebscraperfordataminingpurposes.SISTEMASI 13, 1243–1252 (05 2024)
work page 2024
-
[29]
doi:10.48550/arXiv.2305.14251 , abstract =
Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W.t., Koh, P.W., Iyyer, M., Zettle- moyer, L., Hajishirzi, H.: Factscore: Fine-grained atomic evaluation of factual pre- cision in long form text generation. arXiv preprint arXiv:2305.14251 (2023)
-
[30]
arXiv preprint arXiv:2307.10303 (2023)
Miraoui, Y.: Analyzing sports commentary in order to automatically recognize events and extract insights. arXiv preprint arXiv:2307.10303 (2023)
-
[31]
Advances in Complex Systems24(10 2021)
Morales, J., Flores, J., Gershenson, C.: Statistical properties of rankings in sports and games. Advances in Complex Systems24(10 2021)
work page 2021
-
[32]
Naing, I., Aung, S.T., Wai, K.H., Funabiki, N.: A reference paper collection system using web scraping. Electronics13(14) (2024)
work page 2024
-
[33]
arXiv preprint arXiv:1103.2903 (2011)
Nielsen, F.Å.: A new anew: Evaluation of a word list for sentiment analysis in microblogs. arXiv preprint arXiv:1103.2903 (2011)
-
[34]
Ochieng, P.J., London, A., Krész, M.: A forward-looking approach to compare ranking methods for sports. Information13(5) (2022)
work page 2022
-
[35]
Applied AI letters2(1), e21 (2021) 16 Kumar et al
Pavitt, J., Braines, D., Tomsett, R.: Cognitive analysis in sports: Supporting match analysis and scouting through artificial intelligence. Applied AI letters2(1), e21 (2021) 16 Kumar et al
work page 2021
-
[36]
International Journal of Recent Technology and Engineering (IJRTE)8, 5622–5627 (03 2020)
Polisetty, S., Deepthi, S., Ameen, S., G, R., Mounisha, M.: Extractive text summa- rization for sports articles using statistical method. International Journal of Recent Technology and Engineering (IJRTE)8, 5622–5627 (03 2020)
work page 2020
-
[37]
Journal of machine learning research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020)
work page 2020
-
[38]
Rajaraman, A., Ullman, J.D.: Data Mining, p. 1–17. Cambridge University Press (2011)
work page 2011
-
[39]
Rowe, D.: Global media sport: Flows, forms and futures. Bloomsbury Academic (2011)
work page 2011
-
[40]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Seti, X., Wumaier, A., Yibulayin, T., Paerhati, D., Wang, L., Saimaiti, A.: Named- entity recognition in sports field based on a character-level graph convolutional network. Information11(1) (2020)
work page 2020
-
[42]
arXiv preprint arXiv:2410.09455 (2024)
Shah, A., Shah, H., Bafna, V., Khandor, C., Nair, S.: Veritas-nli: Validation and ex- traction of reliable information through automated scraping and natural language inference. arXiv preprint arXiv:2410.09455 (2024)
-
[43]
Applied Sciences 10(17), 5833 (2020)
Shi, J., Tian, X.Y.: Learning to rank sports teams on a graph. Applied Sciences 10(17), 5833 (2020)
work page 2020
-
[44]
Soft Computing26(9), 4487–4507 (2022)
Vashishtha, S., Susan, S.: Neuro-fuzzy network incorporating multiple lexicons for social sentiment analysis. Soft Computing26(9), 4487–4507 (2022)
work page 2022
-
[45]
Journal of the Operational Research Society69(5), 776–787 (2018)
Vaziri, B., Dabadghao, S., Yih, Y., Morin, T.L.: Properties of sports ranking meth- ods. Journal of the Operational Research Society69(5), 776–787 (2018)
work page 2018
- [46]
-
[47]
arXiv preprint arXiv:2207.08635 (2022)
Wang, J., Zhang, T., Shi, H.: Goal: Towards benchmarking few-shot sports game summarization. arXiv preprint arXiv:2207.08635 (2022)
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
arXiv preprint arXiv:2103.13736 (2021)
Yazbek, D., Sibindi, J.S., Van Zyl, T.L.: Deep similarity learning for sports team ranking. arXiv preprint arXiv:2103.13736 (2021)
-
[50]
arXiv preprint arXiv:2012.06366 (2020)
Zhou, Y., Wang, R., Zhang, Y.C., Zeng, A., Medo, M.: Limits of pagerank-based ranking methods in sports data. arXiv preprint arXiv:2012.06366 (2020)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.