Recognition: 1 theorem link
· Lean TheoremFrom Video to Control: A Survey of Learning Manipulation Interfaces from Temporal Visual Data
Pith reviewed 2026-05-13 16:59 UTC · model grok-4.3
The pith
Video-based robot manipulation methods are limited most by how predictions connect to reliable physical actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
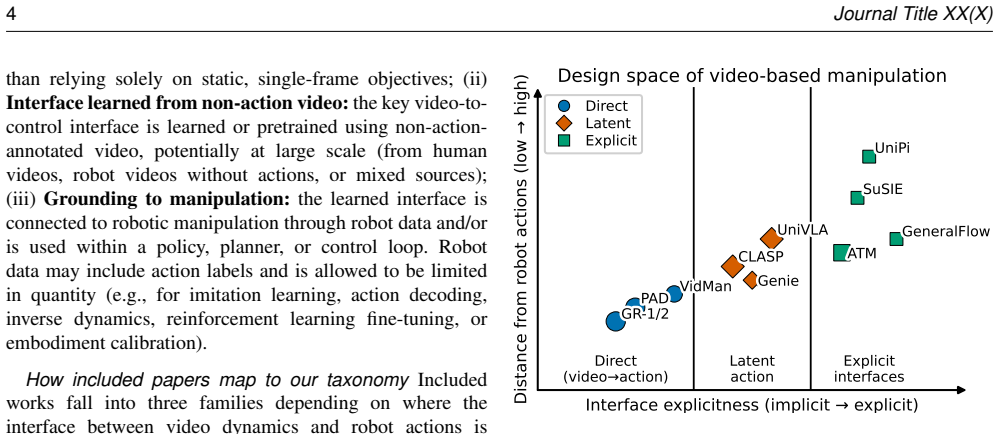
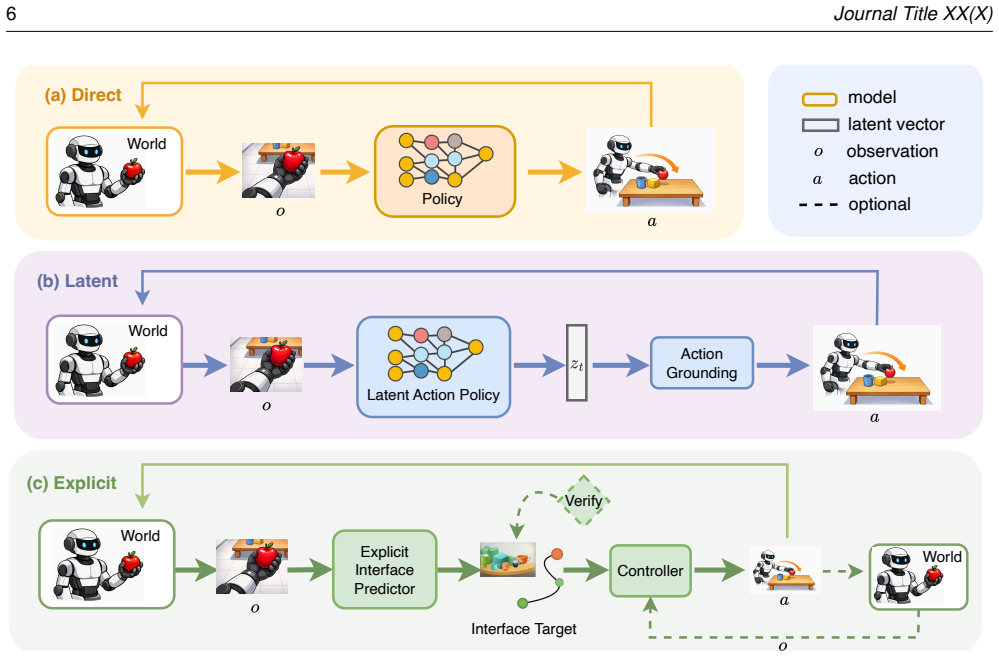
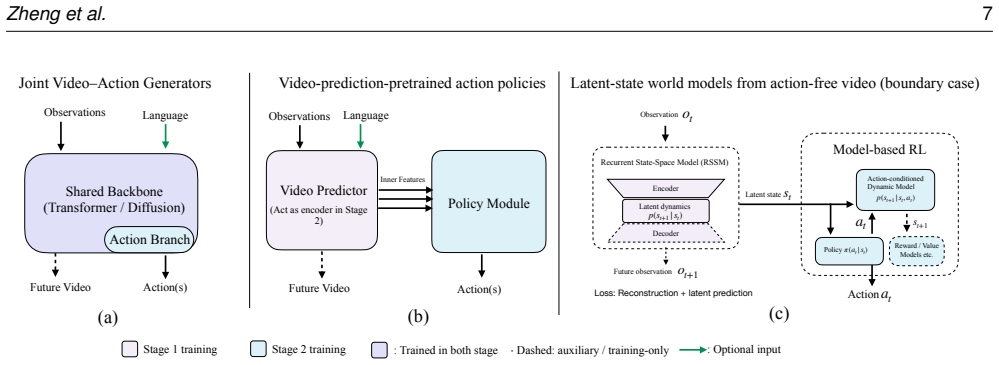
The paper defines an interface-centric taxonomy that places existing video-to-control methods into three families: direct video-action policies that keep the mapping implicit, latent-action methods that pass temporal structure through a compact learned representation, and explicit visual interfaces that output interpretable targets for separate controllers. Analysis of control-integration properties across families shows that the robotics integration layer remains the primary barrier to dependable execution.
What carries the argument
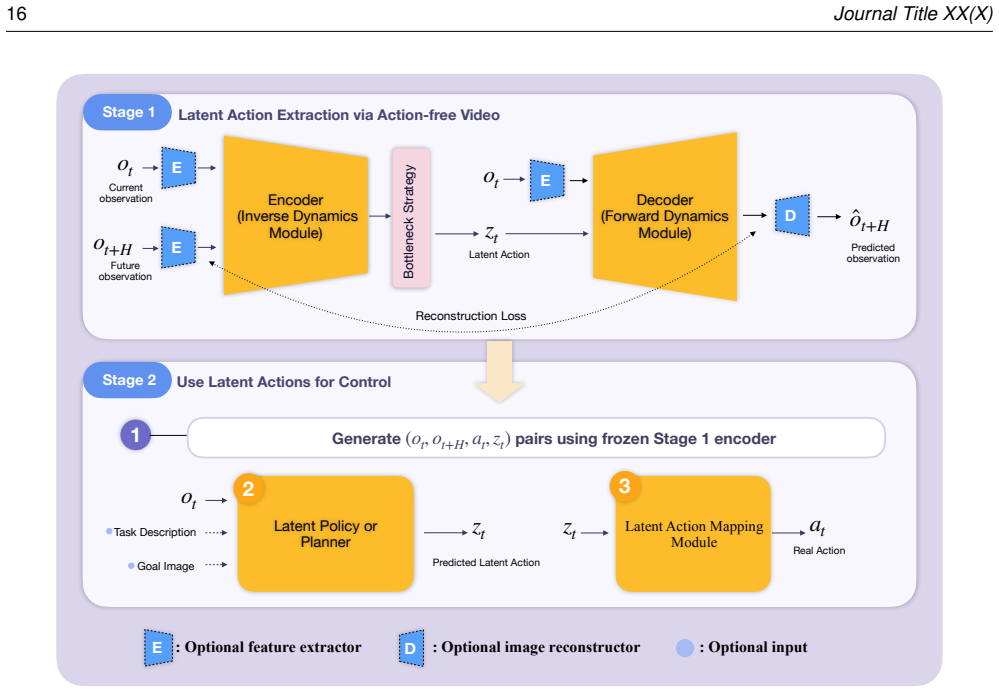
The interface-centric taxonomy that classifies methods by the construction site of the video-to-control interface and the resulting control properties.
If this is right
- Each family closes the control loop at a different stage and admits different forms of pre-execution verification.
- Failure modes enter at distinct points depending on whether the interface is implicit, latent, or explicit.
- Further progress requires targeted work on the robotics integration layer that translates video predictions into safe robot commands.
- The taxonomy supplies a common language for comparing how different methods handle embodiment gaps and missing action labels.
Where Pith is reading between the lines
- Hybrid methods that borrow elements from multiple families could address integration weaknesses that single-family approaches leave open.
- Standardized testbeds focused on integration properties would make it easier to measure whether new techniques actually improve dependable behavior.
- Deployment on physical robots with changing viewpoints and contact dynamics would expose integration shortcomings more clearly than simulation results alone.
Load-bearing premise
The proposed three-family taxonomy captures the essential differences among current video-to-control methods without missing major approaches or imposing artificial divisions.
What would settle it
A published video-based manipulation technique that cannot be assigned to any of the three families in the taxonomy.
Figures




read the original abstract
Video is a scalable observation of physical dynamics: it captures how objects move, how contact unfolds, and how scenes evolve under interaction -- all without requiring robot action labels. Yet translating this temporal structure into reliable robotic control remains an open challenge, because video lacks action supervision and differs from robot experience in embodiment, viewpoint, and physical constraints. This survey reviews methods that exploit non-action-annotated temporal video to learn control interfaces for robotic manipulation. We introduce an \emph{interface-centric taxonomy} organized by where the video-to-control interface is constructed and what control properties it enables, identifying three families: direct video--action policies, which keep the interface implicit; latent-action methods, which route temporal structure through a compact learned intermediate; and explicit visual interfaces, which predict interpretable targets for downstream control. For each family, we analyze control-integration properties -- how the loop is closed, what can be verified before execution, and where failures enter. A cross-family synthesis reveals that the most pressing open challenges center on the \emph{robotics integration layer} -- the mechanisms that connect video-derived predictions to dependable robot behavior -- and we outline research directions toward closing this gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews methods that exploit non-action-annotated temporal video to learn control interfaces for robotic manipulation. It introduces an interface-centric taxonomy organized by where the video-to-control interface is constructed, identifying three families: direct video-action policies (implicit interface), latent-action methods (compact learned intermediate), and explicit visual interfaces (interpretable targets for downstream control). For each family the paper analyzes control-integration properties including loop closure, pre-execution verifiability, and failure modes. A cross-family synthesis concludes that the robotics integration layer constitutes the dominant open challenge and outlines research directions to close the gap.
Significance. If the taxonomy and per-family analyses hold, the survey supplies a useful organizing lens that shifts emphasis from isolated algorithmic advances to the mechanisms needed to connect video-derived predictions to dependable robot behavior. This framing can help the community prioritize integration-layer research, which is essential for translating abundant video data into practical manipulation systems.
minor comments (2)
- [Abstract] Abstract: the three-family taxonomy is presented as capturing essential distinctions, yet the boundary between latent-action and explicit visual interfaces is not illustrated with a borderline example; adding one concrete method that could plausibly fit either category would strengthen the taxonomy's clarity without altering the central claim.
- [Synthesis section] The cross-family synthesis identifies the robotics integration layer as the primary open challenge; a short table or bullet list enumerating the specific integration shortcomings observed in each family would make this claim more immediately verifiable for readers.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our survey, for highlighting the utility of the interface-centric taxonomy, and for recommending acceptance. We appreciate the recognition that the work shifts focus toward the robotics integration layer as the central open challenge.
Circularity Check
No significant circularity
full rationale
This is a survey paper that reviews existing methods, proposes an interface-centric taxonomy as an organizing lens, and synthesizes open challenges from the literature. No equations, derivations, fitted parameters, or predictions appear anywhere in the manuscript. The central claim (robotics integration layer as dominant challenge) is a qualitative observation drawn from per-family analysis of external work, not a reduction to any internal definition or self-citation chain. The taxonomy is explicitly presented as a useful framing rather than a uniqueness theorem or ansatz. All citations are to independent prior literature; no load-bearing step collapses to the authors' own prior results by construction. The paper is therefore self-contained against external benchmarks with zero circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an interface-centric taxonomy organized by where the video-to-control interface is constructed and what control properties it enables, identifying three families: direct video–action policies... latent-action methods... explicit visual interfaces...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Science Robotics 10(106): eadt1497
Ai B, Tian S, Shi H, Wang Y, Pfaff T, Tan C, Christensen HI, Su H, Wu J and Li Y (2025) A review of learning-based dynamics models for robotic manipulation. Science Robotics 10(106): eadt1497. doi:10.1126/scirobotics.adt1497. ://www.science.org/doi/abs/10.1126/scirobotics.adt1497
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence PAMI-9(5): 698--700
Arun KS, Huang TS and Blostein SD (1987) Least-squares fitting of two 3-d point sets. IEEE Transactions on Pattern Analysis and Machine Intelligence PAMI-9(5): 698--700. doi:10.1109/TPAMI.1987.4767965
-
[3]
Bahl S, Mendonca R, Chen L, Jain U and Pathak D (2023) Affordances from human videos as a versatile representation for robotics. ://arxiv.org/abs/2304.08488
-
[4]
Procedia Computer Science 217: 1887--1895
Baratta A, Cimino A, Gnoni MG and Longo F (2023) Human robot collaboration in industry 4.0: a literature review. Procedia Computer Science 217: 1887--1895
work page 2023
-
[5]
arXiv preprint arXiv:2409.16283 (2024)
Bharadhwaj H, Dwibedi D, Gupta A, Tulsiani S, Doersch C, Xiao T, Shah D, Xia F, Sadigh D and Kirmani S (2024 a ) Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation. ://arxiv.org/abs/2409.16283
-
[6]
Bharadhwaj H, Mottaghi R, Gupta A and Tulsiani S (2024 b ) Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. ://arxiv.org/abs/2405.01527
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black K, Brown N, Driess D, Esmail A, Equi M, Finn C, Fusai N, Groom L, Hausman K, Ichter B et al. (2024) 0: A vision-language-action flow model for general robot control ://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
-
[9]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann A, Dockhorn T, Kulal S, Mendelevitch D, Kilian M, Lorenz D, Levi Y, English Z, Voleti V, Letts A et al. (2023) Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan A, Brown N, Carbajal J, Chebotar Y, Chen X, Choromanski K, Ding T, Driess D, Dubey A, Finn C, Florence P, Fu C, Arenas MG, Gopalakrishnan K, Han K, Hausman K, Herzog A, Hsu J, Ichter B, Irpan A, Joshi N, Julian R, Kalashnikov D, Kuang Y, Leal I, Lee L, Lee TWE, Levine S, Lu Y, Michalewski H, Mordatch I, Pertsch K, Rao K, Reymann K, Ryoo M, Salazar ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan A, Brown N, Carbajal J, Chebotar Y, Dabis J, Finn C, Gopalakrishnan K, Hausman K, Herzog A, Hsu J, Ibarz J, Ichter B, Irpan A, Jackson T, Jesmonth S, Joshi N, Julian R, Kalashnikov D, Kuang Y, Leal I, Lee KH, Levine S, Lu Y, Malla U, Manjunath D, Mordatch I, Nachum O, Parada C, Peralta J, Perez E, Pertsch K, Quiambao J, Rao K, Ryoo M, Salazar G, Sa...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
In- structpix2pix: Learning to follow image editing instructions
Brooks T, Holynski A and Efros AA (2023) Instructpix2pix: Learning to follow image editing instructions. ://arxiv.org/abs/2211.09800
-
[13]
Genie: Generative interactive environments, 2024
Bruce J, Dennis M, Edwards A, Parker-Holder J, Shi Y, Hughes E, Lai M, Mavalankar A, Steigerwald R, Apps C, Aytar Y, Bechtle S, Behbahani F, Chan S, Heess N, Gonzalez L, Osindero S, Ozair S, Reed S, Zhang J, Zolna K, Clune J, de Freitas N, Singh S and Rocktäschel T (2024) Genie: Generative interactive environments. ://arxiv.org/abs/2402.15391
-
[14]
In: Proceedings of Robotics: Science and Systems
Bu Q, Yang Y, Cai J, Gao S, Ren G, Yao M, Luo P and Li H (2025) Learning to Act Anywhere with Task-centric Latent Actions . In: Proceedings of Robotics: Science and Systems. LosAngeles, CA, USA. doi:10.15607/RSS.2025.XXI.014
-
[15]
Bu Q, Zeng J, Chen L, Yang Y, Zhou G, Yan J, Luo P, Cui H, Ma Y and Li H (2024) Closed-loop visuomotor control with generative expectation for robotic manipulation. ://arxiv.org/abs/2409.09016
-
[16]
A short note on the kinetics-700 human action dataset
Carreira J, Noland E, Hillier C and Zisserman A (2022) A short note on the kinetics-700 human action dataset. ://arxiv.org/abs/1907.06987
-
[17]
Chao YW, Yang W, Xiang Y, Molchanov P, Handa A, Tremblay J, Narang YS, Wyk KV, Iqbal U, Birchfield S, Kautz J and Fox D (2021) Dexycb: A benchmark for capturing hand grasping of objects. ://arxiv.org/abs/2104.04631
-
[18]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Cheang CL, Chen G, Jing Y, Kong T, Li H, Li Y, Liu Y, Wu H, Xu J, Yang Y, Zhang H and Zhu M (2024) Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. ://arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Chen S, Guo H, Zhu S, Zhang F, Huang Z, Feng J and Kang B (2025) Video depth anything: Consistent depth estimation for super-long videos. arXiv:2501.12375
-
[20]
The International Journal of Robotics Research 30(11): 1343--1377
Chen S, Li Y and Kwok NM (2011) Active vision in robotic systems: A survey of recent developments. The International Journal of Robotics Research 30(11): 1343--1377
work page 2011
-
[21]
IEEE Transactions on Cybernetics 53(3): 1682--1698
Cong Y, Chen R, Ma B, Liu H, Hou D and Yang C (2021) A comprehensive study of 3-d vision-based robot manipulation. IEEE Transactions on Cybernetics 53(3): 1682--1698
work page 2021
-
[22]
(2018) Scaling egocentric vision: The epic-kitchens dataset
Damen D, Doughty H, Farinella GM, Fidler S, Furnari A, Kazakos E, Moltisanti D, Munro J, Perrett T, Price W et al. (2018) Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European conference on computer vision (ECCV). pp. 720--736
work page 2018
-
[23]
International Journal of Computer Vision (IJCV) 130: 33–55
Damen D, Doughty H, Farinella GM, Furnari A, Ma J, Kazakos E, Moltisanti D, Munro J, Perrett T, Price W and Wray M (2022) Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100. International Journal of Computer Vision (IJCV) 130: 33–55. ://doi.org/10.1007/s11263-021-01531-2
-
[24]
(2025) A survey on reinforcement learning of vision-language-action models for robotic manipulation
Deng H, Wu Z, Liu H, Guo W, Xue Y, Shan Z, Zhang C, Jia B, Ling Y, Lu G et al. (2025) A survey on reinforcement learning of vision-language-action models for robotic manipulation. Authorea Preprints
work page 2025
-
[25]
Dharmarajan K, Huang W, Wu J, Fei-Fei L and Zhang R (2025) Dream2flow: Bridging video generation and open-world manipulation with 3d object flow. ://arxiv.org/abs/2512.24766
-
[26]
arXiv preprint arXiv:2507.10672 , year=
Din MU, Akram W, Saoud LS, Rosell J and Hussain I (2025) Vision language action models in robotic manipulation: A systematic review. arXiv preprint arXiv:2507.10672
-
[27]
Du Y, Yang S, Dai B, Dai H, Nachum O, Tenenbaum J, Schuurmans D and Abbeel P (2023) Learning universal policies via text-guided video generation. In: Oh A, Naumann T, Globerson A, Saenko K, Hardt M and Levine S (eds.) Advances in Neural Information Processing Systems, volume 36. Curran Associates, Inc., pp. 9156--9172. ://proceedings.neurips.cc/paper_file...
work page 2023
-
[28]
In: 2008 IEEE International Conference on Automation and Logistics
Echelmeyer W, Kirchheim A and Wellbrock E (2008) Robotics-logistics: Challenges for automation of logistic processes. In: 2008 IEEE International Conference on Automation and Logistics. IEEE, pp. 2099--2103
work page 2008
-
[29]
Edwards AD, Sahni H, Schroecker Y and Isbell CL (2019) Imitating latent policies from observation. ://arxiv.org/abs/1805.07914
-
[30]
arXiv preprint arXiv:2205.04382
Eisner B, Zhang H and Held D (2022) Flowbot3d: Learning 3d articulation flow to manipulate articulated objects. arXiv preprint arXiv:2205.04382
-
[31]
Eze C and Crick C (2025) Learning by watching: A review of video-based learning approaches for robot manipulation. ://arxiv.org/abs/2402.07127
-
[32]
Remittances Review 9: 871--888
Faheem MA, Zafar N, Kumar P, Melon M, Prince N and Al Mamun MA (2024) Ai and robotic: About the transformation of construction industry automation as well as labor productivity. Remittances Review 9: 871--888
work page 2024
-
[33]
Rh20t: A robotic dataset for learning diverse skills in one-shot
Fang HS, Fang H, Tang Z, Liu J, Wang C, Wang J, Zhu H and Lu C (2023) Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. arXiv preprint arXiv:2307.00595
-
[34]
Autonomous robots 9(3): 227--235
Fiorini P and Prassler E (2000) Cleaning and household robots: A technology survey. Autonomous robots 9(3): 227--235
work page 2000
-
[35]
Fischler MA and Bolles RC (1981) Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 24(6): 381–395. doi:10.1145/358669.358692. ://doi.org/10.1145/358669.358692
-
[36]
Goyal R, Kahou SE, Michalski V, Materzyńska J, Westphal S, Kim H, Haenel V, Fruend I, Yianilos P, Mueller-Freitag M, Hoppe F, Thurau C, Bax I and Memisevic R (2017) The "something something" video database for learning and evaluating visual common sense. ://arxiv.org/abs/1706.04261
-
[37]
(2022) Ego4d: Around the world in 3,000 hours of egocentric video
Grauman K, Westbury A, Byrne E, Chavis Z, Furnari A, Girdhar R, Hamburger J, Jiang H, Liu M, Liu X et al. (2022) Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18995--19012
work page 2022
-
[38]
Gu J, Xiang F, Li X, Ling Z, Liu X, Mu T, Tang Y, Tao S, Wei X, Yao Y et al. (2023) Maniskill2: A unified benchmark for generalizable manipulation skills. arXiv preprint arXiv:2302.04659
-
[39]
Guo Y, Hu Y, Zhang J, Wang YJ, Chen X, Lu C and Chen J (2024) Prediction with action: Visual policy learning via joint denoising process. ://arxiv.org/abs/2411.18179
-
[40]
Learning Latent Dynamics for Planning from Pixels
Hafner D, Lillicrap T, Fischer I, Villegas R, Ha D, Lee H and Davidson J (2019) Learning latent dynamics for planning from pixels. ://arxiv.org/abs/1811.04551
work page Pith review arXiv 2019
-
[41]
Mastering Atari with Discrete World Models
Hafner D, Lillicrap T, Norouzi M and Ba J (2022) Mastering atari with discrete world models. ://arxiv.org/abs/2010.02193
work page internal anchor Pith review arXiv 2022
-
[42]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Hu Y, Guo Y, Wang P, Chen X, Wang YJ, Zhang J, Sreenath K, Lu C and Chen J (2024) Video prediction policy: A generalist robot policy with predictive visual representations. ://arxiv.org/abs/2412.14803
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Huang W, Chao YW, Mousavian A, Liu MY, Fox D, Mo K and Fei-Fei L (2026) Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. ://arxiv.org/abs/2601.03782
-
[44]
Huang W, Wang C, Li Y, Zhang R and Fei-Fei L (2024) Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation. arXiv preprint arXiv:2409.01652
-
[45]
IEEE Robotics and Automation Letters 5(2): 3019--3026
James S, Ma Z, Arrojo DR and Davison AJ (2020) Rlbench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters 5(2): 3019--3026
work page 2020
-
[46]
In: European conference on computer vision
Karaev N, Rocco I, Graham B, Neverova N, Vedaldi A and Rupprecht C (2024) Cotracker: It is better to track together. In: European conference on computer vision. Springer, pp. 18--35
work page 2024
-
[47]
Kerr J, Kim CM, Wu M, Yi B, Wang Q, Goldberg K and Kanazawa A (2024) Robot see robot do: Imitating articulated object manipulation with monocular 4d reconstruction. ://arxiv.org/abs/2409.18121
-
[48]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky A, Pertsch K, Nair S, Balakrishna A, Dasari S, Karamcheti S, Nasiriany S, Srirama MK, Chen LY, Ellis K et al. (2024) Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Kingma DP and Welling M (2019) An introduction to variational autoencoders. Foundations and Trends® in Machine Learning 12(4): 307–392. doi:10.1561/2200000056. ://dx.doi.org/10.1561/2200000056
- [50]
-
[51]
Technical Report ISRN KTH/NA/P-02/01-SE, KTH Royal Institute of Technology
Kragic D and Christensen HI (2002) Survey on visual servoing for manipulation. Technical Report ISRN KTH/NA/P-02/01-SE, KTH Royal Institute of Technology. CVAP259
work page 2002
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kwon T, Tekin B, St\"uhmer J, Bogo F and Pollefeys M (2021) H2o: Two hands manipulating objects for first person interaction recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10138--10148
work page 2021
-
[53]
arXiv preprint arXiv:2212.06870 (2022)
Labbé Y, Manuelli L, Mousavian A, Tyree S, Birchfield S, Tremblay J, Carpentier J, Aubry M, Fox D and Sivic J (2022) Megapose: 6d pose estimation of novel objects via render & compare. ://arxiv.org/abs/2212.06870
-
[54]
International Journal of Computer Vision (IJCV) 81
Lepetit V, Moreno-Noguer F and Fua P (2009) EPnP: An accurate O(n) solution to the PnP problem . International Journal of Computer Vision (IJCV) 81. doi:10.1007/s11263-008-0152-6
-
[55]
(2024) What foundation models can bring for robot learning in manipulation: A survey
Li D, Jin Y, Sun Y, A Y, Yu H, Shi J, Hao X, Hao P, Liu H, Li X et al. (2024) What foundation models can bring for robot learning in manipulation: A survey. The International Journal of Robotics Research : 02783649251390579
work page 2024
-
[56]
Li S, Gao Y, Sadigh D and Song S (2025) Unified video action model. ://arxiv.org/abs/2503.00200
work page internal anchor Pith review arXiv 2025
-
[57]
In: 8th Annual Conference on Robot Learning
Liang J, Liu R, Ozguroglu E, Sudhakar S, Dave A, Tokmakov P, Song S and Vondrick C (2024) Dreamitate: Real-world visuomotor policy learning via video generation. In: 8th Annual Conference on Robot Learning. ://openreview.net/forum?id=InT87E5sr4
work page 2024
-
[58]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Liu B, Zhu Y, Gao C, Feng Y, Liu Q, Zhu Y and Stone P (2023) Libero: Benchmarking knowledge transfer for lifelong robot learning. arXiv preprint arXiv:2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
arXiv preprint arXiv:2403.03174
Liu F, Fang K, Abbeel P and Levine S (2024) Moka: Open-world robotic manipulation through mark-based visual prompting. arXiv preprint arXiv:2403.03174
-
[60]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu Y, Liu Y, Jiang C, Lyu K, Wan W, Shen H, Liang B, Fu Z, Wang H and Yi L (2022) Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21013--21022
work page 2022
-
[61]
arXiv preprint arXiv:2411.07223 (2024)
Luo Y and Du Y (2025) Grounding video models to actions through goal conditioned exploration. ://arxiv.org/abs/2411.07223
-
[62]
IEEE Robotics and Automation Letters
Lynch C, Wahid A, Tompson J, Ding T, Betker J, Baruch R, Armstrong T and Florence P (2023) Interactive language: Talking to robots in real time. IEEE Robotics and Automation Letters
work page 2023
-
[63]
Ma YJ, Liang W, Som V, Kumar V, Zhang A, Bastani O and Jayaraman D (2023 a ) Liv: Language-image representations and rewards for robotic control. ://arxiv.org/abs/2306.00958
-
[64]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Ma YJ, Sodhani S, Jayaraman D, Bastani O, Kumar V and Zhang A (2023 b ) Vip: Towards universal visual reward and representation via value-implicit pre-training. ://arxiv.org/abs/2210.00030
work page internal anchor Pith review arXiv 2023
-
[65]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Mandlekar A, Xu D, Wong J, Nasiriany S, Wang C, Kulkarni R, Fei-Fei L, Savarese S, Zhu Y and Mart \' n-Mart \' n R (2021) What matters in learning from offline human demonstrations for robot manipulation. arXiv preprint arXiv:2108.03298
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[66]
Journal of Artificial Intelligence Research 83
McCarthy R, Tan DCH, Schmidt D, Acero F, Herr N, Du Y, Thuruthel TG and Li Z (2025) Towards generalist robot learning from internet video: A survey. Journal of Artificial Intelligence Research 83
work page 2025
-
[67]
Mees O, Hermann L, Rosete-Beas E and Burgard W (2022) Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. ://arxiv.org/abs/2112.03227
-
[68]
Structured world models from human videos.arXiv preprint arXiv:2308.10901, 2023
Mendonca R, Bahl S and Pathak D (2023) Structured world models from human videos. ://arxiv.org/abs/2308.10901
- [69]
-
[70]
(2025) Recipe for vision-language-action models in robotic manipulation: A survey
Motoda T, Makihara K, Nakajo R, Oh H, Shirai K, Hanai R, Murooka M, Suzuki Y, Nishihara H, Takeda M et al. (2025) Recipe for vision-language-action models in robotic manipulation: A survey. Authorea Preprints
work page 2025
-
[71]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Nasiriany S, Kirmani S, Ding T, Smith L, Zhu Y, Driess D, Sadigh D and Xiao T (2025) Rt-affordance: Affordances are versatile intermediate representations for robot manipulation. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, pp. 8249--8257
work page 2025
-
[72]
(2024) Open x-embodiment: Robotic learning datasets and rt-x models
Open X-Embodiment Collaboration A O’Neill, Rehman A, Maddukuri A, Gupta A, Padalkar A, Lee A, Pooley A, Gupta A, Mandlekar A, Jain A et al. (2024) Open x-embodiment: Robotic learning datasets and rt-x models. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, pp. 6892--6903
work page 2024
-
[73]
DINOv2: Learning Robust Visual Features without Supervision
Oquab M, Darcet T, Moutakanni T, Vo H, Szafraniec M, Khalidov V, Fernandez P, Haziza D, Massa F, El-Nouby A et al. (2023) Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Patel S, Mohan S, Mai H, Jain U, Lazebnik S and Li Y (2025) Robotic manipulation by imitating generated videos without physical demonstrations. ://arxiv.org/abs/2507.00990
work page Pith review arXiv 2025
-
[75]
arXiv preprint arXiv:2402.08191 (2024) 14
Pumacay W, Singh I, Duan J, Krishna R, Thomason J and Fox D (2024) The colosseum: A benchmark for evaluating generalization for robotic manipulation. arXiv preprint arXiv:2402.08191
-
[76]
In: 2020 IEEE International Conference on Robotics and Automation (ICRA)
Qin Z, Fang K, Zhu Y, Fei-Fei L and Savarese S (2020) Keto: Learning keypoint representations for tool manipulation. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, pp. 7278--7285
work page 2020
-
[77]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu D, Song H, Chen Q, Yao Y, Ye X, Ding Y, Wang Z, Gu J, Zhao B, Wang D et al. (2025) Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Rybkin O, Pertsch K, Derpanis KG, Daniilidis K and Jaegle A (2019) Learning what you can do before doing anything. ://arxiv.org/abs/1806.09655
-
[79]
Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
Schmidt D and Jiang M (2024) Learning to act without actions. ://arxiv.org/abs/2312.10812
-
[80]
Seo Y, Lee K, James S and Abbeel P (2022) Reinforcement learning with action-free pre-training from videos. ://arxiv.org/abs/2203.13880
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.