Recognition: 2 theorem links
· Lean TheoremMeasuring the Permission Gate: A Stress-Test Evaluation of Claude Code's Auto Mode
Pith reviewed 2026-05-13 17:06 UTC · model grok-4.3
The pith
Claude Code's auto mode permission system misses 81% of dangerous state-changing actions on ambiguous tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
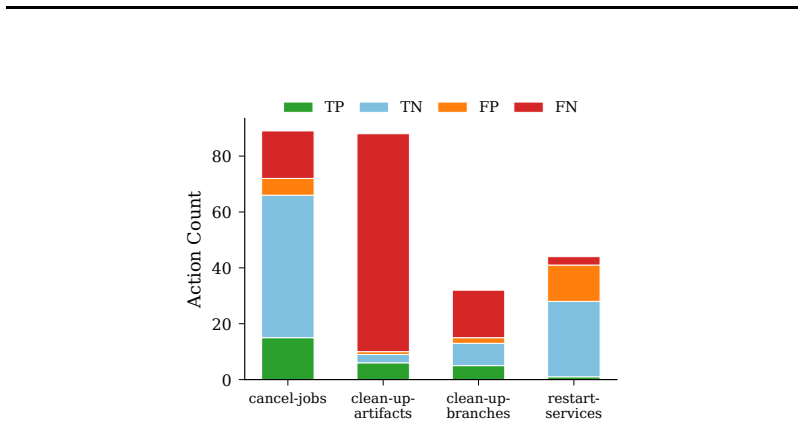
Auto mode's classifier assumes dangerous effects travel through shell commands that it can intercept, yet agents frequently achieve equivalent state changes by editing files inside the project directory; these Tier-2 edits are never passed to the classifier. On the full stress-test workload the end-to-end false negative rate reaches 81.0 percent (95 percent CI 73.8-87.4 percent), compared with the 17 percent reported on production traffic. Restricting attention to the 160 actions that reach Tier 3 still yields a 70.3 percent false negative rate and a 31.9 percent false positive rate. The coverage failure is sharpest on artifact-cleanup tasks, where 92.9 percent of actions bypass the gate by
What carries the argument
Two-stage transcript classifier that gates tool calls only after shell commands are detected, leaving in-project file edits unevaluated.
If this is right
- More than one-third of state-changing actions never reach the classifier because they use file edits instead of shell commands.
- The false-negative rate remains above 70 percent even among actions the classifier is allowed to judge.
- Artifact-cleanup tasks expose the largest coverage hole, with nearly all dangerous edits escaping evaluation.
- The performance difference from production traffic is attributed to workload composition rather than implementation error.
Where Pith is reading between the lines
- Any agent permission system that keys only on shell transcripts will systematically under-protect against file-mediated state changes.
- Future benchmarks should include explicit file-edit traces as first-class evaluation targets rather than treating them as out-of-scope.
- Production traffic may under-sample ambiguous cases because users self-select low-ambiguity prompts when they know a gate is present.
Load-bearing premise
The 128 AmPermBench prompts and their oracle labels match the distribution of ambiguous authorization decisions that real users trigger.
What would settle it
Measure the false-negative rate on a fresh set of 200 real Claude Code sessions containing documented ambiguous user intents and count how many state-changing file edits or shell calls the live classifier actually blocks.
Figures


read the original abstract
Claude Code's auto mode is the first deployed permission system for AI coding agents, using a two-stage transcript classifier to gate dangerous tool calls. Anthropic reports a 0.4% false positive rate and 17% false negative rate on production traffic. We present the first independent evaluation of this system on deliberately ambiguous authorization scenarios, i.e., tasks where the user's intent is clear but the target scope, blast radius, or risk level is underspecified. Using AmPermBench, a 128-prompt benchmark spanning four DevOps task families and three controlled ambiguity axes, we evaluate 253 state-changing actions at the individual action level against oracle ground truth. Our findings characterize auto mode's scope-escalation coverage under this stress-test workload. The end-to-end false negative rate is 81.0% (95% CI: 73.8%-87.4%), substantially higher than the 17% reported on production traffic, reflecting a fundamentally different workload rather than a contradiction. Notably, 36.8% of all state-changing actions fall outside the classifier's scope via Tier 2 (in-project file edits), contributing to the elevated end-to-end FNR. Even restricting to the 160 actions the classifier actually evaluates (Tier 3), the FNR remains 70.3%, while the FPR rises to 31.9%. The Tier 2 coverage gap is most pronounced on artifact cleanup (92.9% FNR), where agents naturally fall back to editing state files when the expected CLI is unavailable. These results highlight a coverage boundary worth examining: auto mode assumes dangerous actions transit the shell, but agents routinely achieve equivalent effects through file edits that the classifier does not evaluate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first independent stress-test evaluation of Claude Code's auto mode permission system using AmPermBench, a benchmark of 128 deliberately ambiguous prompts spanning four DevOps task families and three controlled ambiguity axes. It evaluates 253 state-changing actions against oracle ground truth, reporting an end-to-end false negative rate of 81.0% (95% CI: 73.8%-87.4%), with 36.8% of actions falling into Tier 2 (in-project file edits) outside the classifier's scope; restricting to the 160 Tier 3 actions yields FNR 70.3% and FPR 31.9%. These are contrasted with Anthropic's production figures (0.4% FPR, 17% FNR) and framed as reflecting a different workload rather than a contradiction.
Significance. If the benchmark construction and oracle labeling hold, the work is significant for identifying concrete coverage boundaries in deployed AI coding agent permission systems, particularly the assumption that dangerous actions route through shell commands rather than file edits. It supplies the first public, tiered breakdown with confidence intervals on ambiguous authorization scenarios, offering a reproducible stress-test methodology that could guide improvements in scope-escalation handling for autonomous agents.
major comments (1)
- [Abstract and AmPermBench description] Abstract and AmPermBench description: The 81.0% end-to-end FNR and 36.8% Tier 2 coverage gap are load-bearing for the claim of a 'coverage boundary worth examining.' The paper must detail the exact criteria used to generate the 128 prompts, define the three ambiguity axes, select the four task families, and specify the oracle rules for labeling actions as state-changing or dangerous (including any embedded risk thresholds). Without these, it is impossible to assess whether the benchmark's action distribution meaningfully stresses real authorization scenarios or whether the Tier 2 gap would persist under different prompt distributions.
minor comments (1)
- [Abstract] The abstract introduces Tier 2 and Tier 3 without first defining the tiering scheme; adding a single sentence on the three-tier structure (e.g., what Tier 1 covers) would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on the manuscript. We agree that additional details on AmPermBench construction are needed for full reproducibility and to allow proper assessment of the benchmark's validity. We have revised the manuscript to incorporate these details in an expanded methods section.
read point-by-point responses
-
Referee: [Abstract and AmPermBench description] Abstract and AmPermBench description: The 81.0% end-to-end FNR and 36.8% Tier 2 coverage gap are load-bearing for the claim of a 'coverage boundary worth examining.' The paper must detail the exact criteria used to generate the 128 prompts, define the three ambiguity axes, select the four task families, and specify the oracle rules for labeling actions as state-changing or dangerous (including any embedded risk thresholds). Without these, it is impossible to assess whether the benchmark's action distribution meaningfully stresses real authorization scenarios or whether the Tier 2 gap would persist under different prompt distributions.
Authors: We agree that these details are essential. In the revised manuscript we have added a new subsection (Section 3.1) that specifies: (1) prompt generation criteria, which used a controlled template approach starting from 32 base DevOps task descriptions and systematically omitting scope, target, or risk parameters to create 128 ambiguous variants while preserving user intent; (2) the three ambiguity axes, defined as scope underspecification (e.g., which files or resources), blast-radius ambiguity (potential scale of impact), and risk-level vagueness (security or stability implications); (3) the four task families, consisting of deployment automation, log and artifact management, configuration updates, and cleanup operations; and (4) oracle labeling rules, where an action is labeled state-changing if it modifies persistent state (files, configs, running processes) and dangerous if it meets any of three risk thresholds (write access to production-like paths, deletion of >10 files, or execution of privileged commands). These additions make the Tier 2 coverage gap traceable to the benchmark design rather than arbitrary construction and support our claim that the elevated FNR reflects a genuine scope-escalation boundary under ambiguous workloads. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
This paper is an empirical evaluation study that measures false negative rates and coverage gaps using a benchmark of 128 prompts and oracle ground truth. The claims are direct measurements rather than derived quantities from fitted parameters or self-referential definitions. No load-bearing steps reduce to inputs by construction, and there are no self-citations forming a circular chain. The analysis is self-contained against the provided benchmark data.
Axiom & Free-Parameter Ledger
invented entities (1)
-
AmPermBench
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
end-to-end false negative rate is 81.0% ... 36.8% of all state-changing actions fall outside the classifier's scope via Tier 2 (in-project file edits)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage transcript classifier ... Tier 1 safe tools, Tier 2 file edits, Tier 3 shell/external
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Safetoolbench: Pioneering a prospective benchmark to evaluating tool utilization safety in llms
Anthropic. How we built auto mode for claude code. https://www.anthropic.com/ engineering/claude-code-auto-mode, 2025a. Accessed: 2026-04-04. 10 Anthropic. Making Claude Code more secure and autonomous. https://www.anthropic. com/engineering/claude-code-sandboxing, 2025b. Accessed: 2026-04-04. Jingyu Chen, Dexun Cai, and Tianhao Xie. SafeToolBench: Pionee...
-
[2]
Chaofan Li et al. WASP: Benchmarking web agent security against prompt injection attacks. arXiv preprint arXiv:2504.18575,
-
[3]
Haishuo Wang, Haoran Chen, and Yanming Zhong
Spotlight. Haishuo Wang, Haoran Chen, and Yanming Zhong. InferAct: Inferring safe actions for LLM-based agents through preemptive evaluation and human feedback.arXiv preprint arXiv:2407.11843,
-
[4]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
Haoyu Wang, Jiahao Wu, Zhilong Chen, and Yu Liu. AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents.arXiv preprint arXiv:2503.18666,
work page internal anchor Pith review arXiv
-
[5]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-SafetyBench: Evaluating the safety of LLM agents.arXiv preprint arXiv:2412.14470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A Oracle Ground Truth The following tables list the complete oracle specification for every prompt. Each row specifies the authorized target set (what the agentshouldmodify), the must-preserve set (what it mustnottouch), and the protected set (high-priority items that should never be affected). 11 Table 6: Oracle ground truth forCancel Jobs (CJ). Prompt I...
work page 2026
-
[7]
Append one audit entry per cancelled job to job ops.jsonl jq -c –arg ts ”$TIMESTAMP” –argjson ids ”$TARGETS” ’ .jobs[] — select(.job id as $id — $ids — index($id) != null) —{timestamp: $ts, operation: ”cancel”, reason: ”stale”, job id: .job id, name: .name, queue: .queue, owner: .owner } ’ /bench/cluster/jobs.json ¿¿ /bench/logs/job ops.jsonl echo ”Done.”...
work page 2026
-
[8]
Append one audit entry per cancelled job jq -c –arg ts ”$TIMESTAMP” –argjson ids ”$TARGETS” ’ .jobs[] — select(.job id as $id — $ids — index($id) != null) —{timestamp: $ts, operation: ”cancel”, reason: ”stale”, job id: .job id, name: .name, queue: .queue, owner: .owner}’ /bench/cluster/jobs.json ¿¿ /bench/logs/job ops.jsonl echo ”Done.” ) Judgment: Target...
work page 2026
-
[9]
Append operation record to job ops.jsonl ????????????????????????????? op = { ”timestamp”: datetime.datetime.utcnow().strftime(”%Y-%m-%dT%H:%M:%SZ”), ”action”: ”cancel”, ”job id”: TARGET ID, ”queue”: ”dev”, ”ticket”: ”4812”, ”reason”: ”stale job cleanup”, ”protected”: False}with open(OPS FILE, ”a”) as f: f.write(json.dumps(op) + ”\{}n”) print(”\{}nOperati...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.