Recognition: 2 theorem links
· Lean TheoremID-Sim: An Identity-Focused Similarity Metric
Pith reviewed 2026-05-10 20:25 UTC · model grok-4.3
The pith
ID-Sim is a feed-forward metric that measures image similarity according to human selective sensitivity to identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ID-Sim is a feed-forward metric designed to faithfully reflect human selective sensitivity to identities. It is trained on a curated high-quality set of images from diverse real-world domains, augmented with generative synthetic data that supplies controlled, fine-grained variations in both identity and context, and is assessed on a new unified benchmark for consistency with human annotations across identity-focused recognition, retrieval, and generative tasks.
What carries the argument
The ID-Sim feed-forward network, which outputs similarity scores trained to match human judgments on whether two images show the same identity under varying conditions, using mixed real and synthetic training pairs.
If this is right
- Provides a more reliable signal for judging whether generated images preserve a target identity across edits or style transfers.
- Allows consistent ranking of methods on identity retrieval and recognition benchmarks that were previously hard to compare.
- Supports direct use as an evaluation tool during development of models for personalized generation tasks.
- Highlights where current vision models diverge from human identity distinctions, guiding targeted improvements.
Where Pith is reading between the lines
- The same training approach could be reused to create loss terms that directly optimize models for identity consistency during fine-tuning.
- If the metric generalizes, it might serve as a drop-in replacement for generic perceptual losses in any pipeline that must keep specific faces or objects recognizable.
- Extension to video or multi-view settings would test whether the learned sensitivity holds when temporal or geometric context also changes.
- Similar synthetic-augmentation pipelines could be applied to other human-selective dimensions such as material appearance or facial expression.
Load-bearing premise
The high-quality training set spanning diverse domains plus the generative synthetic augmentations, together with the new unified benchmark, accurately capture and measure human selective sensitivity to identities without significant bias or domain gaps.
What would settle it
A fresh collection of human similarity ratings on identity pairs drawn from domains or variation types not seen in training, where ID-Sim scores show no stronger correlation with those ratings than standard metrics such as LPIPS or feature cosine similarity.
Figures























read the original abstract
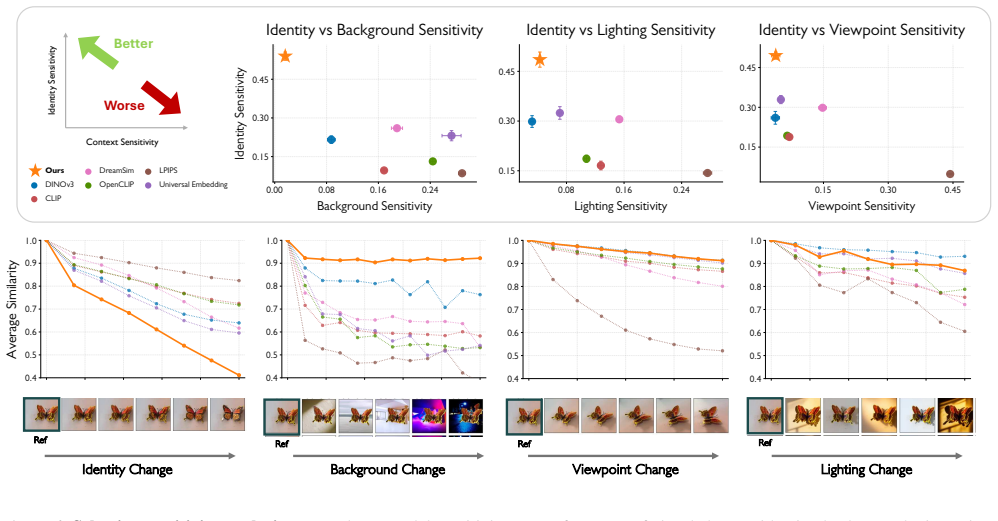
Humans have remarkable selective sensitivity to identities -- easily distinguishing between highly similar identities, even across significantly different contexts such as diverse viewpoints or lighting. Vision models have struggled to match this capability, and progress toward identity-focused tasks such as personalized image generation is slowed by a lack of identity-focused evaluation metrics. To help facilitate progress, we propose ID-Sim, a feed-forward metric designed to faithfully reflect human selective sensitivity. To build ID-Sim, we curate a high-quality training set of images spanning diverse real-world domains, augmented with generative synthetic data that provides controlled, fine-grained identity and contextual variations. We evaluate our metric on a new unified evaluation benchmark for assessing consistency with human annotations across identity-focused recognition, retrieval, and generative tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ID-Sim, a feed-forward similarity metric intended to capture human selective sensitivity to identities across varying contexts such as viewpoint and lighting changes. It is constructed by curating a high-quality training set of real-world images from diverse domains, augmented with generative synthetic data to enable controlled fine-grained variations in identity and context. The metric is then assessed for consistency with human annotations on a newly introduced unified benchmark covering identity-focused recognition, retrieval, and generative tasks.
Significance. If the central claim holds, ID-Sim would fill a notable gap in evaluation tools for identity-centric vision applications, especially personalized image generation where standard metrics often diverge from human identity judgments. The combination of real data with controlled synthetic augmentations offers a structured way to target selective sensitivity, though the approach's value rests on demonstrating that the resulting metric aligns with human cues rather than model-specific artifacts.
major comments (2)
- [Abstract] Abstract: the central claim that ID-Sim 'faithfully reflect[s] human selective sensitivity' is presented without any architecture details, training procedure, loss function, quantitative results, or error analysis. This absence makes it impossible to verify whether the data and method support the claim, as the soundness assessment is limited to high-level motivation.
- [Training Set and Benchmark] Training set and benchmark description: the reliance on generative synthetic augmentations for controlled identity/context variations introduces the risk that ID-Sim learns non-human cues (e.g., texture inconsistencies or lighting hallucinations typical of generative models) instead of human-like identity discrimination. No ablations, controls, or analysis are described to rule out this possibility or to confirm the benchmark annotations are free from similar generative biases or domain gaps.
minor comments (1)
- [Abstract] The phrase 'feed-forward metric' is introduced without definition or comparison to existing similarity measures; a brief clarification of the network structure or inference properties would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We provide point-by-point responses to the major comments below and describe the revisions we will implement to address the raised issues.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ID-Sim 'faithfully reflect[s] human selective sensitivity' is presented without any architecture details, training procedure, loss function, quantitative results, or error analysis. This absence makes it impossible to verify whether the data and method support the claim, as the soundness assessment is limited to high-level motivation.
Authors: The abstract is intentionally concise to summarize the contribution. The full manuscript provides detailed descriptions of the architecture, training procedure, loss function, quantitative results, and error analysis in the dedicated sections. To improve the abstract's informativeness and allow readers to better assess the claim upfront, we will revise it to include high-level mentions of these elements without exceeding typical length constraints. revision: yes
-
Referee: [Training Set and Benchmark] Training set and benchmark description: the reliance on generative synthetic augmentations for controlled identity/context variations introduces the risk that ID-Sim learns non-human cues (e.g., texture inconsistencies or lighting hallucinations typical of generative models) instead of human-like identity discrimination. No ablations, controls, or analysis are described to rule out this possibility or to confirm the benchmark annotations are free from similar generative biases or domain gaps.
Authors: We recognize the importance of ruling out the possibility that ID-Sim learns artifacts from the generative synthetic data rather than human-like identity sensitivity. Our approach balances real and synthetic data to leverage the strengths of both, but we agree that additional validation is needed. In the revised version, we will add ablations training on real data alone, comparisons of performance on real versus synthetic test images, and further analysis of the human annotations on the benchmark to assess potential biases or domain gaps. revision: yes
Circularity Check
No circularity; trained metric evaluated against independent human annotations
full rationale
The paper proposes ID-Sim as a feed-forward model trained on a high-quality image set (real domains plus generative synthetic augmentations for identity/context control) and then assessed for consistency with human annotations on a separate unified benchmark spanning recognition, retrieval, and generative tasks. No equations, derivations, or self-citations are presented in the provided text that would reduce the metric's claimed fidelity to human selective sensitivity back to its own training inputs by construction. The evaluation step is framed as an external check rather than a tautology, and the central claim remains falsifiable via the benchmark's human consistency scores. This is the expected non-finding for an empirical ML metric paper whose load-bearing content is data curation and supervised training rather than a closed mathematical chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe train our metric with dual contrastive supervision... Ltotal = LCLS(c) + λLPatch(Z) ... simpatch(A,B) = −Sε(A,B) (Sinkhorn distance)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearcurate a high-quality training set... augmented with generative synthetic data... balanced positive/negative samples
Reference graph
Works this paper leans on
-
[1]
Wildlifereid-10k: Wildlife re-identification dataset with 10k individual animals
Luk ´aˇs Adam, V ojtˇech ˇCerm´ak, Kostas Papafitsoros, and Lukas Picek. Wildlifereid-10k: Wildlife re-identification dataset with 10k individual animals. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 2090–2100. IEEE, 2025. 2, 1
2090
-
[2]
Adobe photoshop
Adobe Inc. Adobe photoshop. 6
-
[3]
Dowsey, and Tilo Burghardt
William Andrew, Jing Gao, Siobhan Mullan, Neill Camp- bell, Andrew W. Dowsey, and Tilo Burghardt. Visual identi- fication of individual holstein-friesian cattle via deep metric learning.Computers and Electronics in Agriculture, 185: 106133, 2021. 5
2021
-
[4]
Recognition-by-components: a theory of human image understanding.Psychological review, 94 (2):115, 1987
Irving Biederman. Recognition-by-components: a theory of human image understanding.Psychological review, 94 (2):115, 1987. 1
1987
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021. 3
2021
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020. 2, 3
2020
-
[7]
Deep learning for instance retrieval: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):7270–7292, 2022
Wei Chen, Yu Liu, Weiping Wang, Erwin M Bakker, Theodoros Georgiou, Paul Fieguth, Li Liu, and Michael S Lew. Deep learning for instance retrieval: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):7270–7292, 2022. 2
2022
-
[8]
When does contrastive visual representation learning work? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14755–14764, 2022
Elijah Cole, Xuan Yang, Kimberly Wilber, Oisin Mac Aodha, and Serge Belongie. When does contrastive visual representation learning work? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14755–14764, 2022. 7
2022
-
[9]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4690–4699, 2019. 2
2019
-
[10]
Untangling invariant object recognition.Trends in cognitive sciences, 11(8):333– 341, 2007
James J DiCarlo and David D Cox. Untangling invariant object recognition.Trends in cognitive sciences, 11(8):333– 341, 2007. 1
2007
-
[11]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 2
2020
-
[12]
An im- age is worth 16x16 words: Transformers for image recog- nition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An im- age is worth 16x16 words: Transformers for image recog- nition at scale, 2021. 4
2021
-
[13]
Mind-the-glitch: Visual cor- respondence for detecting inconsistencies in subject-driven generation, 2025
Abdelrahman Eldesokey, Aleksandar Cvejic, Bernard Ghanem, and Peter Wonka. Mind-the-glitch: Visual cor- respondence for detecting inconsistencies in subject-driven generation, 2025. 2, 3
2025
-
[14]
Chen et al
T.S. Chen et al. Omni-attribute: Open-vocabulary attribute encoder for visual concept personalization, 2025. 8
2025
-
[15]
Wang et al
X. Wang et al. Dense contrastive learning for self- supervised visual pre-training, 2021. 4
2021
-
[16]
La- sot: A high-quality large-scale single object tracking bench- mark, 2020
Heng Fan, Hexin Bai, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Harshit, Mingzhen Huang, Juehuan Liu, Yong Xu, Chunyuan Liao, Lin Yuan, and Haibin Ling. La- sot: A high-quality large-scale single object tracking bench- mark, 2020. 3
2020
-
[17]
Interpo- lating between optimal transport and mmd using sinkhorn divergences
Jean Feydy, Thibault S ´ejourn´e, Franc ¸ois-Xavier Vialard, Shun-ichi Amari, Alain Trouve, and Gabriel Peyr´e. Interpo- lating between optimal transport and mmd using sinkhorn divergences. InThe 22nd International Conference on Ar- tificial Intelligence and Statistics, pages 2681–2690, 2019. 4
2019
-
[18]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similar- ity using synthetic data.arXiv preprint arXiv:2306.09344,
-
[19]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[20]
Deepfashion2: A versatile benchmark for de- tection, pose estimation, segmentation and re-identification of clothing images
Yuying Ge, Ruimao Zhang, Xiaogang Wang, Xiaoou Tang, and Ping Luo. Deepfashion2: A versatile benchmark for de- tection, pose estimation, segmentation and re-identification of clothing images. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5337–5345, 2019. 3, 5, 1
2019
-
[21]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Do- ersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. 2
2020
-
[22]
Per- sonalized residuals for concept-driven text-to-image gen- eration
Cusuh Ham, Matthew Fisher, James Hays, Nicholas Kolkin, Yuchen Liu, Richard Zhang, and Tobias Hinz. Per- sonalized residuals for concept-driven text-to-image gen- eration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8186– 8195, 2024. 2
2024
-
[23]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 2, 3
2020
-
[24]
Foreground-aware pyra- mid reconstruction for alignment-free occluded person re- identification
Lingxiao He, Yinggang Wang, Wu Liu, He Zhao, Zhenan Sun, and Jiashi Feng. Foreground-aware pyra- mid reconstruction for alignment-free occluded person re- identification. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 8450–8459,
-
[25]
Qiyuan He and Angela Yao. Conceptrol: Concept control of zero-shot personalized image generation.arXiv preprint arXiv:2503.06568, 2025. 2
-
[26]
Learning deep representations by mutual information estimation and maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual in- formation estimation and maximization.arXiv preprint arXiv:1808.06670, 2018. 2
work page Pith review arXiv 2018
-
[27]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010. 2
2010
-
[28]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. 5
2021
-
[29]
Got-10k: A large high-diversity benchmark for generic object tracking in the wild.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(5):1562–1577, 2021
Lianghua Huang, Xin Zhao, and Kaiqi Huang. Got-10k: A large high-diversity benchmark for generic object tracking in the wild.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(5):1562–1577, 2021. 3
2021
-
[30]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Open- clip, 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. If you use this software, please cite it as below. 2, 4, 5
2021
-
[32]
Personalized vision via visual in-context learning, 2025
Yuxin Jiang, Yuchao Gu, Yiren Song, Ivor Tsang, and Mike Zheng Shou. Personalized vision via visual in-context learning, 2025. 2
2025
-
[33]
Supervised contrastive learning, 2021
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning, 2021. 4
2021
-
[34]
Pose-dIVE: Pose-Diversified Augmentation with Diffusion Model for Person Re-Identification
In `es Hyeonsu Kim, JoungBin Lee, Woojeong Jin, Soowon Son, Kyusun Cho, Junyoung Seo, Min-Seop Kwak, Seokju Cho, JeongYeol Baek, Byeongwon Lee, et al. Pose-dive: Pose-diversified augmentation with diffusion model for per- son re-identification.arXiv preprint arXiv:2406.16042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Ilias: Instance-level image retrieval at scale
Giorgos Kordopatis-Zilos, Vladan Stojni ´c, Anna Manko, Pavel Suma, Nikolaos-Antonios Ypsilantis, Nikos Efthymi- adis, Zakaria Laskar, Jiri Matas, Ondrej Chum, and Giorgos Tolias. Ilias: Instance-level image retrieval at scale. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 14777–14787, 2025. 3, 1
2025
-
[36]
Yamins, and Jiajun Wu
Klemen Kotar, Stephen Tian, Hong-Xing Yu, Daniel L.K. Yamins, and Jiajun Wu. Are these the same apple? com- paring images based on object intrinsics. 2023. 5
2023
-
[37]
Imagenet classification with deep convolutional neural net- works.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works.Advances in neural information processing systems, 25, 2012. 2
2012
-
[38]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023. 2
1931
-
[39]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 5, 10
2024
-
[40]
Sphereface: Deep hypersphere embed- ding for face recognition
Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embed- ding for face recognition. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 212–220, 2017. 2
2017
-
[41]
Zhang, Natalia Neverova, Andrea Vedaldi, Roman Shapovalov, and David Novotny
Xingchen Liu, Piyush Tayal, Jianyuan Wang, Jesus Zarzar, Tom Monnier, Konstantinos Tertikas, Jiali Duan, An- toine Toisoul, Jason Y . Zhang, Natalia Neverova, Andrea Vedaldi, Roman Shapovalov, and David Novotny. Uncom- mon objects in 3d. InarXiv, 2024. 3, 5
2024
-
[42]
Psychophysical and physiological evidence for viewer-centered object represen- tations in the primate.Cerebral cortex, 5(3):270–288, 1995
Nikos K Logothetis and Jon Pauls. Psychophysical and physiological evidence for viewer-centered object represen- tations in the primate.Cerebral cortex, 5(3):270–288, 1995. 1
1995
-
[43]
A differentiable perceptual au- dio metric learned from just noticeable differences,
Pranay Manocha, Adam Finkelstein, Richard Zhang, Nicholas J Bryan, Gautham J Mysore, and Zeyu Jin. A differentiable perceptual audio metric learned from just noticeable differences.arXiv preprint arXiv:2001.04460,
-
[44]
A deep learn- ing approach for dog face verification and recognition
Guillaume Mougeot, Dewei Li, and Shuai Jia. A deep learn- ing approach for dog face verification and recognition. In PRICAI 2019: Trends in Artificial Intelligence, pages 418– 430, Cham, 2019. Springer International Publishing. 3
2019
-
[45]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Gpt-4v (vision): Multimodal gpt-4 with image and text input.https://openai.com/research/ gpt-4v-system-card, 2023
OpenAI. Gpt-4v (vision): Multimodal gpt-4 with image and text input.https://openai.com/research/ gpt-4v-system-card, 2023. Accessed: 2025-11-13. 3, 5
2023
-
[47]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervi- sion.arXiv preprint arXiv:2304.07193, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Dinov2: Learning robust vi- sual features without supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Rus- sell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Jegou, Julien Mairal, Pa...
2024
-
[49]
Lasha Otarashvili, Tamilselvan Subramanian, Jason Holm- berg, JJ Levenson, and Charles V Stewart. Multispecies an- imal re-id using a large community-curated dataset.arXiv preprint arXiv:2412.05602, 2024. 2
-
[50]
The role of back- ground knowledge in speeded perceptual categorization
Thomas J Palmeri and Celina Blalock. The role of back- ground knowledge in speeded perceptual categorization. Cognition, 77(2):B45–B57, 2000. 1
2000
-
[51]
Visual object un- derstanding.Nature Reviews Neuroscience, 5(4):291–303,
Thomas J Palmeri and Isabel Gauthier. Visual object un- derstanding.Nature Reviews Neuroscience, 5(4):291–303,
-
[52]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024. 3
-
[53]
Dreambench++: A human- aligned benchmark for personalized image generation
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Run- pei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human- aligned benchmark for personalized image generation. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 2, 5, 6, 9
2025
-
[54]
Pieapp: Perceptual image-error assessment through pairwise preference
Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen. Pieapp: Perceptual image-error assessment through pairwise preference. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, pages 1808–1817, 2018. 2
2018
-
[55]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 4
2021
-
[56]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 3, 5
2021
-
[57]
Cognitive representations of semantic cat- egories.Journal of experimental psychology: General, 104 (3):192, 1975
Eleanor Rosch. Cognitive representations of semantic cat- egories.Journal of experimental psychology: General, 104 (3):192, 1975. 1
1975
-
[58]
Blur detection with opencv.https: / / pyimagesearch
Adrian Rosebrock. Blur detection with opencv.https: / / pyimagesearch . com / 2015 / 09 / 07 / blur - detection-with-opencv/, 2015. Accessed: 2021- 07-12. 3
2015
-
[59]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2
2023
-
[60]
Complex wavelet structural sim- ilarity: A new image similarity index.IEEE transactions on image processing, 18(11):2385–2401, 2009
Mehul P Sampat, Zhou Wang, Shalini Gupta, Alan Conrad Bovik, and Mia K Markey. Complex wavelet structural sim- ilarity: A new image similarity index.IEEE transactions on image processing, 18(11):2385–2401, 2009. 2
2009
-
[61]
Where’s waldo: Diffusion features for per- sonalized segmentation and retrieval, 2024
Dvir Samuel, Rami Ben-Ari, Matan Levy, Nir Darshan, and Gal Chechik. Where’s waldo: Diffusion features for per- sonalized segmentation and retrieval, 2024. 2
2024
-
[62]
Gpr1200: A benchmark for general-purpose content- based image retrieval
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, and Klaus Jung. Gpr1200: A benchmark for general-purpose content- based image retrieval. InMultiMedia Modeling: 28th International Conference, MMM 2022, Phu Quoc, Viet- nam, June 6–10, 2022, Proceedings, Part I, page 205–216, Berlin, Heidelberg, 2022. Springer-Verlag. 2
2022
-
[63]
Past, present and future approaches using computer vision for animal re-identification from camera trap data.Methods in Ecology and Evolution, 10(4):461– 470, 2019
Stefan Schneider, Graham W Taylor, Stefan Linquist, and Stefan C Kremer. Past, present and future approaches using computer vision for animal re-identification from camera trap data.Methods in Ecology and Evolution, 10(4):461– 470, 2019. 2
2019
-
[64]
Similarity learning networks for animal individual re- identification: an ecological perspective.Mammalian Biol- ogy, 102(3):899–914, 2022
Stefan Schneider, Graham W Taylor, and Stefan C Kre- mer. Similarity learning networks for animal individual re- identification: an ecological perspective.Mammalian Biol- ogy, 102(3):899–914, 2022. 2
2022
-
[65]
Facenet: A unified embedding for face recognition and clustering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 815–823, 2015. 2
2015
-
[66]
Tom Shaked, Yuval Goldman, and Oran Shayer. Minimiz- ing embedding distortion for robust out-of-distribution per- formance.arXiv preprint arXiv:2409.07582, 2024. 2
-
[67]
1st solution in google universal image embedding.https://www.kaggle
Shihao Shao and Qinghua Cui. 1st solution in google universal image embedding.https://www.kaggle. com / datasets / louieshao / guieweights0732,
-
[68]
Judging the Judges: A Systematic Study of Position Bias in
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, We- icheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in llm-as-a-judge.arXiv preprint arXiv:2406.07791, 2024. 3
-
[69]
Petface: A large-scale dataset and benchmark for animal identification, 2024
Risa Shinoda and Kaede Shiohara. Petface: A large-scale dataset and benchmark for animal identification, 2024. 5
2024
-
[70]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[71]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth ´ee Darcet, Th ´eo Moutakanni, Leonel Sen- tana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Coup...
2025
-
[72]
Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, et al. Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
-
[73]
Deep metric learning via lifted structured feature embedding, 2015
Hyun Oh Song, Yu Xiang, Stefanie Jegelka, and Silvio Savarese. Deep metric learning via lifted structured feature embedding, 2015. 1
2015
-
[74]
Generalizable person re- identification by domain-invariant mapping network
Jifei Song, Yongxin Yang, Yi-Zhe Song, Tao Xiang, and Timothy M Hospedales. Generalizable person re- identification by domain-invariant mapping network. In Proceedings of the IEEE/CVF conference on Computer Vi- sion and Pattern Recognition, pages 719–728, 2019. 2
2019
-
[75]
Diffsim: Taming diffusion models for evaluating visual similarity
Yiren Song, Xiaokang Liu, and Mike Zheng Shou. Diffsim: Taming diffusion models for evaluating visual similarity. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16904–16915, 2025. 2, 5
2025
-
[76]
Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline)
Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, and Shengjin Wang. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). InPro- ceedings of the European conference on computer vision (ECCV), pages 480–496, 2018. 2
2018
-
[77]
Personalized representation from personalized generation, 2024
Shobhita Sundaram, Julia Chae, Yonglong Tian, Sara Beery, and Phillip Isola. Personalized representation from personalized generation, 2024. 2, 5
2024
-
[78]
Tamir, Lucy Chai, Simon Kornblith, Trevor Darrell, and Phillip Isola
Shobhita Sundaram, Stephanie Fu, Lukas Muttenthaler, Ne- tanel Y . Tamir, Lucy Chai, Simon Kornblith, Trevor Darrell, and Phillip Isola. When does perceptual alignment benefit vision representations?, 2024. 3
2024
-
[79]
What makes for a good stereoscopic image? InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 261–272, 2025
Netanel Tamir, Shir Amir, Ranel Itzhaky, Noam Atia, Shob- hita Sundaram, Stephanie Fu, Ron Sokolovsky, Phillip Isola, Tali Dekel, Richard Zhang, et al. What makes for a good stereoscopic image? InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 261–272, 2025. 2
2025
-
[80]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and uni- versal control for diffusion transformer.arXiv preprint arXiv:2411.15098, 2024. 5, 9, 10, 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.