Recognition: no theorem link
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
Pith reviewed 2026-05-10 18:53 UTC · model grok-4.3
The pith
A memory-centric system trains 120 billion parameter language models at full precision on a single GPU by streaming parameters from CPU memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By storing parameters and optimizer states in host memory and treating the GPU solely as a transient compute engine, the system streams parameters in for each layer and computes gradients out, minimizing persistent device state. A pipelined double-buffered execution engine overlaps parameter prefetching, computation, and gradient offloading across multiple streams to hide transfer costs, while stateless layer templates bind weights dynamically upon arrival to remove persistent autograd graph metadata. This combination enables reliable full-precision training of models up to 120 billion parameters on a single GPU equipped with 1.5 terabytes of host memory.
What carries the argument
Pipelined double-buffered execution engine that overlaps prefetching, computation, and offloading, paired with stateless layer templates that bind weights dynamically as they arrive.
If this is right
- Training runs become possible for models up to 120 billion parameters using only one GPU and large host memory.
- Throughput for 14 billion parameter models rises to nearly twice that of standard CPU offloading techniques.
- Models with 7 billion parameters can train using context lengths of 512 thousand tokens on a single GPU.
- Persistent storage of model data on the GPU is no longer required, freeing device memory for larger batches or longer sequences.
Where Pith is reading between the lines
- Researchers without access to large GPU clusters could experiment with much bigger models using this streaming approach.
- Advances in faster CPU-GPU links would likely push the maximum trainable size even higher under the same design.
- Training frameworks might shift toward treating GPUs as temporary processors rather than permanent holders of model state.
- The method could support deployment of large-model training in settings where only one high-memory GPU is available.
Load-bearing premise
The CPU-GPU connection must supply enough sustained bandwidth for the pipelined engine to keep computation running without pauses or stability problems when models reach 100 billion parameters.
What would settle it
A complete training run of a 120 billion parameter model on one GPU with 1.5 terabytes of host memory that finishes without numerical instability or unexpected slowdowns would confirm the central claim.
Figures






read the original abstract
We present MegaTrain, a memory-centric system that efficiently trains 100B+ parameter large language models at full precision on a single GPU. Unlike traditional GPU-centric systems, MegaTrain stores parameters and optimizer states in host memory (CPU memory) and treats GPUs as transient compute engines. For each layer, we stream parameters in and compute gradients out, minimizing persistent device state. To battle the CPU-GPU bandwidth bottleneck, we adopt two key optimizations. 1) We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution. 2) We replace persistent autograd graphs with stateless layer templates, binding weights dynamically as they stream in, eliminating persistent graph metadata while providing flexibility in scheduling. On a single H200 GPU with 1.5TB host memory, MegaTrain reliably trains models up to 120B parameters. It also achieves 1.84$\times$ the training throughput of DeepSpeed ZeRO-3 with CPU offloading when training 14B models. MegaTrain also enables 7B model training with 512k token context on a single GH200.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MegaTrain, a memory-centric system for full-precision training of 100B+ parameter LLMs on a single GPU. Parameters and optimizer states reside in host memory and are streamed to the GPU per layer; a pipelined double-buffered engine overlaps prefetching, forward/backward passes, and gradient offloading across CUDA streams, while stateless layer templates replace persistent autograd graphs with dynamic weight binding. On an H200 with 1.5 TB host memory the system is claimed to train models up to 120 B parameters and to deliver 1.84× the throughput of DeepSpeed ZeRO-3 (with CPU offloading) for 14 B models; an additional result is 7 B training at 512 k context on GH200.
Significance. If the overlap and stability claims hold at 100 B+ scale, the work would meaningfully lower the hardware barrier for full-precision training of very large models, allowing single-GPU setups with large host memory to replace multi-GPU clusters for certain workloads. The concrete scale (120 B) and throughput (1.84×) numbers, together with the two concrete optimizations, constitute a practical systems contribution that could influence future memory-centric training frameworks.
major comments (3)
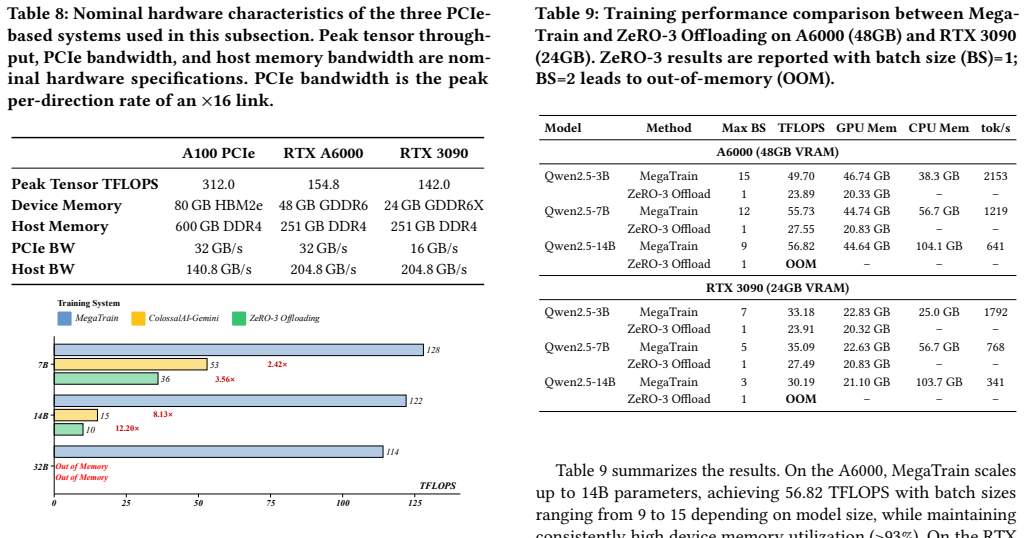
- [Results] Results section: the 1.84× throughput figure is reported only for 14 B models; the headline claim of reliable 120 B training provides no corresponding throughput numbers, per-layer timing breakdown, or measured overlap efficiency, leaving the central scaling assumption (full hiding of several-GB layer transfers behind compute) unverified.
- [System Design] System Design / Execution Engine: the pipelined double-buffered engine and stateless templates are described at a high level, yet no quantitative analysis or micro-benchmark is given for residual host-memory latency, stream-synchronization overhead, or autograd-binding cost when layer sizes reach several GB at 120 B scale; these costs directly determine whether the overlap assumption holds.
- [Evaluation] Evaluation: the manuscript states concrete throughput and scale numbers without error bars, ablation studies, number of runs, or a detailed experimental protocol (model architecture, optimizer settings, exact host-memory bandwidth measurements), so the reliability claim for 120 B models rests on unverified assertions.
minor comments (2)
- [Abstract] The abstract and introduction use the phrase 'reliably trains' without defining a reliability metric or reporting any stability or convergence statistics.
- [System Design] Notation for the double-buffered engine (streams, buffers, binding) is introduced without a small diagram or pseudocode, making the overlap logic harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional evidence and clarity would strengthen the paper. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Results] Results section: the 1.84× throughput figure is reported only for 14 B models; the headline claim of reliable 120 B training provides no corresponding throughput numbers, per-layer timing breakdown, or measured overlap efficiency, leaving the central scaling assumption (full hiding of several-GB layer transfers behind compute) unverified.
Authors: We agree that throughput numbers are provided only for the 14B model to enable direct comparison against DeepSpeed ZeRO-3. The 120B experiments were designed primarily to establish feasibility of full-precision training at that scale on a single GPU without OOM errors, which was verified by successfully executing multiple training steps. In the revision we will add per-layer timing breakdowns and overlap-efficiency measurements for the 14B case, together with a scaling analysis that explains how the double-buffered pipelining continues to hide transfers as layer sizes grow. Full end-to-end throughput figures for 120B were not collected because of the prohibitive wall-clock time required for such runs. revision: partial
-
Referee: [System Design] System Design / Execution Engine: the pipelined double-buffered engine and stateless templates are described at a high level, yet no quantitative analysis or micro-benchmark is given for residual host-memory latency, stream-synchronization overhead, or autograd-binding cost when layer sizes reach several GB at 120 B scale; these costs directly determine whether the overlap assumption holds.
Authors: The system-design section currently emphasizes the architectural approach. We will add a new appendix containing micro-benchmark results that quantify host-memory transfer latency, CUDA-stream synchronization cost, and dynamic-binding overhead for layers of several GB. These measurements were obtained on the same H200 platform and demonstrate that the pipelined execution continues to overlap communication with computation at the layer sizes encountered in 120B models. revision: yes
-
Referee: [Evaluation] Evaluation: the manuscript states concrete throughput and scale numbers without error bars, ablation studies, number of runs, or a detailed experimental protocol (model architecture, optimizer settings, exact host-memory bandwidth measurements), so the reliability claim for 120 B models rests on unverified assertions.
Authors: We will expand the evaluation section with a complete experimental protocol that specifies model architectures (exact hidden sizes, number of layers, and attention heads for both 14B and 120B configurations), optimizer hyperparameters (AdamW betas, epsilon, weight decay, and learning-rate schedule), and host-memory bandwidth figures measured with standard CUDA bandwidthTest utilities. Throughput values will be reported with standard deviations and the number of repeated runs (five or more). Ablation studies isolating the double-buffered engine and the stateless-template optimization will also be included. revision: yes
- Full end-to-end throughput and overlap-efficiency numbers for the 120B model are not available, as collecting them would require impractically long runs on the target hardware.
Circularity Check
No circularity: systems implementation grounded in hardware measurements
full rationale
The paper presents a systems engineering contribution for memory-offloaded LLM training. It introduces a pipelined double-buffered engine and stateless layer templates as implementation techniques, but contains no equations, derivations, fitted parameters, or self-referential definitions. All performance claims (e.g., 1.84× throughput on 14B models, reliable 120B training) are stated as direct outcomes of hardware benchmarks rather than reductions to prior results or internal fits. No load-bearing self-citations or uniqueness theorems appear; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CUDA streams and host-device transfers can be overlapped to achieve near-continuous GPU utilization when data movement is the bottleneck.
- domain assumption Stateless layer templates can be bound to streamed weights without altering gradient correctness or introducing numerical instability.
Reference graph
Works this paper leans on
-
[1]
Jiarui Fang and Yang You. 2022. Meet Gemini: The Heterogeneous Memory Manager of Colossal-AI. Colossal-AI documentation. [Online]. Available: https://colossalai.org/docs/advanced_tutorials/meet_gemini
2022
-
[2]
GPUsPerStudent.org. 2025. H100-Equivalent GPUs Per CS Student: Tracking Academic GPU Compute Availability in the United States. Project website. [Online]. Available: https://www.gpusperstudent.org/
2025
-
[3]
Hennessy and David A
John L. Hennessy and David A. Patterson. 2011.Computer Architecture: A Quan- titative Approach(5th ed.). Morgan Kaufmann, San Francisco, CA
2011
-
[4]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Op- timization. International Conference on Learning Representations. [Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Hanyu Lai, Xiao Liu, Junjie Gao, Jiale Cheng, Zehan Qi, Yifan Xu, Shuntian Yao, Dan Zhang, Jinhua Du, Zhenyu Hou, et al. 2025. A survey of post-training scaling in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Stroudsburg,...
2025
-
[6]
Changyue Liao, Mo Sun, Zihan Yang, Jun Xie, Kaiqi Chen, Binhang Yuan, Fei Wu, and Zeke Wang. 2025. Ratel: Optimizing Holistic Data Movement to Fine-Tune 100B Model on a Consumer GPU. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE Press, Los Alamitos, CA, USA, 292–306. doi:10. 1109/ICDE65448.2025.00029
-
[7]
Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory F. Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. 2018. Mixed Precision Training. Inter- national Conference on Learning Representations. [Online]. Available: https://openreview.net/forum?id=r1gs9JgRZ
2018
-
[8]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. InSC20: Inter- national Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, IEEE Press, Los Alamitos, CA, USA, 1–16
2020
-
[9]
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. 2021. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. InProceedings of the international conference for high performance com- puting, networking, storage and analysis. Association for Computing Machinery, New York, NY, USA, 1–14
2021
-
[10]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534. [Online]. Available: https://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Yanfang Ye, Zheyuan Zhang, Tianyi Ma, Zehong Wang, Yiyang Li, Shifu Hou, Weixiang Sun, Kaiwen Shi, Yijun Ma, Wei Song, et al . 2025. LLMs4All: A Re- view of Large Language Models Across Academic Disciplines. arXiv preprint arXiv:2509.19580. [Online]. Available: https://arxiv.org/abs/2509.19580
-
[13]
Manjiang Yu and Priyanka Singh. 2025. Differentially Private Fine-Tuning of Large Language Models: A Survey. InInternational Conference on Advanced Data Mining and Applications. Springer, Springer, Cham, Switzerland, 100–113
2025
- [14]
-
[15]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al . 2023. Py- torch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277. [Online]. Available: https://arxiv.org/abs/2304.11277. A Implementation Details MegaTrain is implemented as a hig...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.