Recognition: 2 theorem links
· Lean TheoremOffline RL for Adaptive Policy Retrieval in Prior Authorization
Pith reviewed 2026-05-10 19:07 UTC · model grok-4.3
The pith
Offline RL policies learn when to stop retrieving policy chunks, matching 92 percent accuracy with up to 47 percent fewer steps than fixed-K baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors model adaptive policy retrieval for prior authorization as a Markov Decision Process in which the agent iteratively selects chunks from a top-K candidate set or terminates to decide, with a reward that balances decision correctness against retrieval cost. On a corpus of 186 policy chunks spanning 10 CMS procedures, Conservative Q-Learning achieves 92 percent decision accuracy through exhaustive retrieval, a 30-point gain over the best fixed-K baseline. Implicit Q-Learning matches the best baseline accuracy using 44 percent fewer retrieval steps and is the only policy with positive episodic return. Transition-level Direct Preference Optimization matches CQL accuracy while using 47
What carries the argument
The Markov Decision Process formulation in which states capture the current retrieval context and query, actions are either selecting one chunk from the top-K candidates or stopping to issue a decision, and the reward function trades off final decision accuracy against a per-step retrieval cost scaled by lambda.
If this is right
- CQL policies perform exhaustive retrieval to reach the highest accuracy.
- IQL policies achieve baseline accuracy with substantially reduced retrieval effort and produce the only positive return.
- DPO policies occupy a selective yet accurate point on the Pareto frontier that dominates both CQL and behavioral cloning.
- Behavioral cloning without advantage weighting or preference signals fails to learn selective stopping behavior.
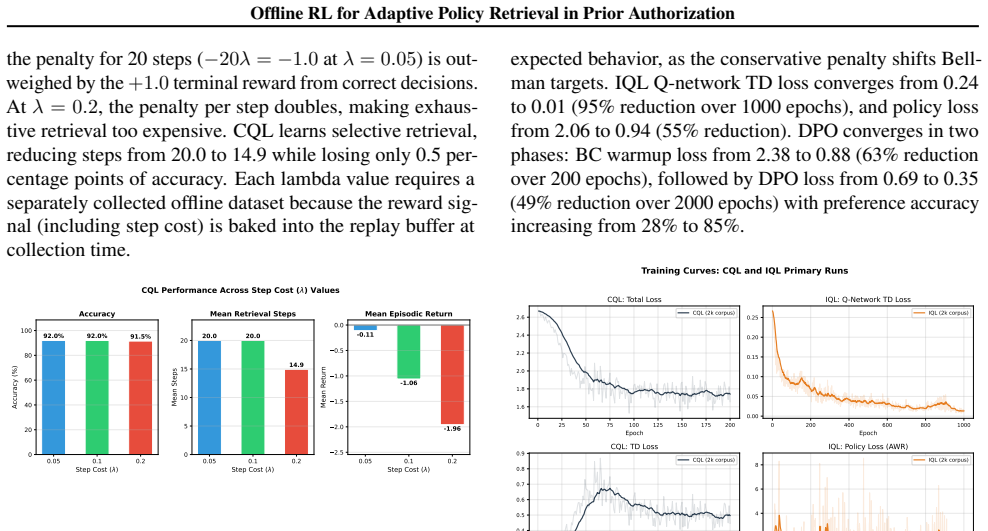
- Raising the step-cost weight lambda to 0.2 causes CQL to shift from exhaustive to selective retrieval.
Where Pith is reading between the lines
- The same MDP-plus-offline-RL approach could be applied to other cost-sensitive retrieval tasks such as legal document review or clinical guideline lookup.
- Deployment on live prior-authorization workflows would test whether the efficiency gains survive distribution shift from synthetic to real queries.
- Varying the lambda parameter offers an explicit dial for trading accuracy against latency in production retrieval systems.
- The observed Pareto dominance suggests that advantage-weighted or preference-based methods are generally required to learn selective retrieval rather than exhaustive behavior.
Load-bearing premise
Synthetic prior authorization requests generated from publicly available CMS coverage data accurately represent the distribution, complexity, and decision criteria of real-world prior authorization queries.
What would settle it
Evaluating the trained CQL, IQL, and DPO policies on a held-out collection of actual prior authorization requests obtained from a health plan or provider system and measuring whether the 92 percent accuracy level and the reported reductions in retrieval steps are preserved.
Figures




read the original abstract
Prior authorization (PA) requires interpretation of complex and fragmented coverage policies, yet existing retrieval-augmented systems rely on static top-$K$ strategies with fixed numbers of retrieved sections. Such fixed retrieval can be inefficient and gather irrelevant or insufficient information. We model policy retrieval for PA as a sequential decision-making problem, formulating adaptive retrieval as a Markov Decision Process (MDP). In our system, an agent iteratively selects policy chunks from a top-$K$ candidate set or chooses to stop and issue a decision. The reward balances decision correctness against retrieval cost, capturing the trade-off between accuracy and efficiency. We train policies using Conservative Q-Learning (CQL), Implicit Q-Learning (IQL), and Direct Preference Optimization (DPO) in an offline RL setting on logged trajectories generated from baseline retrieval strategies over synthetic PA requests derived from publicly available CMS coverage data. On a corpus of 186 policy chunks spanning 10 CMS procedures, CQL achieves 92% decision accuracy (+30 percentage points over the best fixed-$K$ baseline) via exhaustive retrieval, while IQL matches the best baseline accuracy using 44% fewer retrieval steps and achieves the only positive episodic return among all policies. Transition-level DPO matches CQL's 92% accuracy while using 47% fewer retrieval steps (10.6 vs. 20.0), occupying a "selective-accurate" region on the Pareto frontier that dominates both CQL and BC. A behavioral cloning baseline matches CQL, confirming that advantage-weighted or preference-based policy extraction is needed to learn selective retrieval. Lambda ablation over step costs $\lambda \in \{0.05, 0.1, 0.2\}$ reveals a clear accuracy-efficiency inflection: only at $\lambda = 0.2$ does CQL transition from exhaustive to selective retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models prior authorization policy retrieval as an MDP in which an agent iteratively selects chunks from a top-K candidate set or stops to issue a decision. It generates logged trajectories from fixed-K baselines on synthetic PA requests derived from CMS coverage data (186 chunks, 10 procedures), defines a reward balancing decision correctness against per-step retrieval cost, and trains offline RL policies (CQL, IQL, transition-level DPO) plus a BC baseline. On held-out trajectories, CQL reaches 92% accuracy via exhaustive retrieval (+30 pp over the best fixed-K baseline), IQL matches baseline accuracy with 44% fewer steps and the only positive episodic return, and transition-level DPO matches CQL accuracy with 47% fewer steps (10.6 vs. 20.0), occupying a selective-accurate region on the Pareto frontier. A lambda ablation shows an accuracy-efficiency inflection at λ=0.2.
Significance. If the empirical results hold under more detailed reporting, the work demonstrates that offline RL can extract adaptive retrieval policies that dominate static top-K baselines on the accuracy-efficiency frontier for retrieval-augmented decision tasks. The concrete Pareto improvements (especially IQL and DPO) and the lambda ablation provide falsifiable evidence that advantage-weighted or preference-based extraction is required to learn selective stopping, which is a useful contribution to RL-for-RAG literature even within the synthetic setting.
major comments (2)
- [Experimental Setup / Data Generation] Data generation and reward sections: the manuscript provides no explicit description of how the 186 synthetic PA requests were constructed from CMS coverage data, how queries were validated against real prior-authorization cases, or the precise mathematical form of the reward (correctness term minus λ × steps). These omissions are load-bearing for the central performance claims (92% accuracy, step reductions) because the reported numbers cannot be reproduced or assessed for sensitivity to data distribution.
- [Results] Results section: no statistical significance tests, confidence intervals, or per-procedure variance are reported for the accuracy and step-count metrics across the 10 procedures. Without these, the +30 pp improvement and the claim that IQL is the only policy with positive episodic return cannot be evaluated for robustness.
minor comments (1)
- [Ablation Study] The lambda ablation is presented post-hoc; adding a brief pre-specified analysis plan or sensitivity plot for λ ∈ {0.05,0.1,0.2} would strengthen the inflection-point claim.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. The comments highlight important areas for improving the manuscript's clarity and rigor. We respond to each major comment below and will incorporate the necessary revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Experimental Setup / Data Generation] Data generation and reward sections: the manuscript provides no explicit description of how the 186 synthetic PA requests were constructed from CMS coverage data, how queries were validated against real prior-authorization cases, or the precise mathematical form of the reward (correctness term minus λ × steps). These omissions are load-bearing for the central performance claims (92% accuracy, step reductions) because the reported numbers cannot be reproduced or assessed for sensitivity to data distribution.
Authors: We agree that the manuscript would benefit from more explicit descriptions in the data generation and reward sections to facilitate reproducibility. We will add a detailed explanation of how the 186 synthetic PA requests were constructed from the CMS coverage data, including the selection of the 10 procedures and chunking process. We will also clarify that the queries are synthetic and were not validated against real prior-authorization cases, as the study focuses on a controlled synthetic environment. Furthermore, we will include the precise mathematical form of the reward function, which is the correctness indicator minus λ times the number of steps. These revisions will be incorporated in the next version of the manuscript. revision: yes
-
Referee: [Results] Results section: no statistical significance tests, confidence intervals, or per-procedure variance are reported for the accuracy and step-count metrics across the 10 procedures. Without these, the +30 pp improvement and the claim that IQL is the only policy with positive episodic return cannot be evaluated for robustness.
Authors: We concur that the absence of statistical measures limits the ability to assess robustness. In the revised manuscript, we will update the Results section to include 95% bootstrap confidence intervals for the key metrics (accuracy, step counts, and episodic returns), calculated from multiple resamples of the held-out trajectories. Additionally, we will report per-procedure breakdowns to illustrate variance across the 10 procedures. To support the claim regarding IQL's positive episodic return, we will include a statistical comparison (e.g., one-sample t-test against zero for each policy's mean return) and note the significance levels. These enhancements will provide a more rigorous evaluation of the reported improvements. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper formulates adaptive retrieval as an MDP and reports empirical performance of offline RL policies (CQL, IQL, DPO) trained on logged trajectories from baseline strategies over synthetic CMS-derived PA requests. All central claims—92% accuracy, step reductions, Pareto dominance—are direct outputs of experimental evaluation on held-out data with explicit reward definitions and lambda ablations. No equations, predictions, or uniqueness arguments reduce by construction to fitted inputs or self-citations; the chain is a standard train-evaluate loop on a controlled synthetic corpus and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda (step cost)
axioms (1)
- domain assumption The reward function that balances decision correctness against retrieval cost accurately reflects real-world trade-offs in prior authorization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The reward balances decision correctness against retrieval cost... rt = −λ ... Total return: G = rT − λ·n
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train policies using Conservative Q-Learning (CQL), Implicit Q-Learning (IQL), and Direct Preference Optimization (DPO) in an offline RL setting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jeong, S., Baek, J., Cho, S., Hwang, S
Accessed: 2026- 03-13. Jeong, S., Baek, J., Cho, S., Hwang, S. J., and Park, J. C. Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. In Proceedings of NAACL,
2026
-
[2]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline re- inforcement learning: Tutorial, review, and perspectives. arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review arXiv 2005
-
[3]
D., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.